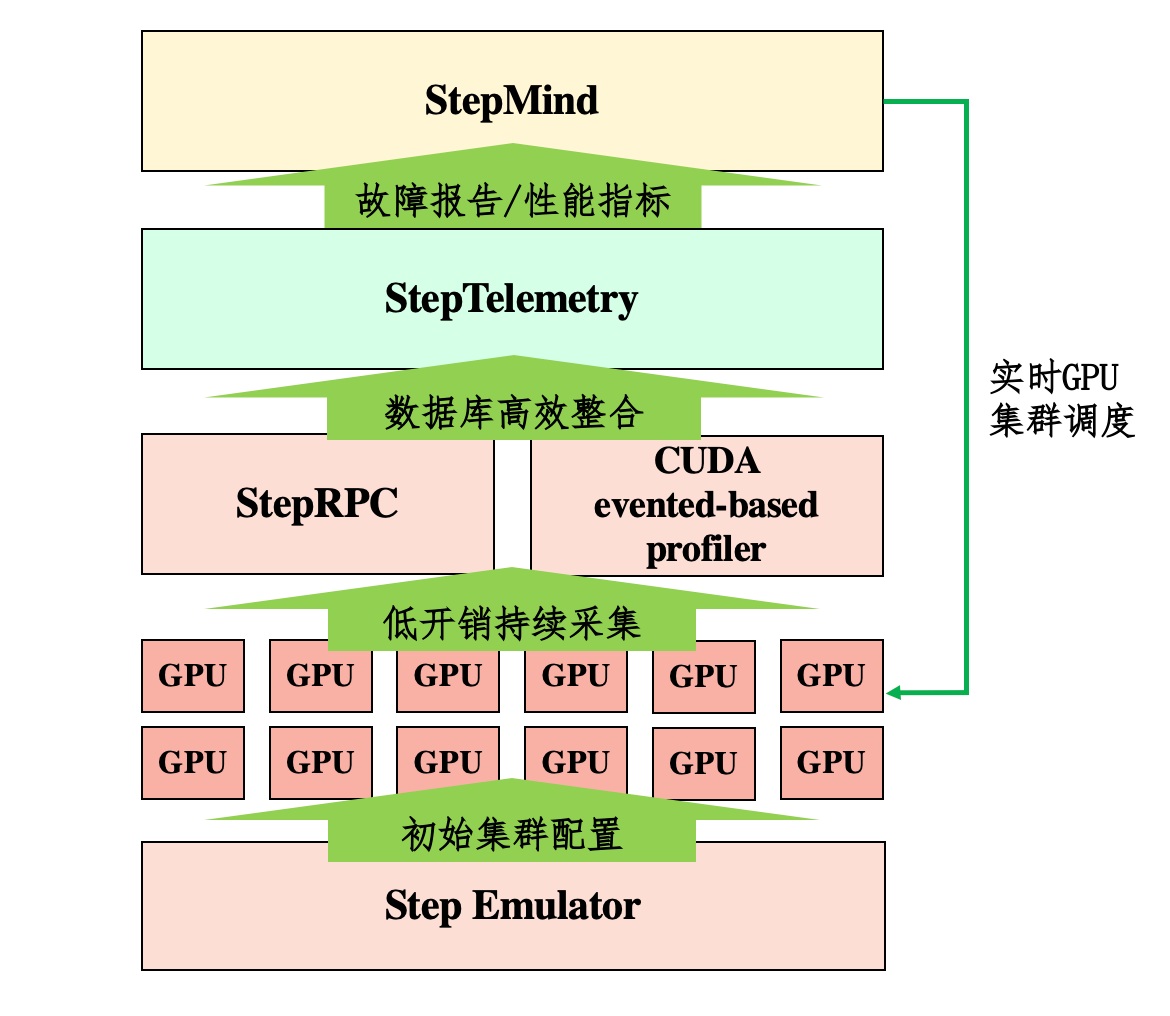
AI Traning System
导言
Step-Video论文详细介绍了AI 系统的一些构建细节。

- Step Emulator: 根据模型结构和超参静态推演出最佳的资源规划和并行策略。
- StepMind:针对大规模GPU集群调度自研的调度平台
- StepRPC: 自研的集成TCP和RDMA协议,实现高效的跨集群通信。
- StepTelemetry:跨集群监控平台,用于细粒度(iteration-level)实时监控集群状态和性能。
VAE与DiT分离训练和推理
Github的推理代码显示,推理时,vae加载是通过本地端口加载:
class StepVideoPipeline(DiffusionPipeline):
def __init__(
self,
# ...
vae_url: str = '127.0.0.1',
caption_url: str = '127.0.0.1',
):
super().__init__()
# ...
self.vae_url = vae_url
self.caption_url = caption_url
self.setup_api(self.vae_url, self.caption_url)
def setup_api(self, vae_url, caption_url):
self.vae_url = vae_url
self.caption_url = caption_url
self.caption = call_api_gen(caption_url, 'caption')
self.vae = call_api_gen(vae_url, 'vae')
return self
# ...
def decode_vae(self, samples):
samples = asyncio.run(self.vae(samples.cpu()))
return samples
def call_api_gen(url, api, port=8080):
url =f"http://{url}:{port}/{api}-api"
import aiohttp
async def _fn(samples, *args, **kwargs):
if api=='vae':
data = {
"samples": samples,
}
elif api == 'caption':
data = {
"prompts": samples,
}
else:
raise Exception(f"Not supported api: {api}...")
async with aiohttp.ClientSession() as sess:
data_bytes = pickle.dumps(data)
async with sess.get(url, data=data_bytes, timeout=12000) as response:
result = bytearray()
while not response.content.at_eof():
chunk = await response.content.read(1024)
result += chunk
response_data = pickle.loads(result)
return response_data
return _fn
Step Emulator¶
- 资源与性能预估 SEMU通过模拟不同模型架构(如层数、注意力头配置)和并行策略(如Tensor/Sequence/Pipeline并行),预测训练时的资源消耗(如GPU内存、计算时间)和性能指标(如模型计算利用率MFU),帮助确定最优配置。
技术优势
- 降低试错成本:避免在大规模集群上直接实验,节省时间和计算资源。
- 系统级优化:通过模拟选择简化的并行策略(如放弃复杂的Pipeline Parallelism),提升训练框架的鲁棒性,减少节点间通信延迟的影响。
实际应用
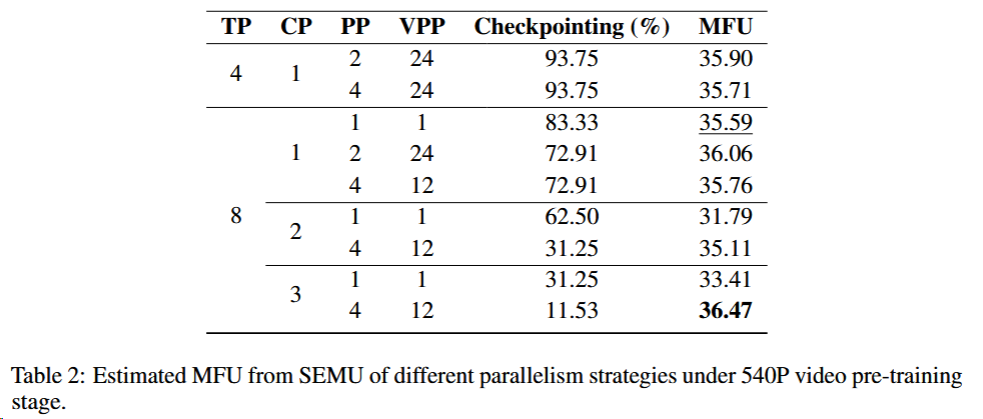
在视频生成模型训练中,SEMU分析多种并行组合(如TP+SP+PP)的Model Flops Utilization (MFU).表现。如图模拟发现,结合8-way Tensor Parallelism与Sequence Parallelism的配置虽略逊于理论最优,但更易维护,最终实现32%的实际MFU。
分布式并行策略:TP+SP+Zero1¶
如表前5行,单纯在张量并行(TP)基础上叠加流水线并行(PP)并不能获得较高的MFU, 原因在于:
- 在8路TP后,PP仅能减少约20GB的模型参数和梯度内存(原总内存需求较高)
- 面对120GB的激活内存(存储中间计算结果的内存),PP只能大量使用激活检查点方法(一种通过重计算节省内存的技术,如表70%以上)来节约内存,但是这会导致训练变慢。
为此引入CP来直接降低激活内存,但其通过网卡(NIC)的通信成本与TP通过NVLink的通信开销相当。为优化CP效率:
- 在自注意力模块采用头部分组CP(head-wise CP)(加速DiT模型的多头注意力模块)
- 在交叉注意力模块采用序列分组CP(sequence-wise CP)(因prompt的k/v序列较短)
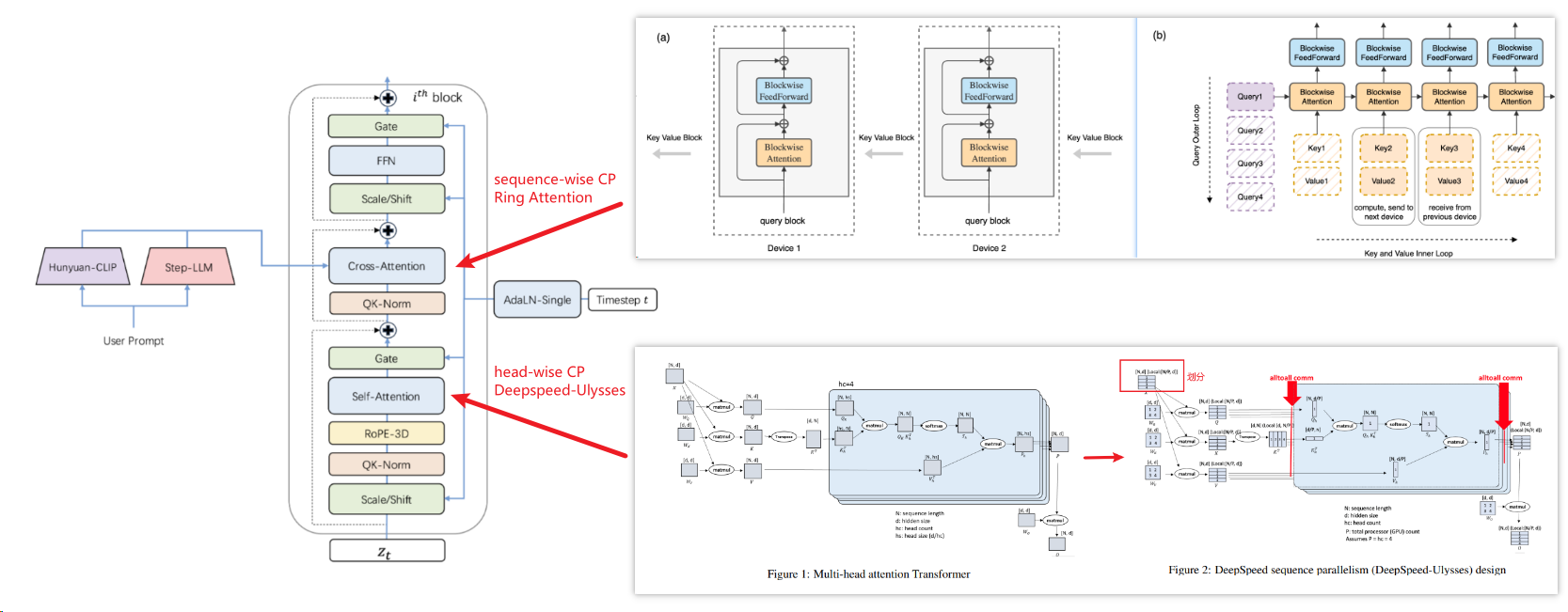
尽管进行了这些CP优化,CP的通讯开销仍然显著,单独使用CP也无法实现高MFU。
- 为此我们应该结合TP+CP+PP。
- 然而,在大规模GPU集群训练中,为了确保系统鲁棒性并便于识别训练中的"掉队节点"(Stragglers),后端框架需尽可能简化。
- 缺乏灵活性:PP需精细划分层数,调试难度大(如Bubble比例控制)。
- 收益有限:在8路TP后,PP仅能减少约20GB参数内存,对120GB激活内存改善有限。
- 为此放弃PP。
- 作为折中方案,我们采用了8路张量并行(TP)结合序列并行(SP)和Zero1优化策略。
- 此配置的MFU比理论最优值仅低0.88%。实际训练中,由于性能指标收集开销和少量掉队节点造成的延迟,实际MFU达到32%,略低于预估水平。
TP overlap¶
- 背景:通讯瓶颈:在标准TP实现中(如NCCL库),AllReduce操作需要SM参与数据搬运,导致通信期间SM被占用,无法同时执行计算任务(如GEMM)。
- 改进:自研StepCCL集合通信库,实现了先进的通信-计算重叠技术。StepCCL直接调用GPU的DMA(直接内存访问)引擎进行数据传输,完全绕过流式多处理器(SMs)。这种设计使得StepCCL的通信操作与GEMM(通用矩阵乘)计算能够在同一GPU上真正并行执行,两者互不干扰性能,从而最大化硬件利用率和计算吞吐量。

DP overlap¶
- 背景:在分阶段训练的前几个阶段,激活内存尚未成为瓶颈。此时主要内存消耗来自模型参数。而性能瓶颈集中在数据并行(DP)引入的梯度归约分散(Reduce-Scatter)和参数全收集(All-Gather)操作,这些操作可占据超过30%的训练时间。
- 改进:通过延后和提前通讯操作,实现DP通信重叠技术:
- 前向阶段重叠:在首个微批次(Micro-Batch)的前向传播中执行参数All-Gather操作;
- 反向阶段重叠:梯度Reduce-Scatter与最后一个微批次的反向传播并行执行。
定制化计算与通信模块(多模态)¶
VAE计算¶
- 背景:PyTorch默认使用NCHW(批大小-通道-高度-宽度)张量格式,而GPU Tensor Core本质仅支持NHWC(批大小-高度-宽度-通道)格式,导致额外的格式转换开销
- 改进:在计算图起始处执行维度置换,将通道维度物理置于末尾,并修改计算图中的每个算子(如卷积、组归一化)适配通道末位格式
- 效果:最终实现VAE编码吞吐量最高提升7倍。
多GPU VAE加速¶
背景:为降低VAE延迟并支持长时高分辨率视频处理,需通过多GPU分摊单设备计算与内存压力。 改进:为卷积操作提供时间并行(Temporal Parallel)与空间并行(Spatial Parallel)两种策略:
时间并行
沿视频帧维度切分潜在表示,使每GPU仅处理部分帧。若下游卷积需跨帧计算,通过All-to-All通信传输重叠帧区域,其开销通常小于计算时间的1%。
DiT优化¶
- 原版RoPE实现因构建嵌入表和索引时需大量耗时的切片(Slice)与拼接(Concat)操作而效率低下。为此,我们开发了定制的RoPE-3D内核,用高效的嵌入计算替代索引操作,显著提升性能。
- DiT模型的Timestep Modulation会导致高激活内存占用(因时间步在序列长度上重复),而同一视频片段内时间步实际相同,此重复是冗余的。我们实现了一种内存高效调制操作:仅在正向传播时扩展时间步,反向传播时保存未扩展的原始时间步。
- 算子融合:为进一步降低内存成本,我们将LayerNorm操作与Timestep Modulation融合,消除中间结果的存储需求。
DP 负载均衡¶
- 背景:
- 视频生成任务需同时处理高分辨率视频(如204帧×256×256)与低分辨率图像(如1×256×256),两者单样本计算量差异可达38倍(1,717.20 vs 44.99 TFLOPs)。
- 若将不同分辨率数据分配至独立批次Batch(如视频与图像分批次训练),会导致:
- GPU利用率波动:高分辨率批次占满GPU算力,低分辨率批次空闲;
- 同步开销:数据并行(DP)中需全局同步梯度,长尾批次拖慢整体进度。
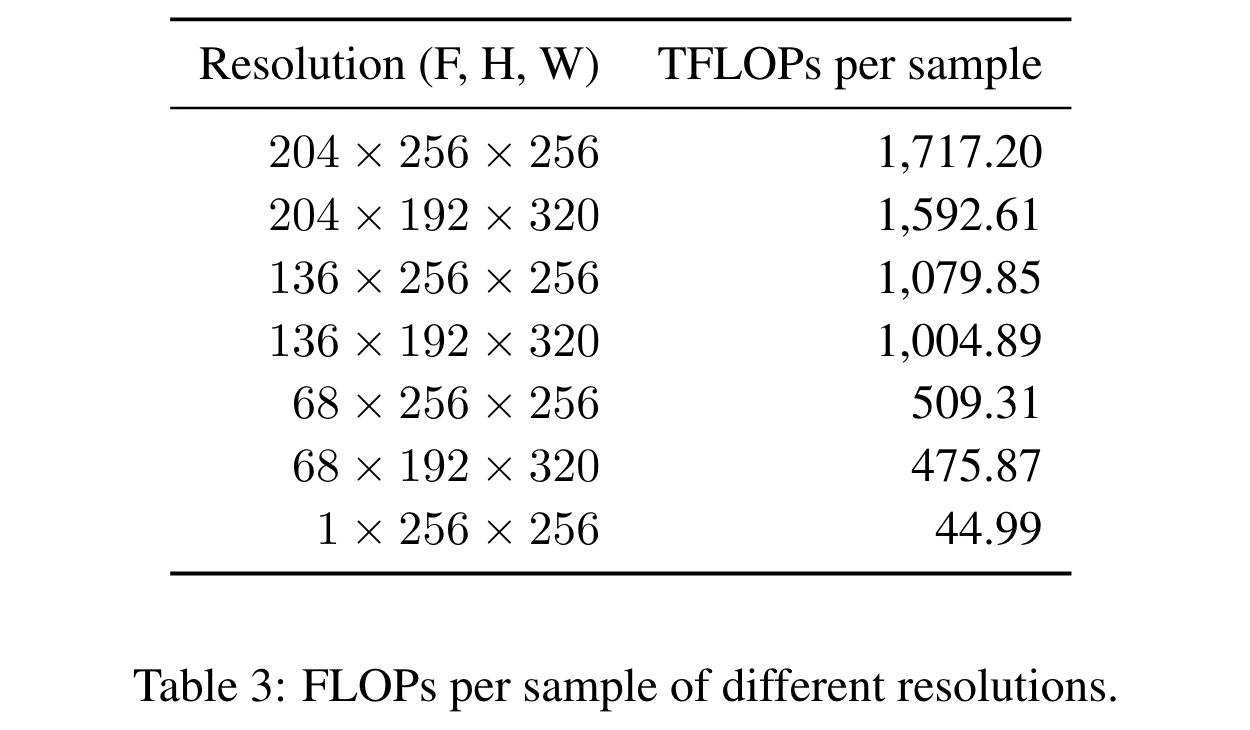
- 思想:对于低分辨率图像可以通过增大batch size使得一个batch的计算量和高分辨率视频的batch相当。
-
改进:
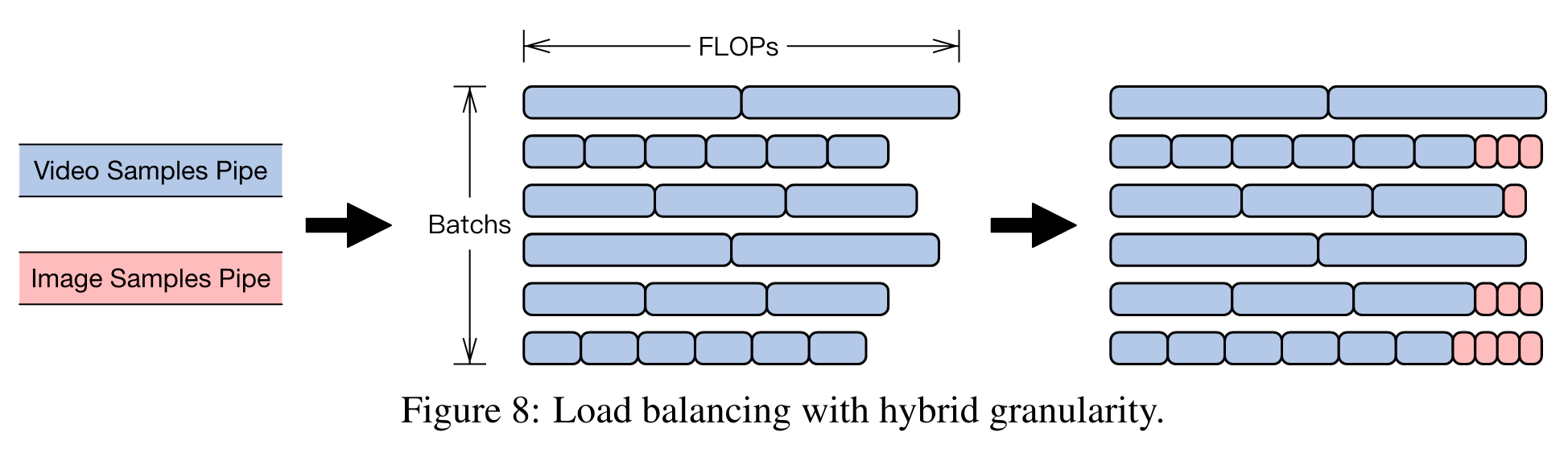
- 提出一种混合粒度的负载均衡策略(如图8所示),包含两个互补阶段:
-
粗粒度FLOPs对齐:通过调整不同分辨率视频的批次大小实现。对于每个分辨率r,计算其单样本FLOPs F_r,并通过公式优化批次大小B_r:
\[B_r = \frac{F_{\text{target}}}{\alpha F_r} \tag{12}\]- 其中,F_target 为目标批次FLOPs(通常取最高分辨率视频的批次FLOPs),α为归一化因子以确保全局批次大小一致。
-
细粒度图像填充:针对剩余的FLOPs差异,系统缓存N个视频批次,根据预设的视频-图像比例β计算需补充的图像数量,并通过贪心启发式算法将图像迭代分配至当前FLOPs最小的批次,直至完成填充。
StepMind¶
监控、评估、调度GPU集群。
全维度细粒度监控调度体系¶
构建了覆盖全维度的细粒度监控系统,可快速定位故障节点。该系统以秒级粒度采集硬件指标(CPU/GPU/内存/PCIe/网络/存储/电源/风扇等)与软件指标(操作系统栈),实现故障的快速全量检测。基于运维经验,故障节点可分为两类:
- 致命错误节点(占比约86.2%):直接中断训练进程。检测到此类节点后,立即替换健康节点并重启任务。为避免误报导致的错误重启,我们采用多信号联合验证机制,包括:RoCEv2网络流量中断;GPU功耗异常降低;训练日志更新停滞...确认为故障后立即重启任务,最大限度减少节点故障导致的停机时间。
- 非致命错误节点(占比约13.8%):虽不立即中断训练,但会降低效率(如单卡MFU下降15-30%)。此类节点检测难度高,需专用方法识别,通常安排在计划维护时段(如保存检查点后)替换,以降低算力浪费。
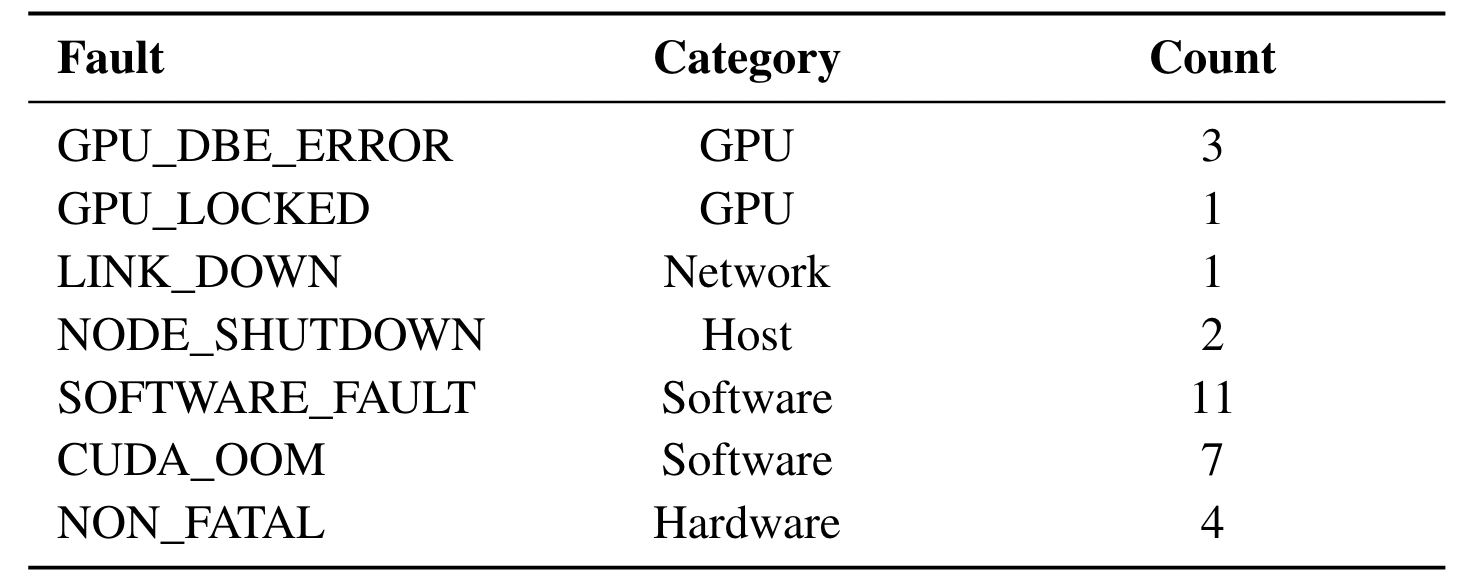
一个月的训练里,严重硬件错误7次,严重软件错误18次,其余错误4次。
节点质量评估框架¶
- 背景:GPU节点存在显著的质量差异,即其故障概率差异巨大。部分服务器的故障风险远高于其他节点,
- 思路:需选择最可靠的服务器,以最大限度减少作业中断。
- 改进:开发了一套创新的节点质量评估框架,系统性整合历史告警模式、维护日志、压力测试结果及负载测试时长,生成综合质量评分。
- 当生产资源池中的节点发生故障时,遵循优先级匹配规则从专用缓冲池选择性部署替代单元:缓冲机质量评分需满足或超过目标资源池优先级层级的运行要求。
- 结果:该方法使关键资源池(如视频池)的故障率从原月均7.0%显著降至0.9%。对应地,每千GPU因硬件问题导致的日重启率降至约LLaMA3.1报告的1/11。

全自动化服务器上线流程¶
当故障机器下线后,必须经过快速修复并满足严格的操作标准,方可重新加入服务池。这确保缺陷设备不会对训练任务产生负面影响。为此实施三项关键措施:
- 瞬时故障的自动重启修复:约60%以上的节点故障属于瞬时故障(多由电压波动、信号干扰等短暂因素引发),例如GPU双位错误(DBE)、GPU卡断开连接及网卡断开连接。此类故障可通过简单重启有效解决。为加速GPU修复,我们开发了自动化系统,可根据识别的故障类型快速重启服务器。通过将此重启系统与后续健康检查及压力测试集成,确保服务器能快速上线且质量可靠。
- 通过诊断脚本进行全方位健康检查:将人工经验编码为可复用的脚本,对GPU节点的硬件配置(如GPU、网卡)和软件配置(如驱动程序、固件)进行全面核查。该实践确保上线服务器具备统一、正确的软硬件配置,有效防止配置异常节点运行训练任务,从而降低作业中断概率。
- 严格的压力测试与准入协议验证性能: 我们通过全面的压力测试确保每台机器发挥峰值性能,主要评估两大领域:
- 单机性能验证:测试GPU AI算力(TOPS)、HBM带宽、主机-设备数据传输速度(H2D/D2H)及GPU间NVLink/PCIe连接性,确保硬件能力最大化。
- RDMA网络验证:通过PyTorch操作模拟分布式训练模式(TP/EP/PP/DP),测试真实网络性能。小规模组测试可快速定位故障节点、线缆或交换机。通过网卡路由跨GPU流量,实现单机内部网络验证,加速故障排查。这些测试提升节点可靠性与性能,防止作业失败,显著增强集群整体稳定性与可用性。
StepTelemetry¶
- 背景:训练框架缺乏可观测性,导致分析内部状态和调试任务故障变得困难。
- 自研StepTelemetry——一套面向训练框架的可观测性套件
- 增强异常检测能力,还要建立可复用的数据收集、后处理与分析管道,适用于任何训练相关数据的处理。
基本功能¶
- 新建进程来异步收集,传输,写入远程数据库
- 提供Python SDK,便于与训练框架集成
高效检测¶
- 背景:传统性能分析工具(如PyTorch Profiler、Megatron-LM Timer)会引入约10%-15%的开销,且难以支持多节点协同分析
- 改进:StepTelemetry采用基于CUDA事件的采集方法,避免不必要的同步操作,以接近零开销持续采集所有训练节点的计时数据。
优化示例
某次训练中,训练效率低于预期但未触发硬件告警。经数据分析发现,部分节点的反向传播时间异常延长。由于反向传播主要依赖张量并行(TP)组通信与计算,推测相关节点性能不足。移除问题节点后,训练效率恢复正常。
数据统计¶
- 背景:视频训练需重点监控数据使用情况,需记录的不仅是Token数量,还需包含视频的元数据。传统方法将元数据转储至本地文件再离线解析,效率低下。
- 改进:通过在dataloader中集成StepTelemetry,元数据直接写入数据库,实现联机分析(OLAP)。研究人员可借助可视化工具进行重复数据过滤、数据分布监控,从而优化模型训练。
性能优化¶
StepTelemetry为性能优化提供洞察支持:通过可视化单次迭代内各阶段耗时,开发者可全局掌握流程瓶颈并优化关键路径。
实例
数据加载器统计揭示训练实际吞吐量。解决数据并行(DP)不均衡问题后,吞吐量显著提升,实现系统效率改进。
StepRPC¶
- 自研StepRPC通信框架,达成高性能、支持StepMind灵活集群组织,支持StepTelemetry统一的数据分析。
- StepRPC以分布式命名管道为核心编程抽象,允许大量服务器通过声明同名管道实现无缝通信。其喷洒模式可将数据均匀分配到训练服务器。
- 创新如下:
零拷贝传输体系¶
- 传统框架痛点:序列化/反序列化(SerDe)过程产生10ms级延迟
- StepRPC创新:
- 内存级直传:绕过传统序列化流程,直接操作张量内存
- 硬件加速:优先使用RDMA实现GPU显存直接访问(GPUDirect RDMA)
- 退避策略(无RDMA时):TCP传输时,产生的GPU-CPU内存拷贝开销,通过将CUDA流内存拷贝与网络传输流水线化来加速。
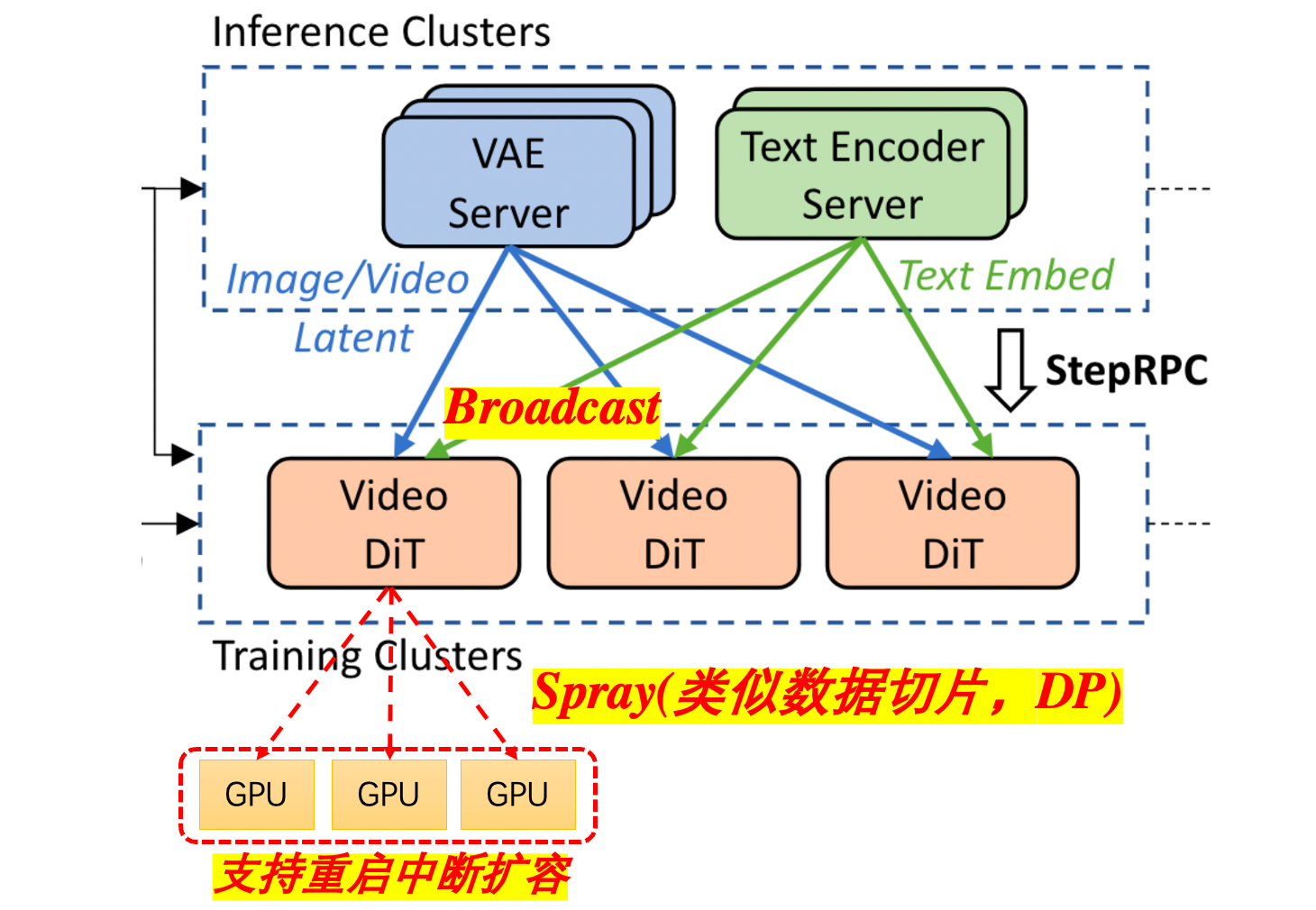
支持高弹性集群管理¶
通过混合通信拓扑实现动态资源调度:支持在线扩缩容的"热插拔"式节点管理
- 广播+喷洒模式突破单一通信模式限制:
- 全局广播:保证所有训练任务获取推理集群的全量数据(适用于参数服务器架构)
- 局部喷洒spraying:在单个任务集群内实现数据分片(适用于AllReduce架构)
支持通讯可观测性¶
- 基础思想:监控生产/消费数据量差异
- 实现:
- 实时故障诊断:实时检测数据丢失、通信故障。
- 瓶颈分析:通过队列延迟、API调用延迟等指标判断推理/训练环节的性能瓶颈;
- 负载均衡:结合数据生产/消费速率指标,可优化GPU资源在推理与训练任务间的分配。
对比当前的集群使用情况¶
StepFun¶
- profiler/StepRPC,从计算和通讯维度,硬件和软件维度,实时启动辅助进程低开销异步写入性能信息到磁盘,使用数据库统一管理,
- StepTelemetry 故障和性能分析中台,实时从原始数据库信息提炼出关键故障和性能指标,及时性能报警和给出故障分析。
- StepMind根据性能指标和故障分析,及时调度GPU机器,实时保障任务的持续高效运行。
Huawei¶
询问李哥通讯、赵哥集群管理的当前实现。
现阶段问题¶
- 客户出运行错误问题,开debug重跑,PTA/CANN各层打印log日志,profiler还是顺序的,打开debug日志会慢很多,花上半天,千卡集群的日志全打开数据量都奔TB去了,传日志回家里,靠grep最后定位问题。
- 更不用说性能波动问题了,客户可没时间开debug分析,没log更难以分析,不了了之都是常态。
- 硬件:质量大会说分析通讯模块的问题,耽误了客户好多天。
- 假如有了StepFun,开发甚至客户只需要在StepTelemetry,过滤分析数据库中历史任务的信息,即可快速定位。甚至常见问题StepMind都可以自动调整。
- 开发人员日常开发中也被折磨的要死,
- 模型在某台机器不达标的问题单(PTA,MM),要给出理由。StepMind就说明了,有些机器老化了,就是不行了,下线是影响最小的办法。
- 开发遇到性能裂化也难以有全局的视野(说的就是黑盒CANN),开发没有全局的视野就会圈地自萌,开发出不兼容其他组件的产品。
上面的种种问题,StepFun的框架就是一种大集群训练时的高效解决方案,也会成为产品的核心竞争力,软件的护城河。
现阶段解决方案¶
- 特战队虽然能解决问题
- 但是容易陷入解决方案case by case难以复用,没有固化的问题。
- 客户使用调试优化门槛还是很高。
实现¶
需要大领导推动,涉及统一的标准和跨部门的协作。
- 统一的数据库日志接口,硬件和软件(PTA,MM,HCCL,CANN) 使用统一日志语言。
- 高效的实时关键日志记录:技术难点,能不能实现低开销的实时日志记录,
- 工具部:构建StepTelemetry 实时故障和性能分析中台
- 集群部:实现StepMind 实时集群管理。
关键指标¶
- 低开销,
- 实现实时收集信息、分析、改正,
- 客户使用时,有清晰的集群健康度视野。自发的说华为的产品好用,易用。