[LLM]: DeekSeekV3
导言
本来在多模态组,结果被拉去优化TX的dspv3部署,还是要熟悉相关概念逻辑。
模型分类¶
- deepseek V3:对话模型,最新版deepseek基座模型(无深度思考能力),其指令版本具备对话能力,
- 与gpt-4o,qwen2.5系列等模型属于同阶段模型。参数量671B,当前最强开源基座模型,但参数量巨大,完整部署大约需1300G+显存。
- deepseek R1:推理模型,【也就是最近爆火的模型,由于其在相对低资源的条件下,SFT+多阶段强化学习训练出能力超强推理能力而闻名】。
- 擅长复杂问题的推理,准确率相较于deepseek V3更高,但思考过程过长。
- deepseek R1-zero:推理模型,可以理解deepseek R1的先验版本,
- R1-zero的训练是一个探索性的过程,它验证了RL本身对于激励base模型产生推理的能力。
- 在这个探索结论上,才开始正式进入R1的训练。【此模型为实验性质,其能力低于deepseek R1,因而也未面向C端用户上线】
- DeepSeek-R1-Distill-Qwen-xxxB:知识蒸馏版的推理模型,
- 使用deepseek R1中间阶段的80w条训练数据,对Qwen2.5系列进行SFT指令微调的模型。(无强化学习过程,可以理解为COT思维链数据的SFT)大家平时听到的残血版,蒸馏版,大多指此版本。
特点¶
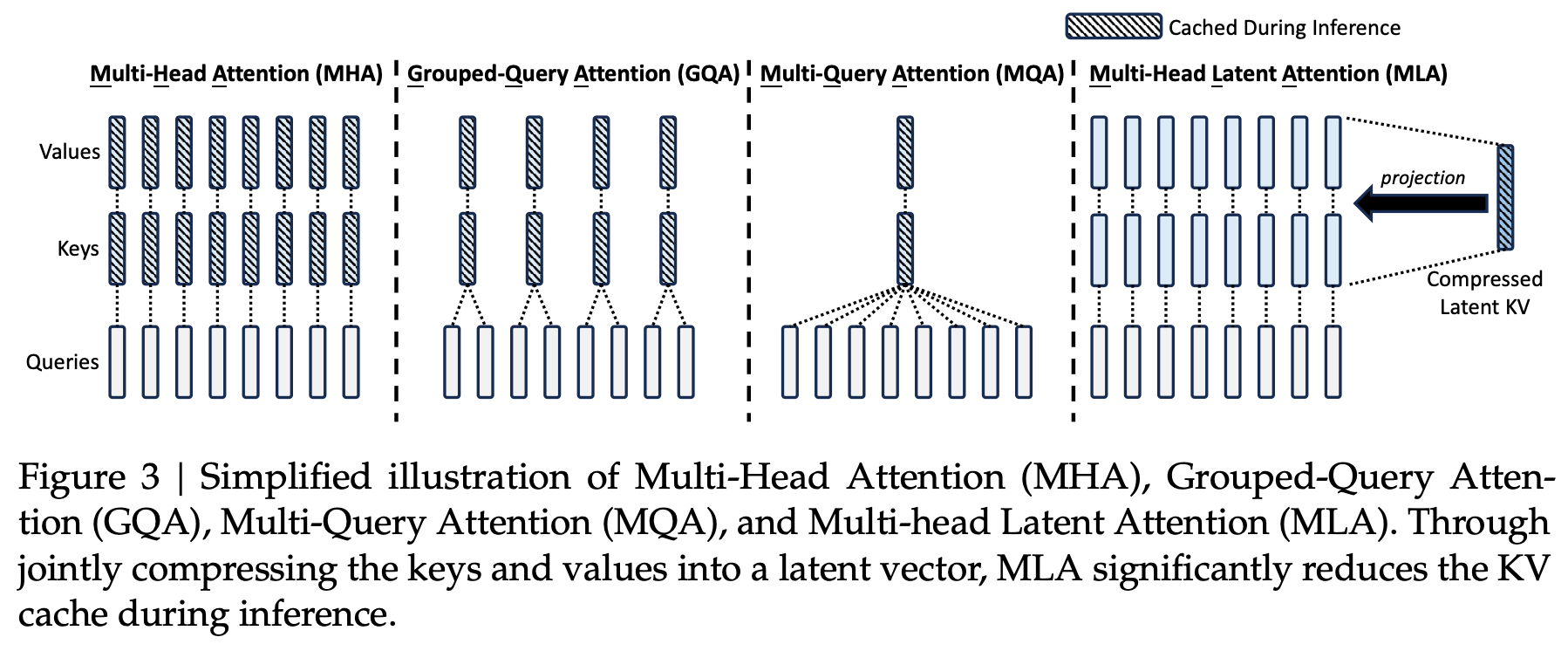
- 多维度注意力压缩(Multi-head Latent Attention,MLA):这是继承自DeepSeek-V2的注意力优化方案,通过将传统注意力头的维度压缩至潜在空间(如从128维降至32维),在保持信息捕获能力的同时减少75%的注意力计算量。同时采用分组交互机制,不同注意力头在潜在空间进行知识蒸馏,避免信息的冗余。
- 深度优化的MoE架构(DeepSeekMoE):采取对专家网络进行细粒度拆分的策略,将每个专家拆分为16个微型子专家(Mini-expert),通过动态路由选择最优组合,提升参数的利用率。引入专家容量弹性伸缩机制,根据输入复杂度自动调整各层专家数量,实现"瘦层肥层"动态调节。
- 零辅助损耗负载均衡:传统的大模型方案主要通过添加辅助损失函数(如专家负载方差惩罚项)强制均衡专家使用率,但会干扰主任务训练。在DeepSeek-V3中基于路由概率的自然分布熵最大化原则,设计了自适应的专家选择策略,无需额外损失项即可实现95%+的专家利用率。
- 训练稳定性策略:通过梯度噪声自适应裁剪(Gradient Noise-Adaptive Clipping)技术,成功抑制万卡级分布式训练中的梯度异常波动,为大模型训练提供稳定性保障。
- Group Relative Policy Optimization(GRPO)强化学习技术
MLA+MOE¶
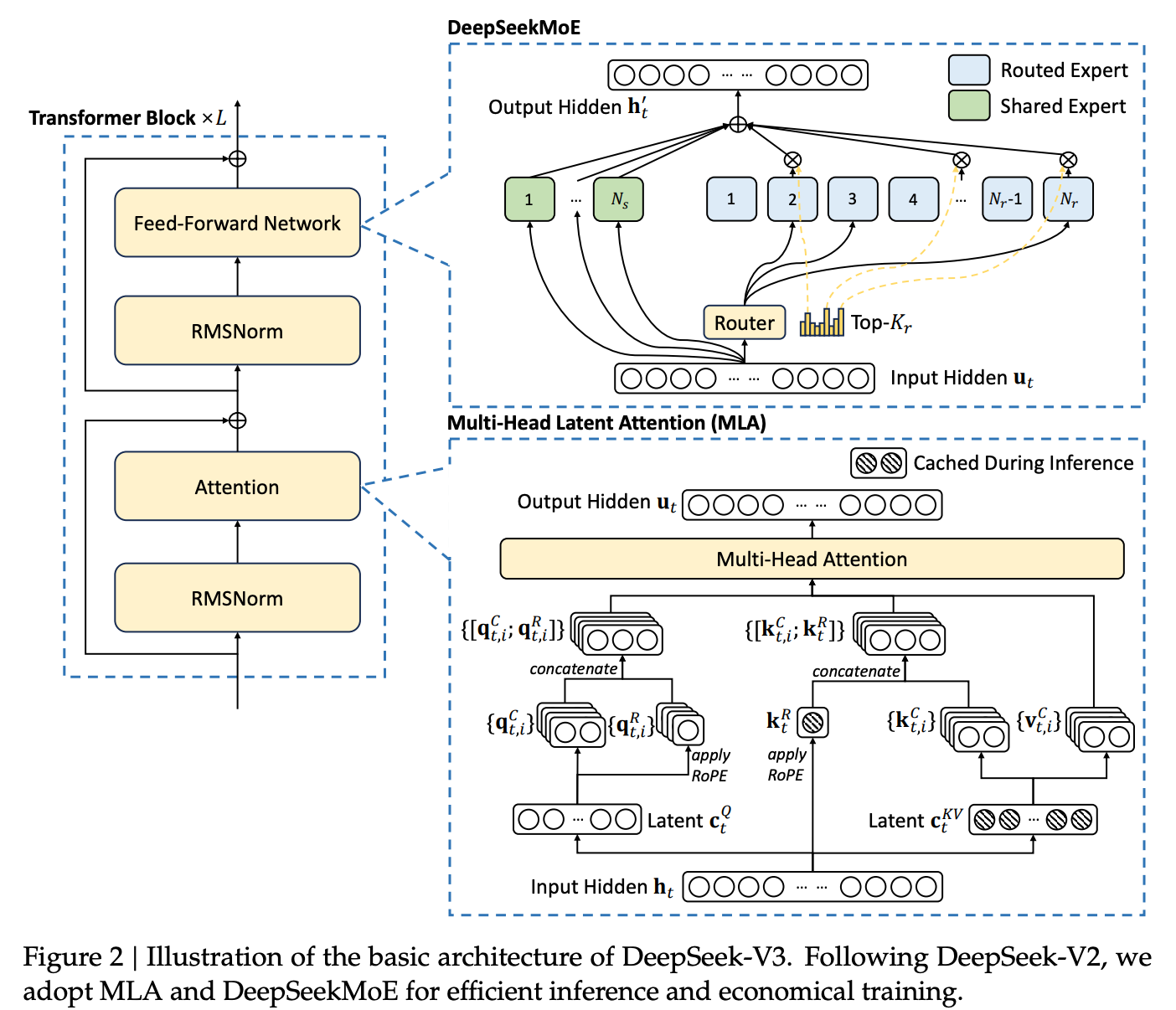
MHA、MQA、GQA 2 MLA¶
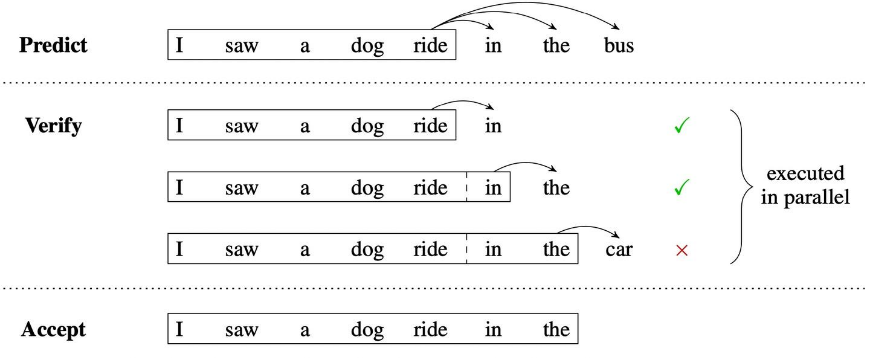
- 阶段1:predict (预测),利用 k个Head一次生成 k个token,每个Head生成一个token2
- 阶段2:verify(验证),将原始的序列和生成的 k个token拼接,组成 pair
- 阶段3:accept(接受): 选择 head预估结果与 label一致的最长的 k个token,作为可接受的结果。