LLM Model
LLM通俗易懂的实现逻辑介绍
LLM Research path¶
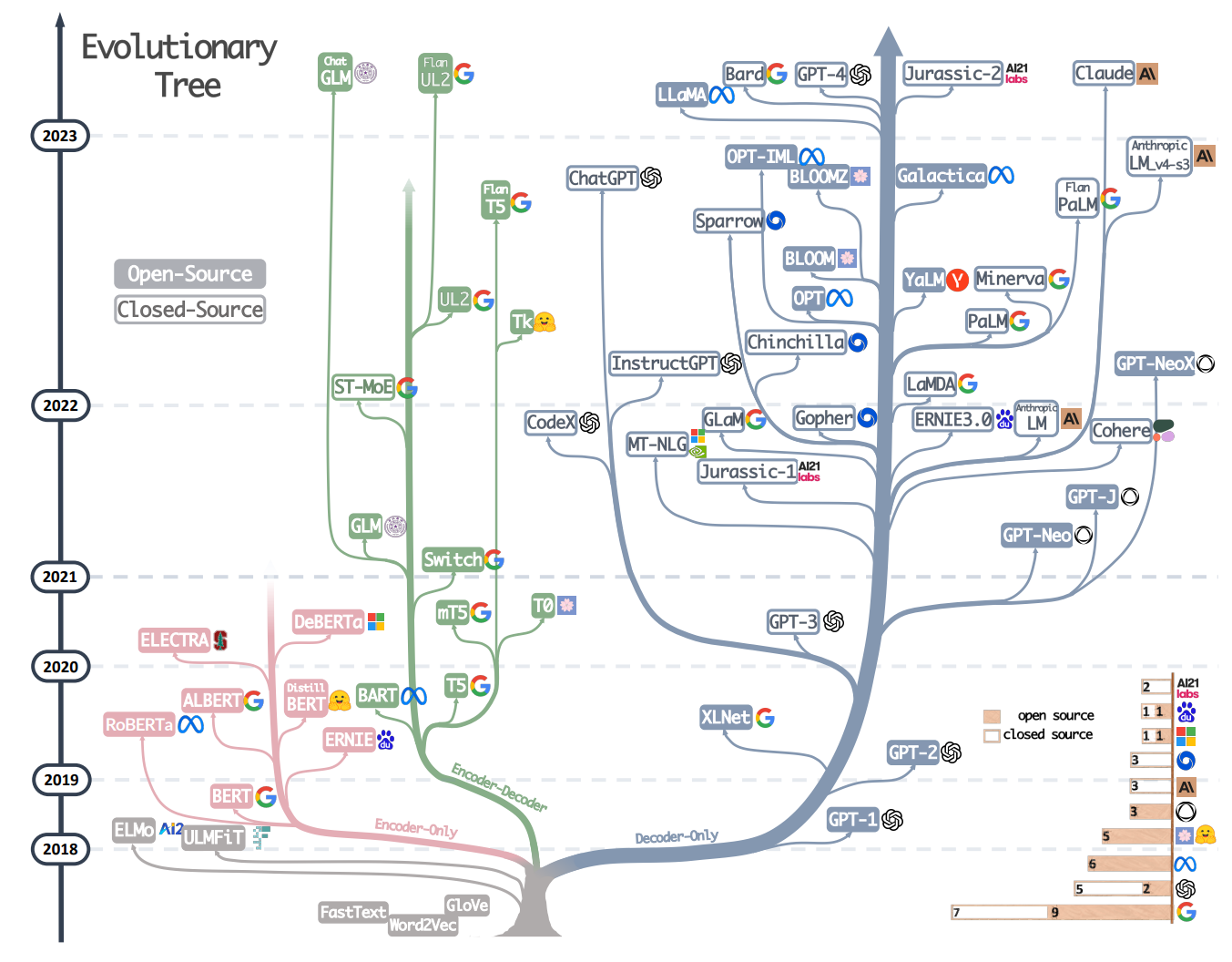

LLM Parameters Size¶
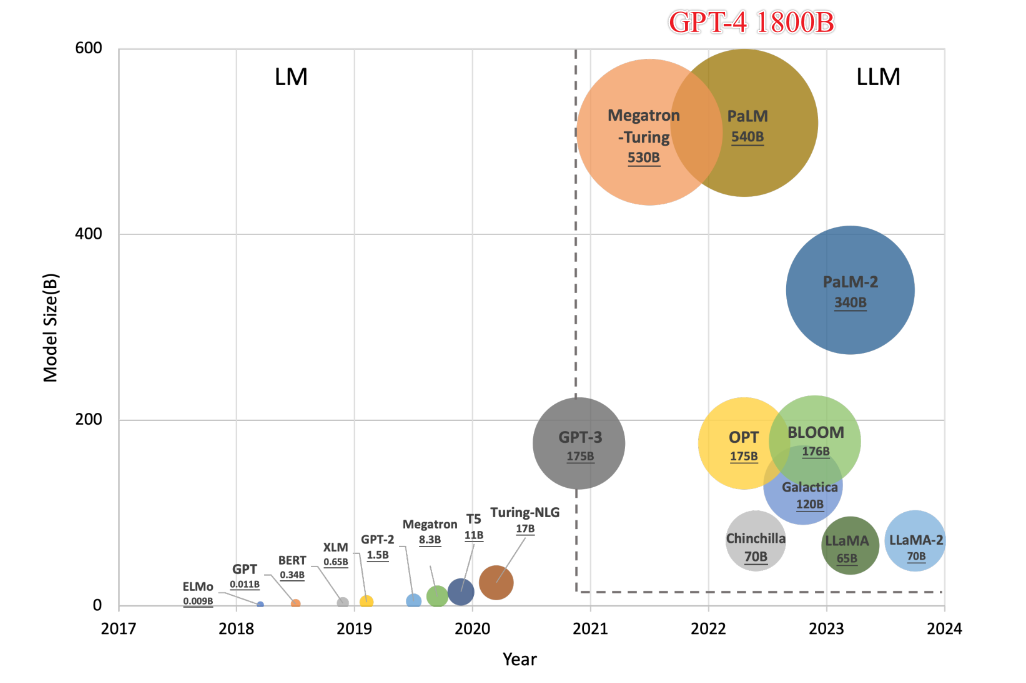
7B,70B to GPU memory?
B是10亿的单位,全精度是32位,也就是4字节。More in detail.
GPT-3(自回归模型)¶

- GPT的全称是Generative Pre-Trained Transformer。
- 2017年,OpenAI(2015年成立)提出GPT论文
- 2018.6 推出GPT1 1.2亿
- 2019.11 推出GPT2 15亿 。这时OpenAI没钱了,非盈利组织变收益封顶的盈利组织,微软注资10亿美元
- 2020.6 推出GPT3 1750亿,这时没有人工反馈,导致参数量再增大,效果也无法提升了。
- 2022.3 推出GPT3.5
- 2022.11 推出ChatGPT
- 2023.4 推出GPT-4, 虽然诞生于22年8月,OpenAI经过8个月的时间来确保对齐后才发布。
- 2017年,OpenAI(2015年成立)提出GPT论文
- GPT核心原理:根据前面输入的语句,推测下一个字是什么
- GPT 拥有一张包含了五万个单词的词汇表,它会基于互联网上的海量文本,大致了解每个单词后面可能会跟着哪些单词,并给出相应的出现概率。
- GPT模型的生成过程核心是
- 先通过无标签的文本去训练(无监督学习)生成语言模型,
- 再根据具体的NLP任务(如文本蕴涵、QA、文本分类等),来通过有标签的数据对模型进行fine-tuning微调(有监督学习、人工反馈的强化学习)。
- 它与ELMO一样,仍然是用语言模型进行无监督训练的,但是它用了特征提取能力更强的Transformer,并且是单向的Transformer。
GPT-3 模型的参数量达到 1750 亿,即便拥有 1024 张 80GB A100, 那么完整训练 GPT-3 的时长都需要 1 个月。
2021年1月,OpenAI官宣了120亿参数的GPT-3变体DALL-E。 多模态可以实现语言到图像的转化。
ChatGPT¶
- 使用了GPT-3.5大规模语言模型(LLM,Large Language Model),
- 并在该模型的基础上引入强化学习来Fine-turn预训练的语言模型。这里的强化学习采用的是RLHF(Reinforcement Learning from Human Feedback),
-
即采用人工标注的方式。目的是通过其奖励惩罚机制(reward)让LLM模型学会理解各种NLP任务并学会判断什么样的答案是优质的(helpfulness、honest、harmless三个维度)。
-
部分有趣的原理:关于token和无法反转字符
-
意义
- chatGPT貌似打通了机器理解人类自然语言的屏障,表面上能理解人们的意思。
- 如果机器能直接理解人类的目的,就不需要编程人员来实现我们的想法,可以让chatGPT理解并自主实现,AutoGPT的出现就是如此,去掉了对目的实现方式的深究,直接获得AI结果的方式。就是AIGC的核心。
- 这也激发了人们对AGI的畅想,期待着会自主思考(思维链CoT与常识)并学习进化的AI。
- 带来的思考
- 记忆力特别好,会找规律,但是不明白自己在说什么的小孩。(数学逻辑欠缺,如何修正?)
- 不理解真实世界,没有真正在“回答”问题,只是在模仿人类的语言行为
- 大力出奇迹,以及NLP+强化学习的方式能够取得很好的表现。
- 当无监督学习的数据量增大到一定到程度,有监督学习就算变少也不会影响模型效果。
- 到了GPT-3,当参数到达了1750亿以后,更是突然出现了诸如思维链等特性。
- 记忆力特别好,会找规律,但是不明白自己在说什么的小孩。(数学逻辑欠缺,如何修正?)
- 缺点
- 准确度(胡说 (人工标注强化学习过。过于专业或者网上缺少的知识,chatgpt难以回答
- 据对齐和伦理性
- AI 生成的东西会污染网络
- transform 绝对不是AGI的基础模型,不是未来。
- 关于最佳模型的讨论 - 2023北京智源AI大会
- Transformer不会是超强AI的模型架构,大语言模型(LLM)不理解世界运转逻辑,更强的AI模型应具备对现实世界的无监督学习能力
- 自回归模型”(Auto-regressive model)没有关于基础现实的知识,既缺乏常识也没法规划答案
如何使用LLM:
- (L)借助庞大的数据库: 头脑风暴
- (LM)语言模型
- 办公辅助,生成书信论文格式,谦卑语气的检讨书
- 整合版本的搜索引擎
- 快速入门概念:不熟悉的领域的基本操作( 如何写简单前端,关于这一点的准确性,由于是入门的问题,也能精确解决
- 模板或者格式化的工作 ,不再只限于重复工作
- 如何使用新编程语言,如何爬虫。
GPT-5 / 6¶
OpenAI 已经在尝试用AI训练(面临崩溃问题)和解释AI,并且直接从世界中学习
世界模型?¶
论文: A Path Towards Autonomous Machine Intelligence
通过世界模型,AI可以真正理解这个世界、能预测和规划未来。通过成本核算模块,结合一个简单的需求(按照最节约行动成本的逻辑去规划未来),它就可以杜绝一切潜在的毒害和不可靠性
这个未来如何实现?世界模型如何学习?杨立昆只给了一些规划性的想法,比如还是采用自监督模型去训练,比如一定要建立多层级的思维模式。他介绍了联合嵌入预测架构(JEPA),系统性地介绍了这一实现推理和规划的关键
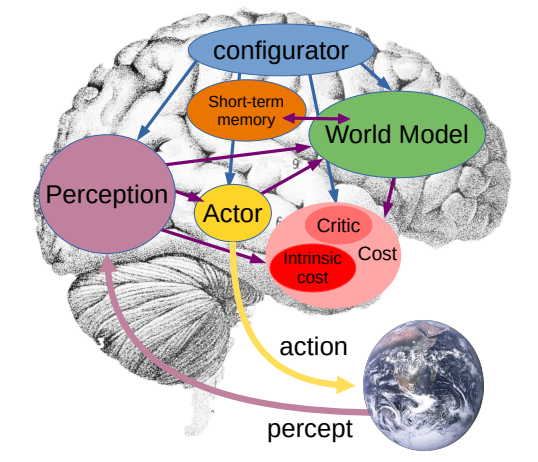
DeepSeek¶
见deepseekv3一文
QWQ¶
DeepSeek V3.2¶
K2-Thinking¶
251217 MiMo-V2-Flash 小米¶
MiMo-V2-Flash 是一个混合专家(MoE)语言模型,具有 309B 总参数 和 15B 活动参数。它专为高速推理和代理工作流设计,采用了一种新颖的混合注意力架构和多令牌预测(MTP),在实现最先进性能的同时显著降低了推理成本。
MiMo-V2-Flash 在长上下文建模能力和推理效率之间创造了新的平衡。主要特点包括:
- 混合注意力架构:以 5:1 的比例交错滑动窗口注意力(SWA)和全局注意力(GA),并使用激进的 128 令牌窗口。这通过可学习的 注意力沉降偏差 减少了近 6 倍的 KV 缓存存储,同时保持了长上下文性能。
- 这里之所以选泽混合SWA,是因为小米团队通过实验发现:SWA简单高效且易于使用,在通用任务、长上下文处理和推理能力上,其整体表现优于线性注意力(Linear Attention)。而且还可以提供固定大小的键值缓存(KV cache),便于与现有训练和推理基础设施集成。
- 多令牌预测(MTP):配备了一个轻量级 MTP 模块(每个块 0.33B 参数),使用密集 FFN。这在推理过程中将输出速度提高了三倍,并有助于加速 RL 训练中的推出。
- 高效预训练:使用 FP8 混合精度和原生 32k 序列长度,在 27T 令牌上进行训练。上下文窗口支持长达 256k 的长度。
- 代理能力:后训练利用多教师在线策略蒸馏(MOPD)和大规模代理 RL,在 SWE-Bench 和复杂推理任务中实现了卓越的性能。
- 一个有意思的点是,MiMo-V2-Flash采用了一种新的后训l练策略:多教师在线策略蒸馏+(Multi-TeacherOnlinePolicyDistillation,MoPD)。其核心是高效的在线策略学习机制:在通过SFT/RL获得领域专家教师模型后,学生模型从自身策略分布中采样(rollout),并利用多个教师提供的密集、逐token奖励进行优化。
- MOPD训练稳定目效率极高:与传统SFT+RL流程相比,仅需不到1/50的计算资源即可匹配教刻师模型的峰值性能。此外,MOPD采用解耦设计,支特灵活集成新的教师模型和ORM(On-Policy-Distillation),并自然实现“教与学”的闭环迭代:蒸馏得到的学生模型可发展为更强的教刻师模型,从而实现能力的持续自我提升。
在线与离线蒸馏¶
DeepSeek-V3,2的训练其实也采用专家模型蒸馏的思路:
- 对于每个任务,首先开发一个专门针对该领域的模型,所有专家模型均基于相同的预训练DeepSeek-V3.2基础模型进行微调。每个专家模型都通过大规模RL进行训练。
- 在专家模型准备就绪后,它们被用于生成最终模型微调所需的领域特定数据。
- 实验结果表明,在蒸馏数据上训练的模型,其性能仅略低于领域专用专家模型,而通过后续的RL训练,这一性能差距可以被有效消除。
DeepSeek-V3.2这种蒸馏策略其实属于off-policy distillation+,区别于on-policy distillation。
优劣势¶
关于off-policy distillation的劣势,Thinking machines的文章也进行了说明:
- on-policy训练的缺点在于,学生模型学习的上下文是教师常出现的情境,而不是学生自身经常会遇到的情境。这可能导致累积误差:
- 如果学生在早期犯了一个教师从未犯过的错误,它会逐渐偏离训练中观察到的状态。当我们关注学生在长序列上的表现时,这一问题尤为突出。
- 为了避免这种偏离,学生必须学会从自身的错误中恢复。
- off-policy distillation的另一个问题是,学生可能学会模仿教师的风格和自信,但不一定掌握其事实准确性。
这里有一个很好的类比:如果你在学习下棋,
- 在线策略强化学习(on-policy RL)类似于在没有指导的情况下自己下棋。比赛胜负的反馈直接与自己的表现相关,但每场比襄只会收到一次反馈,并且不会告诉你哪些走法对结果影响最大。
- 离策略蒸馏(off-policy distillation)则类似于观看国际象棋大师下棋:你观察到非常强的走法,但这些走法出现在新手玩家几乎不会遇到的棋局状态中。
待学习¶
A Survey of Large Language Models
ChatGPT, GPT-4, and GPT-5: How Large Language Models Work
参考文献¶
-
Harnessing the Power of LLMs in Practice A Survey on ChatGPT and Beyond ↩