DMD & DMDR
导言
多模态生成模型的推理速度一直受制于diffusion模型的多步去噪,这也限制了RL的迭代速度。为此DMDR解决了这个问题。可以结合DiffusionNFT+DMDR
一句话先看懂¶
DMDR 可以理解为把 DMD 的“分布蒸馏”和 RL 的“偏好对齐”合并到同一个训练框架里。本文以文本到图像为主,因为论文实验主要落在 SDXL、SD3、SD3.5 等视觉生成模型上 [2]。它的目标不是单纯把多步 diffusion 压成少步,而是让少步模型既保留 teacher 的生成先验,又能通过 reward 超过 teacher;论文报告它在 few-step 设置下取得了很强的结果,部分场景甚至超过多步 teacher [1][2]。
DMD 怎么做¶
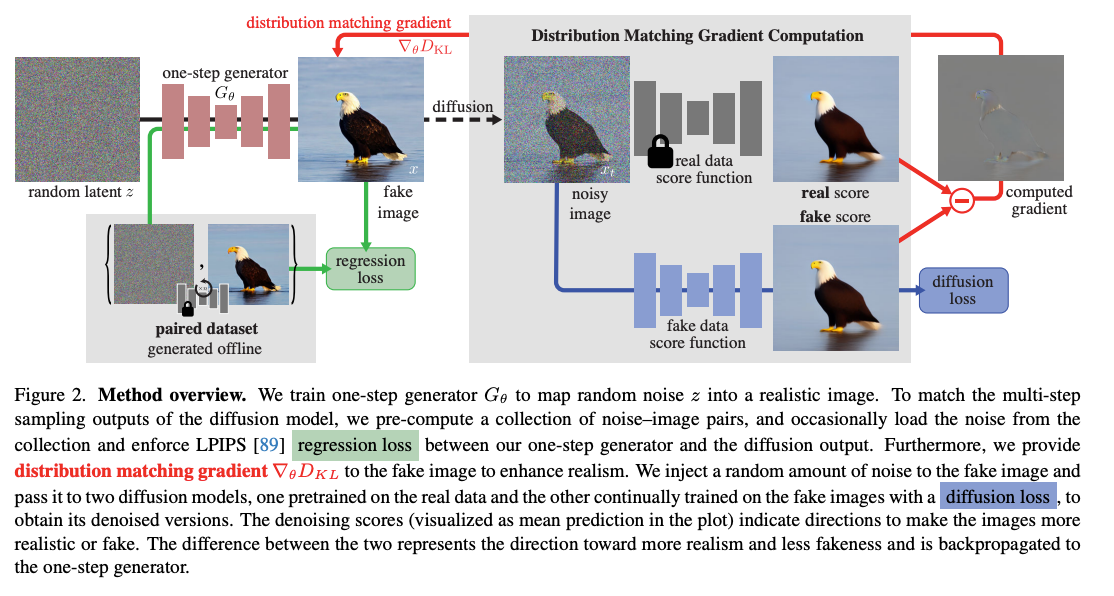
DMD 的核心不是模仿 teacher 的每一步轨迹,而是在每个噪声层 \(t\) 上让学生分布 \(p_{\text{fake},t}\) 逼近 teacher 分布 \(p_{\text{real},t}\),本质上是在“分布空间”做蒸馏 [2]。可以把它记成:
其梯度本质上来自 real score 与 fake score 的差,score 可以粗略理解成“朝更高概率区域走的方向” [2]。
流程可以简化成 4 步:
- 先从高斯噪声 \(z \sim \mathcal{N}(0, I)\) 出发,由 few-step student 生成样本 [2]。
- 再把样本做 re-noise / forward diffusion,拉回到某个时间步 \(t\),让比较发生在同一噪声层 [2]。
- 用 teacher 侧的 real score estimator 和 student 侧的 fake score estimator 估计两侧分布的 score [2]。
- 用 score 差更新 generator;同时用 diffusion loss 训练 fake score estimator,使它持续跟上 student 的变化 [2]。
可以把这套机制理解成:不是让 student 机械复刻 teacher,而是让两者在每个噪声坐标上对齐。这样既保留扩散模型的生成先验,又把采样步数压到很少 [2]。
DMDR 怎么做¶
DMDR 的出发点是:DMD 能提速,但 student 的上限仍然受 teacher 约束;而 RL 能引入 teacher 之外的 reward 信号,让 student 有机会超过 teacher [1][2]。相比把 RL 放到蒸馏之后再单独做正则,DMDR 直接把两者放在一起优化,并且不依赖外部真实图像数据,也绕开了 GAN 分支常见的不稳定性 [2]。
联合训练带来两个互补效应 [2]:
- RL 促进 DMD:把学生从低奖励模式里拉出来,提升 mode coverage(避免漏掉 teacher 的重要模式),缓解 zero forcing(某些模式被直接忽略)。
- DMD 稳定 RL:用 teacher 的完整分布约束 student,避免只追 reward 导致的 reward hacking(为了高分生成劣化图像)。
论文中的联合目标可以简写为:
为了让训练一开始就能“站稳”,DMDR 还设计了一个动态冷启动阶段 [2]:
- DynaDG:在 teacher 侧和 student 侧的 score estimator 上注入 LoRA;早期对 teacher 侧用较小 scale,让 real/fake 的分布估计更容易重叠,后期再逐步减弱,恢复更准确的 teacher 估计 [2]。
- DynaRS:早期更多采样高噪声层,让模型先学全局结构;之后再逐渐过渡到更均匀的噪声采样,补细节 [2]。
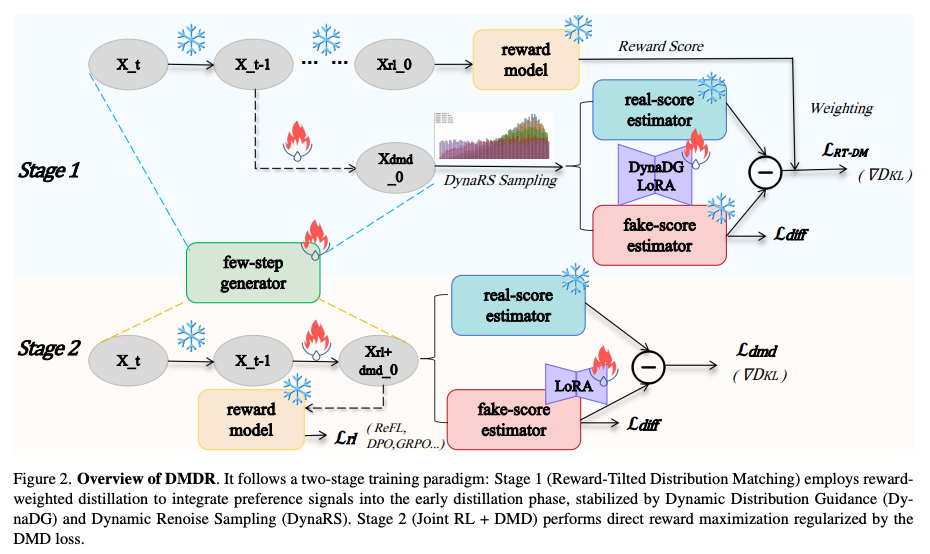
从工程角度看,DMDR 是 image-free 的,不依赖额外真实图像数据,同时可兼容 denoising-based 和 flow-based 模型,也能和 ReFL、DPO、GRPO 等 RL 算法组合 [2]。
论文信息
- 论文名:Distribution Matching Distillation Meets Reinforcement Learning [1][2]
- 作者:Dengyang Jiang 等 [1][2]
- 单位:香港科技大学、阿里巴巴集团、浙江工业大学、香港中文大学等机构 [2]
- 公开时间:arXiv 首次提交为 2025-11-17,最新 v4 为 2026-03-24 [1]
- 开源代码:官方 GitHub 仓库已公开,地址是 https://github.com/vvvvvjdy/dmdr;但仓库 README 说明当前主要开放的是 ImageNet 训练 demo [3]
快速记忆¶
- DMD:把“多步扩散”压成“少步生成”,方法是对齐每个噪声层上的分布,而不是模仿整条轨迹 [2]。
- DMDR:在 DMD 上加 RL,让少步模型既快又更符合偏好,同时用 DMD 约束 RL,减少 reward hacking [1][2]。
- 关键技巧:冷启动阶段用 DynaDG + DynaRS 先把训练拉起来,再进入 DMD 与 RL 的联合优化 [2]。
- 结果:few-step 模型可达领先水平,部分设置下甚至超过多步 teacher [1][2]。
因此,DMDR 的本质不是“先蒸馏、后 RL”,而是让 DMD 充当结构约束,让 RL 提供偏好方向,在同一训练过程中同时提速和提质 [1][2]。
最新研究¶
AnyFlow:任意步数视频扩散蒸馏
AnyFlow: Any-Step Video Diffusion Model with On-Policy Flow Map Distillation
新加坡国立大学 Show Lab, MIT, NVIDIA视频扩散Flow MapOn-Policy 蒸馏Any-Step推理加速
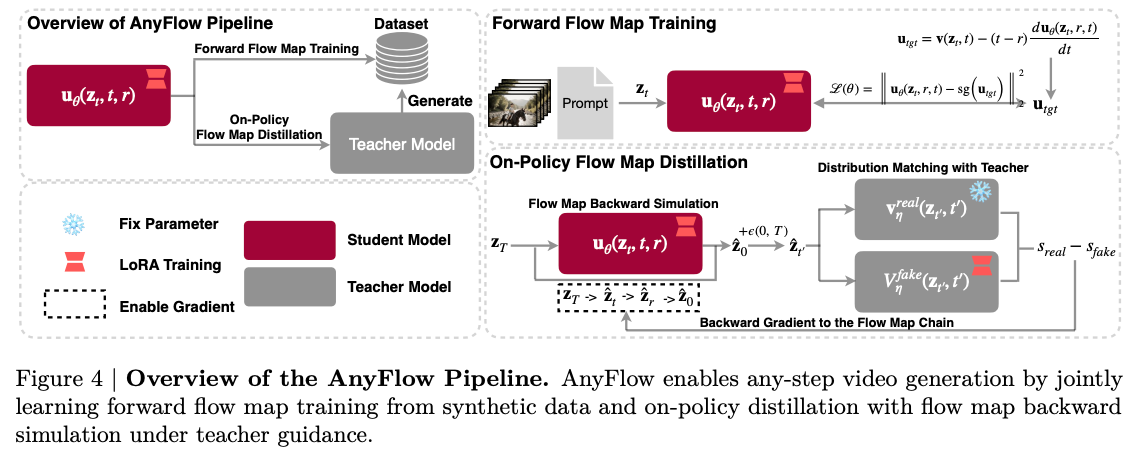
- 前序问题:近一年的少步视频生成几乎被一致性蒸馏(Consistency Distillation)统治,4-8 步即可出图,但只要把采样步数从 4 加到 16/32 画质反而塌——CD 用一致性轨迹替换了原始 PF-ODE 轨迹,破坏了 ODE 采样在测试时的可扩展行为,无法服务「任意步数」推理需求
- 本文贡献:提出 AnyFlow——首个基于 flow map 的任意步数视频扩散蒸馏框架:(1) 把蒸馏目标从端点一致性映射 z_t→z_0 升级为流图过渡 z_t→z_r,让学生学会任意时间区间的跳跃;(2) Flow Map Backward Simulation 把完整 Euler rollout 拆为多段 shortcut,用 on-policy rollout 替代 off-policy 配对蒸馏,缓解少步采样的离散化误差和因果生成的 exposure bias
- 实验效果:在双向 DiT 与因果两类视频扩散骨干、1.3B 到 14B 全规模区间一致达到或超越 consistency baseline;当步数从 4 提升到 16/32 时性能不再退化、反而单调上升,重新恢复了 ODE 采样的 test-time scaling 优势
- 批判点评:把蒸馏目标从端点一致性升级到任意区间流图是范式级创新,FMBS 的 on-policy 反向模拟在视频域是首次系统化提出;但论文未公开 VBench/UCF-FVD 等具体数值,复现门槛在 1B-14B 教师 + 大规模 on-policy rollout,数据与算力两端都不低