AI Traning Parallism
导言
- AI 训练时,有些分布式训练的常见并行概念需要了解。
- 例如,TP, VP, SP, VPP
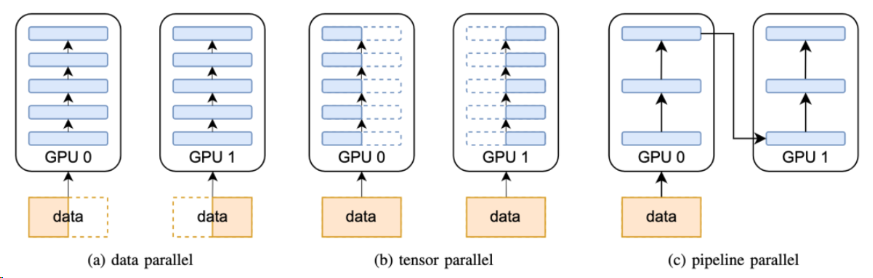
数据并行 DP¶
(Data Parallelism)
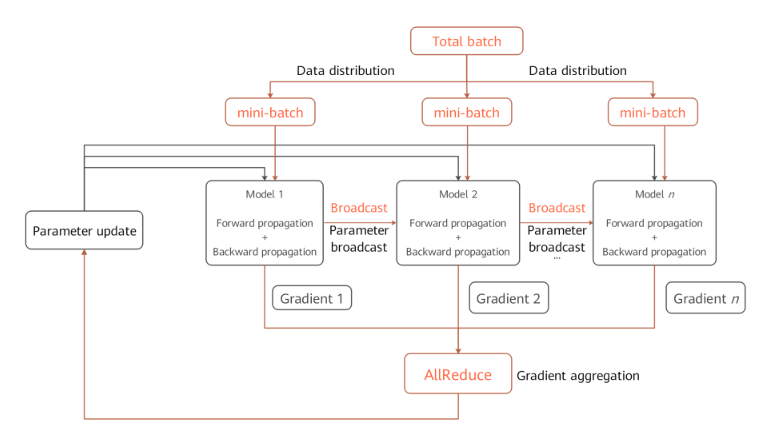
- 思想:把同一个模型放在多个GPU上,batch数据平均分布到各个GPU上,并行计算。
- 难点:注意参数同步和信息过期问题。
- 优点:
- 加速比线性。
- 部署简单工作量小,每个节点内的计算效率高。
- 由于部署简单,是最先采用的并行方式。
- 缺点:
- 需要在每个节点复制所有模型参数,显存重复度高,利用率低,并不适合大模型的部署。只适用于训练样本较多而模型较小的情况。
- 数据分布在不同机器,需要allreduce同步权重 FS(fully shared)DP
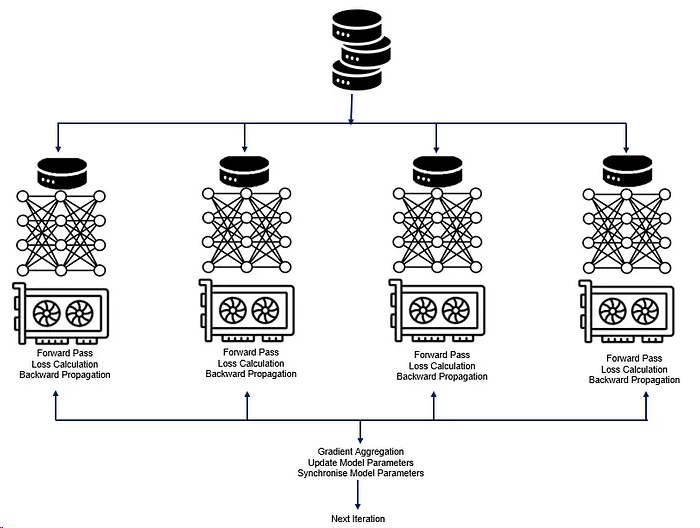
特点+具体操作:
- 同构模型,不同数据:每个节点都包含完整的模型,以及模型的参数(weight,parameter),输入数据则根据模型的并行度进行拆分,分别被每个节点读取;
- 假设我们有8张GPU卡或者昇腾的NPU卡来训练图片分类的模型,训练的批量为160,那么每张卡上面分到的批量数据(min-batch)为20,每张卡基于样本数据完成训练。
- 独立运行:每个节点读取相应的输入数据后,分别独自处理模型的前向和反向传播,并得到Gradients,归并所有的梯度并更新梯度;
- 梯度聚合:因为各张卡上处理的数据样本不同,所以获得的梯度会有些差别。因此,需要对梯度进行聚合(求和、均值)等计算来保持和单卡训练相同的结果,最后再更新参数。
- 统一通讯:所有节点之间的通信,主要包括前向传播的Loss归并以及反向传播的gradient归并以及更新,这些通信则是通过相应的通信原语(gather/reduce/broadcast)操作。
- 参数更新:梯度聚合会让各卡的模型以相同的梯度值同时进入参数更新阶段,然后针对新的数据进行下一轮训练。
模型并行¶
Model Parallelism
- 思想: 通过将模型切分成不同的部分分别在多个设备上进行计算,从而使得其可以部署更大的模型。
- 难点:
- 需要人为的切分设计。
- 也有必要的数据传输。
- 切分的部分能有线性加速比,
- 优点:
- 适用于模型较大无法单独放入一个设备内存的情况,通过将模型切分到多个设备上进行计算,从而使得其可以部署更大的模型。
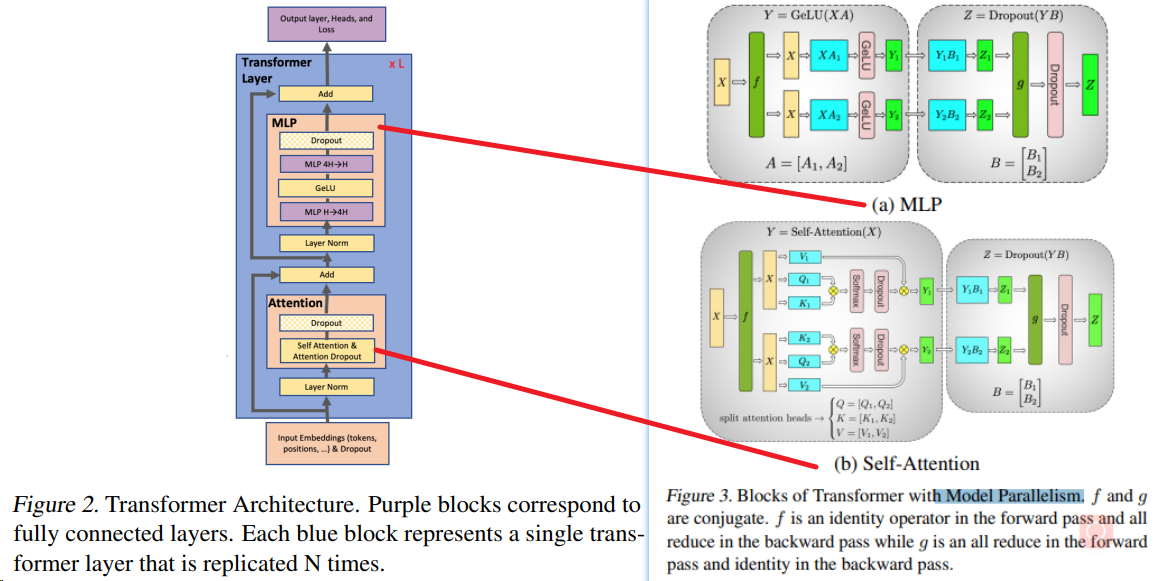
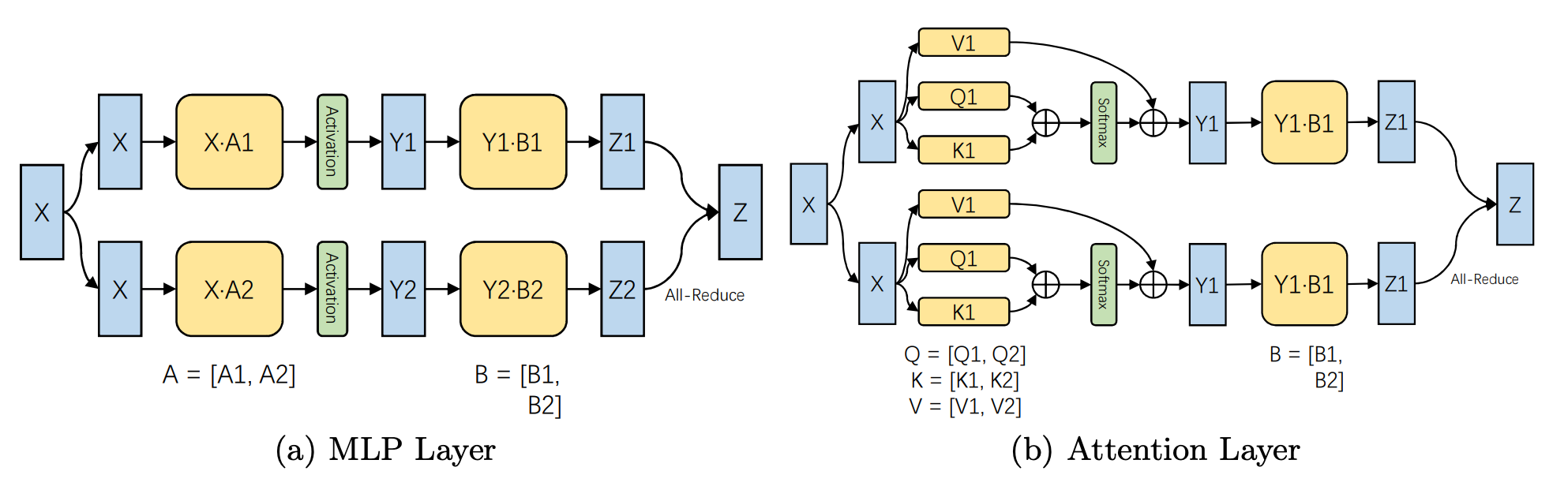
张量并行 TP¶
Tensor Parallelism 是模型并行的一种
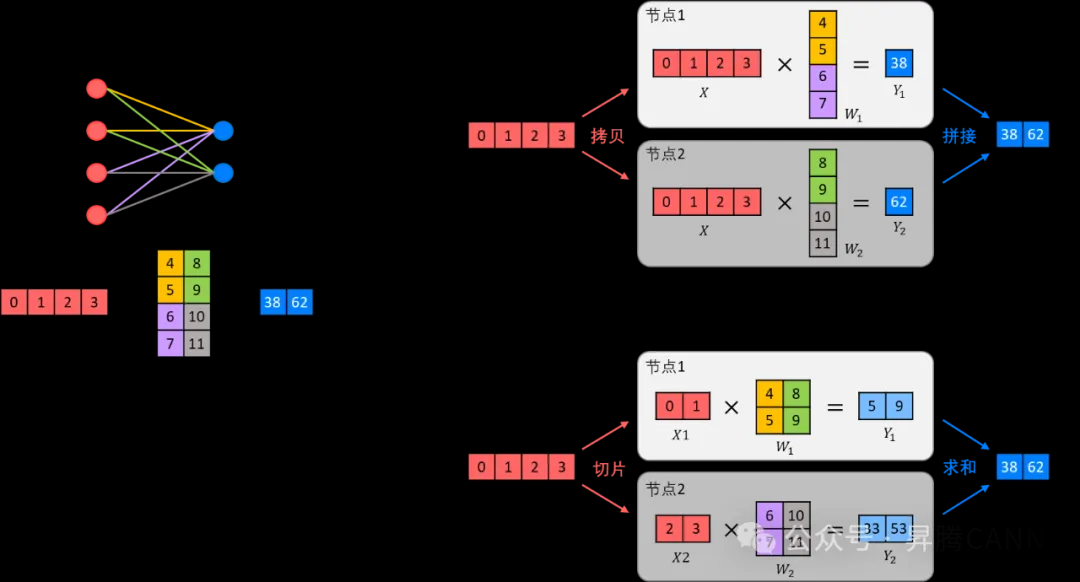
- 思想:通过在多个计算设备上分片模型参数来实现并行。
- 举例:一个操作中进行并行计算,主要是矩阵-矩阵乘法。张量并行训练是将一个张量沿特定维度分成 N 块,每个设备只持有整个张量的 1/N,同时不影响计算图的正确性。这需要额外的通信来确保结果的正确性。
- 底层逻辑是矩阵乘法的拆分计算, 矩阵乘法中列并行与行并行这两种张量并行的方式,以及它们在前向传播和反向传播中的区别。14
- 难点:额外的通信
- 优点:每个设备只持有整个张量的 1/N
序列并行 SP¶
Sequence Parallelism 是模型并行的另一种
- 序列并行可以看作是先前介绍过的数据并行在Transformer大语言模型下的延伸和扩展,它是更加细粒度的数据并行。15
- 大家知道,Transformer语言类模型所处理的数据对象是序列(Sequence),一个batch中包含多个序列,一个序列中包含多个token,每个token由一个向量表示。
- 序列并行(Sequence Parallelism, SP)即为将一个序列切开,分片段到多个节点上并行处理的策略,其主要目的是可以摆脱单卡存储限制,训练超长上下文的大模型。
根据现有文献描述,序列并行可以被部署在Transformer模型的两个的阶段中:
- 一个是Attention阶段,
- 另一个是LayerNorm与Dropout阶段,来自Megatron-LM8
虽然都是序列并行,但由于处于不同的运算阶段,它们的行为以及影响是不同的。前者的目的主要是减少数据存储压力,打破模型输入序列长度(sequence length)的限制;而后者则是为了与LayerNorm与Dropout前后相邻阶段的张量并行(TP)搭配使用,减少存储压力。
- 关键:SP能够有效地分配和管理大规模输入序列的计算任务,从而使得模型能够处理更长的序列而不会受到单个设备内存限制的束缚。
Megatron SP: 将层内切分的并行思想,从TP的对Tensor并行,拓展到对Norm层和Dropout层也并行8
在大型 Transformer 模型训练中,激活重新计算是一种常用的方法来解决内存容量限制问题。本文提出了两种技术来减少这种重新计算的需求:序列并行和选择性激活重新计算。
序列并行通过在不适合标准张量并行的区域中避免冗余的激活存储,减少了内存消耗。(下图中的TP指代Megatron-LM2的MP)
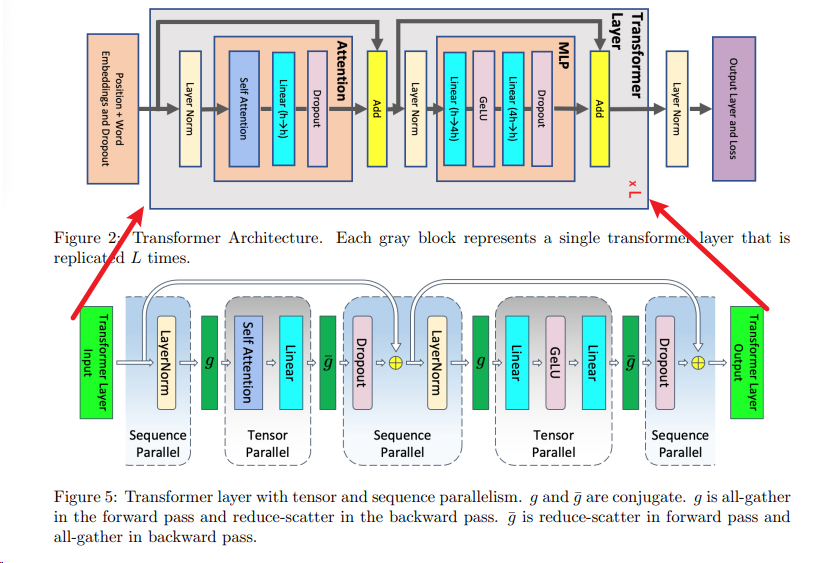
选择性激活重新计算则通过只重新计算内存消耗大但计算成本低的部分,减少了重新计算的开销。
DeepSpeed-Ulysses: 整体从序列维度进行划分设计10。
- DeepSpeed Ulysses 是由微软研究院提出的一种系统优化方法,通过All2All通信操作处理分割后的Q(查询)、K(键)、V(值)和O(输出)张量。
- 这种方法的特点是当序列长度和计算设备成比例增加时,通信量保持不变。
- 在All2All操作后,这四个张量的分割从序列维度L转移到注意力头数维度hc。
- 这样,每个注意力头的softmax(QK^T)V计算可以完整地进行,而不会因为张量的分割而中断。
- 针对常见的attention模块:
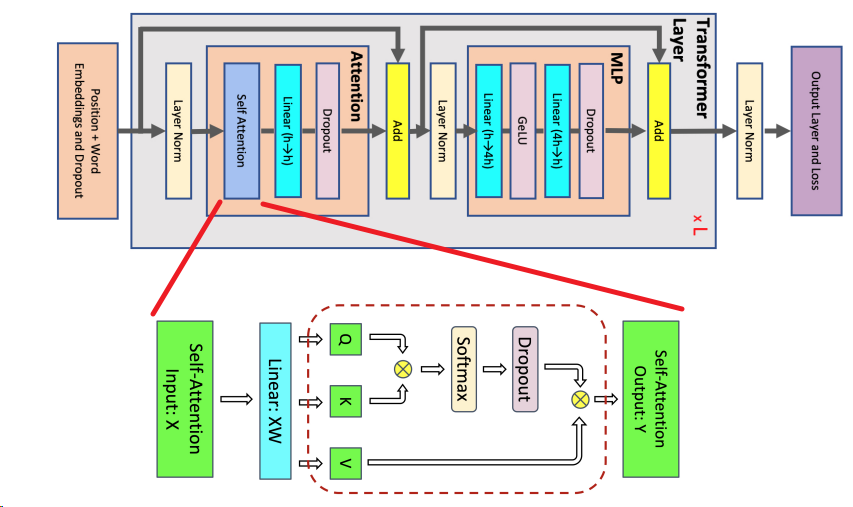
在序列维度上进行并行。并行对象是输入数据的序列维度,它将输入序列均匀地分割(N/P),并在参与计算的 GPU 之间进行分配,其中 N 是序列长度,P 是参与的 GPU 数量。
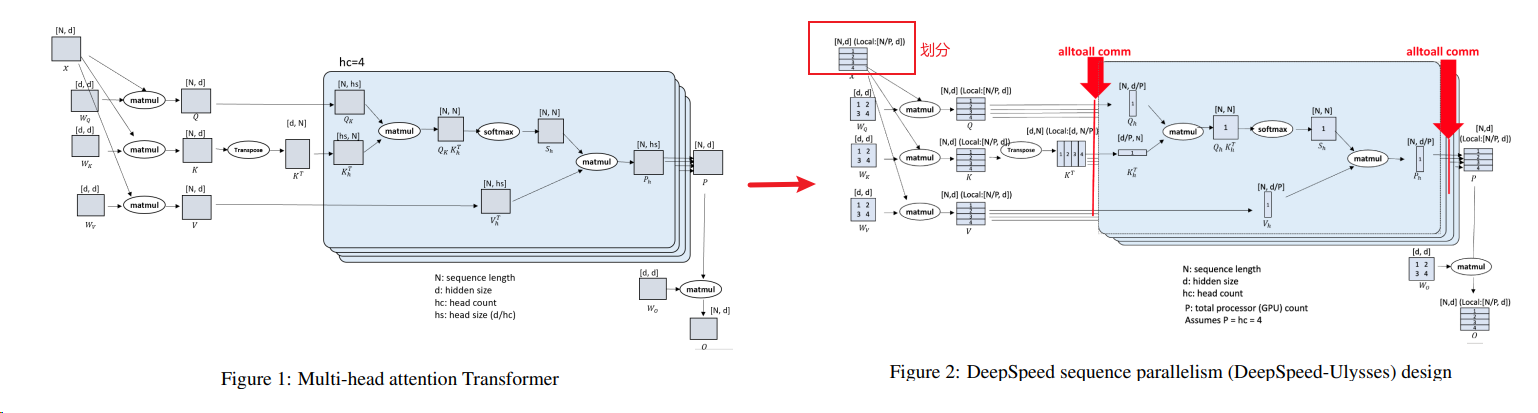
Ring Attention: 分块并Ring来传递键值,计算掩盖通讯,来自Ring Self-Attention5或者Ring Attention9.
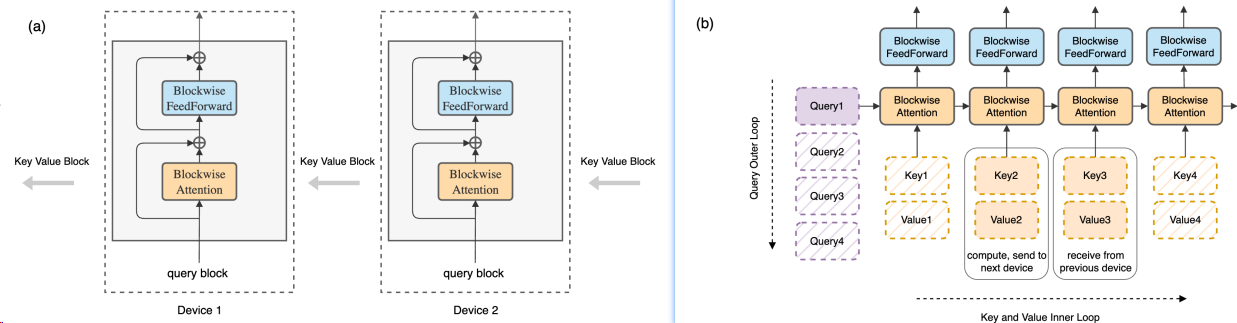
在多个设备上实现Ring Attention的并行主要依赖于以下几个关键点:
-
区块化计算:Ring Attention模型将自注意力和前馈网络的计算分解成区块形式,每个设备负责计算自己区块的自注意力和前馈网络。
-
环形拓扑结构:所有参与计算的设备形成一个逻辑上的环形结构(Ring)。在计算过程中,每个设备会将自己的键值块(key-value blocks)发送给下一个设备,同时接收来自上一个设备的键值块。
-
通信与计算重叠:在计算区块化自注意力时,每个设备同时进行键值块的发送和接收操作,这样的操作可以确保通信操作与计算操作的时间重叠,从而不会增加额外的通信开销。
-
内存高效:由于每个设备只需存储与自己计算相关的区块数据,这大大减少了内存的使用,使得模型能够处理更长的序列数据。
-
无缝扩展:Ring Attention模型的设计允许上下文长度随着设备数量的增加而线性增长,这意味着通过增加更多的设备,可以无缝地扩展模型处理的序列长度。
具体实现时,每个设备会在外层循环中处理自己的查询块(query block),而在内层循环中,设备会计算本地的键值块与查询块之间的自注意力,并且在计算的同时,将键值块传递给下一个设备,同时接收来自上一个设备的键值块。这种方式确保了计算的连续性和通信的并行性,从而实现了高效的多设备并行计算。通过这种方式,Ring Attention模型能够有效地处理数百万甚至更长的序列数据,为大规模AI模型的训练和推理提供了技术支持。
优势和局限
- DeepSpeed-Ulysses在增加计算设备和序列长度时能保持恒定的通信量,
- 而Ring-Attention通过计算和通信的重叠隐藏了由SP引入的点对点(P2P)通信成本。
- 然而,DeepSpeed-Ulysses的并行度受到注意力头数的限制,
- 而Ring-Attention在分块矩阵乘法中的计算效率较低。
TP vs SP¶
Attention阶段的序列并行与TP的对比:Attention阶段除了SP(属于数据并行),还有一种通用的并行方式是TP(属于模型并行)15。
- TP将Attention阶段的计算按照Multi-Head中Head的维度分开,涉及到的通信主要是正向一次的各Head输出矩阵的AllReduce和反向一次的输入矩阵梯度的AllReduce;
- 而SP是按照输入数据的序列长度的维度分的,涉及到的通信主要是正向一次的矩阵的AllGather与反向一次的矩阵梯度的ReduceScatter。
- 值得提及,SP在Multi-Head与Single-Head情况下的通信行为一致,由于Head没有被分开,不涉及跨Head的通信行为。
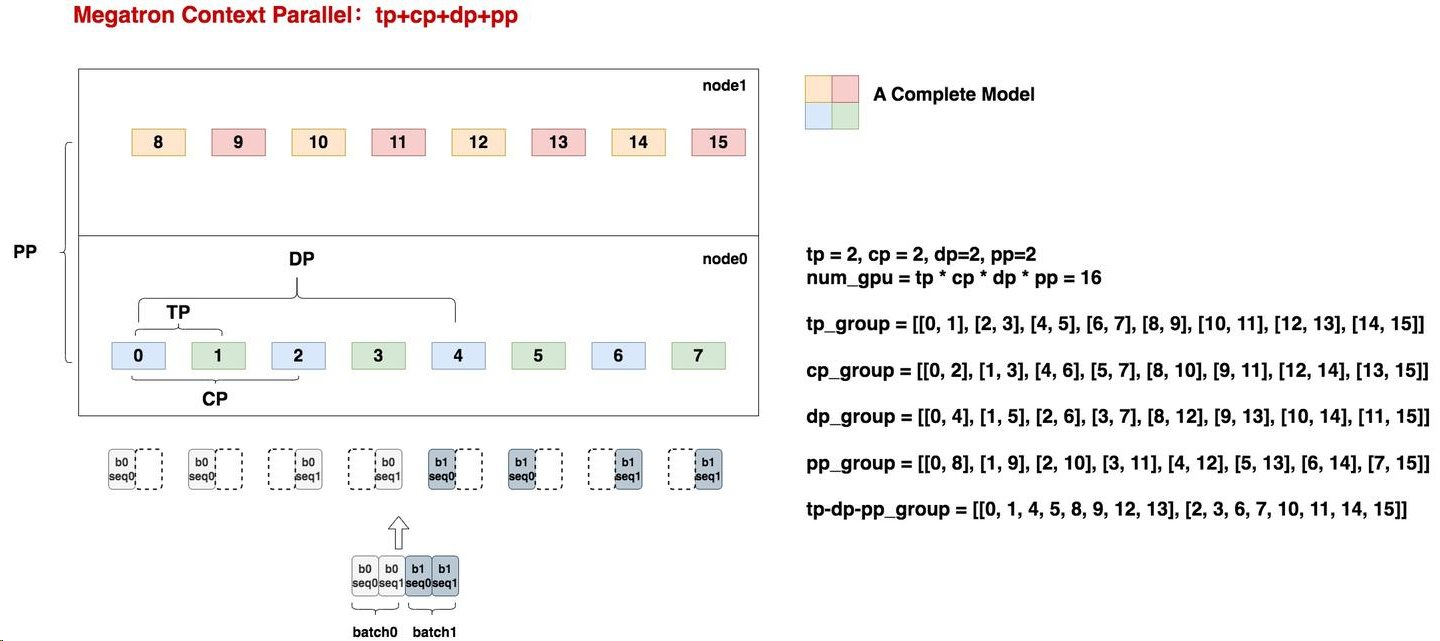
上下文并行 CP¶
Context Parallelism 是序列并行Megatron SP的加强
Context Parallelism解决SP中未完成的self-attention序列并行问题。从而使得TP和CP变成两个独立的并行维度。16
通过从序列维度划分三份,并Ring来交换KV,实现计算和通讯的覆盖:
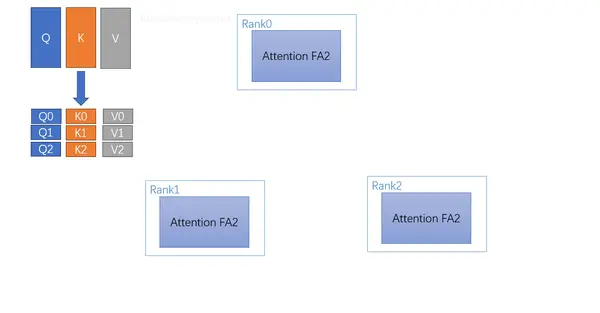
CP vs SP¶
Megatron-LM提出的CP与Colossal-AI提出的SP的差别:CP在SP之后被提出,其主体思想与Colossal-AI的SP一致,都是Attention阶段的序列并行15。
其主要优化点在于:
- CP进一步利用了Flash Attention的方法对注意力矩阵进行了分块计算。
- 结合上述Ring Attention的计算通信流水部署方案,CP一次传输一组KV矩阵,得到一个分块的输出矩阵O,最后再整合,降低存储与通信开销。
流水线并行 PP¶
Pipeline Model Parallelism (层间切分的模型并行)
- 思想:AI训练是重复的有依赖长过程,可以打散成有依赖的基本单元micro-batch进行流水线调度, 提高设备的利用率。
- 难点:依赖基本单元间的数据传输时间,如何隐藏。流水线并行的方式更复杂,并且micro-batch的方式减少了单节点计算密集度,增加了节点间的信息传递频率,使得取得一个好的加速比成为一个难题。
- 优点:解决了数据并行显存利用率低的问题,其通过对模型的切分,每个节点只需要放置一部分的模型参数,从而使得其可以部署更大的模型。
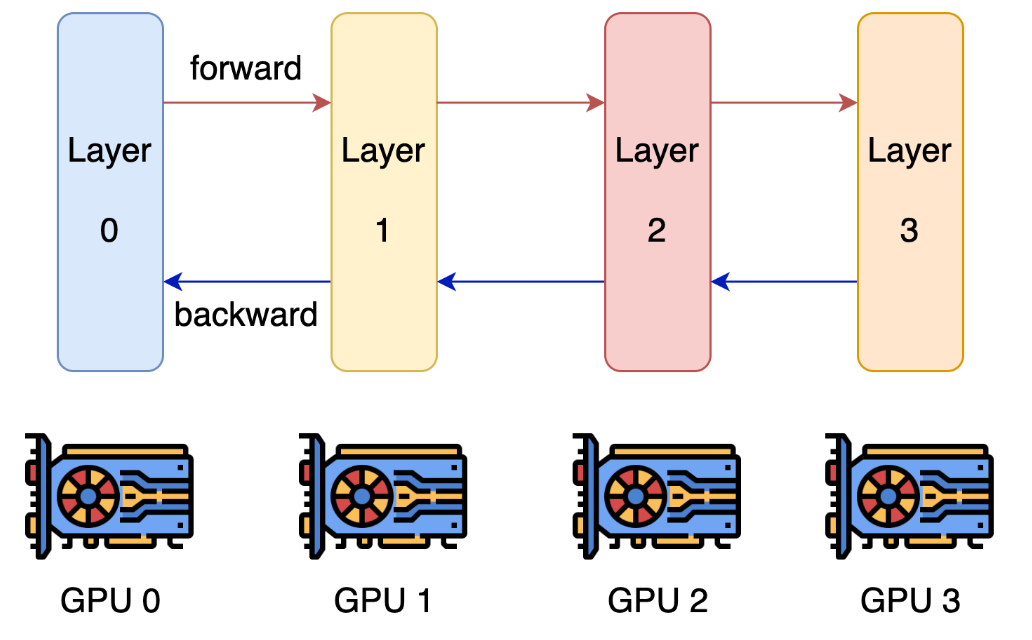
GPipe¶
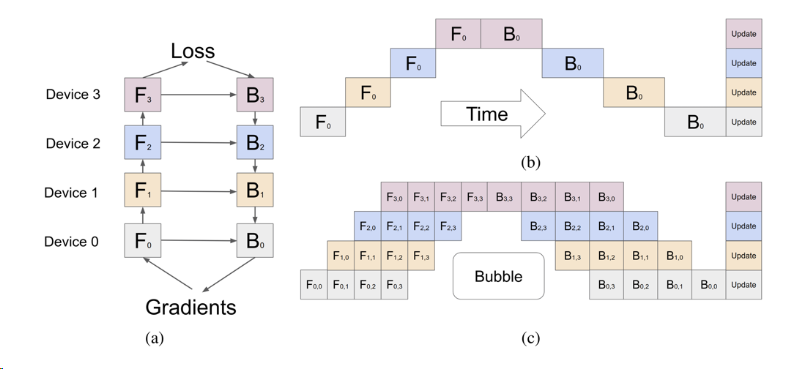
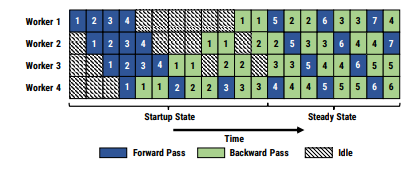
1F1B¶
PipeDream¶
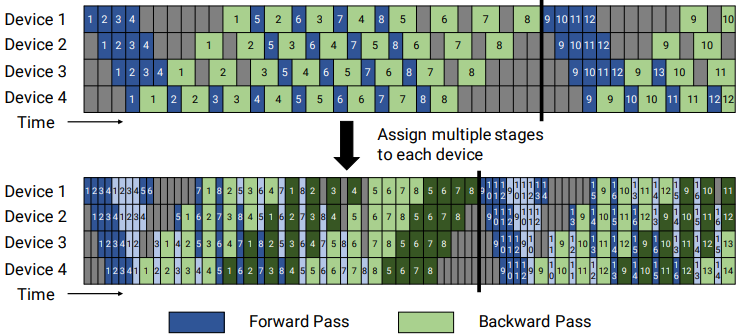
VPP¶
- 假定当前模型网络共16层(编号 0-15),4个Device,
- 前述GPipe模式和PipeDream是分成4个stage, 按编号0-3层放Device1,4-7层放Device2,并以此类推。
- virtual pipeline则是按照文中提出virtual_pipeline_stage概念减小切分粒度,
- 以virtaul_pipeline_stage=2为例,将0-1层放Device1,2-3层放在Device2,...,6-7层放到Device4,8-9层继续放在Device1,10-11层放在Device2,...,14-15层放在Device4。
DualPipe¶
idea
传统流水线并行卡之间串行,效率低。可以0号和7号卡同时都是layer0和layer7,这样做的目的:真个流水线能同时运行两批次的数据!比如第1批从gpu0卡的layer0开始forward,第10批数据从gpu7卡的layer0开始forward,提升效率!
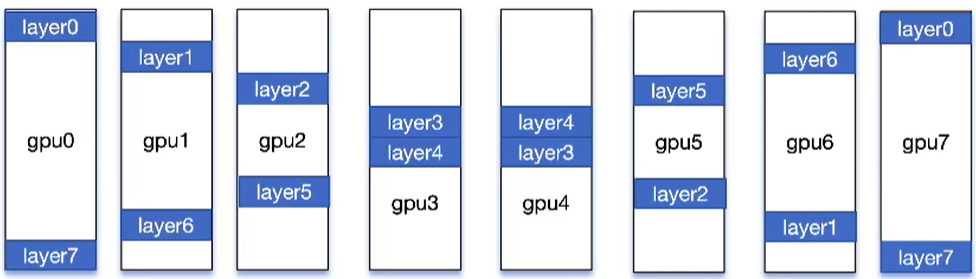
DualPipe 是一种创新的双向管道并行算法,在 DeepSeek-V3 技术报告中提出。实现了正向和反向计算-通信阶段的完全重叠,同时也减少了管道气泡时间。

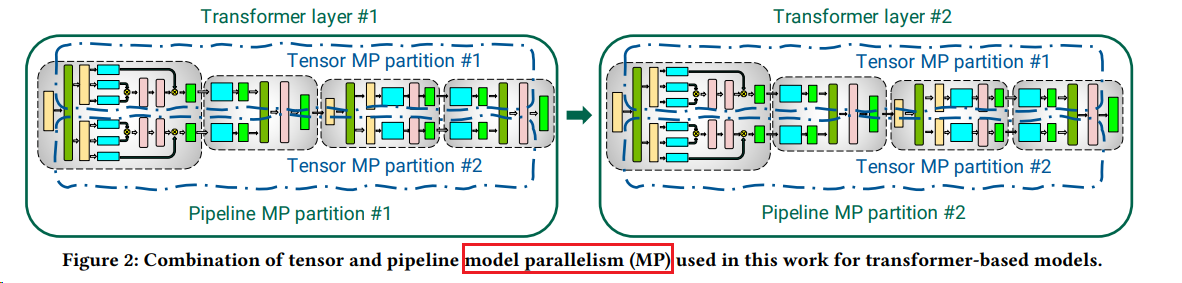
混合并行¶
- 2021年10月,微软和英伟达联合提出了 PTD-P(Inter-node Pipeline Parallelism, Intra-node Tensor Parallelism, and Data Parallelism)训练加速方法,
- 通过数据并行、张量并行和 Pipeline 并行“三管齐下”的方式,将模型的吞吐量提高 10%以上。
- 该并行方法可以在3072个GPU 上,以502P的算力对一万亿参数的GPT 架构模型进行训练,实现单GPU吞吐量52%的性能提升。
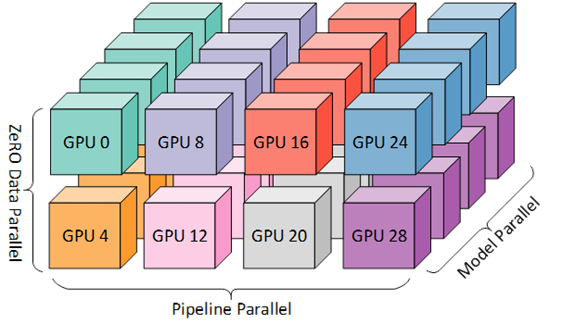
Bloom-176B
DP8,TP4, PP12:
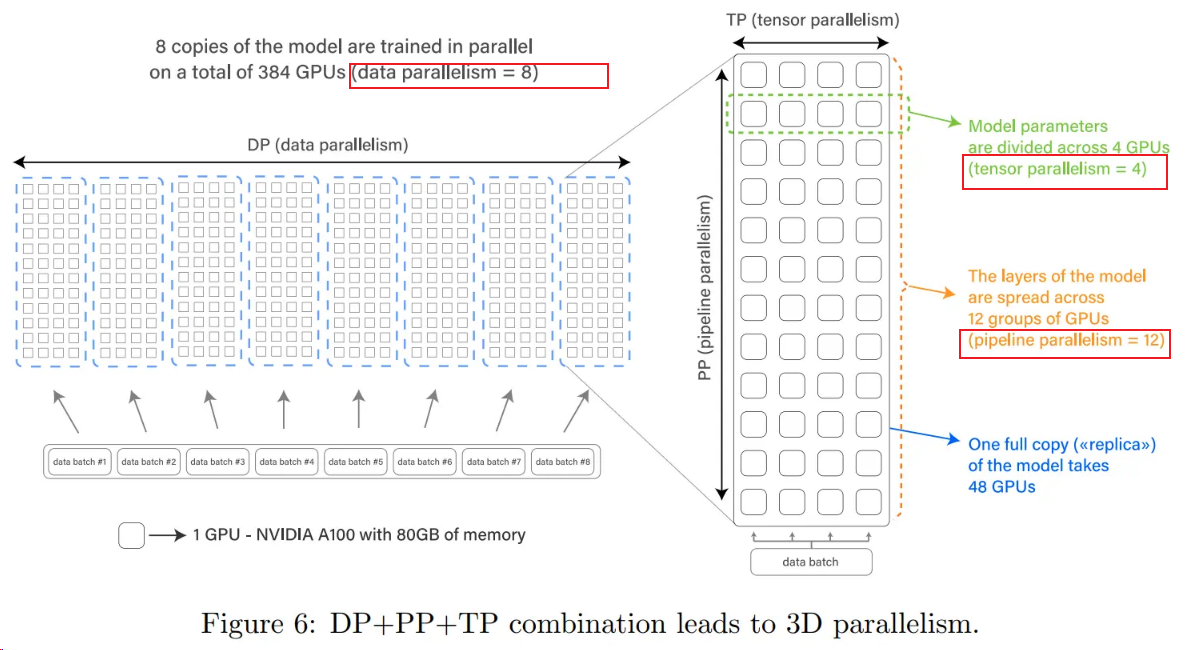
专家并行 MoE(EP)¶
MOE的概念
- 思想:一种基于稀疏 MoE(Mixture-of-Experts) 层的深度学习模型架构被提出,即将大模型拆分成多个小模型(专家,expert), 每轮迭代根据样本决定激活一部分专家用于计算,
- 优点:只计算一部分,达到了节省计算资源的效果;
- 实现:MoE 将模型的某一层扩展为多个具有相同结构的专家网络(expert),并由门(gate)网络决定激活哪些 expert 用于计算,从而实现超大规模稀疏模型的训练。
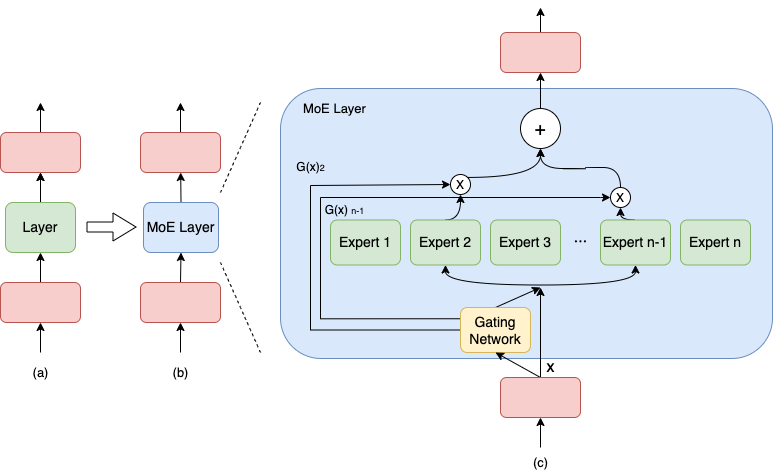
MOE 与 EP的关联
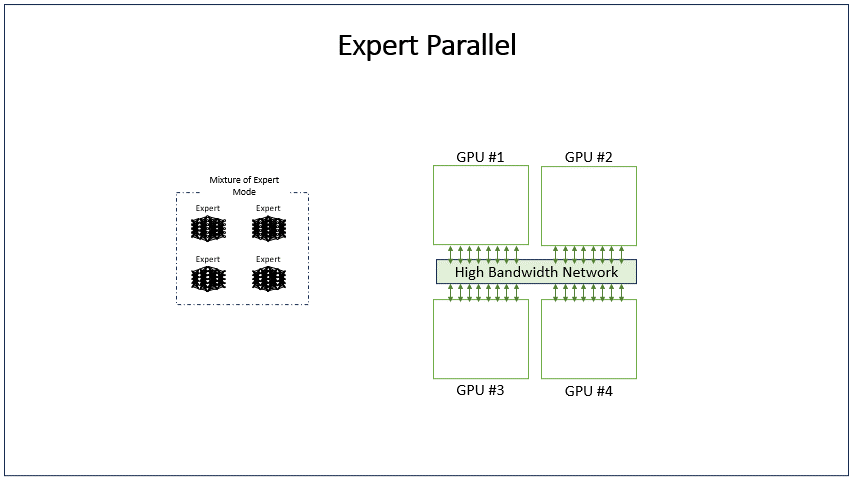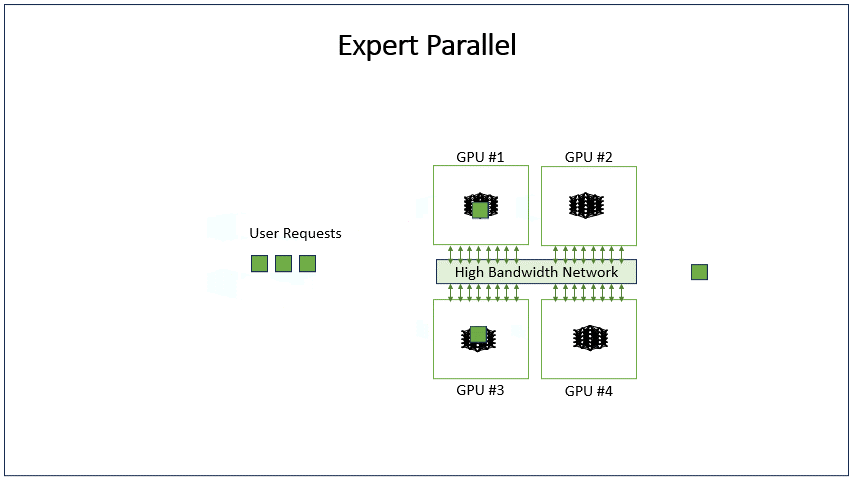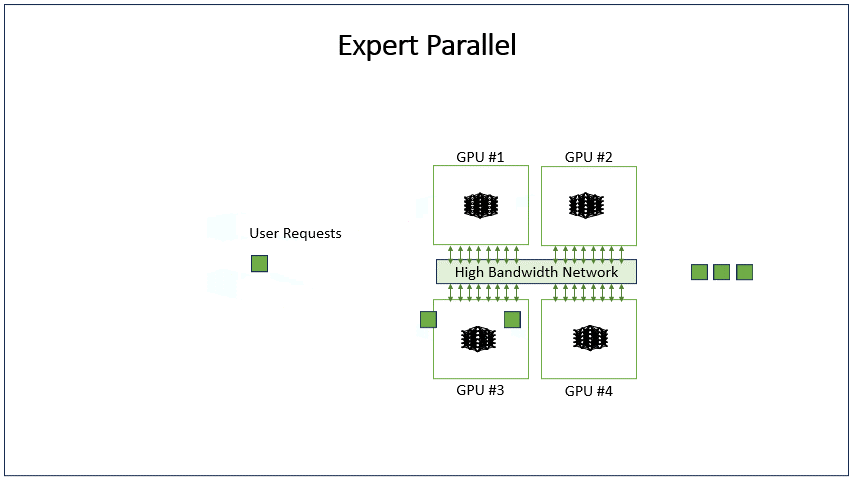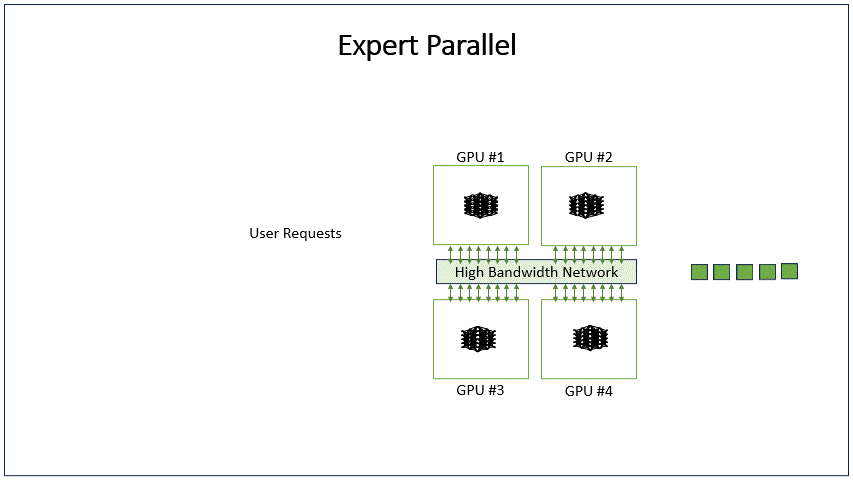
- MOE层如果不开EP, MoE的结构由多个 expert 构成,每次只选择一个专家执行;
- MOE层开启EP,MOE层的多个专家就能同时并行,处理不同的tokens,从而达到并行的效果。为了实现这点需要对topk的token来dispatch和combine
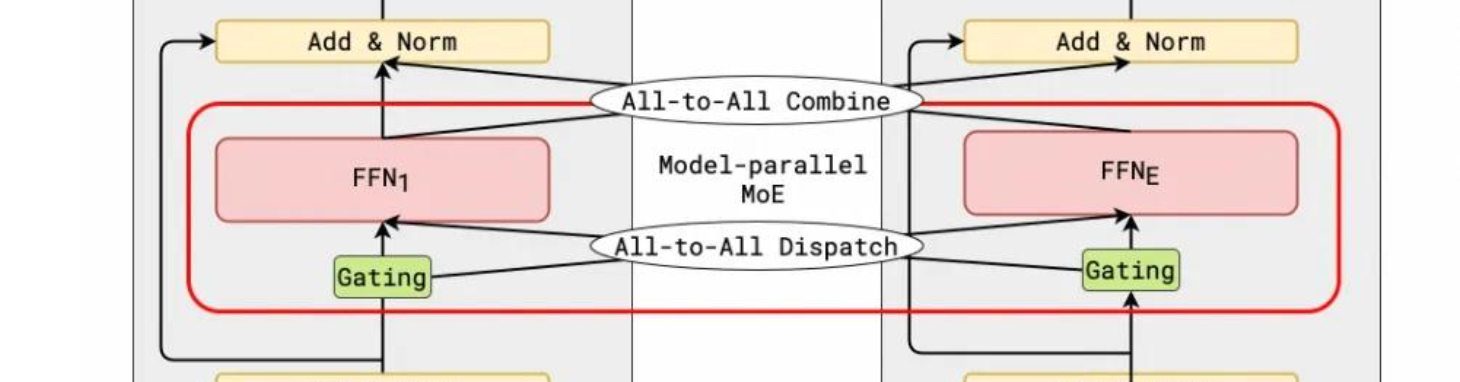
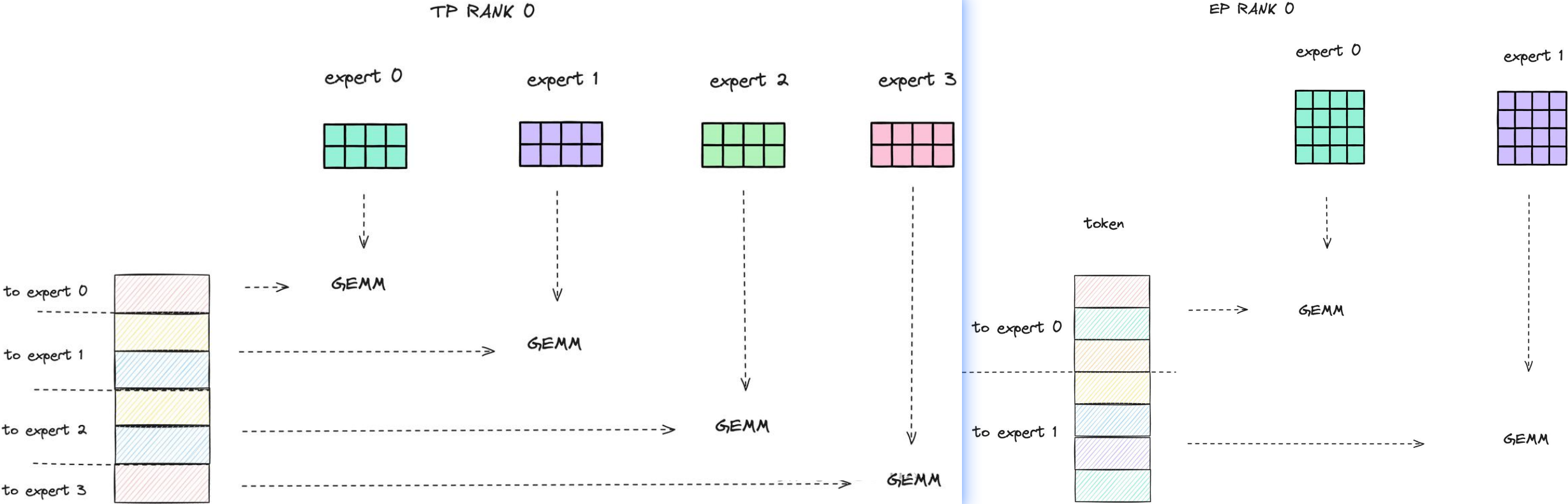
EP 与 TP的区别
- TP开启时:每个 EP rank 上只包含一部分 expert,而每个 EP rank 上的 token(即 token 对应的 hidden state) 会根据 gating 结果分发到其他 EP rank 上的 expert。这个过程通过 all-to-all 通信完成。
- 只开启EP时,GPU会拥有多个完整的专家,每个矩阵计算都是完整的,是大矩阵计算。
- 不同情况各有优劣。
EP
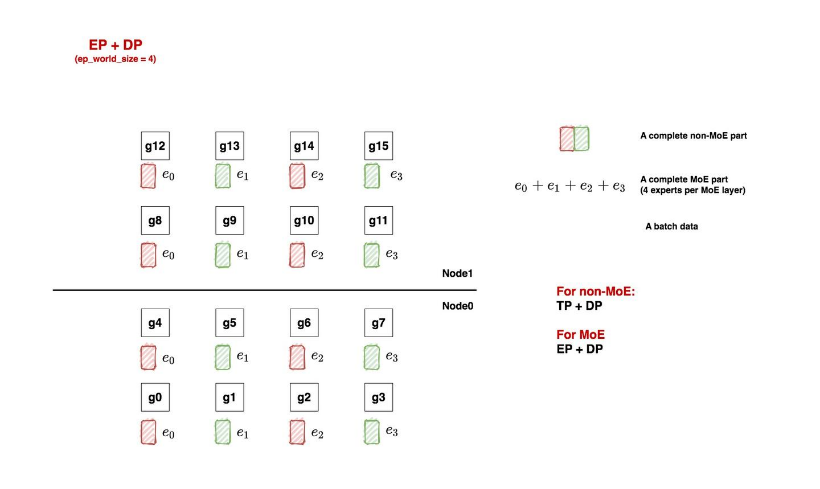
红色和绿色方块表示非-MOE层,e0、e1表示MOE层(总共4n个专家)
一共16块GPU:
- ep_world_size = 4:表示我们希望用4块GPU装下一套完整的专家。确定这个数值后,我们就能确认ep_groups
- local_expert_num:expert_num / ep_world_size,其中expert_num表示每层专家的总数。
- 假设每层专家数量是4,那么1块gpu上就放一个专家;
- 假设每层专家数量是8,那么1块gpu上就放2个专家。
- 所以图中的e0等符号并不绝对表示这里只有1个专家,只是对local_expert的统称。
- ep_dp_world_size:类比于non-MoE层,MoE层同样也有数据并行的概念。例如图中[g0, g4, g8, g12]上都维护着e0,所以它们构成一个ep_dp_group。这个group的作用是当我们在计算bwd时,它们之间是需要做梯度的allreduce通讯的,我们会在下文详细图解这一点。另外需要注意的是,构成ep_dp_group的条件不仅是e相同,还需要每个e吃的batch的数据不同(类比于一个普通的dp_group,组内的每张卡吃的是不同的小batch)。现在你可能无法具象化感受这点,我们在后文将ep+tp+dp并行的时候再细说。
- ep_tp_world_size:类比于non-MoE层,MoE层同样也有张量并行的概念,即一个专家可以纵向切割成若干份.
代码实现
参考DeepSeek-VL2实现, 当前代码实现有几个特点:
- EP=x,就将world_size拆分成几份,每份里的机器上拥有 experts/EP 的专家数的副本。
- self.shared_experts = MLP, forward里和路由专家结果相加。
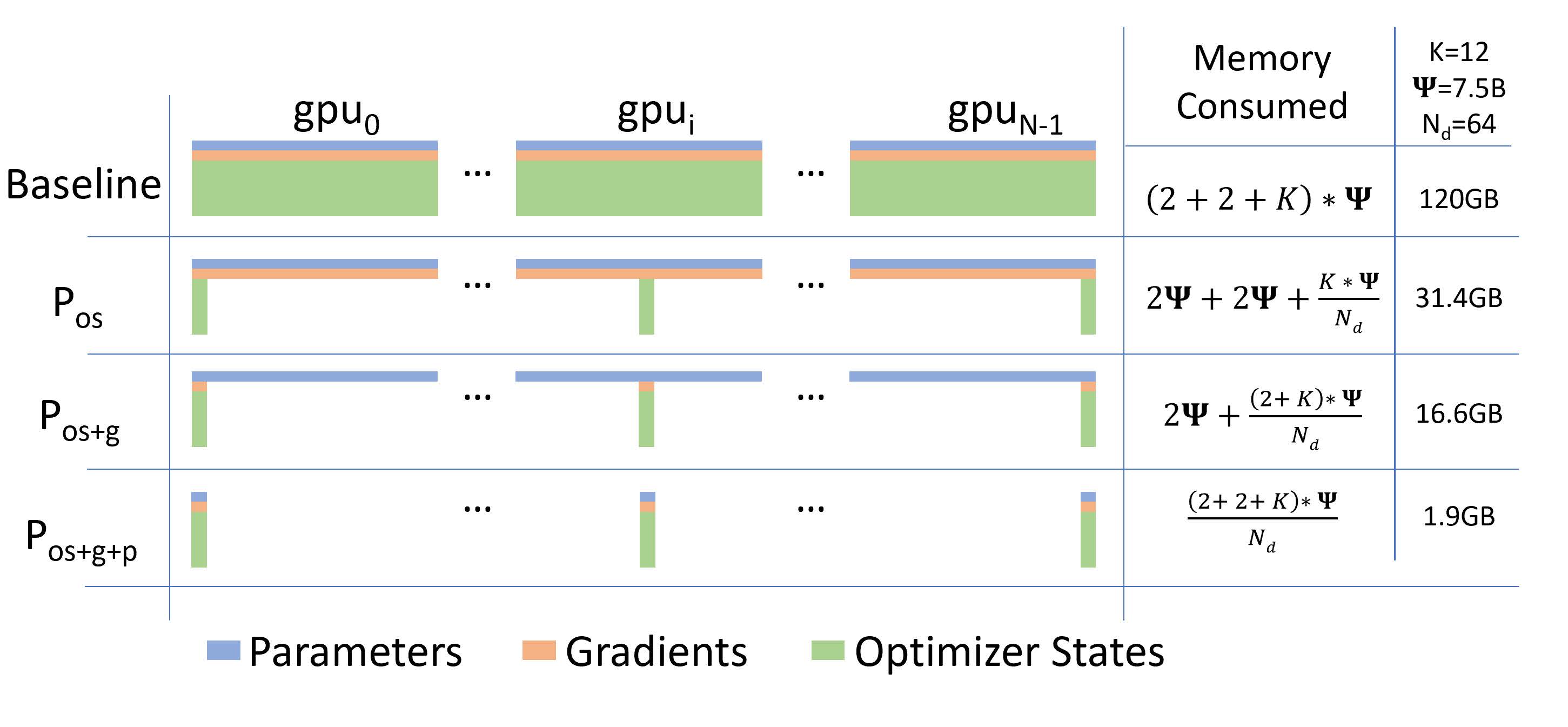
ZeRO¶
- ZeRO通过在多个设备上分片优化器状态、梯度和参数来减少每个设备的存储需求。
- Zero 优化方法有三个层次,分别是 ZeRO-1、ZeRO-2 和 ZeRO-3。13
- 它们是由微软提出的 ZeRO(Zero Redundancy Optimizer) 优化技术的不同阶段,旨在减少大规模分布式训练中的内存占用。
 ¶
¶
1. ZeRO-1:优化器状态分区¶
- 目标:减少优化器状态的内存占用。
- 实现方式:将优化器状态(如动量、梯度方差等)分布在不同的 GPU 上,而不是在每个 GPU 上保存完整的副本。
- 优点:显著减少内存占用,同时通信开销较小。
- 适用场景:适合中等规模的模型训练。
2. ZeRO-2:梯度分区¶
- 目标:进一步减少梯度存储的内存占用。
- 实现方式:将梯度分区存储在不同的 GPU 上,每个 GPU 只保存一部分梯度。
- 优点:内存占用进一步降低,但通信开销有所增加,因为需要在反向传播后聚合梯度。
- 适用场景:适合大规模模型训练。
3. ZeRO-3:参数分区¶
- 目标:最大化内存节省,支持超大规模模型训练。
- 实现方式:将模型参数分区存储在不同的 GPU 上,每个 GPU 只保存一部分参数。
- 优点:内存占用大幅降低,可以训练非常大的模型,但通信开销最大,因为需要在每次前向和反向传播时聚合参数。
- 适用场景:适合超大规模模型训练(如 GPT、BERT 等)。
对比总结¶
| 特性 | ZeRO-1 | ZeRO-2 | ZeRO-3 |
|---|---|---|---|
| 分区对象 | 优化器状态 | 梯度 | 模型参数 |
| 内存节省 | 中等 | 较大 | 最大 |
| 通信开销 | 最小 | 中等 | 最大 |
| 适用场景 | 中等规模模型 | 大规模模型 | 超大规模模型 |
分层ZeRo¶
- 分层Zero(Hierarchical Zero)是一种用于大规模AI模型训练的优化方法,旨在解决传统Zero(Zero Redundancy Optimizer)在大规模分布式训练中的局限性。
- 它通过分层通信和计算优化,提升训练效率和扩展性。
核心思想是将计算和通信任务分层处理,减少通信开销,提高资源利用率。具体包括:
- 分层通信:将通信任务分为多个层次,优先在低层次(如节点内)完成,减少高层次(如跨节点)的通信。
- 分层计算:将计算任务分层处理,优先在低层次完成,减少高层次的计算负担。
主要特点
- 减少通信开销:通过分层通信,降低跨节点通信频率,提升效率。
- 提高资源利用率:分层计算使资源分配更合理,减少闲置。
- 增强扩展性:优化后的方法更适合大规模分布式训练,支持更多计算节点。
异构系统的并行¶
人们思考为什么 CPU 内存没有被用于分布式训练。
参考文献¶
-
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism ↩↩
-
PipeDream: Generalized Pipeline Parallelism for DNN Training ↩
-
Sequence Parallelism: Long Sequence Training from System Perspective ↩↩
-
DISTFLASHATTN: Distributed Memory-efficient Attention for Long-context LLMs Training ↩
-
Reducing Activation Recomputation in Large Transformer Models ↩↩
-
Ring Attention with Blockwise Transformers for Near-Infinite Context ↩
-
DEEPSPEED ULYSSES: SYSTEM OPTIMIZATIONS FOR ENABLING TRAINING OF EXTREME LONG SEQUENCE TRANSFORMER MODELS ↩↩
-
Efficient large-scale language model training on gpu clusters using megatron-lm ↩
-
https://zhuanlan.zhihu.com/p/5502876106 ↩
-
ZeRO: Memory Optimizations Toward Training Trillion Parameter Models ↩
-
https://developer.nvidia.com/zh-cn/blog/demystifying-ai-inference-deployments-for-trillion-parameter-large-language-models/ ↩