AI Hardware & Accelerators
导言
- 牧本定律由1987年牧村次夫提出,半导体产品的发展历程总是在“标准化”和“定制化”之间交替摆动,大概每十年摆动一次,揭示了半导体产品性能功耗和开发效率之间的平衡,这对于处理器来说,就是专用结构和通用结构之间的平衡—专用结构性能功耗优先,通用结构开发效率优先。
- 贝尔定律是由戈登贝尔在1972年提出的一个观察,即每隔10年,会出现新一代计算机(新编程平台、新网络连接、新用户接口、新使用方式),形成新的产业,贝尔定律指明了未来一个新的发展趋势,这将会是一个处理器需求再度爆发的时代,不同的领域、不同行业对芯片需求会有所不同,比如集成不同的传感器、不同的加速器等等。
生产特殊的硬件:
- 带来的加速比和能耗收益,达到10倍百倍都是很正常的。
- 但是开发成本也是巨大的,包括芯片设计,流片成本,软件栈的开发,商业化的推广。
- 开发周期也相当长。需要对当前的技术的未来具有前瞻性。不要生产出来就过时了。
常见的例子,用于并行计算的GPU, H265视频编解码单元, Google TPU芯片、车载芯片、手机AI芯片。
AI领域的至今不变的特点:
- 基于反向传播和梯度/参数更新的整体逻辑
- 需要保存大量的参数来表征问题,以高维矩阵的形式存储,所以矩阵运算十分常见
- 训练由于要计算并更新梯度,一般是计算密集。但是推理一般是访存密集。
现在大火的transformer,除非它就是AGI的最理想模型,不然为一个模型专门定制硬件,很容易钱就打水漂了。为自己的算法模型定制一块AI芯片,如特斯拉。但应用面越窄,出货量就越低,摊在每颗芯片上的成本就越高,这反过来推高芯片价格,高价格进一步缩窄了市场,因此独立的AI芯片必须考虑尽可能适配多种算法模型。1
当然,也可以从workload的应用出发,分析有什么重复的热点,值得做成专用的电路单元。
AI 芯片关键设计指标¶
Key Metrics
算力单位
- OPS
- MAC, Memory Access Cost: 模型运行时的内存占用量
- MACs,Multiply-Accumulate Operations, 乘加操作
- 但是 MAC 也指代单次的乘加操作
传统GPU¶
1. 加速矩阵运算¶
一是分块矩阵的One Shot流派,也有称之为GEMM通用矩阵乘法加速器,典型代表是英伟达、华为。
2. 数据流思想,¶
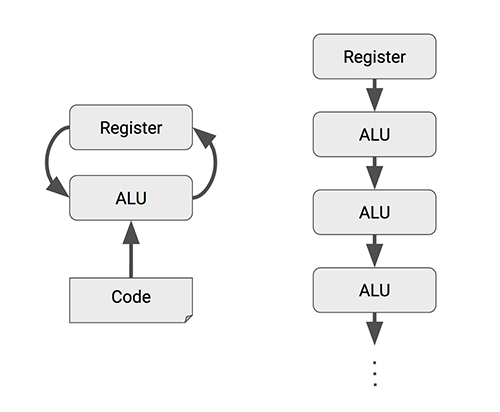
- 脉动阵列(systolic array)的数据流流派,典型代表是谷歌、特斯拉。
- 对于卷积操作,能做到一次访存后,流水线执行完一系列的卷积的乘加操作。

3. 存内计算¶
忆阻器阵列,和3D堆叠内存。
姜庆彩: FloatPIM: In-Memory Acceleration of Deep Neural Network Training with High Precision
姜庆彩: ViTCoD: Vision Transformer Acceleration via Dedicated Algorithm and Accelerator Co-Design
成本计算¶
24年2月,AI推理芯片Groq估算成本不菲8400万元。56
Tranformer应用的特点¶
- Self-Attention需要对输入的所有N个token计算N的二次方大小的相互关系矩阵
- 与CNN不同,Swin Transformer的数据选择与布置占了29%的时间,矩阵乘法占了71%,而CNN中,矩阵乘法至少占95%。1
如何加速Tranformer¶
苹果、高通、谷歌手机芯片的AI模块怎么设计的¶
终端侧AI才是生成式AI规模化的未来 | 高通颜辰巍@MEET2024