导言
- 图片推理多采用各种GUI(ComfyUI, Stable Diffusion WebUI) 2
- 训练基于 kohya-trainer 和 GUI, 带标签的二次元图片数据可以从 danbooru 爬取。
- 模型和方法实现,如LyCORIS框架? 从civitai免费下载
Model download from civitai¶
- civitai优势:海量免费模型,效果图,和CLIP文本
- 注意类别 checkpoint model or LoRa model 。后续在ComfyUI的放置位置也不同。
- 还有18+的模型,不愧是你。
ComfyUI¶
特点:基于节点流程的 Stable Diffusion 操作界面,可以通过流程,实现了更加精准的工作流定制和完善的可复现性。
安装与配置¶
# Git clone this repo. (6.5MB)
git clone https://github.com/comfyanonymous/ComfyUI.git
# venv
conda create --name myenv python=3.11
conda activate myenv
# Nvidia GPU install pytorch (2.2GB)
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu121
# Dependencies
pip install -r requirements.txt
# download model from civitai
# Put your SD checkpoints (the huge ckpt/safetensors files) in: models/checkpoints
# Put your VAE in: models/vae
# lora in models/loras , and Unet in models/unet, and so on.
Running¶
# shaojiemike @ icarus3 in ~/github/ComfyUI on git:master o [10:43:10] C:130
$ python3 main.py --listen 222.195.72.213 --cuda-device 0
Set cuda device to: 0
Total VRAM 40338 MB, total RAM 515603 MB
Set vram state to: NORMAL_VRAM
Device: cuda:0 NVIDIA A100-PCIE-40GB : cudaMallocAsync
VAE dtype: torch.bfloat16
Using pytorch cross attention
Starting server
To see the GUI go to: http://222.195.72.213:8188
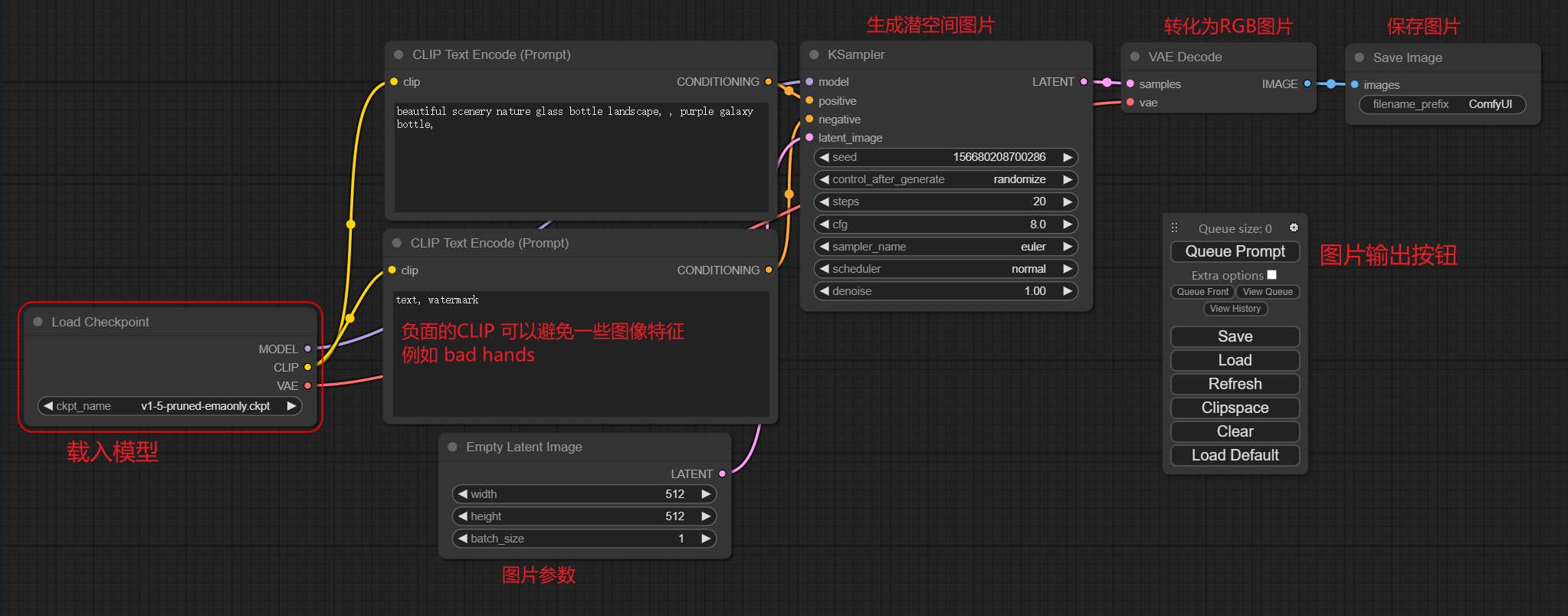
SDXL效果¶
选取模型。在推理的过程中,绿框标注了运行到了哪一步。
SDXL 推理速度、占用¶
naive的控制变量法,笼统分析一下。
默认配置¶
| plan | Max VRAM | time | step time | batch | resolution | steps | cfg |
|---|---|---|---|---|---|---|---|
| default | 7.4GB | 3.72s | 0.147 s/step | 1 | 512*512 | 20 | 8.0 |
CLIP text¶
文本限制的多少,对速度几乎没有影响。
分辨率 对 速度, 显存占用¶
| plan | Max VRAM | time | step time | batch | resolution | steps | cfg |
|---|---|---|---|---|---|---|---|
| batch 4 | 8.8GB | 4.83s | 0.205 s\/step | 4 | 512*512 | 20 | 8.0 |
| 768x768 | 13.6GB | 9.01s | 0.357 s/step | 4 | 768x768 | 20 | 8.0 |
| 1280x768 | 14.7GB | 12.52s | 0.492 s/step | 4 | 1280x768 | 20 | 8.0 |
| 1024x1024 | 18.3GB | 12.29s | 0.534 s/step | 4 | 1024x1024 | 20 | 8.0 |
Step 的效果分析¶
- Step 1 2 4 8 16 32 64 结果图对比。 to add
- 8步之前都没有扩散收敛,还是一片黑色。
| plan | Max VRAM | time | step time | batch | resolution | steps | cfg |
|---|---|---|---|---|---|---|---|
| baseline | xxx | xxx | xxx | 1 | 1024x1024 | ? | 8.0 |
repeat try 5 times
| step num -> | 1 | 2 | 4 | 8 | 16 | 32 | 64 |
|---|---|---|---|---|---|---|---|
| min time(s) | 0.85 | 0.63 | 1.06 | 2.44 | 3.91 | 7.65 | 13.41 |
| max time(s) | 1.07 | 1.37 | 2.01 | 3.28 | 4.35 | 8.45 | 14.16 |
CFG 的影响¶
- The CFG Scale, standing for Classifier-Free Guidance Scale.
- range from 7 to 11.
- 较高的CFG比例值会导致输出图像与输入提示或图像更加一致,但会牺牲质量。
- 相反,较低的CFG比例值会产生质量更好的图像,但可能与原始提示或图像不同。
- 效果图对比 todo
- 如下,对时间,和显存占用基本没有影响。
| plan | time | batch | resolution | steps | cfg |
|---|---|---|---|---|---|
| cfg 7 | 14.82 | 1 | 1024x1024 | 64 | 7.0 |
| cfg 8 | 14.16 | 1 | 1024x1024 | 64 | 8.0 |
| cfg 11 | 14.76 | 1 | 1024x1024 | 64 | 11.0 |
batch 对 速度, 显存占用¶
batch 就是并行度,也就是图片数量。
| plan | Max VRAM | time | step time | batch | resolution | steps | cfg |
|---|---|---|---|---|---|---|---|
| default | 7.4GB | 3.72s | 0.147 s/step | 1 | 512*512 | 20 | 8.0 |
| batch 2 | 7.6GB | 3.94s | 0.161 s/step | 2 | 512*512 | 20 | 8.0 |
| batch 4 | 8.8GB | 4.83s | 0.205 s/step | 4 | 512*512 | 20 | 8.0 |
| batch 8 | 9.6GB | 7.64s | 0.297 s/step | 8 | 512*512 | 20 | 8.0 |
| batch 16 | 18.3GB | 12.00s | 0.481 s/step | 16 | 512*512 | 20 | 8.0 |
| batch 32 | 27.6GB | 23.35s | 0.925 s/step | 32 | 512*512 | 20 | 8.0 |
Nsight System 分析¶
设置path为/staff/shaojiemike/github/ComfyUI. Program为/staff/shaojiemike/miniconda3_icarus0/envs/myenv/bin/python3 main.py --listen 222.195.72.213 --cuda-device 0
程序结构¶
先不插入 NVTX分析, 由于step=20, 可以看出20个迭代步时间基本相同,结构也相同。

具体到每一步的组成为下图:

其中细算的kernel Zoom in 放大后,交替的使用了下面的CUDA API:
func浅蓝色cudaMallocAsync红色cudaFreeAsync浅红色cudaMemsetAsync浅绿色- 灰色 代表组成更杂乱,需要zoom in来细化。
Async suffix
CUDA API函数名中的“Async”后缀表示相应的操作是异步的。在CUDA中,异步函数在操作完成之前将控制返回给调用程序。这允许CPU在GPU在后台处理请求的操作时继续执行其他任务或计算。
Kernel热点¶
推理过程很明显由几种kernel组成,而且看名字就是pytorch的kernel。
ampere_fp16_s16816gemm_fp16_128x256_ldg8_relu_f2f_stages_64x3_tn这似乎是与矩阵乘法有关的内核名称(gemm通常表示通用矩阵乘法),使用了半精度浮点运算(fp16)。具体细节包括128x256的矩阵块大小,ldg8(可能表示使用8字节事务加载全局内存),以及涉及64x3操作的一些阶段。"relu"表明可能涉及修正线性单元(ReLU)激活函数。该内核似乎经过了对Ampere架构的优化。pytorch_fmha::fmha_fwd_loop_kernel<FMHA_kernel_traits<(int)256, (int)64, (int)16, (int)1, (int)4, (unsigned int)8, __half>, (bool)0, (bool)0, (bool)0>(pytorch_fmha::FMHA_fprop_params)这似乎是PyTorch(一种流行的深度学习框架)中与混合精度注意力机制有关的内核,可能涉及多头注意力(给定 "fmha")。它包含一个前向循环内核,具有特定的特征,如256个线程,64个warp,每个线程16个元素。使用__half表示它使用了半精度浮点数据类型。void at::native::elementwise_kernel<(int)128, (int)4, void at::native::gpu_kernel_impl<at::native::CUDAFunctor_add<c10::BFloat16>>(at::TensorIteratorBase &, const T1 &)::[lambda(int) (instance 1)]>(int, T3)这似乎是与PyTorch的本地GPU实现中的逐元素操作相关的内核。它使用了128个线程和4个元素每个线程。该操作是一个加法(CUDAFunctor_add),涉及到BFloat16数据类型。Kernel占比8.2%。 其中是NV的官方库void cutlass_cudnn_infer::Kernel<cutlass_tensorop_f16_s16816fprop_optimized_f16_128x128_32x4_nhwc_align8>(T1::Params)
cudnn,cublas,cutlass的区别
cudnn、cublas 这样的基础算子原语库在常见的卷积层上性能表现很好,通常都能够满足用户的需求,但是在面对用户高度定制化的算法时,基础算子库往往并不能充分发挥硬件的性能。3
- 这是由于算子优化的长尾问题引起的,基础算子库引入了许多卷积优化的通用策略,但是这些优化的策略并不能覆盖所有的情况,实际算法中的卷积层有可能并不能从通用的优化策略中获得收益,从而无法充分发挥硬件的性能。
- 基础算子库的另一个问题是用户无法对这些基础算子进行定制化开发,当算法开发人员想为卷积算子添加一种新的激活函数,或者想添加一种特殊的卷积算子(比如:LocalConv)时,就会变得束手无策。
cutlass 是 NVIDIA 推出的一款线性代数模板库,它定义了一系列高度优化的算子组件,开发人员可以通过组合这些组件,开发出性能和 cudnn、cublas 相当的线性代数算子。
Nsight Compute¶
基本概念¶
ckpt, safetensors¶
- ckpt 是 pytoch 使用 pickle 序列化存储的格式,简单易用,但是会可能序列化某些 python 执行代码。
- safetensors 是 HuggingFace 推出的新的模型存储格式,不会包含执行代码,不需要反序列化,加载更快,目前已经是主流的 Stable Diffusion 模型存储格式。