ML Optimizer
导言
- 优化算法(Optimizer)目标是优化(最小化或最大化)一个损失函数,以调整模型参数,使模型在训练数据上表现得更好。
- 在深度学习中,优化算法是训练神经网络时至关重要的组成部分,它们决定了模型参数如何更新以最小化损失。
- 所以梯度下降、动量法、随机梯度下降、RMSprop、Adam、AdamW、LAMB等算法都是优化算法。
Gradient Descent (GD)¶
梯度下降法,最基本的优化方法,沿着负梯度的方向更新参数,
梯度直接更新位置。 梯度下降法相关的优化方法容易产生震荡,且容易被困在鞍点,迟迟不能到达全局最优值。动量法¶
梯度先更新速度然后更新位置。
可以加快收敛并减小震荡.Stochastic Gradient Descent (SGD)随机¶
对于问题 梯度下降每一次迭代都需要出所有的梯度,即每一次算n个梯度,进行下面的迭代
梯度下降每一次迭代都需要出所有的梯度,即每一次算n个梯度,进行下面的迭代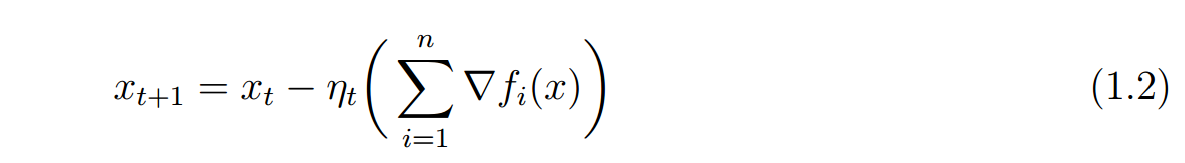 而随机梯度下降,每一次选一个函数计算梯度,然后迭代,减少了计算量,而且一般收敛效果更好。
而随机梯度下降,每一次选一个函数计算梯度,然后迭代,减少了计算量,而且一般收敛效果更好。
Root Mean Square prop (RMSprop)¶
由于指数加权平均,各数值的加权而随时间而指数式递减,越近期的数据加权越重,但较旧的数据也给予一定的加权。
RMSprop采用梯度平方的指数加权平均。 $$cache = decay_rate * cache + (1 - decay_rate) * dx^2 $$ $\(x += - learning\_rate * \frac{dx }{\sqrt{cache}+eps})\)$
Adaptive Moment estimation (Adam)¶
为解决 梯度下降 GD 中固定学习率带来的不同参数间收敛速度不一致的弊端,AdaGrad 和 RMSprop 诞生出来,为每个参数赋予独立的学习率。计算梯度后,梯度较大的参数获得的学习率较低,反之亦然。
此外,为避免每次梯度更新时都独立计算梯度,导致梯度方向持续变化,Momentum 将上一轮梯度值加入到当前梯度的计算中,通过某种权重对两者加权求和,获得当前批次参数更新的更新值。
Adam 结合了这两项考虑,既为每一个浮点参数自适应性地设置学习率,又将过去的梯度历史纳入考量
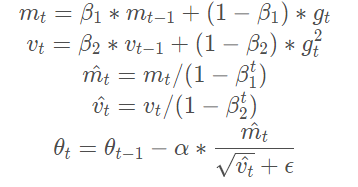
\(g^t\)表示t时刻梯度
AdamW¶
Adam 虽然收敛速度快,但没能解决参数过拟合的问题。具体的举措,是在最终的参数更新时引入参数自身:
LAMB¶
在使用 Adam 和 AdamW 等优化器时,一大问题在于 batch size 存在一定的隐式上限,一旦突破这个上限,梯度更新极端的取值会导致自适应学习率调整后极为困难的收敛,从而无法享受增加的 batch size 带来的提速增益。LAMB 优化器的作用便在于使模型在进行大批量数据训练时,能够维持梯度更新的精度。具体来说,LAMB 优化器支持自适应元素级更新(adaptive element-wise updating)和准确的逐层修正(layer-wise correction)
参考文献¶
https://blog.csdn.net/weixin_41089007/article/details/107007221
https://www.jianshu.com/p/e17622b7ffee
https://www.jiqizhixin.com/articles/2018-07-03-14