AI Post Traning: RL & RHLF & DPO
导言
Deepseek 的 GRPO 方法展示了强化学习的潜能。
RLHF 利用复杂的反馈回路,结合人工评估和奖励模型来指导人工智能的学习过程。而DPO 采用了更直接的方法,直接运用人的偏好来影响模型的调整。
Step-Video论文介绍了Video-DPO, 这类训练中最后通过人工标注优化的方法。
RLHF¶
RLHF (Reinforcement Learning from Human Feedback) ,即以强化学习方式依据人类反馈优化语言模型。
思想:用生成文本的人工反馈作为性能衡量标准,或者更进一步用该反馈作为损失来优化模型。RLHF 使得在一般文本数据语料库上训练的语言模型能和复杂的人类价值观对齐。1
预训练一个语言模型 (LM) ;¶
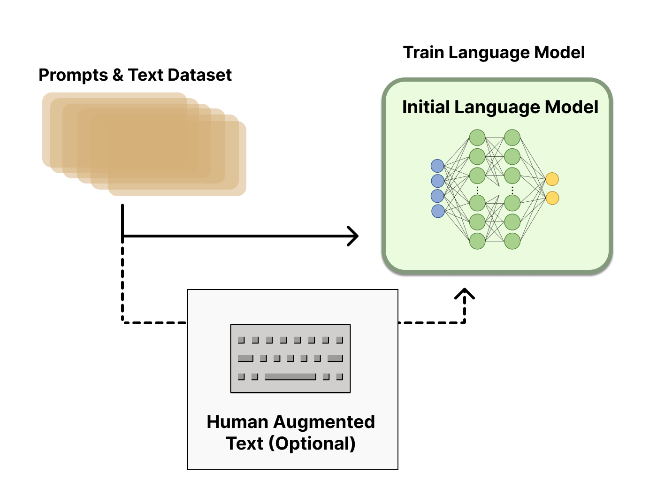
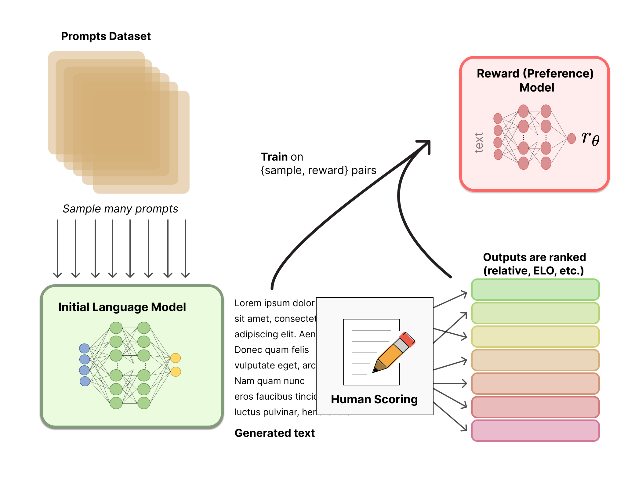
聚合问答数据并训练一个奖励模型 (Reward Model,RM) ;¶
人工对 LM 生成的回答进行排名
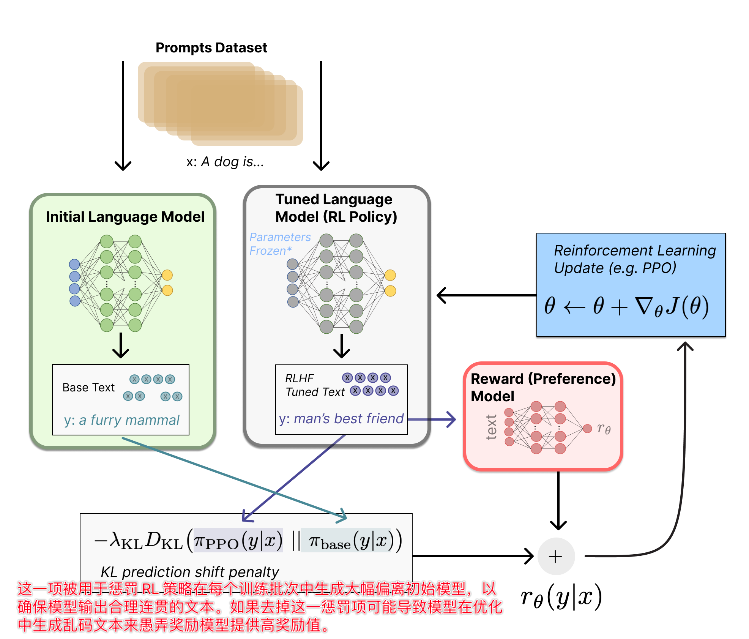
用强化学习 (RL) 方式微调 LM。¶
- 使用策略梯度强化学习 (Policy Gradient RL) 算法、近端策略优化 (Proximal Policy Optimization,PPO) 微调初始 LM 的部分或全部参数。
- 将提示 x 输入初始 LM 和当前微调的 LM,分别得到了输出文本 y1, y2,将来自当前策略的文本传递给 RM 得到一个标量的奖励 rθ,基于此优化。
DPO¶
- DPO 是基于人类直接反馈可以有效地指导人工智能行为发展的原理而提出的。
- 通过直接利用人的偏好作为训练信号,DPO 简化了校准过程,将其框定为一个直接学习任务。
- 优势:简化了人工智能系统的适应性,以更好地满足用户需求,绕过了与构建和利用奖励模型相关的复杂性。
LLM-DPO¶
使用成对的例子和相应的人类偏好,使用二元交叉熵损失函数对模型进行微调。这种统计方法将模型的输出与首选结果进行比较,量化模型的预测与所选择的首选结果的匹配程度。
偏好数据,可以表示为三元组(提示语prompt, 良好回答chosen, 一般回答rejected)。
损失函数¶
- 思路: 最大化奖励模型(此处的奖励模型即为训练的策略),使得奖励模型对chosen和rejected数据的差值最大,进而学到人类偏好。


Video-DPO¶
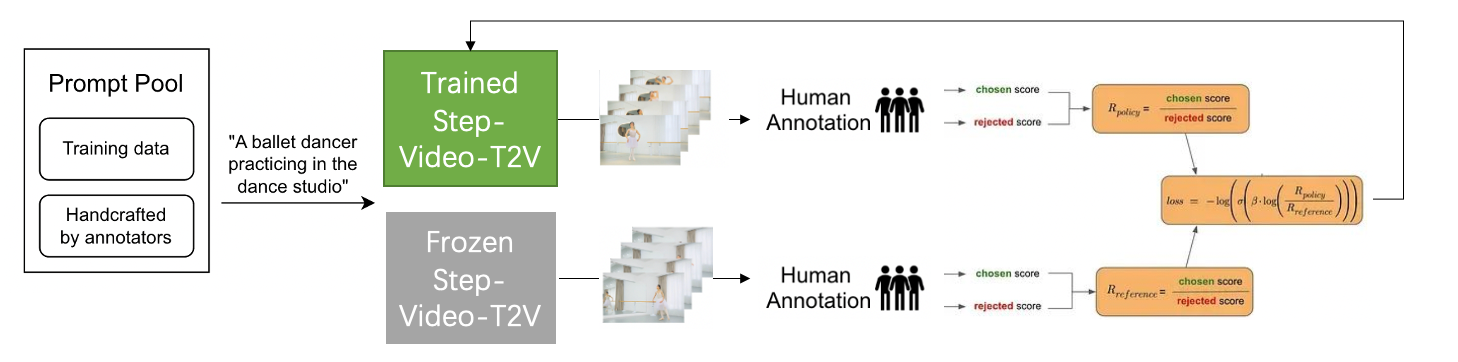
思路和LLM-DPO一样,其核心思想简洁直观且易于实现。具体而言,给定相同条件下的人类偏好数据和非偏好数据,目标是调整当前策略(即模型),使其更倾向于生成偏好数据,同时避免生成非偏好数据。为了稳定训练,引入参考策略(即参考模型)以防止当前策略偏离参考策略过远。策略目标函数定义为:2
其中,\(\pi_\theta\)为当前策略,\(\pi_{\text{ref}}\)为参考策略,\(x_w\)和\(x_l\)分别为偏好样本和非偏好样本,\(y\)为条件(如文本提示)。
数据对收集¶
为收集训练所需的偏好数据对\((x_w, x_l|y)\),我们构建多样化提示集:
- 首先从训练数据中随机选取提示以保证多样性;
- 其次邀请标注员根据模拟真实用户交互的指南合成新提示;
- 最后对每个提示生成多组视频,由人类标注员打分并筛选偏好数据。
标注过程通过质量控制确保一致性。
训练时,每次迭代选择一个提示及其对应的正负样本对,并通过固定初始噪声和时间步长保持数据一致性以提升训练稳定性。
超参调整¶
- 背景:原目标函数(式8)基于DiffusionDPO(Wallace等,2024)和DPO(Rafailov等,2024),但针对流匹配框架(Flow Matching)进行了调整。
- 通过将策略相关项记为\(z\),可推导梯度:
- 问题:当\(\beta\)过大(如DiffusionDPO中\(\beta=5000\))且\(z<0\)时,梯度可能爆炸(放大\(\beta\)倍),需通过梯度裁剪和极低学习率(如\(1e-8\))维持稳定,但会导致收敛缓慢。
- 改进:为此,我们降低\(\beta\)并提高学习率,显著加速收敛。
奖励模型¶
- 问题:实验表明,人类反馈有效提升了生成质量,但当模型能轻易区分正负样本时改进饱和。
- 解释:这可能因训练数据来自早期模型版本,迭代后当前策略已显著偏离历史策略,导致旧数据利用率下降。(DPO循环时无法记住前面的DPO数据)
- 改进:
- 为此,我们提出训练基于人类标注数据的奖励模型,
- 目的:动态评估新生成样本的质量,并通过周期性微调保持与当前策略对齐,
- 效果:最终实现实时数据打分与筛选(On-Policy),提升数据效率。
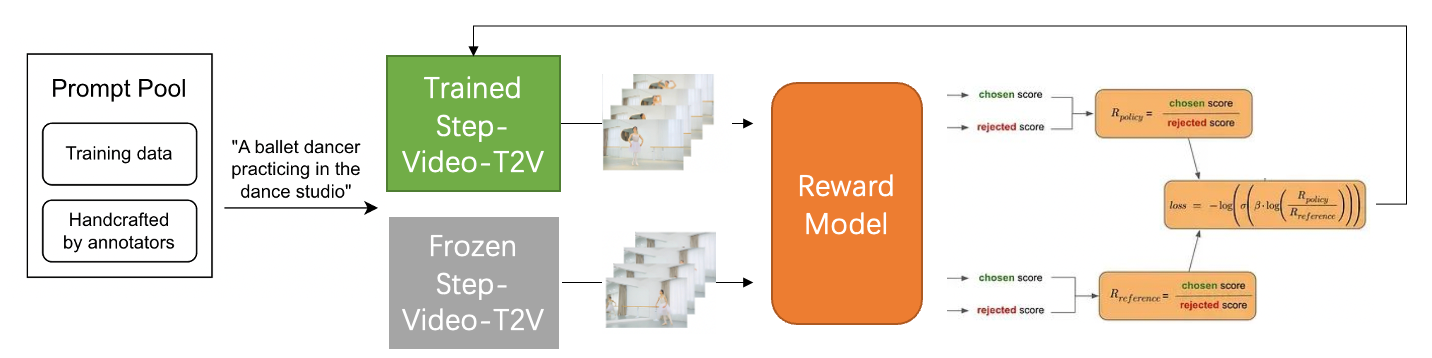
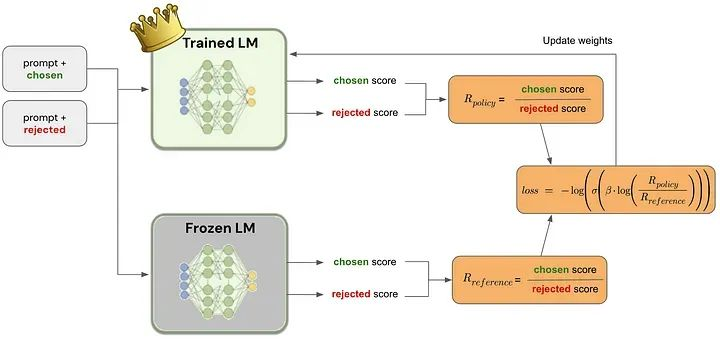
RHLF vs DPO¶

图中的chosen表示为下标w(即win),rejected表示为下标l(即lose)
上图左边是RLHF算法,右边为DPO算法,两图的差异对比即可体现出DPO的改进之处:3
- RLHF算法包含奖励模型(reward model)和策略模型(policy model,也称为演员模型,actor model),基于偏好数据以及强化学习不断迭代优化策略模型的过程。
- DPO算法不包含奖励模型和强化学习过程,直接通过偏好数据进行微调,将强化学习过程直接转换为SFT过程,因此整个训练过程简单、高效,主要的改进之处体现在于损失函数。
策略选择¶
遵循以下几个因素:4
- 任务复杂性: 如果您的项目涉及到
- 复杂的交互或者需要理解细微的人类反馈,RLHF 可能是更好的选择。
- 更直接的任务或需要快速调整时,DPO 可能更有效。
- 资源考量: 考虑计算资源和人工注释器的可用性。DPO 通常在计算能力方面要求较低,在收集必要数据方面可以更直接。
- 期望控制水平: RLHF 提供了更多的细粒度控制微调过程,而 DPO 提供了一个直接的路径,以调整模型输出与用户的喜好。评估在微调过程中需要多少控制和精度。
Video-FineTuning¶
EasyAnimate V5¶
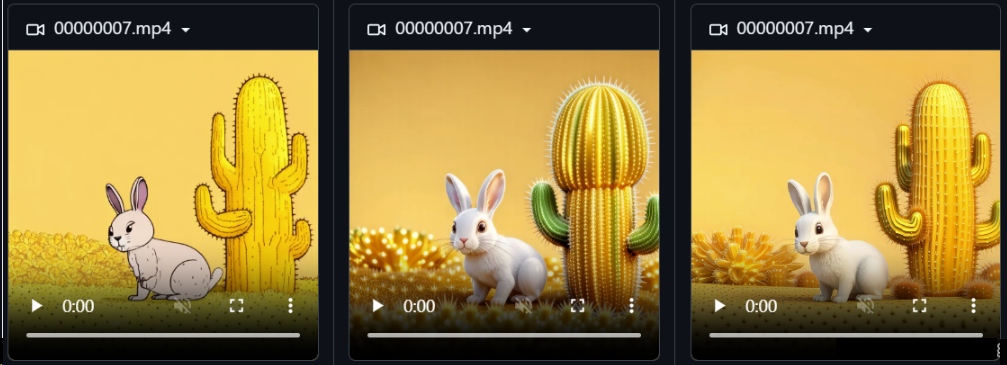
为了进一步优化生成视频的质量以更好地对齐人类偏好,我们采用奖励反向传播(DRaFT 和 DRTune)对 EasyAnimateV5.1 基础模型进行后训练,使用奖励提升模型的文本一致性与画面的精细程度。
如下三个视频,首个视频是没有使用奖励模型的生成效果,第二个视频是使用HPS作为奖励模型的生成效果,第三个视频是使用MPS作为奖励模型的生成效果。可以看到后面两个模型明显更为讨人喜欢。
细节
我们在EasyAnimate ComfyUI中详细说明了奖励反向传播的使用方案。我们实际使用了HPS v2.1和MPS两个模型对EasyAnimateV5.1进行奖励反向,两个模型都是人类偏好模型,作为反馈,调整后的EasyAnimateV5.1具有更好的文视频一致性,且画面更加精细。
Visual-RFT¶
视觉强化微调!DeepSeek R1技术成功迁移到多模态领域,全面开源