On-Policy Distillation
导言
On-Policy Distillation(OPD)不是 top-k,也不等于 RL。它先让学生模型生成自己的轨迹,再让教师在学生实际到达的前缀上提供 token 分布,以减少训练与部署时的状态分布偏移。
OPD 能否生效,关键不是教师参数量是否更大,而是师生是否共享可比较的动作空间、思维模式是否兼容,以及教师是否真的提供了学生尚未掌握的知识。本文同时梳理 DeepSeek V4、Qwen3/Qwen3.5、Qwen3.5-Omni 的公开流程,以及 verl/verl-omni 的现有能力与缺口。
OPD 的定义¶
给定提示词 \(x\),学生策略 \(\pi_\theta\) 先生成 \(y\sim\pi_\theta(\cdot\mid x)\)。教师不提供一条固定的标准答案,而是在学生已经生成的每个前缀 \(s_t=(x,y_{1:t-1})\) 上重新计算分布 \(\pi_T(\cdot\mid s_t)\)。常见目标可以写成:
它和三类训练信号的区别是:
- 离线蒸馏 / SFT:在教师或数据集预先生成的轨迹上学习,便宜稳定,但学生一旦走到训练数据没有覆盖的状态,监督就会变弱。
- 纯任务 RL:学生自己探索,但通常只有答案对错、单测通过率等序列级稀疏奖励,信用分配困难。
- OPD:学生自己探索,教师在学生的状态上给出逐 token 的密集方向。任务 reward 可以叠加,但不是 OPD 的定义条件。
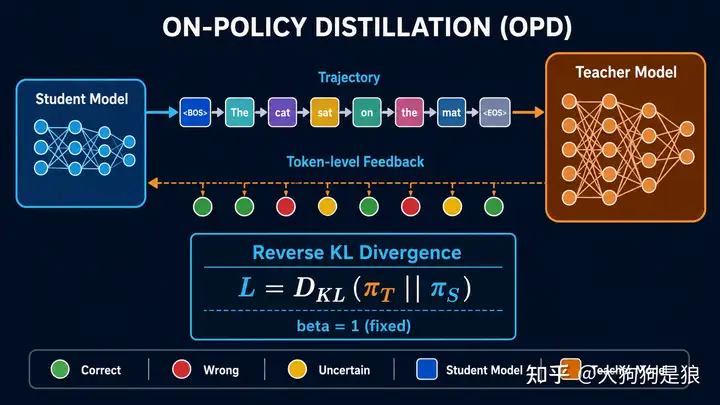
OPD 不是 top-k¶
On-policy 描述的是数据从哪里来,top-k 描述的是教师分布传多少。二者属于不同维度。工程上至少有三种信号粒度:
- 全词表分布:教师返回整个 vocabulary 的 logits,信息最完整,通信和显存成本最高。DeepSeek V4 报告明确使用 full-vocabulary reverse KL。13
- 教师 top-k 分布:仅传教师概率最大的 \(k\) 个 token,以较低成本近似分布 KL;
k=64是常见配置,但不是 OPD 原理。 - 学生采样 token 的 log-prob:教师只计算学生实际采到 token 的概率,用
k1、low_var_kl等估计 reverse KL,最省带宽但方差更高。verl 的loss_mode: k1走的是这条路径,配置中的topk: 64不生效。14
同理,OPD 与 KL 方向也不是同一件事。经典响应蒸馏通常在教师数据上最小化 teacher-to-student cross entropy;MiniLLM 则在学生生成序列上优化 reverse KL。9 现代框架还可以在 on-policy 数据上实现 sampled reverse KL 或 top-k forward KL。不能简单记成“SFT = forward KL、OPD = reverse KL”,更不能把 forward/reverse 写反。
OPD 也不等于 RLAIF
OPD 的教师是 token 分布提供者,不必充当语义裁判;训练可以直接反向传播蒸馏损失,也可以把蒸馏损失转成 policy-gradient advantage。任务 reward、GRPO 和 reward model 都是可选组合项。
有效性边界¶
“更强的大模型能否蒸馏更小的模型”要拆成两类条件。模型规模只影响潜在上限,并不保证知识可迁移。
硬约束¶
- 动作空间可比较:做 token-level KL 时,师生必须对同一个 token ID 表达同一个语义。不同 tokenizer 或词表不能直接比较 logits;需要统一 tokenizer、字符/字节级重映射,或退化为序列级蒸馏。当前 verl 会把学生
sequence_ids直接交给教师,因此实际上要求词表兼容。14 - 状态可重放:教师必须能够读取学生到达的前缀。多模态模型还要求 processor、音视频占位符、位置编码和输出协议兼容。
- 学生容量足够:小模型不可能无损容纳教师的全部能力;OPD 改善的是训练信号,不会消除容量上限。
软约束¶
- 思维模式兼容:师生在高概率 token 上需要有足够重叠,否则教师梯度会持续把学生推向它无法稳定表达的区域。
- 教师有新增知识:教师必须在目标提示词上提供学生尚未掌握、且可学习的知识。单纯 benchmark 更高不等于可迁移信息更多。
- 路由与初始化合理:多教师场景中,应把样本交给对应领域专家;同源 SFT 初始化或短暂的 off-policy warm-up 可以显著降低初始 KL。
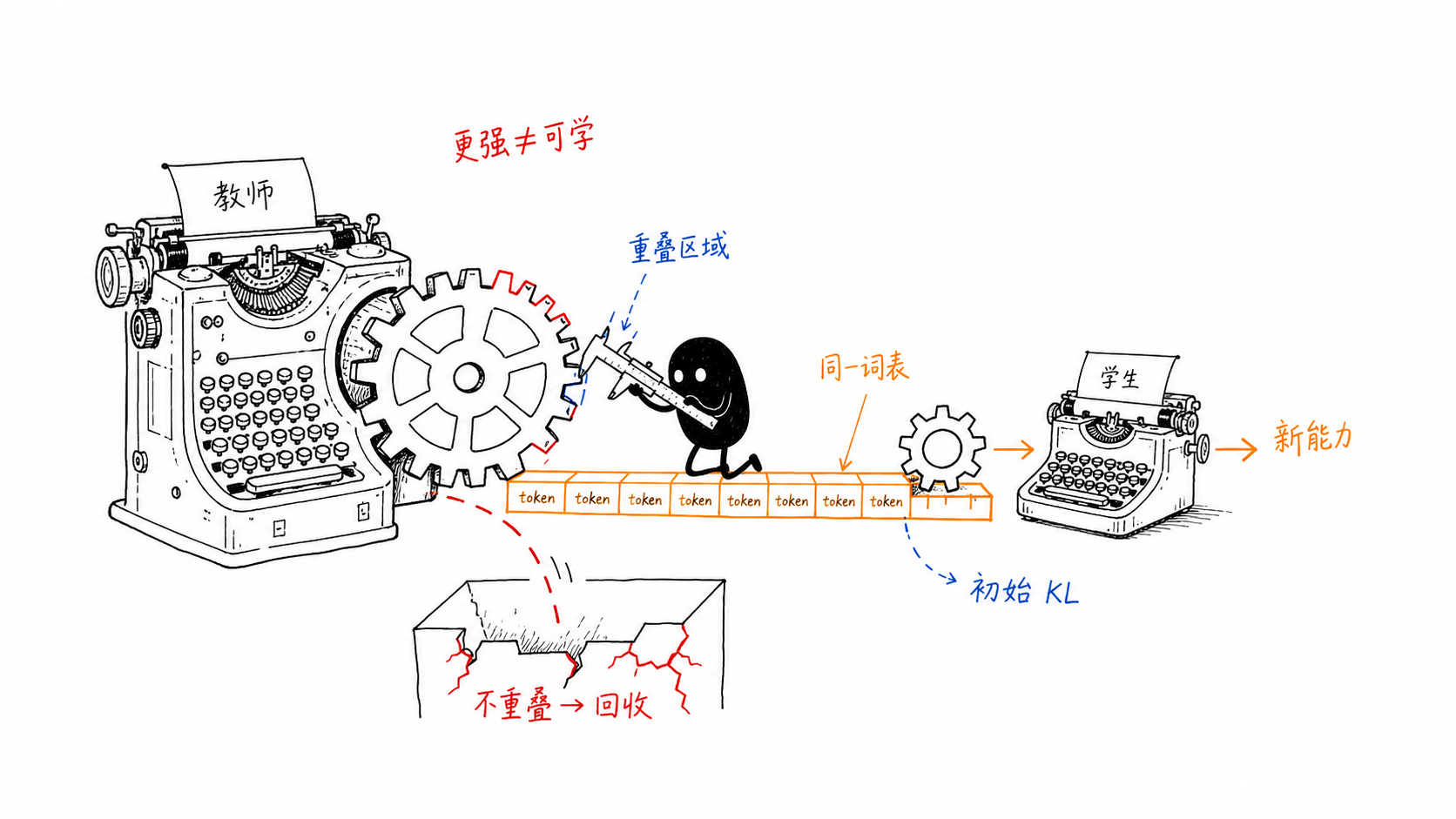
《Rethinking On-Policy Distillation》把失效机制概括为两个必要条件:thinking-pattern compatibility 与 genuine new knowledge。论文观察到,训练信号主要集中在师生共同的高概率 token 上,这部分 token 承载了约 97%–99% 的概率质量;如果重叠区域里没有新增知识,或者教师的推理模式与学生严重错位,参数量更大的教师也可能无效。10
“DeepSeek 蒸馏 Qwen 失败”的准确含义¶
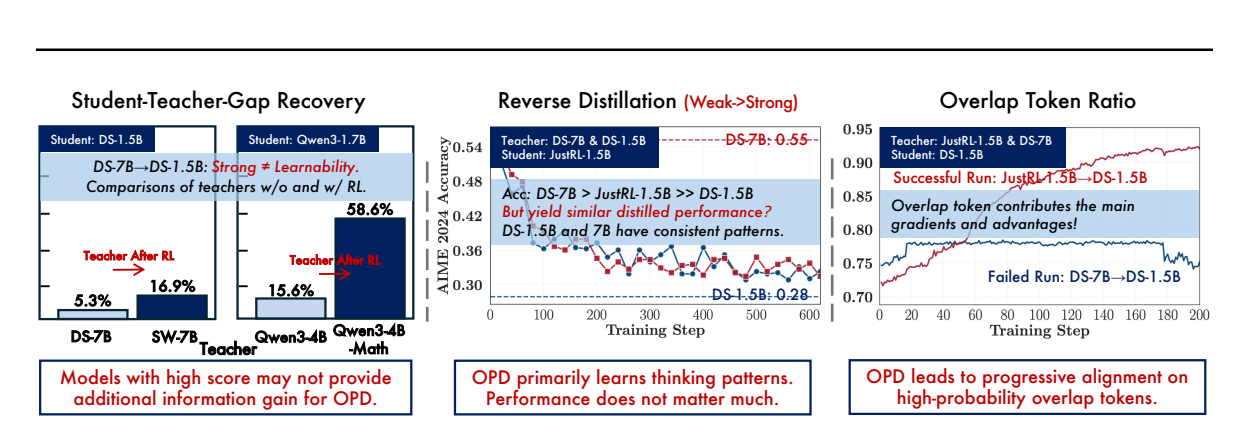
记忆中的案例不是因为 DeepSeek 与 Qwen 使用不同词表而水土不服。论文中的学生是 DeepSeek-R1-Distill-Qwen-1.5B,两个候选教师分别是同系列 DeepSeek-R1-Distill-Qwen-7B 和从相同 7B 起点继续数学 RL 的 Skywork-OR1-Math-7B;它们都建立在 Qwen tokenizer 上。
实验中,前一个更强教师只能恢复约 5.3% 的师生能力差距,后一个教师可恢复约 16.9%。这说明主要问题是教师与学生的策略/思维模式错位,以及可迁移新增知识不足,而不是 token ID 无法对齐。反向实验甚至出现 7B 学生被 1.5B 教师拉低的现象,进一步说明“教师 benchmark 更高”不是充分条件。10
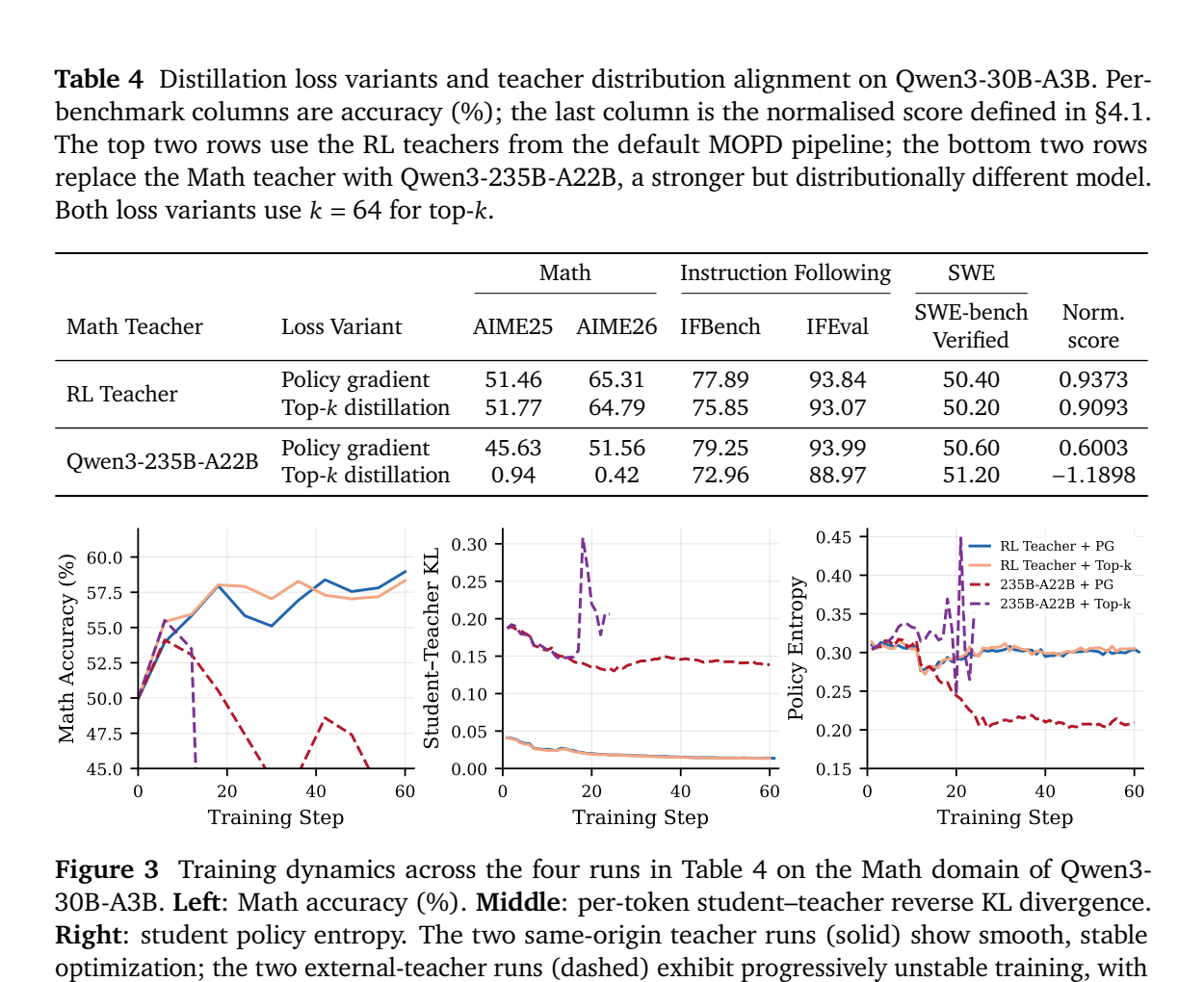
MOPD 论文给出了更直接的对照:将同源的 Qwen3-30B-A3B 数学专家换成外部 Qwen3-235B-A22B 后,初始 token KL 从约 0.04 升到 0.19,PG-OPD 的归一化得分从 0.9373 降到 0.6003,top-k 版本则从 0.9093 降到 -1.1898 并在约第 18 步崩溃。top-k 不能修复策略不兼容。11
失效时的处理顺序
- 先确认 tokenizer、chat template 和多模态 processor 完全一致;
- 再测训练前的 per-token KL、top-probability overlap 与学生熵,而不是只看教师榜单分数;
- 用 teacher-generated response 做短暂的 off-policy cold start;
- 过滤出 teacher-aligned prompts,或换成从同一 SFT checkpoint 训练出的领域专家;
- 最后才调
topk、clamp、loss coefficient 等优化超参。
工业模型流程¶
公开材料中的“OPD”并不是同一套配方。下表只写官方报告明确披露的内容,未披露处不做推断。
| 模型 | 教师来源 | 学生与教师关系 | 在线阶段 | 信号粒度 |
|---|---|---|---|---|
| DeepSeek V4 | 数学、代码、Agent、指令遵循等十余个领域专家 | 同一模型体系内先独立 SFT + GRPO,再合并到统一学生 | 学生 rollout,按样本选择对应专家 | 全词表 reverse KL |
| Qwen3 | Qwen3-32B 或 Qwen3-235B-A22B | 大模型蒸馏到 0.6B–30B-A3B 小模型 | 先离线模仿 /think 与 /no_think 输出,再在学生响应上对齐教师 logits |
报告写 KL/logits 对齐,未披露 top-k |
| Qwen3.5 | 未公开完整 OPD recipe | 未公开 | 官方模型卡只披露通用后训练与大规模 RL | 不能由 Qwen3 流程外推 |
| Qwen3.5-Omni | 同一 Qwen3.5 base 派生的文本、视觉、音频领域专家 | 先整合到统一 Thinker,再做跨模态自蒸馏 | 用文本条件生成更优回答,再作为音频条件样本的目标 | 报告未披露 logits、KL 或 top-k |
DeepSeek V4:同源多专家合版¶
DeepSeek V4 的重点不是“大尺寸蒸馏小尺寸”,而是把同一底座分化出的多个领域策略重新合成一个统一模型:
- 各领域专家分别进行领域 SFT 和 GRPO;
- 统一学生在混合数据上生成自己的轨迹;
- 根据样本领域选择相应专家,在学生前缀上做 full-vocabulary reverse KL;
- 通过教师权重卸载、缓存最后隐藏状态、按教师重排样本和异步加载,缓解十余个教师的显存与切换成本。13
这与 MOPD 的思想一致:多个同源专家分别探索,再蒸馏回一个学生。报告没有证明任意外部大模型都适合作为教师,也没有把核心流程描述为异构词表的大到小压缩。
Qwen3:明确的大到小蒸馏¶
Qwen3 技术报告披露的小模型训练包含两个阶段:先使用强教师生成的 thinking/non-thinking 响应进行 off-policy 蒸馏,再让小模型自己生成响应,并对齐 Qwen3-32B 或 Qwen3-235B-A22B 的 logits。目标覆盖 0.6B、1.7B、4B、8B、14B 和 30B-A3B,因此这是明确的大尺寸到小尺寸压缩。12
Qwen3.5:公开信息不足¶
截至 2026-07-21,Qwen3.5 官方模型卡没有给出可复现的 OPD 数据流、教师列表和 KL 形式。verl 仓库存在 Qwen3.5-4B student + Qwen3.5-35B-A3B teacher 示例,只能证明框架能够跑这种配置,不能反推 Qwen3.5 官方就是这样训练的。1416
Qwen3.5-Omni:专家整合与跨模态自蒸馏¶
Qwen3.5-Omni 的 Thinker 训练分为三步:
- 领域专家蒸馏:从同一个 Qwen3.5 base 派生文本、视觉、音频专家,分别 SFT + RL;用专家生成的数据合并为统一模型。
- 跨模态 OPD:对同一问题构造 audio/text 配对输入,先在文本条件下生成质量更高的回答,再把它作为音频条件回答的训练目标,使音频推理向文本推理对齐。
- 交互式 RL:继续优化复杂的视觉、音频和 Agent 交互任务。15
这里的第二步被报告称为 OPD,但公开描述更接近跨模态自蒸馏;报告没有说明使用 full logits、top-k 还是 sampled-token KL。Talker 则有独立的多阶段语音生成流程,不能默认沿用 Thinker 的 token KL。
verl 能力地图¶
以下能力图以 verl a07d3e3(2026-07-21)与 verl-omni 04259f6(2026-07-18)的代码为准。绿色表示已有可运行链路,黄色表示有基础组件但缺少完整 OPD 闭环,红色表示面向 Qwen3.5-Omni 全量目标仍需新增。1417
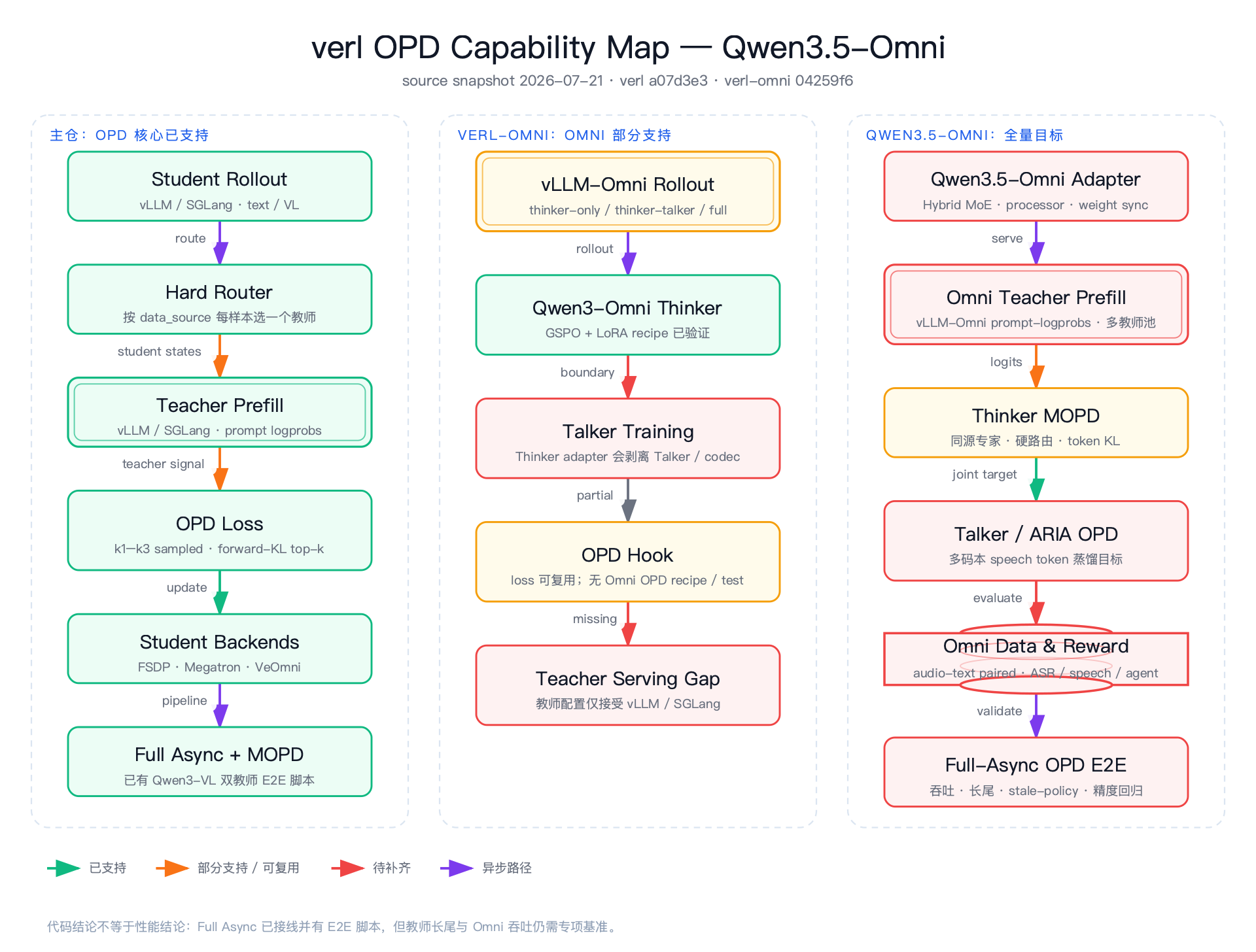
当前支持¶
| 层次 | verl main | verl-omni | 判断 |
|---|---|---|---|
| 学生训练 | FSDP、Megatron、VeOmni;PG 或直接蒸馏回传 | Qwen3-Omni Thinker 的 GSPO + LoRA | 文本/视觉 OPD 成熟;Omni 仅有训练基础 |
| 教师推理 | vLLM、SGLang;可传 image/video/audio 输入 | rollout 支持 thinker_only、thinker_talker、full |
教师配置尚不接受 vLLM-Omni engine |
| 蒸馏损失 | forward_kl_topk、k1、low_var_kl、mse 等;任务 reward 可选 |
复用 verl loss plumbing | 算法积木已有 |
| 多教师 | teacher_key 硬路由;每个样本选择一个教师 |
没有 Omni OPD 示例与 E2E test | MOPD 主干已有,Omni 闭环缺失 |
| 异步流水 | 多资源池、独立 teacher worker、full-async OPD E2E | Omni rollout engine 已有 | 可异步重叠,但不能消除 teacher prefill |
| Talker | 不覆盖 ARIA 多码本语音目标 | Thinker adapter 会显式移除 talker、code2wav、code_predictor |
全量 Omni OPD 的主要红区 |
verl 当前的 MOPD 是硬路由 + 现有蒸馏损失,而不是每个样本同时融合多个教师分布。典型流程是:
- 从同一个 SFT checkpoint 出发,在数学、代码、Agent 等数据集上分别做 RL,得到领域专家;
- 学生同样从该 SFT checkpoint 初始化,在混合数据上 rollout;
- 根据
teacher_key或默认的data_source把每个样本交给一个专家,再做 sampled reverse KL 或 top-k KL。1114
这套算法没有要求教师比学生更大,反而强调同源初始化与策略接近。若数据集路由已经明确,MOPD 本身不依赖一个额外的 learned router;若单个 prompt 同时跨多个领域,才需要软路由、动态专家选择或同样本多教师融合,而这些并非 verl 当前默认能力。
多教师空泡与 full async¶
多教师的空泡同时来自调度和算法:
- 静态资源切分:每位教师拥有固定 worker pool;不同数据集数量、序列长度和推理成本不均时,冷门教师空闲、热门教师排队。
- 批次长尾:普通 async 可以重叠 student rollout 与 teacher prefill,但同步 batch 仍要等待最慢教师。
- 必要依赖:精确 OPD 必须先得到教师在学生前缀上的分布,样本才能完成 loss 计算。verl 的 full-async 路径也要在单样本进入 ready queue 前
await teacher_logprobs。 - 陈旧度:如果为了消除等待而复用旧教师分数或先更新学生,训练就不再是严格的当前策略 OPD,会引入 staleness/off-policy 偏差。
可以上 full async,而且 verl main 已有多教师 full-async E2E 配置。它让已经完成 rollout、reward 和 teacher scoring 的样本先进入训练,消除全局 batch barrier;但它只能隐藏教师计算,不能删除教师 prefill 这条单样本关键路径。进一步优化应优先做按领域分桶、动态副本数、长度感知调度、相近教师合批,以及限制 student policy staleness,而不是把问题只归因于 KL 算法。
Qwen3.5-Omni 的目标缺口¶
若目标是蒸馏一个高性能 Qwen3.5-Omni,建议分三阶段推进:
- P0:Thinker-only 文本/视觉 OPD
- 复用 Qwen3-Omni Thinker adapter 与现有 OPD loss;
- 先选择同 tokenizer、同 chat template、同源训练的领域教师;
- 补齐 Qwen3-Omni OPD recipe、精度测试、full-async 性能测试。
- P1:Qwen3.5-Omni Thinker 闭环
- 新增 Qwen3.5-Omni Hybrid-MoE adapter、processor 和权重同步;
- 让 vLLM-Omni teacher 返回 prompt token logprobs/top-k,而不仅是生成结果;
- 建立 audio/text paired data、不同数据集的 reward/verifier 与 teacher route。
- P2:Thinker + Talker 全量 OPD
- 为 Talker 的 ARIA、多码本 speech token 设计可比较的蒸馏目标;
- 覆盖
talker、code2wav、code_predictor的训练与权重同步; - 增加语音自然度、说话人一致性、音画同步和交互式 Agent 的端到端评测。
近期最现实的范围
当前最可行的是 Qwen3-Omni Thinker-only、同源多专家、硬路由、sampled reverse KL、full async。要宣称“高性能 Qwen3.5-Omni 全量 OPD”,还必须补齐 Omni teacher logprobs、Talker/ARIA 目标、跨模态数据与奖励,以及端到端回归测试;仅有教师生成与 GRPO 不等于完成 OPD。
生成模型中的 OPD¶
OPD in DiT-Models¶
多教师 OPD 来整合不同领域专家模型的能力,相比混合奖励强化学习收敛更快、效果更好。
DeepSeek-V4 和 GLM5 等模型成功启发了我们进行一种另外的尝试:多教师 OPD 合版。通过学生模型的在线 rollout 和教师模型的稠密奖励巧妙解决了多任务的梯度冲突。
在流匹配模型的后训练对齐中,核心问题在于模型无法同时兼顾多个异构的对齐任务,陷入了严重的「跷跷板效应」。猛犸模型的danceGRPO就遇到了
单奖励 GRPO 虽然能在孤立的单目标任务中让模型逼近性能天花板,但会导致非目标领域的对齐能力发生严重退化,引发「奖励黑客」行为,如上图所示,使用 GenEval 进行强化学习训练的模型无法成功完成文字渲染和风格化生成任务;
混合奖励 GRPO 试图通过简单堆叠或混合多个标量奖励函数来进行联合优化,却根本无法建立稳定的认知基础,每当引入新的奖励信号时,就会引发此前已习得能力的灾难性遗忘与参数吞噬。如下表所示,每当有新的奖励模型加入训练,模型进行基础视觉生成和文本渲染的能力都会下降。
联合多任务 RL (Joint Multi-Task Optimization) :使用现有的 RL 算法例如 DiffusionNFT, GRPO 去联合优化多个任务。这种范式会撞上两个问题: 1 奖励冲突:不同任务的优化⽅向往往存在相互干扰; 2 任务失衡:简单任务会主导训练过程,导致复杂任务难以充分学习。
级联 RL (Cascade RL):按阶段依次训练不同任务。虽然能够缓解任务冲突,但是训练流程复杂,需要分别调整各阶段的超参数与训练策略,而且容易产生灾难性遗忘,后续任务训练的时候会削弱已有能力。
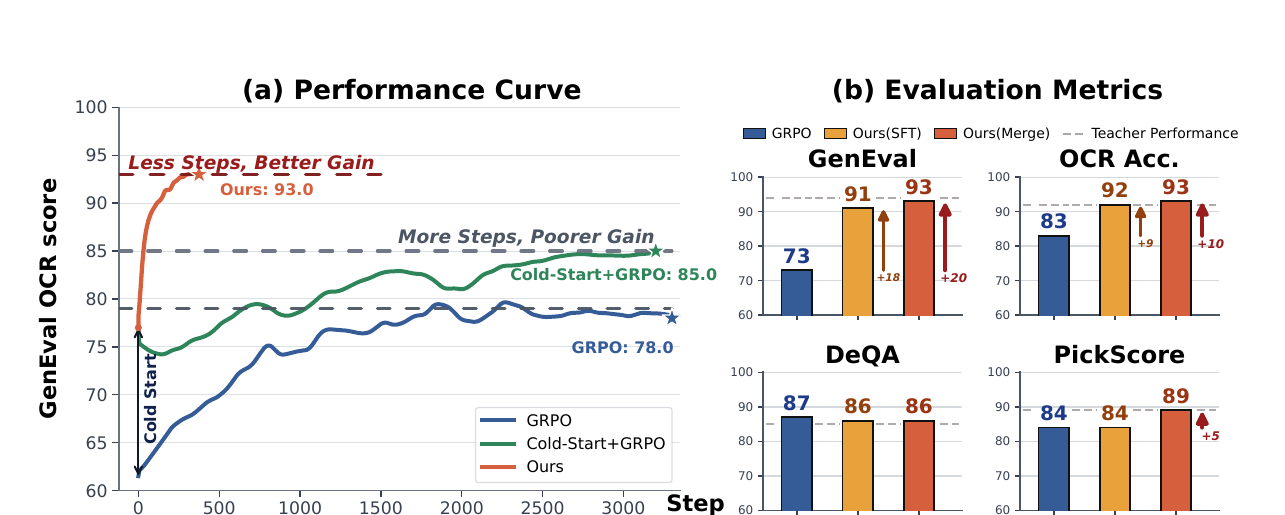
Flow-OPD13 的关键判断是:直接用单一奖励做 RL 会在多任务指标之间互相牵扯,而冷启动 + 多教师 on-policy distillation 能把探索收益转成更均衡的密集监督。论文 Figure 1 用训练曲线和四项指标概括了这个逻辑:
Flow-OPD 的训练流程可以拆成三步:
- 首先通过单奖励 GRPO 培养对应任务的教师;
- 对学生模型进行冷启动,这里包含两种冷启动策略,分别是监督微调 SFT 和模型融合。冷启动赋予了较高的初始表现,可以促使学生模仿教师的生成模式,从而快速收敛;
- 多教师 OPD 蒸馏:Flow-OPD 的核心思想是让学生模型通过「实践」暴露自身的错误与偏差,并在自己生成的图像路径上,实时接受不同专家教师的精准指引。
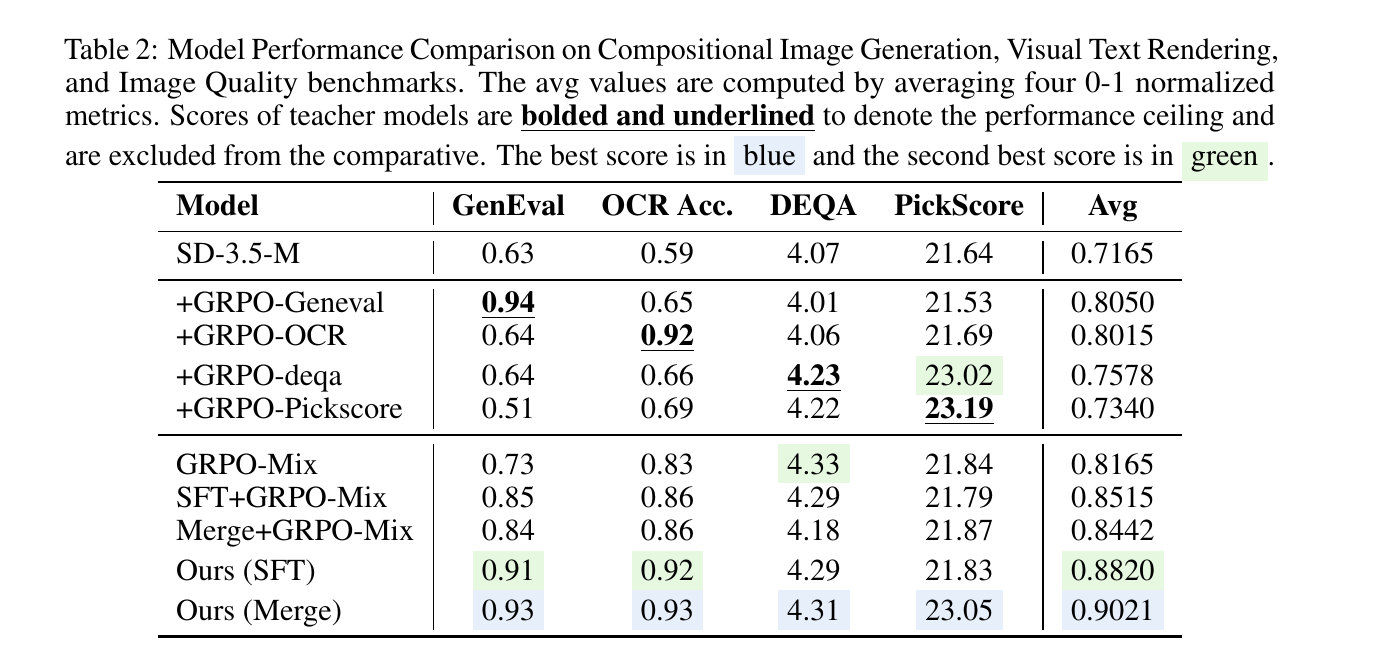
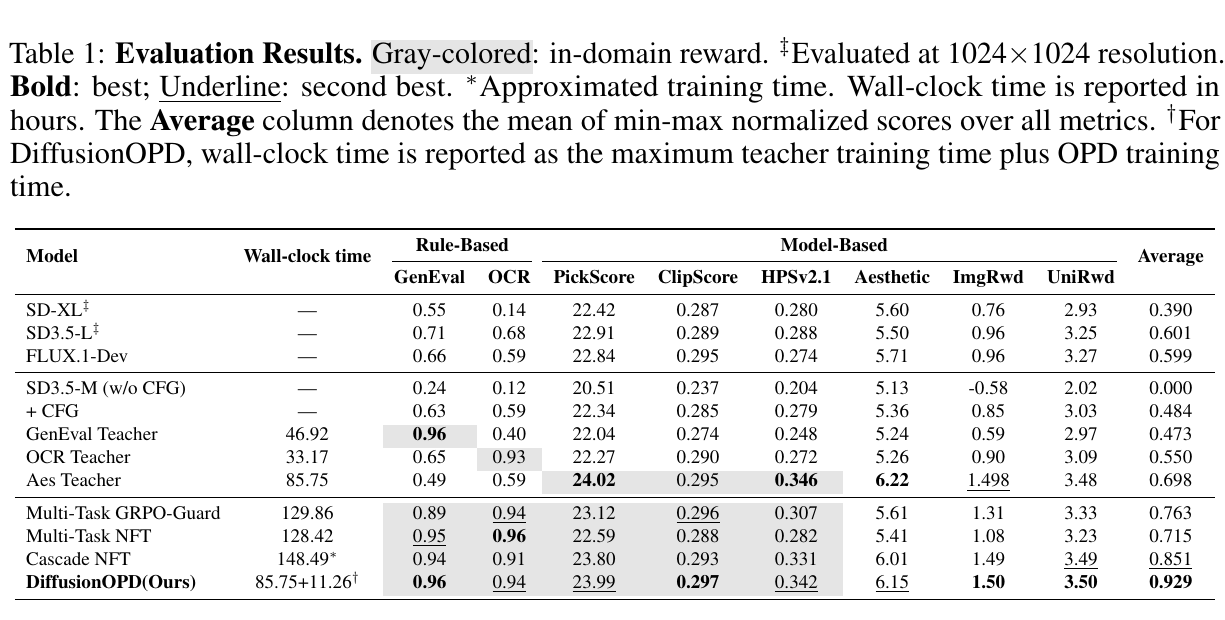
DiffusionOPD24 把这一思路写成更直接的两阶段算法:先针对不同任务分别训练各自的「专家教师」模型;随后,再通过在线策略蒸馏,将这些教师模型的能力统一蒸馏到同一个学生模型中,实现多任务能力整合。最终,一个统一的 student model 便能够同时兼顾构图、OCR、美学等多项能力。

DanceOPD¶
DanceOPD5678 可以看成把「多教师 OPD」继续往底层推了一层:不要先在数据比例、loss 权重或模型参数上混合能力,而是把每一种能力看成共享 flow state space 里的一个 velocity field。文生图、局部编辑、全局编辑、真实感增强,甚至 CFG 这种推理时 guidance operator,都可以被写成「在当前状态下下一步该往哪走」的速度场。
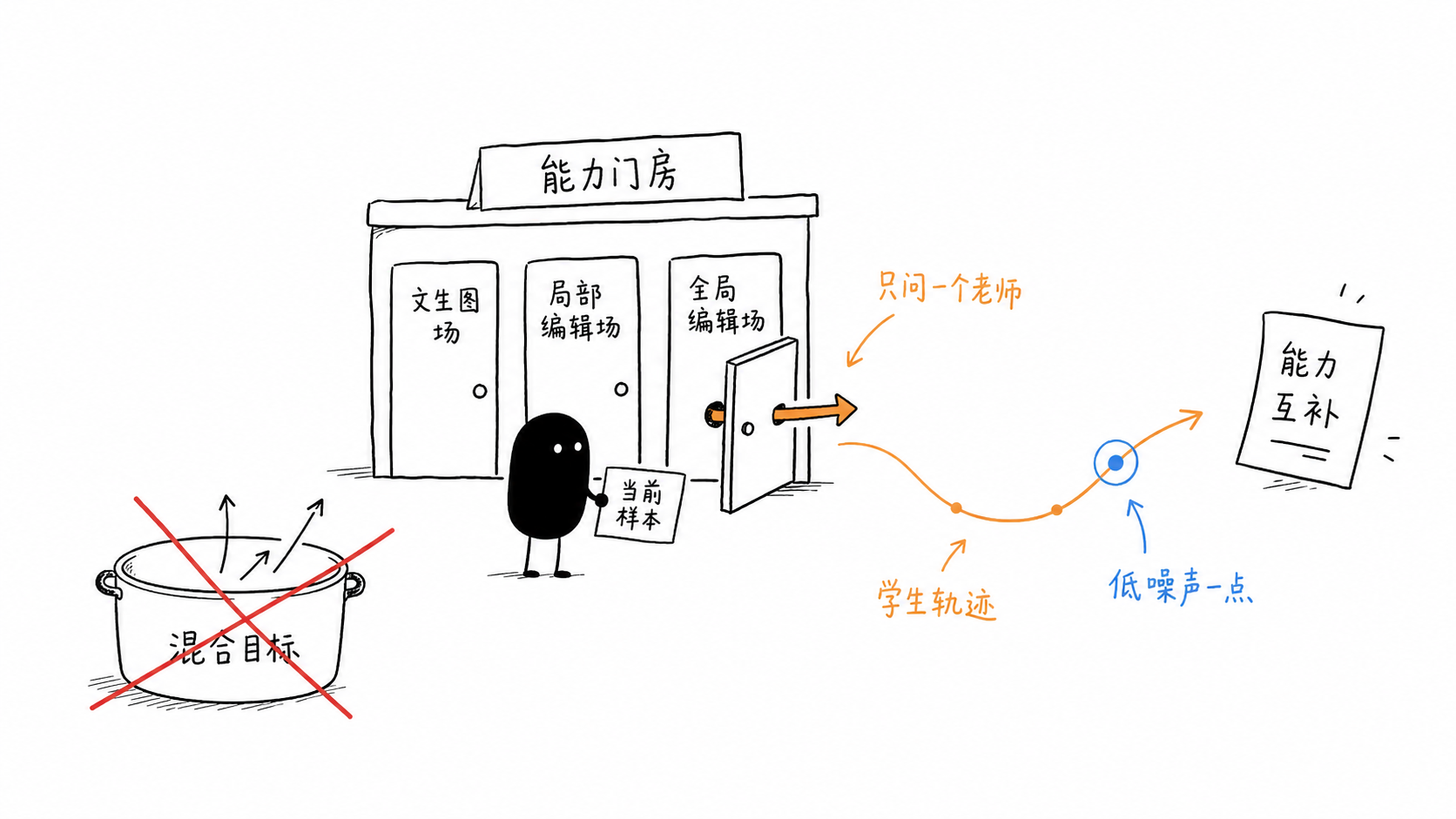
论文把 DanceOPD 的训练步骤压得很简单:
- Hard routing:每个样本只路由到一个能力场。例如纯文生图样本问 T2I teacher,局部编辑样本问 local edit teacher,全局编辑样本问 global edit teacher。
- On-policy query:先让当前 student 自己 rollout,取 student 实际访问的中间状态,而不是 teacher trajectory、data state 或固定 off-policy state。
- Semantic-side single query:一条轨迹只取一个偏低噪声、靠近语义侧的 query point,避免同一 rollout 上多个高度相关状态反复放大同一方向。
- Velocity MSE:在这个 stop-gradient state 上,让 student velocity 直接回归 routed teacher velocity。
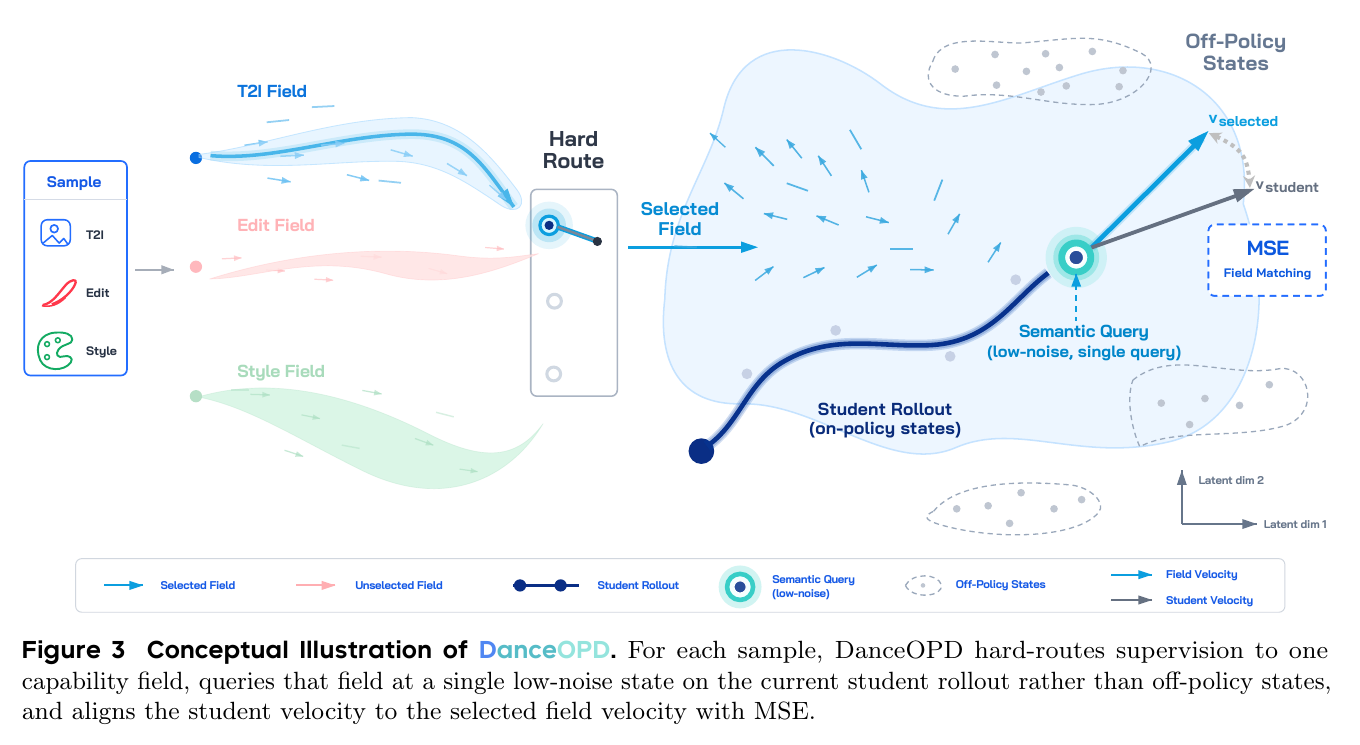
这也解释了为什么 DanceOPD 比之前的 OPD 变体更稳。DiffusionOPD 已经把 on-policy velocity matching 引入扩散模型;Flow-OPD 则用 dense scalar reward 和 PPO-style 更新来做 flow matching OPD。但 DanceOPD 进一步把 OPD 的失败源拆成三个更具体的问题:
- 目标场混淆:soft teacher mixing 会把几个 teacher field 平均成一个没有清晰语义身份的方向;DanceOPD 的 hard routing 保留「这个样本到底该学哪个能力」。
- 状态分布错位:off-policy distillation 可能在 teacher 或静态数据状态上问老师,但部署时 student 访问的是自己的状态;DanceOPD 在 student-induced state 上查询老师。
- 轨迹查询相关性:dense trajectory supervision 看起来信息更多,但同一条 rollout 上的状态共享 prompt、初始噪声、学生动力学和路径历史,梯度并不独立;DanceOPD 只取一个低噪声 query。
为什么低噪声单点反而更强
对图像编辑和风格吸收来说,高噪声状态更像全局结构和通用去噪,低噪声状态更接近最终图像,承载更多材质、属性、风格和局部细节。DanceOPD 不是少学,而是把 teacher query 放在信号密度更高、相关性更低的位置。
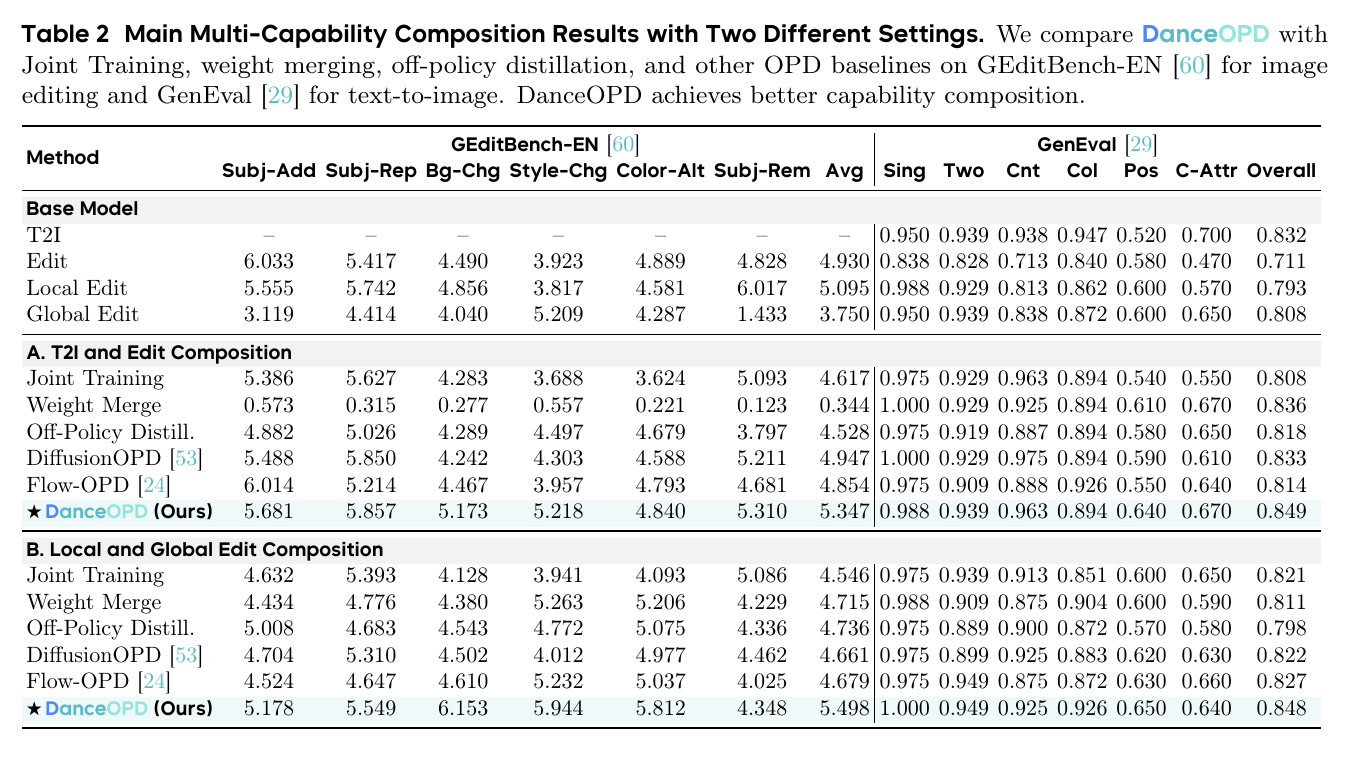
主实验也支持这个判断。Table 2 里,T2I + Edit 组合中 DanceOPD 的 GEditBench Avg 达到 5.347,GenEval Overall 达到 0.849;Local + Global Edit 组合中 GEditBench Avg 达到 5.498,GenEval Overall 达到 0.848。也就是说,目标编辑能力上去了,文生图 anchor 没有塌。
几个消融更能说明「为什么更好」:
- Hard routing vs soft mixing:hard-routed MSE 的 GEditBench Avg 比 soft-teacher MSE 高
15.2%;即使用 KL-style 目标,hard routing 仍高10.6%。 - Low-noise query vs median/high-noise query:low-noise semantic-side query 分别比 median- 和 high-noise query 高
23.7%与19.5%。 - Single query vs dense query:same-step accumulation 已经会让平均分下降;叠加 dense supervision 后下降可达
22.8%。SDE rollout 能把压力设置从4.437拉回5.255,但仍比默认单点低8.6%。 - Plain MSE vs weighted variants:论文报告 plain velocity MSE 比 KL weighting、timestep weighting、DMD/SDS/consistency-style surrogate 等加权替代方案高
2.8%到4.5%。
工程上要注意两个边界:
- 共享 field 假设不是免费的。DanceOPD 要求 frozen sources 在同一个生成状态空间里暴露兼容 velocity field。论文实验成立,是因为来源共享 backbone family、latent representation、scheduler convention 和 velocity parameterization。
- 路由身份仍然需要定义。论文里的 T2I、local edit、global edit、style、guidance 等能力桶比较清楚;真实用户 prompt 可能同时包含多个意图,后续可能需要 verifier、reward model 或动态 router 来决定该问哪个场。
当前 GitHub 仓库已经公开训练代码、smoke tests、数据适配器和 SD3.5 / Z-Image backend 模板;但 README 也明确说明,内部 teacher LoRA 和 student checkpoint 不随仓库发布。也就是说,DanceOPD 更像一个同底座多专家后训练 recipe:如果团队已经有同一模型家族下的 T2I、edit、style、quality teacher,它给出了一个比混数据、混权重、混 teacher 输出更清楚的合成路径。
近期还有几条强相关路线
- D-OPSD:面向 few-step 扩散模型的 on-policy self-distill(不依赖外部奖励器)。
- AnyFlow:视频生成方向的 on-policy flow-map distillation(any-step)。
- CollectionLoRA:多教师 OPD,把多效果 LoRA 蒸到一个 LoRA(编辑场景)。
- RTDMD(严格说不是纯 OPD):把 DMD + GRPO 融合,论文里报告很强,工程化也比较完整。