Introduction to AI and Machine Learning Basics
摘要
AI相关的基础知识。 可以参考华为昇腾架构师的博客。
AI(Artificial Intelligence) vs. Machine Learning vs. Deep Learning¶
AI是人工智能(Artificial Intelligence)的缩写,是指通过计算机系统和算法模拟、模仿和扩展人类智能的科学和技术领域。
人工智能的目标是使计算机具备像人类一样的智能和学习能力,能够理解、推理、学习、决策和解决问题。
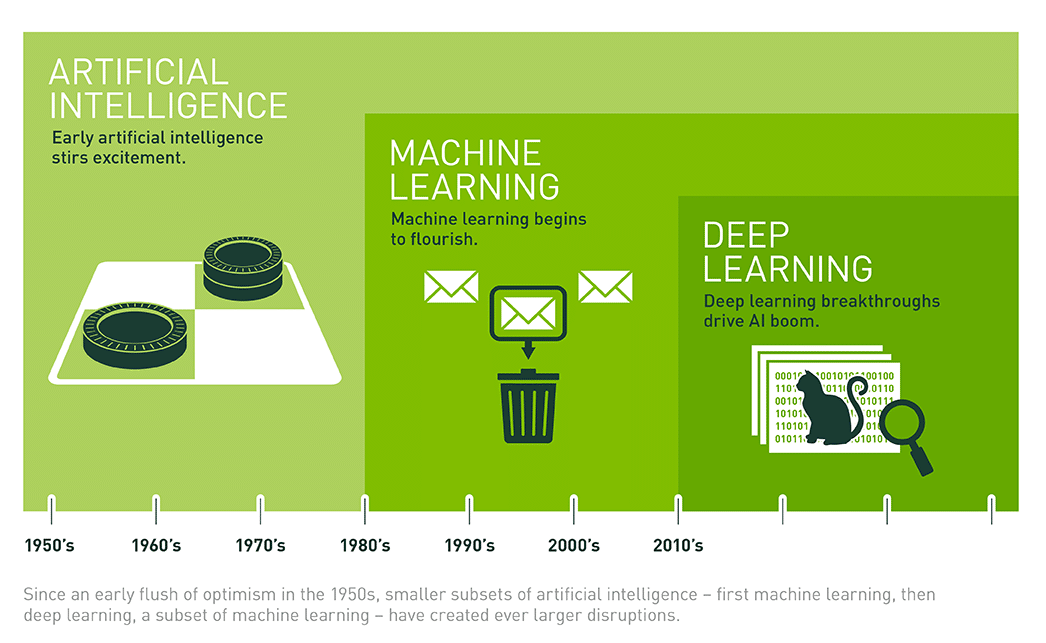
这张图很好的说明了发展的历程。很早人们就注意到了人工智能的概念,但是直到GPU的出现,极大的提高了并行运行的效率,这个深度学习才高速发展起来。
强人工智能(General AI)vs. 弱人工智能(Narrow AI)¶
AI先驱的梦想就是构建具有与人类智慧相同特征的由当时新兴计算机构成的复杂机器。这个概念就是我们所说的“强人工智能(General AI)”,这是一个神话般的机器,具有我们所有的感觉(甚至更多),我们所有的理智,像我们一样想。
“弱人工智能(Narrow AI)”的概念,是一种能够执行特定任务的技术,或者比我们人类能做的更好的技术。例如,Pinterest利用AI进行图片分类,Facebook使用AI对脸部识别。
AI Up and Down¶
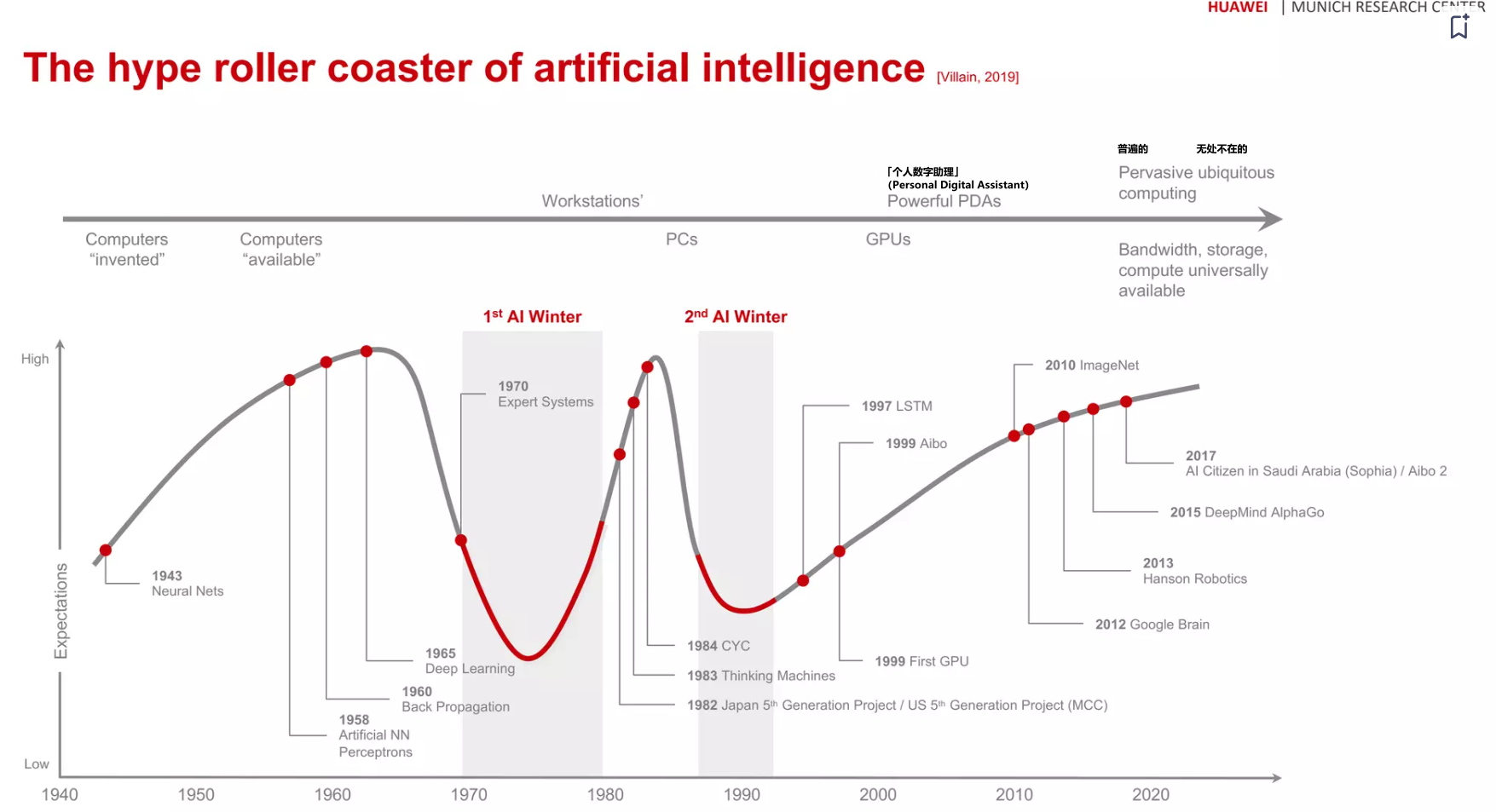
两次 AI 寒冬
第一次和第二次AI寒冬分别发生在20世纪中叶和末叶,这两个时期都伴随着对人工智能的热情减退和资金投入的减少。以下是两次AI寒冬的原因和后来的复苏:
第一次AI寒冬(约1974年 - 1980年代中期):
原因:
- 不切实际的期望: 早期对人工智能的期望过高,人们对AI系统的性能和能力寄予了过高的期望,但技术水平尚未达到这些期望。
- 技术限制: 计算机硬件和算法的限制使得早期的AI系统无法胜任更为复杂的任务,导致实际应用受限。
- 资金压力: 由于早期的研究成果与商业应用之间存在较大差距,资金投入减少,导致了一些研究项目的停滞。
走出方式:
- 专注于实际问题: AI研究者逐渐转向解决实际问题,例如专注于专家系统和应用程序的开发,而不是过于抽象的问题。
- 技术进步: 随着计算能力的提升和新的算法的发展,AI技术逐渐变得更加实用和可行。
第二次AI寒冬(1987年 - 2000年代初):
原因:
- 专家系统破产: 专家系统在商业应用上的表现未能达到预期,一些项目被认为是失败的,导致对AI的信心下降。
- 资金问题: 随着专家系统破产,投资者和企业减少对AI的投资,导致了一段时间的资金匮乏。
- 技术局限: 一些重要的技术问题,如处理不确定性和处理大规模数据的能力,限制了AI的进展。
走出方式:
- 机器学习的崛起: 随着机器学习算法的发展,尤其是深度学习的崛起,AI能力得到了显著提升。
- 大数据的作用: 数据的可用性和处理能力的提升,使得机器学习能够更好地处理复杂任务。
- 商业应用的成功: 成功的商业应用案例,如互联网搜索、语音助手和推荐系统,提高了对AI的信心,吸引了更多的投资和关注。
总体而言,每一次AI寒冬后的复苏都是通过技术创新、实际应用的成功以及对AI潜力的重新认知来实现的。
符号主义与行为主义¶
AI发展的历史中,符号主义(Symbolism)和行为主义(Behaviorism)是两种重要的思想流派,它们分别代表了人工智能研究中不同的理念和方法论。这两种思潮在人工智能的发展过程中都有着重要的影响。
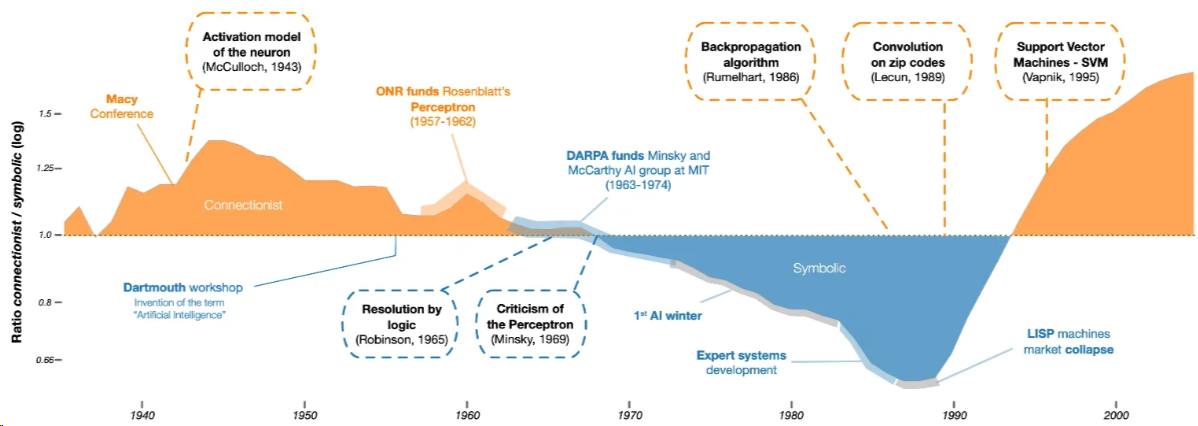
1. 符号主义(Symbolism)¶
符号主义,也被称为逻辑主义(Logicism),是一种认为智能可以通过符号操作和逻辑推理实现的人工智能方法。这一流派基于这样的假设:人类的认知过程可以通过符号操作来模拟,并且符号处理系统可以用来构建智能系统。
符号主义的特点:¶
- 符号操作:符号主义认为,智能可以被形式化为对符号的操作。符号可以代表现实世界中的对象、关系和规则,智能系统通过符号的操作来实现推理和问题解决。
- 规则与逻辑推理:符号主义的方法通常基于明确的规则和逻辑推理系统。例如,专家系统就是典型的符号主义AI,通过一系列的“如果-那么”规则来推理和决策。
- 高层抽象:符号主义更多关注高层次的抽象问题,如知识表示、推理机制、规划等。这类系统依赖于人类编码的知识库和逻辑规则。
典型代表:¶
- 逻辑学派:由数学家和逻辑学家主导的人工智能研究,如图灵机、数理逻辑、定理证明等。
- 专家系统:如Mycin、Dendral等,这些系统依赖于预定义的规则和知识库来执行任务。
- GOFAI(Good Old-Fashioned AI):20世纪50年代到80年代的传统人工智能方法,大多基于符号处理和逻辑推理。
2. 行为主义(Behaviorism)¶
行为主义是一种强调通过环境刺激与反应的关系来理解和构建智能的理论,强调通过学习和行为的调整来实现智能。它的理念更多与学习理论和经验积累相关,认为智能是通过适应环境和从反馈中学习而逐渐形成的。
行为主义的特点:¶
- 刺激-反应模型:行为主义的核心是通过对环境的反应来理解智能。系统通过接收输入(刺激),产生输出(反应),并根据反馈调整行为。
- 学习与经验:行为主义重视学习过程,特别是在动态环境中的学习,如强化学习。通过不断的试错和反馈,系统逐渐优化其行为策略。
- 神经网络与连接主义:行为主义的理念逐渐演变成了连接主义(Connectionism),这也是现代深度学习的基础思想。连接主义强调通过模拟神经网络的学习过程来实现智能。
典型代表:¶
- 强化学习:强化学习是一种典型的行为主义方法,通过奖励和惩罚机制引导系统学习最优策略。
- 神经网络:神经网络尤其是深度神经网络的崛起代表了行为主义方法的应用,这种方法通过大量数据和训练来逐步调整网络的权重,实现学习和智能。
- 感知器模型:感知器是早期神经网络的一种,它通过调整权重来学习模式分类任务。
3. 符号主义与行为主义的比较¶
- 知识表示:
- 符号主义依赖显式的知识表示,使用规则、逻辑和符号来编码世界信息。
-
行为主义更倾向于隐式的知识表示,通过学习过程在神经网络的权重中编码知识。
-
学习方式:
- 符号主义通常依赖于人工编码的规则和逻辑,而不是通过学习获得的知识。
-
行为主义则强调从数据中学习,通过环境的反馈进行知识的积累。
-
计算模型:
- 符号主义基于传统的计算模型,如图灵机,强调逻辑推理的精确性。
- 行为主义更关注基于统计和概率的方法,如神经网络的加权计算,强调学习能力和适应性。
4. 两者的结合与现代发展¶
尽管符号主义和行为主义在理念上存在差异,但现代人工智能研究逐渐开始探索两者的结合。例如:
-
神经符号学习:这是一种将符号主义的逻辑推理和行为主义的神经网络学习结合起来的方法,尝试利用符号表示的解释性与神经网络的强大学习能力。
-
深度学习中的规则嵌入:一些研究者在神经网络中嵌入符号规则,以便模型能够在遵循规则的同时进行灵活的学习。
随着人工智能的发展,符号主义和行为主义的方法都在不断演变,结合两者优势的方向越来越多。
常见的任务¶
数据来自文本和图像两类, 很自然有下面几大类。
- 自然语言处理(Natural Language Processing,NLP):NLP任务涉及处理和理解人类语言文本。
- 包括文本分类、命名实体识别、情感分析、机器翻译等。
- 大型语言模型Large Language Model 核心原理是根据前文推算出下一个可能发生的字的模型,能够理解和生成语言,具备对话、问答、翻译、摘要等能力。
- 计算机视觉(Computer Vision):计算机视觉任务涉及处理和分析图像和视频数据。
- 包括目标检测、图像分割、人脸识别、图像生成,医学影像标注,自动驾驶等。
- AIGC(AI generated content)是指由人工智能生成的内容,
- 包括文本续写、文字转图像视频、AI主持人、音乐生成、游戏场景生成、代码补全与生成等应用。
- 生成模型(Generative Models):生成模型是指能够生成新的数据样本的模型。
- 包括生成对抗网络(GANs)、变分自编码器(Variational Autoencoder,VAE)等。
- AGI 通用人工智能
- 普遍认为AGI将在2030年左右到来 —— 2022年 AIGC元年的观点。
- LeCun 世界模型?!
细分的领域¶
包括:
- HPC/科学计算 + AI
- 异常检测(Anomaly Detection):异常检测任务涉及识别与正常行为模式不符的异常样本或事件。
- 包括检测欺诈行为、网络入侵、设备故障等。
- 分类问题(如图像分类、垃圾邮件检测等)和回归问题(如房价预测、股票价格预测等)
- 监督学习(Supervised Learning):在监督学习中,模型通过使用标记好的训练数据来学习输入与输出之间的映射关系。
- 聚类(将相似的数据点分组)和降维(减少数据维度)
- 无监督学习(Unsupervised Learning):在无监督学习中,模型从未标记的数据中发现数据之间的结构、模式或关系,而无需预先提供标签信息。
- 机器人控制、AI与人的游戏对抗、游戏玩法优化
- 强化学习(Reinforcement Learning):在强化学习中,模型通过与环境进行交互来学习最佳行为策略。模型根据环境的反馈(奖励或惩罚)来调整自己的行为,以最大化累积奖励。
- 大模型在具体任务上的加速学习
- 迁移学习(Transfer Learning):迁移学习是指将在一个任务上学到的知识应用到另一个相关任务上。通过在一个大规模任务上训练模型,然后将其用于相关任务,可以加快学习速度并提高性能。
智能体的等级¶
OpenAI 24年7月就提出 5种水平的AI的分类。
- 一级:聊天机器人,这是能以对话语言和人类互动的AI。
- 二级:推理者,这种AI可以解决人类级别的问题。
- 三级:智能体,这种AI是可以采取行动的系统。
- 四级:创新者,这是可以帮助发明创造的AI。
- 五级:组织,这种AI可以完成一个组织的工作。
25年年中,有论文细化了该智能体的分类:
受汽车工程师协会(SAE)自动驾驶六级分类的启发,智能体也根据其功能和能力被划分为以下层级:
- L0——无 AI,具备工具(有感知能力)和行动;
- L1——使用基于规则的 AI;
- L2——用基于模仿学习(IL)/强化学习(RL)的 AI 替代基于规则的 AI,增加推理和决策能力;
- L3——应用基于大型语言模型(LLM)的AI 替代基于 IL/RL 的 AI,并设置记忆和反思功能;
- L4——在 L3 的基础上,实现自主学习和泛化能力;
- L5——在 L4 的基础上,增加个性(情感 + 性格)和协作行为(多智能体)。
AI 已实现¶
过去十年AI算力增长5000倍¶
在过去十年里,GPU的AI推理性能提升了五千倍,其中只有三倍来自工艺进步(摩尔定律)。Bill Dally揭示了其余提升的真正来源:数值表示(如从FP32到FP4带来了32倍提升)、复杂指令集(如矩阵乘法指令将开销降至极低)、以及稀疏性利用。但下一个十年,精度很难降低,大约在30~1000倍之间。 参考: Bill Dally - Trends in Deep Learning Hardware
价值落地爆发期¶
AI 挑战 与 展望¶
人工智能三定律¶
- 第一定律:任何有效的控制系统都必须与它所控制的系统一样复杂(阿什比定律(Ashby’s law))3
- 第二定律:生物体最简单的完整模型就是生物体本身。试图将系统的行为简化为任何形式的描述都会使事情变得更复杂,而不是更简单(冯·诺依曼提出)
- 第三定律:任何简单到可以理解的系统都不会复杂到可以智能地运行,而任何复杂到可以智能运行的系统都会复杂到无法理解(第三定律存在一个漏洞—完全有可能在不理解智能的情况下将它构建出来)
AI的软硬协同形态?可朽计算/凡人计算¶
-
在传统计算中,计算机被设计为精确地遵循指令。我们可以在不同的物理硬件上运行完全相同的程序和神经网络,这意味着程序或神经网络的权重中的知识是永生的(immortal),不依赖于任何特定的硬件。但要实现这种永生,需要付出高昂的代价—需要高功率运行晶体管,以便它们以数字方式运行。
-
放弃计算机科学最基本的原则—软硬件可以分离,从而得到凡人计算(Mortal Computation)。4
- 凡人计算的巨大优点:
- 以更少的能量运行大语言模型之类的AI,特别是使用更少的能量来训练AI大模型。通过放弃硬件(身体)和软件(灵魂)的分离,我们可以节省大量能源,可以使用非常低功耗的模拟计(这正是大脑正在做的事情)
- 获得更便宜的硬件,硬件可以在3-D中便宜地生长,而不用在2-D中非常精确地制造。这需要大量的新的纳米技术,或可能需要对生物神经元进行基因改造。
- 凡人计算面临两大问题:
- 1)学习过程必须利用它所运行的硬件的特定模拟属性,而无需确切知道这些属性是什么,这意味着无法使用反向传播算法(backpropagation)来获得梯度,因为反向传播算法需是前向传播的精确模型;
- 2)凡人计算的生命是有限的,当特定的硬件死掉时,它学习的知识会随之消亡,因为知识和硬件错综复杂地绑定在一起;解决方案是在硬件失效前,将知识蒸馏出来给学生。
类似的观点Biological Neural Network
奇点时刻¶
如果我们翻开哲学家戴维·查尔默斯(David J. Chalmers)那篇经典的《奇点:哲学分析》,会发现当下的疯狂景象,不过是这套严密逻辑推演的必然兑现。论文地址
在查尔默斯的推导模型中,我们正处于一个被称为「扩展前提(Extension Premise)」的关键节点。
他将这一过程量化为从AI到AI+再到AI++的阶跃:
- AI:人类水平的人工智能。
- AI+:超越人类最强大脑的智能。
- AI++:超级智能,其超越程度正如人类超越老鼠一般。
正如查尔默斯引用的I.J. Good在1965年的那个著名论断:「超智能机器(Ultraintelligent Machine)将是人类需要制造的最后发明」。
逻辑非常性感且冷酷:
- 机器设计机器:既然设计机器本身是一种智力活动,那么一台超越人类的机器(AI+),必然能设计出比人类所能设计的更好的机器。
- 递归的雪崩:这台被AI+设计出的新机器,拥有更强的设计能力,它将设计出下一代更强的机器。
- 无限逼近:只要这台机器能通过编写代码来优化自身,我们将无可避免地迎来一场「智能爆炸」。
我们现在看到的,正是查尔默斯所描述的「速度爆炸」与「智能爆炸」的完美合流。当模型开始比人类更擅长优化算法时,我们就不再是处于一个线性的增长曲线上,而是站在了垂直墙面的底端。
我理解的世界模型(2023版本)¶
- 当前的网络设计,相对于复杂的问题还是太过简单了, 或许网络的复杂预留了空间来学习到表征问题的参数,但是没有特殊设计的网络难以快速学习到。(就类似于视频播放时没有专用的解码器)(并不是增加了网络的层数,网络就复杂了,只是网络的某个维度的表征能力上限变高了。
- 递归拆分模型:需要使用我们已有的知识,先尽可能的将输入空间划分成更小的子空间,网络需要拟合的问题就会变得更简单。
- 思路来源:世界模型,和逻辑链。还有AI4HPC时,设计网络支持粒子的平移旋转不变性。
- 划分的维度:文本和图像的逻辑关系,和情感色彩。(当然怎么用导数连续的数学方式表达是一个关键问题。
- 划分的举例: 1. 文本可以把主谓宾,疑问句陈述句反问句都识别出来。 2. 图像可以先做对象识别,把人物,物体,动物,场景识别出来, 3. 然后比如对于人物,把头,身体和手腿识别出来, 4. 再在脸里面识别出眼睛,鼻子,嘴。 5. 假如人为先分类到了嘴的维度,留给AI表征的维度就很简单了,就嘴形,大小,厚度,唇色和质感。 6. 如果分类到了唇色这个维度,AI需要表征的就色号一个维度了
- 好处: 1. 评价维度不再单一,并且可跟踪。 2. 可解释, 3. 可控。限制AI的认识维度的类别,比如去掉毒品和犯罪的分类。
- 可能的缺点:需要引入一种机制,使得整个系统能自动拓展类型。不然整个模型的表征能力被固定在有限的类别里了。
- 总结:我认为可能的AGI或者多模态的实现,是一个人为或者特殊AI的分类器 + 子模块的AI模型。
AI 系统方法论¶
方法论在许多学科中都扮演着核心角色,为研究和实践提供了系统化的框架。在人工智能(AI)领域,特别是近年来随着深度学习的迅速发展,一些关键的方法论思想对于理解和推进这一领域的发展至关重要。这里,我们将探讨三个具有代表性的概念:Rich Sutton 的 "The Bitter Lesson"、Scaling Law、以及 Emerging Properties。
1. The Bitter Lesson (苦涩的教训)¶
"The Bitter Lesson" 是由 Rich Sutton,在 2019 年发表的一篇经典文章中提出的观点。文章的核心观点是,人工智能的长期进步主要依赖于不断增长的计算能力,而不是更加精妙的算法设计或人类的先验知识。Sutton 通过回顾 AI 历史上的一系列突破,指出那些依赖通用方法和计算能力的进展往往比那些依赖特定领域知识或人工设计的技术更为持久和影响深远。这个教训强调了在设计 AI 系统时优先考虑可扩展性和计算效率的重要性。
2. Scaling Law¶
Scaling Laws 在深度学习和人工智能领域中描述了一个重要的现象:随着模型大小、数据集大小或计算预算的增加,模型的性能会按照某种可预测的方式提高。这种规律在各种类型的 AI 模型中都有观察到,特别是在大型语言模型(如 GPT 系列)的开发中尤为明显。Scaling Laws 不仅帮助研究者预测模型扩展的效果,而且还指导着资源的分配,比如如何平衡模型大小、训练时间和数据集大小以获得最佳性能。
3. Emerging Properties (涌现属性)¶
Emerging Properties 指的是当系统达到一定的复杂度时,会自然出现一些新的特性或行为,这些特性在系统的更简单或更小的版本中并不明显。在 AI 领域,尤其是在大型模型中,经常可以观察到这种现象。例如,一些大型语言模型能够展示出令人惊讶的创造力、推理能力或对复杂概念的理解,这些能力在小型模型中很难实现。这些涌现属性的出现通常与模型的规模和复杂度密切相关,强调了扩展模型可能带来意想不到的新能力和应用。
总的来说,这些方法论思想在人工智能的研究和应用中起着指导作用,强调了规模、计算能力和系统复杂度在实现 AI 长期进步中的重要性。通过理解和应用这些原则,研究人员和开发者可以更有效地设计和优化 AI 系统,以实现更高的性能和更广泛的应用。
AI 各领域的近未来发展¶
绘画领域(数据驱动)¶
数据飞轮(数据驱动模型的训练,数据资产化),和数据工厂越来越重要:
商业化思考¶
- 移动互联网: ToC
- 深度学习时代, 人脸识别,目标检测, 赋能了互联网行业,安防行业,智慧城市行业以及智慧工业等强B端行业。
- 大模型时代: 6
- ToC/ToB: 大模型+辅助工具 来形成的融入现有工作流的产品。
- 类似GPTs的生态
- AGI的雏形:多模态的未来。
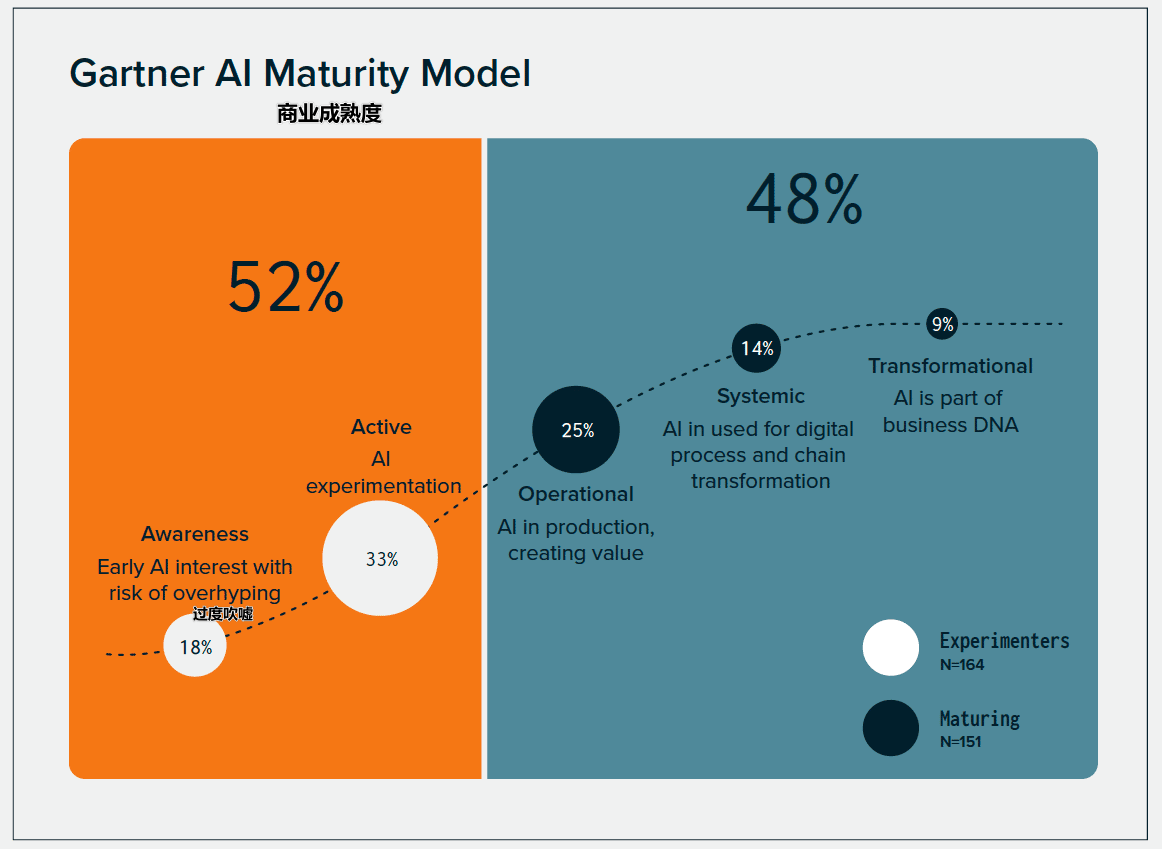
数字孪生¶
Digital Twin(数字孪生)是对真实的世界进行建模和预测。一般我们将数字孪生的发展分为四个阶段:
- 真实世界
- 构建真实世界的数字镜像(分为实时镜像和延迟镜像两种)
- 真实世界和数字镜像的交互这导致了数字线程的扩展,数字世界具有影响物理实体操作的能力(可能以自主方式)
- 数字物理孪生对具有一定程度的自主性。
- 进入第五阶段,自治水平不断提高,数字物理孪生对可以作为自主代理在网络空间中进行交互,将本地数据分析扩展到全球数据分析。
举一个简单的例子:
- 在没有互联网出现的时候,我们生活在物理世界,没有虚拟世界,每天在真实的道路上走,这是第一阶段。
- 然后有了最早的地图软件,他们对真实的道路进行建模,我们可以在数字世界里看到真实的道路情况和交通情况,道路模型不是实时更新的,交通情况是实时更新的。这就是上面提到的延迟镜像和实时镜像,这是第二阶段。
- 后面地图软件通过各种数据分析,它知道哪条路上经常发生车祸,会提醒我们要注意,这个时候数字世界模型开始影响我们真实生活中的操作,这是第三阶段。
- 到了现在我们正在逐步进入第四阶段,地图软件上实时显示道路的交通情况,根据数据模拟告诉你要走哪条路,我们会实时受到他们的影响,而这种实时的预测就是自主性的。同时现实生活中的决策也会影响物理世界模型,比如某人热爱探险从庄稼地里走过,地图软件就认为这里有一条路,标记成道路,后面推荐给其他人(是谁家的智障在这里就不点名批评了)。
HPC + AI + 科学计算 的新发展方向¶
- 静态代码分析器的机器学习实现:LSTM(确实是和时间有关的问题,毕竟是指令按序指令)
- DeepMD实现分子动力学模拟
- 网络其实设计的很简单,除开为了满足物理性质的特殊设计,其实就是一个全联接的前馈神经网络(MLP),计算出loss反向传播修改每个全连接层的权值。
- 原因很简单,输出和输出很简单,只需要寻找各个原子初始坐标和基态能量和结果总能量的关系。即没有CV图像庞大的数据需要通过CNN特征提取,也没有语音和文字这种按时间大量输入的问题需要引入时间,用RNN或者注意力机制解决。
粗浅的观点¶
由于我不是学AI的,可以说是完全不懂。
- 但是从抽象的层次来说,比如熵和信息量的角度说,信息量文本 < 图片 < 视频。 所以领域发展的成熟度的结果是,大语言模型先商业化(chatgpt),然后是图像(stable diffusion),最后才会是视频(AIGC电影片段)。当然这可能是对应训练的数据更不好整理的原因。
- AIGC/AGI产品产生商业化价值,其实分成两步:
- Step1: 使用者提出需求(文本为主),模型接受后从无序的训练数据中尝试提取出相关的信息。
- Step2: 使用者人工修正、过滤结果(反驳gpt的幻觉,丢弃SD生成的多指图)
- Future: 如果第一步更成熟, 第二步人为的努力就更少,更容易商业化。
- AI模型设计的有效复杂性的探讨
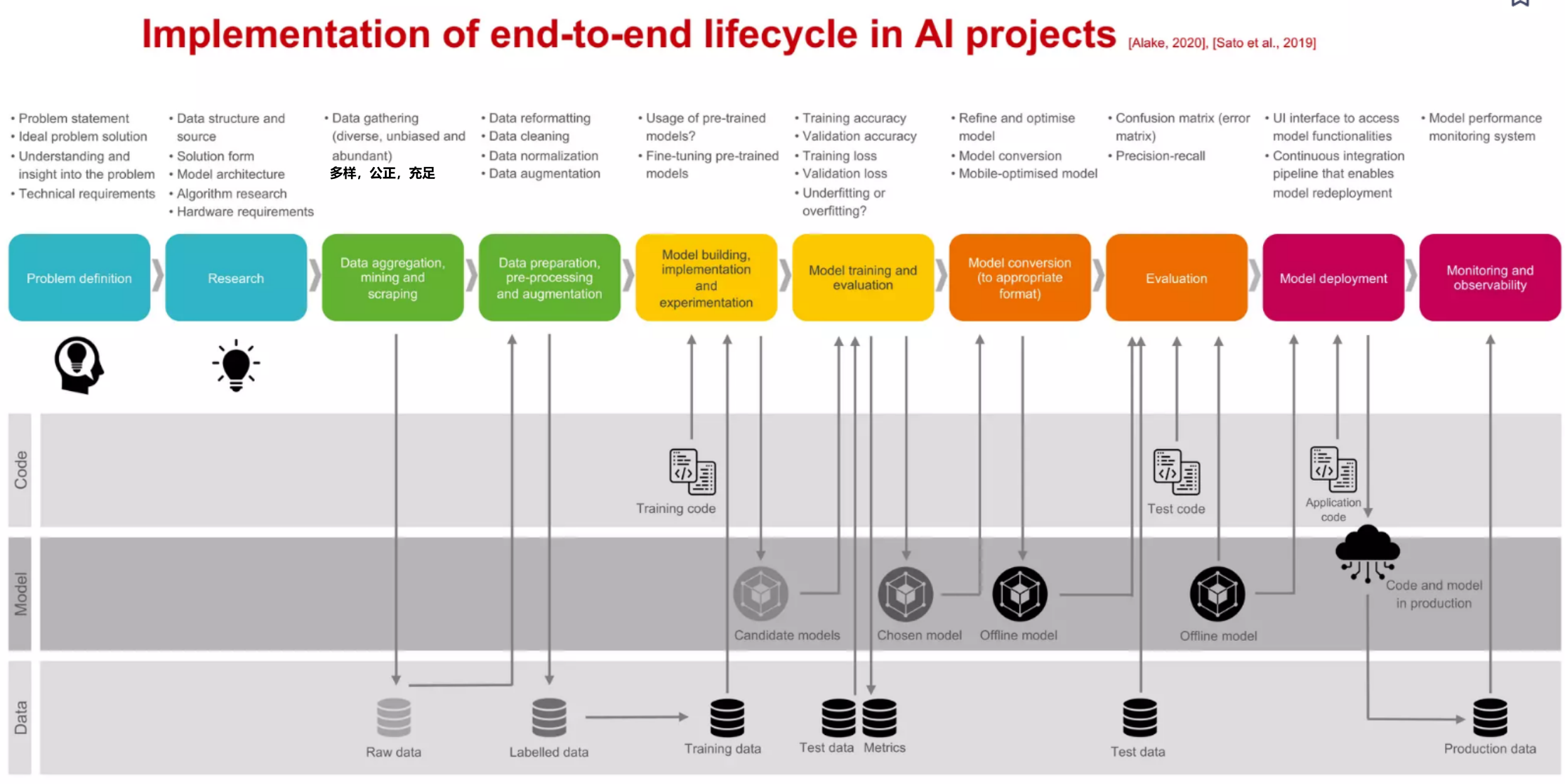
End-to-end lifecycle of AI projects¶
机器学习¶
机器学习是一种人工智能(Artificial Intelligence,AI)的分支,旨在让计算机通过数据和经验自动学习和改进算法(修改参数权重, 不是),而无需明确编程。
机器学习最基本的方法是使用算法(统计学算法)来解析处理数据,从中学习,然后对世界中的某些事物, 进行识别,做出决定或预测。
出发点: 与其用特定的指令集编写软件程序来完成特定的任务,还不如使用大量的数据和算法“训练”机器,让它能够学习如何执行任务。
事实证明,多年来机器学习的最佳应用领域之一是计算机视觉领域。要实现计算机视觉,它仍然需要大量的手工编码来完成工作。研究人员会去写手动编写分类器,比如边缘检测过滤器,这样程序就能识别出物体的起点和停止位置;形状检测确定是否有八面;识别字母“S-T-O-P”的分类器。从所有这些手工编写的分类器中,他们将开发算法来理解图像和学习识别图像,确定它是否是一个停止符号。
机器学习三大范式¶
机器学习的三大范式是:
- 监督学习(Supervised Learning):利用带标签的数据进行训练,目标是预测输入数据的标签。
- 无监督学习(Unsupervised Learning):利用无标签的数据进行训练,目标是发现数据的内在结构或模式(如聚类、降维)。
- 强化学习(Reinforcement Learning):通过智能体与环境的交互,基于奖励机制学习策略以实现目标。
为什么 深度学习 不属于三大范式?
- 深度学习(Deep Learning) 是机器学习的一种技术方法或实现方式,它使用深层神经网络来建模复杂的数据模式。
- 深度学习可以应用于上述三大范式,例如:
- 监督学习中的图像分类(如用 CNN 模型)。
- 无监督学习中的降维(如用 Autoencoder)。
- 强化学习中的策略优化(如用 DQN)。
机器学习的分类¶
在接下来的讨论前,你需要知道概率论的相关知识,本人有稍微介绍。
包括:2
- 常用离散分布
- 二项分布
- 常用连续分布
- 正态分布(高斯分布)
- 指数分布
- 伽马分布
- 贝塔分布
- 三大抽样分布
- 随机过程
- 泊松过程与泊松分布
- 马尔科夫链
- 平稳过程
- 布朗运动
- 鞅过程
- 大数定理,中心极限定理
- 参数估计
- 先验分布 后验概率分布
- 点估计
- 矩估计
- 最大似然估计与EM算法
- 最小方差无偏估计
- 贝叶斯估计
- 区间估计
- 方差回归与回归分析
参数学习¶
在机器学习领域,参数学习(Parameter Learning)是指通过观测数据来估计模型中的参数,从而使得模型能够适应数据并具有预测能力的过程。参数学习是机器学习中的一种重要任务,它通常涉及以下步骤:
- 定义模型:首先,需要选择或定义适当的模型来描述数据的生成过程或模式。
- 模型可以是线性模型、非线性模型、神经网络、决策树等各种形式。
- 确定损失函数:为了估计模型的参数,需要定义一个损失函数,用于衡量模型预测结果与实际观测值之间的差异。
- 常见的损失函数包括均方误差、交叉熵等,具体选择取决于任务的特点和模型的性质。
- 构建目标函数:目标函数是将损失函数与参数联系起来的函数。通过最小化目标函数,可以找到使模型在训练数据上表现最好的参数值。
- 优化算法:为了找到目标函数的最小值,需要使用优化算法进行参数的更新和调整。
- 常见的优化算法包括梯度下降、牛顿法、共轭梯度等,它们通过迭代地调整参数来最小化目标函数。
- 反向传播算法(Backpropagation)主要用于计算神经网络模型中的参数梯度,以便通过网络的反向路径使用梯度下降等优化方法更新参数。
- 训练模型:使用训练数据进行模型的训练。训练过程中,优化算法根据当前参数值和损失函数的梯度信息,更新参数,并不断迭代,直到达到停止条件(如达到最大迭代次数或损失函数收敛)。
- 参数估计:一旦训练完成,模型的参数就得到了估计。这些参数可以用于对新的未见过的数据进行预测或分类。
最大似然估计与损失函数的关系¶
可以理解成现有的监督学习的参数,都是在知道标签后的最大似然估计。由于模型不同,最大似然估计的公式就具体变成了各种损失函数与优化算法。
- 回归问题:特化成最小二乘估计(最小二乘法),对应的损失函数: 均方误差
- 分类问题:特化 损失函数:交叉熵
监督学习¶
- 监督学习通过训练数据集中的输入和对应的标签进行学习,从而能够预测或分类新的未标记数据
- 训练集是有标注的。
常见的监督学习算法包括
- 回归分析(自变量与因变量的关系,多在一二维的数据分析上)
- 线性回归(Linear Regression):线性回归是回归分析中最简单和最常见的方法之一。它假设自变量和因变量之间存在线性关系,并试图拟合出最优的线性模型来预测因变量。
- 多项式回归(Polynomial Regression):多项式回归是在线性回归的基础上,通过引入高阶多项式项来拟合非线性关系。它可以处理自变量和因变量之间的非线性关系,并更灵活地拟合曲线。
- 岭回归(Ridge Regression)和Lasso回归(Lasso Regression):这是在线性回归中使用的正则化方法,用于处理自变量之间存在共线性(多重共线性)的情况。它们通过添加正则化项来控制模型的复杂度,防止过拟合。
- Logistic回归(Logistic Regression):尽管名为回归,但实际上是一种分类算法。它用于处理因变量是二分类或多分类问题的情况,通过拟合逻辑函数来预测样本属于不同类别的概率。
- 非线性回归(Nonlinear Regression):非线性回归适用于自变量和因变量之间存在复杂的非线性关系的情况。它使用非线性函数拟合数据,并尝试找到最优的非线性模型。
- 统计分类(分类器)
- 决策树学习和随机森林 1. 隨機森林是一個包含多個決策樹的分類器 2. 过拟合剪枝
- 支持向量机(SVM,support vector machine)
- 最近邻居法(KNN算法,又译K-近邻算法)
- 朴素贝叶斯(贝叶斯网络)
当然人工神经网络也能分类,但是有种杀鸡用牛刀的感觉,费力结果不一定更好。
决定适合某一问题的分类器仍旧是一项艺术,而非科学。
无监督学习¶
- 无监督学习则从未标记的数据中学习数据的结构和模式,用于聚类、降维和异常检测等任务。
- 与监督学习相比,训练集没有人为标注的结果。
常见的无监督学习算法有
- 聚类
- (模糊)K-均值聚类(动态聚类法)
- 人工神经网络(无监督我也来了)
- 自编码器
- 生成对抗网络(GAN,Generative Adversarial Network) 1. 通过让两个神经网络相互博弈的方式进行学习。生成对抗网络由一个生成网络与一个判别网络组成。生成网络从潜在空间(latent space)中随机取样作为输入,其输出结果需要尽量模仿训练集中的真实样本。判别网络的输入则为真实样本或生成网络的输出,其目的是将生成网络的输出从真实样本中尽可能分辨出来。而生成网络则要尽可能地欺骗判别网络。两个网络相互对抗、不断调整参数,最终目的是使判别网络无法判断生成网络的输出结果是否真实。(常用于生成以假乱真的图片)
- 自组织映射(SOM)
- 适应性共振理论(ART)
半监督学习¶
半监督学习是介于监督学习和无监督学习之间的一种学习方式,利用带有标签的部分数据和未标记的数据进行学习。
强化学习(增强学习)¶
- 强化学习(Reinforcement learning,简称RL)是通过智能体与环境进行交互学习最佳行动策略,通过奖励信号来指导学习过程。通过正确就正向激励,错误就反向评价来修正模型。(多出现在游戏AI上,比如AlphaGo)
- 强化学习不需要带标签的输入输出对,同时也无需对非最优解的精确地纠正。其关注点在于寻找探索(对未知领域的)和利用(对已有知识的)的平衡。
无监督学习和强化学习的异同
在无监督学习和强化学习中,参数的训练过程有所不同。
- 在无监督学习中,参数的训练是通过对数据的内在结构和模式进行建模来实现的,而不需要事先标记的目标值。
- 常见的无监督学习算法包括聚类、降维和生成模型等。
- 训练参数的方法可以使用最大似然估计、最小化损失函数或其他自定义的优化目标。
- 例如,在聚类算法中,我们可以使用期望最大化算法(EM算法)来估计潜在的类别分布和数据点的类别归属。
- 在强化学习中,参数的训练是通过智能体与环境的交互来实现的。强化学习是一种通过试错的方式来学习最优策略的方法。智能体通过观察环境状态,采取行动并接收奖励信号,然后根据奖励信号调整参数。
- 常用的强化学习算法包括Q-learning、策略梯度方法和深度强化学习等。
- 参数的训练通常使用值函数估计、策略梯度优化或深度神经网络等技术。
在无监督学习和强化学习中,参数的训练过程都是通过优化方法来最大化某种指标或最小化某种损失函数。无监督学习更侧重于发现数据中的结构和模式,而强化学习更关注于学习与环境交互的最优策略。具体的训练方法和算法选择取决于具体的问题和应用领域。
深度学习 ?= 人工神经网络 =!¶
基本概念与关系¶
人工神经网络(Artificial Neural Network,ANN)是深度学习的基础和核心组成部分之一。
人工神经网络是一种受到生物神经系统启发的数学模型,用于模拟和处理信息。它由多个人工神经元(或称为节点)组成,这些神经元通过连接权重相互连接,并通过激活函数对输入信号进行处理。人工神经网络可以通过学习调整连接权重,以适应输入和输出之间的关系,并进行任务如分类、回归等。
深度学习是机器学习的一个分支,专注于使用深层次的神经网络(即具有多个隐藏层的神经网络)进行学习和表示学习。深度学习的关键创新是引入了深层次的非线性模型,这些模型能够通过多个层次的转换逐渐提取和组合输入数据中的高级特征。
深度学习通过使用深层神经网络来自动学习数据表示,并在大规模数据集上进行训练。深度学习的强大之处在于,通过增加网络的深度,它能够学习到更抽象、更高级别的特征表示,从而提高模型的表达能力和性能。
因此,深度学习利用了人工神经网络的结构和算法,通过增加网络的深度来提高模型的学习能力和表达能力。人工神经网络是深度学习中最基础、最重要的组成部分之一,为深度学习的发展提供了坚实的理论基础和工具。
人工神经网络的历史¶
- 概念的出现:“人工神经网络(Artificial Neural Networks)”也是早期机器学习专家提出的,存在已经几十年了。
- 每个神经元都将一个权重分配给它的输入,确定它与所执行任务的关系,对应正确与不正确的程度。最后的输出结果由这些权重的总和决定。
- 关键进展:保罗·韦伯斯发明的反向传播算法(Werbos 1975)。这个算法有效地解决了异或的问题,还有更普遍的训练多层神经网络的问题。
- 初期不够流行:支持向量机和其他更简单的方法(例如线性分类器)在机器学习领域的流行度逐渐超过了神经网络,但是在2000年代后期出现的深度学习重新激发了人们对神经网络的兴趣。
- 现在有循环神经网络和前馈神经网络两种,CNN就是一种前馈神经网络。
- 大幅度发展:2014年出现了残差神经网络,该网络极大解放了神经网络的深度限制,出现了深度学习的概念。
人工神经网络 与 深度学习的历史关系¶
2014年出现了残差神经网络,该网络极大解放了神经网络的深度限制,出现了深度学习的概念。
利用这些神经网络,增加了层和神经元,然后通过系统运行大量的数据来训练它。真正实现深度学习的“深度”,使得其能够描述神经网络中的所有的层次信息。
神经网络现在一般用于深度学习,所以将两者等价也不是不可以。
人工神经网络特点¶
人工神经网络(Artificial Neural Networks,ANN)具有以下特点:
- 自适应学习:人工神经网络可以通过学习算法自适应地调整神经元之间的连接权重,从而改变网络的行为和性能。通过与训练数据的反馈,神经网络可以逐步优化自己的权重参数,提高对输入模式的识别和预测能力。
- 非线性映射能力:人工神经网络可以通过非线性函数来建模复杂的输入与输出之间的关系。它能够学习和表示非线性模式和特征,从而更好地适应现实世界中的复杂问题。
- 广义的通用函数逼近器:根据万能逼近定理(Universal Approximation Theorem),具有足够多神经元和适当的激活函数的人工神经网络可以逼近任意复杂的函数。这使得神经网络在各种问题和任务中具备较强的建模能力。
- 分布式表示:人工神经网络采用分布式表示的方式来存储和处理信息。即信息被分散在网络中的多个神经元之间,每个神经元负责处理一部分信息。这种分布式表示的特点使得神经网络能够同时处理多个输入特征,并具有一定的容错性。
- 并行处理能力:人工神经网络的计算是并行进行的,多个神经元同时对输入进行处理。这种并行性能够加速计算过程,使得神经网络具有高效的计算能力。
- 容错性:人工神经网络具有一定的容错性,即在部分神经元或连接失效的情况下,仍然能够保持良好的性能。这种容错性使得神经网络在面对噪声和部分信息缺失的情况下仍然能够有效地处理数据。
- 可解释性挑战:随着神经网络的深度和复杂性增加,解释网络内部运行机制和权重的含义变得困难。这使得人工神经网络的解释性成为一个挑战,特别是在需要透明性和可解释性的应用场景中。
总的来说,人工神经网络是一种强大的模型,具有非线性映射能力、分布式表示、并行处理能力、自适应学习、容错性和广义的函数逼近能力。它在解决复杂问题和处理大规模数据时具有广泛的应用潜力。
与传统的机器学习不同的特点¶
人工神经网络与传统的机器学习算法相比具有以下不同的特点:
- 特征学习与表示学习:传统机器学习算法通常需要手动选择和提取适合任务的特征。而人工神经网络可以通过训练自动学习特征表示,从原始数据中学习到更高级别、更抽象的特征表示,减少了对特征工程的依赖。
- 非线性模型能力:人工神经网络可以建模和学习非线性关系,而传统机器学习算法通常是基于线性模型。这使得神经网络在处理复杂的、非线性的数据模式时具有更好的表达能力。
- 大规模数据处理:人工神经网络在大规模数据集上具有较好的处理能力。通过深层网络结构和并行计算,可以处理大量的数据并从中学习到更准确的模式和规律。
- 端到端学习:人工神经网络可以实现端到端的学习,从原始输入直接学习到输出,无需手动设计多个阶段的处理和特征。这简化了机器学习系统的设计和开发流程。
-
非凸优化问题:人工神经网络的训练通常涉及非凸优化问题,即寻找全局最优解的问题。相比之下,传统机器学习算法通常涉及凸优化问题,有较好的全局最优解保证。
-
模型的复杂性与解释性:人工神经网络通常具有复杂的网络结构和大量的参数,使得模型更加复杂。这导致了神经网络的解释性相对较低,难以理解模型内部的运行机制和权重的含义。
- 训练复杂性和计算资源需求:相对于传统机器学习算法,训练神经网络通常需要更多的计算资源和时间。深层网络的训练可能需要大量的训练数据和更复杂的优化算法,同时也需要更多的计算资源来进行模型的训练和推理。
综上所述,人工神经网络相对于传统机器学习算法具有更强的特征学习能力、非线性模型能力、大规模数据处理能力和端到端学习能力。但同时也存在模型复杂性、解释性挑战、训练复杂性和计算资源需求等方面的特点。选择使用哪种方法取决于具体的任务、数据和资源要求。
人工神經网络分类¶
- 依学习策略(Algorithm)分类主要有:
- 监督式学习网络(Supervised Learning Network)为主
- 无监督式学习网络(Unsupervised Learning Network)
- 强化学习(Reinforcement Learning):基于奖励机制,在与环境交互中学习最优策略。
- 依网络架构(Connectionism)分类主要有:
- 前馈神经网络(Feed Forward Network)信息在网络中单向传播,没有循环连接。
- 包括MLP、CNN、Transformer、GPT-3(基于Transformer)
- 循环神经网络(Recurrent Network)网络中存在循环连接,可以处理具有时间依赖性的序列数据。
- 包括RNN,LSTM
- 循环神经网络具有循环连接,可以处理具有时间依赖性的序列数据。RNN 在处理序列数据时能够保留先前状态的信息,并具有记忆能力。
- 卷积神经网络(Convolutional Neural Networks):主要用于图像和视觉任务,通过卷积层和池化层来提取图像特征。
- CNN 属于前馈神经网络(Feedforward Neural Networks)的一种,但它在结构上具有一些特殊的设计。CNN 主要用于图像和视觉任务,通过卷积层和池化层来提取图像特征,从而捕捉图像中的局部关系和空间结构。
- 自编码器(Autoencoders):用于无监督学习和特征提取,由编码器和解码器组成。
- 前馈神经网络(Feed Forward Network)信息在网络中单向传播,没有循环连接。
- 基于层级结构:
- 单层神经网络:仅包含一个神经元层。
- 浅层神经网络:包含一到多个隐藏层(通常少于3层)。常用于处理较简单的任务,例如基本的模式识别和分类问题。
- 深度神经网络:包含多个隐藏层(例如5层或更多),通常用于处理更复杂的任务,如图像识别、自然语言处理等。
- 基于应用领域:
- 图像识别神经网络:用于图像分类、目标检测等计算机视觉任务。
- 语音识别神经网络:用于语音识别和语音合成任务。
- 自然语言处理神经网络:用于文本分类、机器翻译、情感分析等自然语言处理任务。
特殊的神经网络¶
表示网络节点关系的图神经网络属于一类特殊的神经网络模型,专门用于处理图结构数据的任务。它们利用图的节点和边表示数据之间的关系和连接。
图神经网络在处理图结构数据时具有独特的优势,可以考虑节点之间的邻近关系和全局拓扑结构,从而更好地捕捉图中的信息和模式。与传统的神经网络模型相比,图神经网络能够处理非欧几里德空间中的数据,如社交网络、蛋白质相互作用网络、推荐系统中的用户-物品关系等。
图神经网络的具体设计可以包括以下组件和操作:
- 图卷积层(Graph Convolutional Layer):通过将节点的特征与其邻居节点的特征进行聚合,更新节点的表示。
- 图池化层(Graph Pooling Layer):通过对图的节点进行聚合和降维,减少图的规模和复杂性。
- 图注意力机制(Graph Attention Mechanism):通过学习权重,动态地聚焦于图中重要的节点和边。
- 图生成模型(Graph Generation Models):用于生成新的图样本,如图生成对抗网络(GANs)。
- 图自编码器(Graph Autoencoders):用于无监督学习和图的特征提取。
图神经网络的发展和研究是为了解决图数据分析和图结构任务,如图分类、节点分类、链接预测、图生成、图聚类等。这些任务通常需要考虑节点之间的关系和全局拓扑结构,并且图神经网络提供了一种有效的方式来处理和分析这种复杂的数据结构。
多层神经网络常见组成结构¶
现在的多层神经网络结构一般包含以下几种常见的层:
- 输入层(Input Layer):接收原始数据作为模型的输入,每个输入特征对应网络中的一个节点。
- 隐藏层(Hidden Layer):位于输入层和输出层之间的一层或多层。每个隐藏层都包含多个节点(神经元),并使用激活函数对输入进行非线性变换。
- 输出层(Output Layer):位于网络的最后一层,输出模型的预测结果或表示。输出层的节点数通常取决于具体的任务,例如分类任务可能有多个类别的节点,回归任务可能只有一个节点。
除了这些基本层之外,还有一些特殊的层和技术,常见的包括:
- 卷积层(Convolutional Layer):主要用于处理图像和计算机视觉任务。卷积层通过应用一系列卷积核(过滤器)来提取输入数据中的局部特征,并共享权重以减少参数量。
- 池化层(Pooling Layer):常与卷积层结合使用,用于减少特征图的尺寸和参数数量,同时保留主要特征。常见的池化操作包括最大池化(Max Pooling)和平均池化(Average Pooling)。
- 循环层(Recurrent Layer):用于处理序列数据,如自然语言处理和时间序列分析。循环层中的神经元具有循环连接,可以在每个时间步骤上保留先前的状态信息。
- 规范化层(Normalization Layer):如批归一化(Batch Normalization)和层归一化(Layer Normalization),用于提高网络的稳定性和收敛速度。
- 注意力层(Attention Layer):通过学习注意力权重来对输入的不同部分进行加权处理,用于处理序列和集合数据中的相关性和重要性。
需要注意的是,具体的网络结构和层数可能因任务和研究领域而异。不同的问题和应用可能会使用不同的层和技术来构建适合的神经网络结构。
CNN神经网络的各种常见的网络层¶
- 卷积层、
- 激励层:由于卷积也是一种线性运算,因此需要对卷积层的输出进行一个非线性映射,一般为ReLu函数。
- 池化层:进行降维操作,一般有两种方式:进行下采样,对特征图稀疏处理,减少数据运算量
- max pooling:取池化视野中的最大值
- Average pooling:取池化视野中的平均值
- 归一化层:
- 在Batch Normalization(简称BN)出现之前,我们的归一化操作一般都在数据输入层,对输入的数据进行求均值以及求方差做归一化,但是BN的出现打破了这一个规定,我们可以在网络中任意一层进行归一化处理。
- 不仅可以加快了模型的收敛速度,而且更重要的是在一定程度缓解了深层网络中“梯度弥散”的问题,从而使得训练深层网络模型更加容易和稳定。
- 也有更先进的,比如layernorm
- 切分层:对某些(图片)数据的进行分区域的单独学习
- 融合层:对某些(图片)数据的进行分区域的单独学习
- dropout层:为了防止过拟合(模型在训练数据上损失函数较小,预测准确率较高;但是在测试数据上损失函数比较大,预测准确率较低。)
- 在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征
- 全连接层:通常在CNN的尾部进行重新拟合,减少特征信息的损失。
- 输出层
NLP 领域革命¶
自监督任务¶
- 关系: 自监督学习实际上与监督学习、非监督学习、半监督学习并没有本质上的鸿沟。
- 定义: 自我监督方法可以看作是一种具有监督形式的特殊形式的非监督学习方法,这里的监督是由自我监督任务而不是预设先验知识诱发的。与完全不受监督的设置相比,自监督学习使用数据集本身的信息来构造伪标签。
- 未来: 在表示学习方面,自我监督学习具有取代完全监督学习的巨大潜力。人类学习的本质告诉我们,大型注释数据集可能不是必需的,我们可以自发地从未标记的数据集中学习。更为现实的设置是使用少量带注释的数据进行自学习。
人话版解释:自监督学习 = 拿着没有答案的题库(无标签数据),自己把答案盖住再猜一遍(构造伪标签),以此来训练自己(监督过程)。
核心意思是:自监督学习通过“自己给自己出题、自己对答案”的方式,把“无监督数据”变成了“有监督训练”。
什么是自监督学习?(核心概念)
一句话解释: 它是“没有老师,学生把课本的内容遮住一部分,试着填空,然后自己翻开看对不对”的学习方式。
- 数据来源(像非监督学习): 只有课本(海量无标签数据),没有老师画重点(没有人工标签)。
- 训练方式(像监督学习): 学生自己制造考题(比如把这一页撕下一半),试图恢复它。
举个最直观的例子(完形填空): 假设你有一堆书,但没有老师告诉你书里讲了什么。
- 自监督任务: 你随便拿一句话:“今天天气真好。”
- 制造伪标签(挖空): 你把“真好”两个字遮住,变成:“今天天气__ __。”
- 预测: 你猜这里应该是“不错”,或者“糟糕”。
- 监督信号(对答案): 你移开遮挡物,发现原话是“真好”。
- 学习: 你发现猜错了,于是调整自己的大脑模型,学会了“今天天气”后面常跟形容词。
在这个过程中,没有人教你(非监督的数据),但你通过遮挡和恢复(构造伪标签),强行制造了一个有标准答案的过程(监督的形式)。这就是文中说的“没有本质上的鸿沟”。
逐句翻译你提供的文本,为了消除你的困惑,我把那段话拆解开来翻译:
| 原文难点 | 通俗翻译 |
|---|---|
| “没有本质上的鸿沟” | 意思是:不要把它们看成三个完全隔离的世界。自监督就是拿非监督的数据,跑监督学习的流程。 |
| “具有监督形式的特殊形式的非监督学习” | 形式上像有人教(有对错反馈),但本质上没人教(数据没标签)。 |
| “由自我监督任务而不是预设先验知识诱发” | 这里的“任务”就是指“完形填空”或“拼图”。不是人类预先定义好“这是猫、那是狗”(先验知识),而是模型自己通过任务去理解数据结构。 |
| “使用数据集本身的信息来构造伪标签” | 这是核心! 比如把一张图切碎(数据本身),让你拼回去。原来的完整图就是“标签”,但它是数据自带的,不是人标的,所以叫“伪标签”。 |
常见的自监督学习任务(Pretext Tasks)
为了让模型学会理解世界,科学家设计了很多“自我折磨”的任务,这些任务统称为前置任务(Pretext Tasks):
在自然语言处理(NLP)中(BERT/GPT 的基础)
- Masked Language Modeling (MLM): 就像上面的“完形填空”。BERT 就是这么训练的。
- Next Token Prediction: 预测下一个词。GPT 就是这么训练的(把后面一个词遮住让你猜)。
在计算机视觉(CV)中 * 旋转预测: 把一张照片旋转(0°, 90°, 180°, 270°),让模型猜这张图被转了多少度。如果模型能猜对,说明它得先看懂图里有个“正着”的东西。 * 拼图游戏(Jigsaw): 把一张图切成 9 块打乱,让模型拼回去。 * 着色(Colorization): 把彩色照片变黑白,让模型还原颜色。
为什么要搞自监督学习?
你可能会问:直接让人去标数据(监督学习)不好吗?
这段话最后提到了:“具有取代完全监督学习的巨大潜力”。 原因很简单:由于太贵了,且学得不够深。
- 数据成本: 互联网上有万亿级别的文本和图片(免费),但让人去给每张图打标签(猫、狗、车)太贵了,也太慢了。自监督可以利用那 99% 的无标签数据。
- 学习本质: 监督学习(教什么学什么)往往比较死板。自监督学习(通过上下文理解世界)能学到更通用的特征。
- 比喻: 监督学习是背题库通过考试;自监督学习是通读全书理解原理。
自回归语言模型 VS 自编码语言模型¶
自回归语言模型(Autoregressive Language Model, AR)和自编码语言模型(Autoencoding Language Model, AE)的理解
自回归语言模型是根据上文或者下文来预测后一个单词。那不妨换个思路,我把句子中随机一个单词用[mask]替换掉,是不是就能同时根据该单词的上下文来预测该单词。我们都知道Bert在预训练阶段使用[mask]标记对句子中15%的单词进行随机屏蔽,然后根据被mask单词的上下文来预测该单词,这就是自编码语言模型的典型应用。
自回归语言模型没能自然的同时获取单词的上下文信息(ELMo把两个方向的LSTM做concat是一个很好的尝试,但是效果并不是太好),而自编码语言模型能很自然的把上下文信息融合到模型中(Bert中的每个Transformer都能看到整句话的所有单词,等价于双向语言模型),但自编码语言模型也有其缺点,就是在Fine-tune阶段,模型是看不到[mask]标记的,所以这就会带来一定的误差。
1. 自回归语言模型(AR Model)¶
顺序预测,单向依赖。¶
- 训练目标: 预测序列中的下一个 Token(词语或子词),基于其之前的所有 Token。
- 数学表示: 最大化给定历史 \(\text{history}\) 下,当前 Token \(x_t\) 的条件概率。 $\(P(x) = \prod_{t=1}^{T} P(x_t | x_1, x_2, \dots, x_{t-1})\)$
- 信息流: 始终是单向的(从左到右,或从右到左)。
- 典型模型: GPT-n 系列、Transformer Decoder。
- 优势:
- 天然适合生成任务: 生成时天然地一个接一个输出,与训练方式完全一致(没有 Fine-tune 阶段的偏差)。
- 概率模型: 可以计算一个句子的联合概率 \(P(x)\)。
- 劣势(你提出的关键点): 只能看到单侧上下文(如左侧),无法自然地整合双向信息。
2. 自编码语言模型(AE Model)¶
破坏重建,双向依赖。¶
- 训练目标: 预测被随机破坏(Masking)的 Token,基于所有未被破坏的 Token。
- 训练任务(如 BERT): 掩码语言模型(Masked Language Model, MLM)。
- 信息流: 由于 Transformer Encoder 中的 Self-Attention 机制可以看到整个序列,所以信息流是双向的。
- 典型模型: BERT、RoBERTa。
- 优势(解决了 AR 的痛点):
- 双向上下文: 能将整个句子(上文和下文)的信息融合到每个 Token 的表示中,学到的特征更丰富、更深刻。
- 劣势(你提出的关键点):
- Fine-tune 偏差(Pretrain-Finetune Discrepancy): 预训练时看到 \([MASK]\) Token,但在 Fine-tune 时,任务句子中没有 \([MASK]\)。模型在预训练时需要恢复被替换的 Token,但在下游任务(如情感分析、命名实体识别)中则不再需要处理 \([MASK]\),这种输入的不一致性会带来误差。
- 不适合生成任务: 缺乏自然连贯的生成机制。虽然可以迭代地 Masking 和预测来生成,但效果通常不如 AR 模型。
3. AR 和 AE 与之前概念的关系¶
这两个模型是自监督学习(Self-Supervised Learning, SSL)在 NLP 领域最成功的应用范例。
| 概念 | 自回归 (AR) / 自编码 (AE) | 关系解释 |
|---|---|---|
| 自监督学习 | 共同的范式 | AR 和 AE 都是通过自监督任务(预测下一个词 或 恢复被 Mask 的词)来构造伪标签,从而进行预训练。它们是 SSL 在文本数据上的具体实现方式。 |
| 监督学习 | AR 和 AE 的训练形式 | 一旦构造了伪标签,无论是预测下一个词(AR)还是预测被 Mask 的词(AE),模型都是在最小化预测值与伪标签的差异,这遵循了监督学习的流程。 |
| 非监督学习 | AR 和 AE 的数据来源 | 它们都使用海量的、无人工标签的文本数据进行训练,从而学习到文本的内在结构和分布,这体现了非监督学习的本质。 |
| 自回归 | AR 独有 | 预测下一个词的自监督任务天然赋予了模型生成的能力,因此 AR 模型是目前大语言模型生成式 AI 的主流架构。 |
| 自编码 | AE 独有 | 预测被破坏的词的自监督任务天然赋予了模型理解的能力,因此 AE 模型(BERT)是解决理解类任务(如分类、抽取)的开山鼻祖。 |
AR仍是主流¶
当前最火的qwen3 等模型还是 自回归语言模型(AR Model),但是自回归模型(AR)确实提出已久(可追溯到20世纪的语言模型如n-gram,甚至更早的马尔可夫模型),而自编码模型(AE,如 BERT)在2018年前后因预训练+微调范式大放异彩,但至今 AR 仍是大语言模型(LLM)主流架构,原因涉及任务目标、训练-推理一致性、生成能力、scaling law 等多个维度。以下是关键原因分析:
1. 任务目标不同:生成 vs 理解¶
- AR 模型天然适合生成任务:
自回归通过 \(P(x_t | x_{<t})\) 逐 token 预测下一个词,与人类写作/对话的顺序生成过程一致,因此在文本生成、对话、代码合成、故事创作等任务上具有天然优势。 - AE 模型(如 BERT)侧重理解:
通过掩码语言建模(MLM)学习上下文表示,擅长分类、问答、实体识别等判别式任务,但无法直接生成连贯长文本(因为训练时看到完整上下文,推理时却需从零生成)。
🔸 简言之:AE 是“完形填空”,AR 是“接着写”。生成式 AI 的爆发(如 ChatGPT)本质上是“接着写”需求的胜利。
2. 推理阶段的一致性(Training-Inference Mismatch)¶
- AE 模型存在训练-推理不一致问题:
BERT 训练时输入是带[MASK]的完整句子(能看到未来词),但实际生成时必须从左到右逐字预测(看不到未来词),导致分布不匹配,难以直接用于生成。 - AR 模型训练即推理:
训练时只用历史信息预测下一个 token,与推理完全一致,无此问题。
3. Scaling Law 与大模型涌现能力¶
- 实证研究表明(如 Chinchilla、LLaMA 等工作),AR 模型在大规模数据+参数下表现出强大的涌现能力(如推理、泛化、指令遵循)。
- 虽然 AE 模型在中小规模预训练中效果优异,但在超大规模(>10B 参数)场景下,AR 架构更容易通过增加数据/算力获得性能提升,且更适配 decoder-only 的简洁架构。
4. 架构效率与工程实现¶
- Decoder-only(AR)架构更简单高效:
相比 BERT 的 encoder(需双向 attention),AR 模型使用 causal attention(mask future tokens),推理时可缓存 past key-value,加速生成。 - AE 模型若用于生成,需额外设计(如 BART、T5 引入 encoder-decoder),但增加了复杂度和延迟。
5. 自回归 + 指令微调 + RLHF 的组合威力¶
- 以 GPT、Qwen 为代表的 AR 模型,通过 SFT(监督微调) + RLHF/DPO(对齐人类偏好),在对话、指令遵循、安全性等方面取得突破。
- AE 模型缺乏有效的生成式对齐路径,难以直接融入这一范式。
补充:AE 是否完全被淘汰?¶
没有。AE 思想仍在以下场景活跃:
- 混合架构:如 T5、Flan-T5 使用 encoder-decoder(含 AE 预训练思想),擅长摘要、翻译等输入-输出映射任务。
- 表示学习:在检索、嵌入、语义匹配等任务中,BERT 类模型仍是 SOTA。
- 新范式探索:如 MAE(Masked Autoencoders) 在视觉领域成功,但在 NLP 生成任务中尚未撼动 AR 地位。
总结¶
AR 未被 AE 替代,是因为生成式 AI 的核心需求(开放-ended 生成、对话、创作)天然契合 AR 的顺序预测机制,且在 scaling、对齐、工程效率上更具优势。AE 仍是理解类任务的利器,但“生成时代”属于自回归。
这也解释了为何 Qwen3、Llama 3、GPT-4 等主流 LLM 仍坚定采用 AR 架构。
多模态领域¶
自监督依然主流¶
具体看多模态生成的文章。
一些基本概念¶
BF16、 FP16、TF32¶
BF16、FP16、和TF32 是在 AI 训练中常用的数值数据格式,它们通过减少精度来提升计算效率,特别是在深度学习中的大规模矩阵运算时显得尤为重要。以下是每种格式的详细介绍:
- BF16(Bfloat16):
- 全称:Brain Floating Point 16-bit。
- 位数分配:1位符号位,8位指数位,7位尾数位。
-
特点:与 FP32(32位浮点数)的指数位相同,但尾数位减少,保留了与 FP32 相近的动态范围(相同的指数范围),但精度降低。BF16 是在大型神经网络训练中常用的格式,提供了在减少计算和内存需求的同时保持较好模型精度的能力。
-
FP16(Half Precision Floating Point):
- 全称:16-bit Floating Point。
- 位数分配:1位符号位,5位指数位,10位尾数位。
-
特点:比 FP32 有更少的尾数位和指数位,因此其表示范围和精度都比 FP32 小,但它的计算效率和存储需求大大降低。FP16 常用于推理和训练阶段,但可能需要额外的技巧来避免数值不稳定性。
-
TF32(TensorFloat-32):
- 全称:TensorFloat 32-bit。
- 位数分配:1位符号位,8位指数位,10位尾数位。
- 特点:这是 NVIDIA 为其 Ampere 架构 GPU 引入的格式,结合了 FP16 的计算效率和 FP32 的动态范围。它采用了与 FP32 相同的指数位数,但尾数位比 FP32 少。这使得 TF32 能够在保持较高训练精度的同时,加速计算速度,特别是在深度学习训练任务中表现出色。
这些格式的共同点在于,它们都通过减少精度来换取更高的计算性能和更少的存储需求,特别适用于大规模 AI 模型的训练。
预训练模型(pre-traing)¶
- 背景:模型参数的初始化一直是一个重要的研究问题,一个合适的初始化能够提升模型性能,加速收敛找到最优解。
- 定义:预训练是一个阶段。是让模型从“白纸”变成“通才”的过程。
- 目标:在海量、多样化的无标签文本(如互联网数据、书籍)上进行训练, 构建一个基础语言模型(Base Model),让模型掌握语言的基本规律、世界知识和文本生成能力。目标并不是让模型立刻能画出完美的图,而是让它先理解这个世界的基本规律(比如:天空是蓝色的、猫有两只耳朵、语言的语法逻辑等)。
- 关系:
- 预训练本质上是主要利用了无监督学习的方法(如自监督学习,Self-Supervised Learning),在海量原始文本上进行“读懂”世界的任务。
- 多模态生成预训练用了从数据量大,和自动化的角度上,即使用了图文对,也叫做预训练。
- 无监督或自监督训练后的模型,能够很自然地作为下游任务(如图像分类、目标检测)模型微调前的初始化参数。
- 无监督算法的性能由微调后模型在下游任务的性能,如准确率、收敛速度等等相比基线模型是否有提高来进行判断。
- 预训练本质上是主要利用了无监督学习的方法(如自监督学习,Self-Supervised Learning),在海量原始文本上进行“读懂”世界的任务。
- 方式: 通常是预测下一个词(Next-Token Prediction)。模型自己根据上下文生成“标签”。
- 历史:
- 在计算机视觉领域,由于CNN在过去的统治力,所以无监督深度学习通常都是基于标准卷积网络模型。例如将ResNet预训练后的模型迁移到其他基于CNN模型也是相当容易且直接的。
- 但现在时代变了,Vision Transformer(ViT)成为了新的主流模型。
多模态生成预训练, 为什么用“图文对”依然算预训练?
这里我们需要区分“数据的形式”和“学习的任务”。
在机器学习的语境下,“有监督”通常指的是需要人工极其精确地标注出目标(比如:手动在图上画框并标注“这是一只猫”)。
而 MM-DiT(SD3/Flux 的核心)的预训练被称为大规模自监督/弱监督,原因如下:
- 数据来源是“自然存在”的: 互联网上的图片通常自带 Alt-text(网页描述)。模型只是在利用这些现成的数据,而不是依赖人类专门为模型训练而手工打的标签。
- 任务目标是“重建”: MM-DiT 的核心任务不是分类(比如判断是猫还是狗),而是根据文本的指引,把噪声还原成对应的图像。
- 规模差异: “有监督训练”通常只有几万或几十万条精确数据;而“预训练”动辄使用数亿、数十亿条原始图文对。
MM-DiT 在预训练中具体在学什么?你可以把 MM-DiT 的预训练看作是在学习两套“语言”之间的翻译和映射规律:
- 文本侧(Text Stream): 理解词与词之间的逻辑(由 T5 或 CLIP 编码器提供初始理解)。
- 图像侧(Image Stream): 理解像素之间的空间关系(物体形状、材质、光影)。
- 融合学习(The "MM" part): 这是 MM-DiT 的核心。它通过 Modality-Specific Weights 让文本和图像在同一个 Transformer 块里“聊天”。
“自监督”在 MM-DiT 里的体现在 Flow Matching 的框架下,MM-DiT 的训练依然遵循路径拟合:
- 输入:
(带噪声的图像 Latent, 原始文本描述, 时间步 t) - 输出: 预测一个速度向量 v。
- 自监督闭环: 模型的“老师”其实是那张没加噪声之前的原图。模型不断对比自己生成的向量和指向原图的真实向量之间的差距。
- 结论: 文本在这里更像是一个“控制变量”或“上下文”,而核心的监督信号来自于图像数据自身。
总结:预训练的三个阶段为了严谨,现在最顶尖的模型(如 Flux)其实是这样分层利用数据的:
| 阶段 | 数据类型 | 性质 | 目的 |
|---|---|---|---|
| 基础预训练 | 原始互联网图文对(乱且杂) | 弱监督 / 自监督 | 让模型见过世面,建立通识。 |
| 高质量重打标预训练 | GPT-4V 重新描述的高精数据 | 强监督预训练 | 让模型学会“精准听话”,理解复杂指令。 |
| 微调 (SFT/LoRA) | 极小规模特定风格数据 | 有监督微调 | 锁定某种特定画风或人物特征。 |
MM-DiT 的确用了文本和图像,但它利用这些数据的方式是“大规模、自动化”的,这正是它被称为预训练(Pre-training)而不是普通分类训练(Training)的原因。
思考:如果文本描述本身写错了(图文不符),模型在预训练时会不会被带偏?(这其实涉及到目前最前沿的数据清洗技术了)
SFT (Supervised Fine-Tuning)¶
- 目标: 将基础模型转变为一个“能听懂人话”的指令遵循模型(Instruction-Following Model)。
- 数据: SFT 使用的数据是人类专家精心标注的指令和对应回答,这是一个典型的 \(X \to Y\) 映射。
- 关系: SFT 是一种特殊的监督学习,它使用更少的、高质量的标签数据,对预训练好的模型进行小幅度的权重调整。
SOTA¶
SOTA也就是state-of-the-art,若某篇论文能够称为SOTA,就表明其提出的算法(模型)的性能在当前是最优的。
网址:https://www.stateoftheart.ai/models
https://sota.jiqizhixin.com/
联邦学习¶
联邦学习(Federated Learning)是一种分布式机器学习方法,允许多个参与方(如设备或组织)在不共享原始数据的情况下,协作训练一个全局模型。其核心思想是在各个参与方的本地设备上进行模型训练,而不是将数据集中到一个中心服务器进行处理,从而保护数据的隐私和安全。
联邦学习的主要特点:
- 数据不出本地:各参与方在自己的设备上使用本地数据进行模型训练,而不需要将数据上传到中心服务器。只有训练后的模型更新(如参数或梯度)会被发送到中心服务器或其他设备。
- 隐私保护:由于原始数据不会离开本地设备,联邦学习能够在一定程度上保护用户隐私,避免数据泄露的风险。它常用于涉及敏感数据的场景,如医疗、金融等领域。
- 全局模型更新:中心服务器(或其他协调机制)收集各参与方的模型更新,并对其进行聚合,生成全局模型。然后,更新后的全局模型会被发送回参与方,以继续改进本地模型。
联邦学习的典型流程:
- 初始模型:中心服务器生成一个初始模型,并分发给所有参与方。
- 本地训练:每个参与方在自己的本地设备上使用本地数据对模型进行训练,计算得到模型更新(例如权重或梯度)。
- 模型上传:参与方将模型更新发送回中心服务器,而非原始数据。
- 聚合更新:中心服务器对所有参与方的模型更新进行聚合,生成全局模型。
- 分发更新:中心服务器将更新后的全局模型分发回各参与方,继续下一轮的本地训练。
联邦学习的应用场景:
- 智能设备:例如智能手机中的键盘预测模型,利用联邦学习可以在不上传用户输入数据的情况下改进输入法的预测性能。
- 医疗领域:医院可以利用联邦学习共同训练一个疾病预测模型,而无需分享患者的敏感医疗数据。
- 金融领域:各金融机构可以合作训练欺诈检测模型,保护用户隐私。
联邦学习的挑战:
- 通信效率:频繁地传输模型更新可能会带来较大的通信开销,特别是在网络条件较差的情况下。
- 异构性:参与方的计算能力和数据分布可能存在较大差异,如何处理这种异构性是一个挑战。
- 安全性:尽管联邦学习在一定程度上保护了隐私,但仍然面临一些安全威胁,如模型更新中的信息泄露或中毒攻击。
通过联邦学习,数据隐私得到了增强,协作效率也有所提高,但同时也引入了新的技术和管理上的挑战。
超参¶
1. 参数(Model Parameters)
- 定义:
参数是模型内部的配置变量,通过训练数据自动学习得到,直接影响模型的预测能力。 - 特点:
- 数据驱动:通过反向传播等优化算法从数据中学习(如权重\(W\)、偏置\(b\))。
- 动态调整:在训练过程中不断更新,以最小化损失函数。
- 示例:
- 神经网络的权重矩阵和偏置向量。
- 卷积神经网络中的卷积核参数。
- Transformer中的注意力矩阵(Query、Key、Value)。
2. 超参数(Hyperparameters)
- 定义:
超参数是模型外部的配置变量,需在训练前手动设定,用于控制模型的学习过程和结构设计。 - 特点:
- 人工设定:依赖经验或实验调优(如学习率\(\eta\)、批量大小\(B\))。
- 静态固定:训练过程中保持不变,但可通过网格搜索、随机搜索等方法优化。
- 示例:
- 结构类:网络层数、每层神经元数量、激活函数类型。
- 训练类:学习率、迭代次数(Epochs)、优化算法(如Adam)。
- 正则化类:L2正则化系数、Dropout比例。
| 特性 | 参数(Parameters) | 超参数(Hyperparameters) |
|---|---|---|
| 来源 | 数据驱动,自动学习得到 | 人工设定,不依赖数据 |
| 调整方式 | 训练中通过梯度下降等算法动态更新 | 训练前手动设定或通过调优算法搜索 |
| 作用对象 | 模型内部变量(如权重、偏置) | 控制模型结构或训练过程 |
| 示例 | \(W\), \(b\), 注意力矩阵 | \(\eta\), \(B\), 网络层数 |
- 参数:决定模型的预测能力,是模型能力的直接体现。
- 超参数:影响模型的训练效率和最终性能,需通过实验调优(如学习率过高会导致震荡,过低则收敛缓慢)。
https://www.jianshu.com/p/98f138c5ac11
https://zh.wikipedia.org/wiki/
-
https://blogs.nvidia.com/blog/2016/07/29/whats-difference-artificial-intelligence-machine-learning-deep-learning-ai/ ↩
-
《AI的25种可能》 ↩
-
AI教父Hinton智源大会闭幕主题演讲 ↩
-
The 2023 path to AI maturity: Many companies have reached the mature level—but at what cost? ↩