Train Stages: Pretrain, Mid-Train(CT), SFT, RL
导言
模型训练,为什么需要这么多阶段,每个阶段的独特职责和意义是什么。
预训练、中训练、后训练
大语言模型(LLM)的训练通常分为三个主要阶段:预训练(Pre-training)、中训练(Mid-training)和后训练(Post-training)。
- 预训练阶段赋予模型通用的语言能力、世界知识和基础的推理能力。就像让孩子泛读海量的书籍,目标是掌握基本的语言和常识。这个阶段学的知识很广,但不够精深。
- 中训练阶段则向模型注入特定领域的知识,例如代码、医学文献或公司内部文档。Continued Training (CT) 这是一个新发现的、很重要的阶段。就像在孩子泛读之后,让他精读一些高质量的科普文章或数学应用题,为后面的专项学习打下更好的基础。
- 最后的后训练阶段,旨在引导模型产生符合期望的特定行为,如遵循指令、解决数学问题或进行对话。(SFT、RL、Distillation )
Mid-train的重要性¶
Mid-train位于Pre-train和Post-train之间,用于弥合预训练数据分布和后训练目标的差距。通过通过使用更高质量、更具针对性的数据(例如指令格式的数据)+预训练阶段相同的训练目标,来强化模型在特定领域的推理先验知识,稳定优化过程,并为后续的强化学习(RL)做好准备。
这篇论文发现1,在计算资源有限的前提下,将一部分计算资源从RL分配给中期训练,最终的整体效果会比全部资源用于RL更好。特别是对于难度适中的任务,“大量中期训练 + 少量RL” 的方案是最优的。中期训练奠定了坚实的“能力基石”,RL则负责最后的“冲刺和优化”。
后训练/微调/RL的必要性¶
大型语言模型(Large Language Models, LLMs)的出现是人工智能领域的一个重要里程碑。这些模型通过在海量的文本语料库上进行自监督预训练,掌握了强大的语言理解和生成能力。2
然而,预训练的目标(如“下一个词预测”)本质上是模仿数据分布,这并不足以保证模型生成的内容完全符合人类的价值观和期望。未经对齐的LLM可能会产生不准确、有偏见、有害甚至虚构的内容。
因此,模型对齐(Alignment)应运而生。其核心目标是微调预训练模型,使其行为与人类的意图、偏好和价值观(如有帮助性、诚实性、无害性,即“3H”原则)保持一致。这是确保LLM安全、可靠地部署于现实世界的关键步骤。
为了应对对齐挑战,研究界探索了多种方法,其中基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)迅速成为主导范式。RLHF的核心思想是将人类的偏好数据转化为一个数值奖励信号,然后利用强化学习算法优化语言模型的策略(即其生成文本的方式),以最大化期望奖励。
在LLM对齐的早期探索中,研究者们建立了两种影响深远的基础范式。
- 一种是基于强化学习的PPO,它将经典的RL框架引入LLM微调,通过复杂的系统协调实现了强大的性能;
- 另一种是DPO,它通过深刻的理论洞见,将对齐问题转化为一个更简洁的监督学习问题,显著提升了训练的稳定性和效率。
为什么需要后训练?¶
想象一下,我们辛辛苦苦训练出了一个拥有海量知识的基础大模型。它能记住无数事实、理解复杂的语法结构,甚至具备潜在的推理能力。但这还不够!就像一个学富五车的学者,如果他不了解如何有效地与人沟通、不明白你的具体需求,或者无法根据情境调整自己的表达方式,他的学识就难以充分发挥价值。[^6]
大语言模型(LLMs)的基础模型(Base Model)在海量数据上预训练后,虽然掌握了基础能力,但它们并不能直接理解和遵循人类的复杂指令,也无法自然地与人互动,更不用说根据用户的偏好或特定任务需求来调整行为。它们可能不知道何时需要一步步推理(思维),何时需要直接给出答案(非思维),也不知道如何生成符合特定格式、长度或风格的文本。
后训练的目标是将基础模型与人类偏好和下游应用更好地对齐。简单来说,就是教模型“读懂人心”,让它知道我们想要什么,并以我们希望的方式来回应。
Qwen3的后训练尤其强调两大目标:
- 思维控制,让模型能选择是否推理以及控制推理深度;
- 以及强到弱蒸馏,利用大模型的知识高效地训练小模型。
RL定义、流程¶
强化学习是智能体(Agent)通过试错与环境(Environment)进行交互,学习如何做出最优决策以最大化累积奖励(Cumulative Reward)的过程。
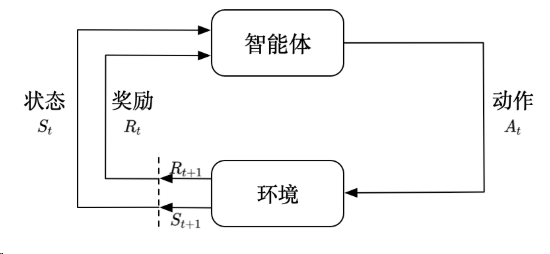
其常规流程是一个迭代的循环:
- 感知状态(State, \(S\)): 智能体感知环境的当前状态 \(S_t\)。
- 决策动作(Action, \(A\)): 智能体根据其策略(Policy, \(\pi\)),基于当前状态 \(S_t\) 选择一个动作 \(A_t\)。
- 环境反馈: 动作 \(A_t\) 在环境中执行,环境会产生两个反馈:
- 即时奖励(Reward, \(R\)): 智能体获得一个即时奖励 \(R_{t+1}\),用于衡量动作的好坏。
- 新状态(New State, \(S'\)): 环境转移到新的状态 \(S_{t+1}\)。
- 策略更新(Update): 智能体利用获得的奖励 \(R_{t+1}\) 和状态序列 \((S_t, A_t, R_{t+1}, S_{t+1})\) 来更新其策略 \(\pi\)(以及可能的值函数 \(V\) 或 \(Q\)),目的是让策略在未来能获得更高的累积奖励。
- 重复: 智能体在新状态 \(S_{t+1}\) 继续下一个时间步的交互。
核心要素:
- 策略 (\(\pi\)): 定义了智能体在特定状态下选择动作的规则。
- 奖励信号 (\(R\)): 定义了RL的目标,即最大化累积奖励。
- 价值函数 (\(V\) 或 \(Q\)): 预测一个状态或状态-动作对的长期期望累积奖励,用于指导策略的改进。
Agent in RL和Agentic RL
Agentic RL 的核心目标是决策(Decision-making)。它旨在优化LLM 在一系列连续的交互步骤中完成复杂任务的能力。
RL 如何提效¶
难度是数据边缘¶
外推泛化(Depth Generalization)指看模型能不能把学到的简单技能组合起来,解决更复杂的问题。
- 对于太简单的题目,RL是无效的,只是机械刷题、1
- 对于太难的,RL也是无效的,因为模型根本学不会;
- 只有正好在模型能力边界的题目,通过合理的奖励机制,RL能够引导模型探索正确的解题路径,实现了能力边界的拓展。
核心魅力:自动化处理 Corner Case¶
相较于 SFT(监督微调),RL 真正的价值在于其对 OOD(分布外数据) 的处理能力:
- 无脑梭哈:只需定义好环境与 Question,利用 GRPO 等算法让模型在探索中自发碰撞出 Corner Cases 并学习。
- 正样本质量:RL 极其依赖正样本的规模与多样性,但获取高质量正样本的路径存在技术陷阱。
泛化需要有锚点¶
上下文泛化(Contextual Generalization)是指模型能否实现举一反三的能力:比如模型在“动物园”的场景下学会了加法,那么它能不能把加法应用到“学校”的场景中?1
研究发现:如果预训练数据中完全没有“学校”场景的题目,那么后续无论怎么用RL训练,模型都无法把加法技能迁移到“学校”场景。但是,只要在预训练中掺入极少量的“学校”场景基础题(比如只占1%),这就好像在心里埋下了一颗“种子”。
一旦有了这颗“种子”,后续的RL训练就能像浇水施肥一样,极大地激发模型的迁移能力。模型可以轻松地将从“动物园”中学到的复杂推理技能,应用到“学校”场景中。
RL阶段的扩展定律¶
研究2通过对 Qwen2.5 全系列模型的详尽实证分析,确立了 RL 后训练在数学推理任务上的扩展定律。
关键启示:
- 大模型不仅起步高,学得也快:在相同数据/计算下,大模型效率更高。
- 效率有天花板:不能指望通过无限扩大模型来线性获得效率收益,必须考虑饱和效应。
- 数据复用是实用的:在数据匮乏时,多跑几个 Epoch 没问题,总步数到位就行。
- 专业化的代价:数学能力的增强可能以逻辑推理能力的退化为代价,且难以直接迁移到代码或科学领域。
Meta提出的一个名为ScaleRL的强化学习框架,旨在解决LLM强化学习阶段缺乏可预测性的问题。文章介绍了利用S型曲线预测计算量与性能关系的分析框架,详细阐述了包含PipelineRL异步设置、CISPO损失函数等核心组件的ScaleRL训练配方,并总结了关于性能上限、计算效率及大规模验证的核心洞见:
- RL性能可拟合成:sigmod曲线,有收敛上限;
- 性能上限非普适:不同RL配方的性能上限A差异巨大,需通过实验识别。
- RL领域的“苦涩教训”:在低计算量下表现更优的方法,在扩展到高计算量时,其性能可能更差。例如,在对比不同批次大小时,较小的批次在训练初期性能增长更快,但其性能上限却低于较大的批次。这印证了「苦涩的教训」——最终胜出的是那些充分利用计算资源、具有更好伸缩性的方法,而非那些为小规模计算而优化的「捷径」。S 型曲线框架的价值正在于,它能帮助我们透过早期的效率表象,识别出那些拥有更高性能上限 、真正「可伸缩」的方法。
- 大道至简,干预措施的作用:许多被认为能提升性能的常见技巧,如优势归一化、数据课程、长度惩罚等,其主要作用是调节计算效率,而非改变性能上限。
- 大规模验证:使用ScaleRL对8B模型进行10万GPU小时训练,前半程数据拟合的S型曲线与后半程真实数据高度吻合,验证了框架的预测能力。
大道至简RL¶
(小模型专属的?)
- 传统认为:优势: 迭代快;劣势:效果差(不稳定)
- 但是 JustRL 小模型多步数GRPO也有效果,一文做实验却发现不一定是这样的(结论的泛化性有待怀疑)
- Step-3-V-10B:通过力大砖飞的RL(PPO+GAE),实现10B参数媲美100B模型智能的效果:RLVR:600 次迭代 + RLHF:300 次迭代 + PaCoRe Training:500 次迭代。
RL 核心原理¶
NIPS25唯一满分论文:Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? 揭示传统观点认为RL训练能够赋予LLMs超越基础模型的全新推理能力,但本文通过系统性实验证明:RL训练并未真正扩展模型的根本推理能力边界,而主要是提高了模型在已有能力范围内采样到正确推理路径的效率。(RL将pass@k的能力压缩到了pass@1;但是在k很大时,RL后的模型甚至打不过基模)
RL的悲观观点¶
强化学习相对于监督学习比我们想象的要更加低效
当然为了更高效,RL领域一方面设计的复杂reward、课程学习、和分段reward;另一方面加速推理,简化流程来产出早期可评估信号。
RL越强,AGI越远
知名科技博主Dwarkesh Patel犀利在视频中指出,各大实验室通过RL(强化学习),耗资数十亿美元让大模型“排练”Excel、网页操作等技能,恰恰暴露其距真正AGI仍远。若AI真接近类人智能,就该像人类一样从经验中自主学习,而非依赖“可验证奖励训练”。而真正突破在于“持续学习”能力,这一过程或需5-10年才能完善。
Offline RL vs Online RL¶
在线强化学习(Online RL)和离线强化学习(Offline RL,也称 Batch RL)的主要区别在于智能体(Agent)获取数据的方式以及是否能在训练过程中与环境进行交互。
以下是它们的核心区别对比:
1. 核心定义与交互方式¶
- 在线强化学习 (Online RL): 智能体处于一个“试错”的循环中。它在环境中采取行动,观察结果(奖励和下一个状态),并立即利用这些新数据来改进自己的策略。
-
流程: 交互 收集数据 更新策略 再次交互。
-
离线强化学习 (Offline RL): 智能体不再与环境直接交互,而是从一个预先收集好的、固定的数据集中学习。这个数据集通常由其他策略(可能是人类操作员或其他算法)产生的历史记录组成。
- 流程: 预收集数据 静态学习 部署。
2. 关键维度对比¶
| 维度 | 在线强化学习 (Online RL) | 离线强化学习 (Offline RL) |
|---|---|---|
| 数据来源 | 实时交互产生的数据 | 静态的历史数据集(日志) |
| 探索能力 | 主动探索:可以尝试新动作来发现更好的策略 | 被动学习:无法探索数据集之外的可能 |
| 反馈机制 | 封闭环路:策略改变后能立即看到反馈 | 开放环路:无法验证新策略在真实环境中的效果 |
| 安全性 | 较低:探索过程中可能采取危险动作(如撞车) | 较高:训练过程不涉及实体操作,非常安全 |
| 成本/可行性 | 高:需要实时运行环境或高精度模拟器 | 低:利用现有存储数据,无需昂贵的实时交互 |
| 主要挑战 | 样本效率(需要大量交互) | 分布偏移 (Distribution Shift) |
3. 应用场景示例¶
-
在线强化学习:
- 游戏 AI(如 AlphaZero、星际争霸):可以在模拟器中进行数亿次低成本尝试。
- 机器人实验室环境:在受控条件下进行实机训练。
-
离线强化学习:
- 医疗推荐: 无法在患者身上随机试验不同的药物,只能通过历史病历数据学习最优方案。
- 自动驾驶: 在真实道路上随机“探索”太危险,通常利用数百万英里的行驶日志进行学习。
- 推荐系统: 利用用户的历史点击日志进行策略优化,避免频繁打扰用户。
总结:
- Online RL 像是一个在操场上边跑边学、不断摔跤总结经验的学生。
- Offline RL 像是一个坐在图书馆里,通过查阅学长们留下的实验记录来学习的学生。
4. 为什么离线强化学习更难?—— 分布偏移问题¶
这是 Offline RL 面临的最致命问题。 在训练过程中,智能体可能会预测某个在数据集中从未出现过的动作(Out-of-Distribution, OOD)具有极高的回报。由于无法去真实环境中验证,智能体容易产生“过度自信”的错误估计,导致学出的策略在实际部署时表现极差。
而在 Online RL 中,如果智能体高估了某个动作,它只需要去尝试一下,发现回报并不高,就会自动修正这个估计。
DPO解释分布偏移问题¶
虽然 DPO 常被看作一种有监督微调(SFT)的变体,但它的核心逻辑依然是离线策略优化。为了让你理解为什么它比在线学习(如带奖励模型的 PPO)更难,我们可以通过一个形象的对比来看:
1. 核心矛盾:你没见过的,“脑补”出来的就是对的吗?¶
在 DPO 中,我们拥有的数据是固定的:{问题 x, 好的回答 yw, 坏的回答 yl}。
在线 RL (类似 PPO):有“教练”实时纠错¶
- 过程: 模型生成了一个它认为“绝妙”但实际上很离谱的回答(例如一串乱码,但正好触发了奖励模型的漏洞)。
- 结果: 奖励模型(或真人)会立即给这串乱码打低分。
- 反馈: 模型立刻知道:“哦,这招不行”,然后修正自己的认知。
离线 RL (类似 DPO):只能“死记硬背”¶
- 过程: DPO 试图推导出一个概率分布,使得
yw的概率远大于yl。 - 风险: 优化过程中,模型可能会发现某些单词组合(在数据集中从未出现过)在数学公式推导下能获得极高的分值。
- 致命点: 因为是离线的,没有“教练”告诉你这串新组合是错的。模型会顺着这个“数学漏洞”疯狂漂移,最终生成一堆看似逻辑合理但人类完全无法理解的内容。
2. DPO 中的“分布偏移”具体长什么样?¶
在 DPO 中,分布偏移主要体现在模型策略 () 与 参考策略 () 以及 原始数据分布 之间的脱节。
A. 过度拟合与“奖励黑客” (Reward Hacking)¶
DPO 的损失函数中包含一个隐含的奖励函数。如果模型发现某种特定的说话风格(比如总是以“好的”开头)在数据集里普遍被选为 yw,它可能会在离线训练中不断强化这种风格,直到它生成的每一句话都变得极其机械化。
B. 缺乏负面反馈的边界¶
在离线数据里,我们只告诉了模型:A 比 B 好。 但是,如果模型想尝试 C(一个全新的回答方向),离线数据里没有关于 C 的任何信息。
- 如果 C 其实很烂,但模型“脑补”出 C 应该比 A 更好。
- 在离线状态下,没有任何力量能拉回这个错误的认知。
3. DPO 是如何“勉强”应对这个问题的?¶
为了防止模型“跑偏”太远(即缓解分布偏移),DPO 在公式里内置了一个约束:KL 散度。
- ** 的作用:** 它像一根“安全绳”。它告诉模型:“你优化的方向可以偏向 ,但你的整体分布不能离最初的那个模型(SFT 模型)太远。”
- 局限性: 即使有这根绳子,如果 (惩罚系数)设得太小,或者训练步数太多,模型依然会挣脱约束,走向崩溃(即性能突然大幅下降)。这就是为什么离线训练调参极其痛苦。
4. 总结对比:为什么 DPO(离线)更难?¶
| 特性 | 在线学习 (PPO) | 离线学习 (DPO) |
|---|---|---|
| 数据动态性 | 活的。模型自己生成,自己领悟。 | 死的。只能从历史偏好中抠细节。 |
| 错误的代价 | 没关系,试错(Explore)是学习的一部分。 | 致命。一旦产生错误认知的偏离,会越跑越远。 |
| 稳定性 | 训练复杂,但有奖励模型兜底。 | 训练简单,但极易因为数据分布偏移导致模型“变傻”。 |
简单来说: 离线强化学习(如 DPO)就像是看着去年的考试卷子和标准答案复习。如果你自作聪明总结出了一些卷子里没考到的“歪理”,考试时(部署时)没人能提醒你,你就会直接挂科。而在线强化学习是有老师带着你做模拟题,你一想歪,老师就敲你教鞭。
参考文献¶
-
On the Interplay of Pre-Training, Mid-Training, and RL on Reasoning Language Models RL不是“许愿池”:CMU研究揭示大模型推理能力的真正来源 ↩↩↩
-
从 0.5B 到 72B:揭秘 RL Post-Training 中的计算、数据与模型规模权衡 Scaling Behaviors of LLM Reinforcement Learning Post-Training: An Empirical Study in Mathematical Reasoning ↩↩
-
https://www.dwarkesh.com/p/bits-per-sample ↩
-
https://www.tobyord.com/writing/inefficiency-of-reinforcement-learning ↩