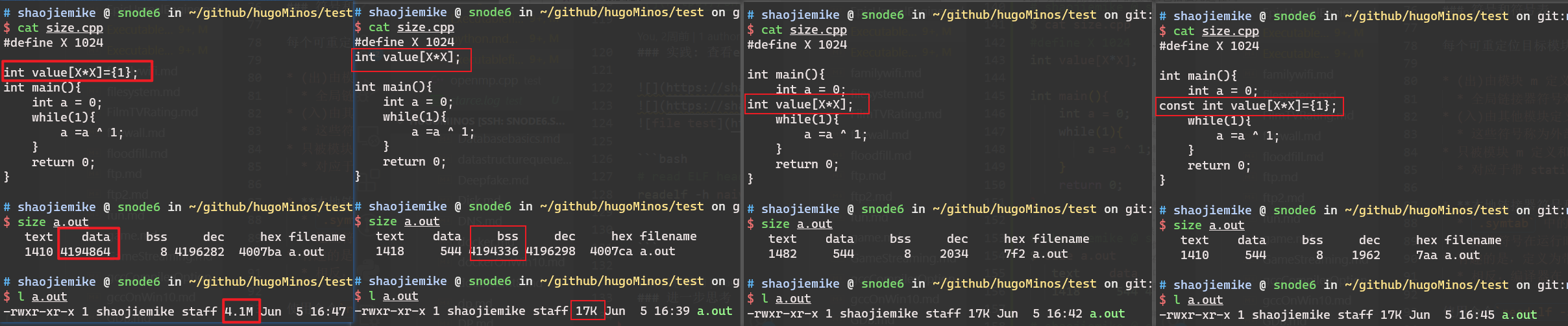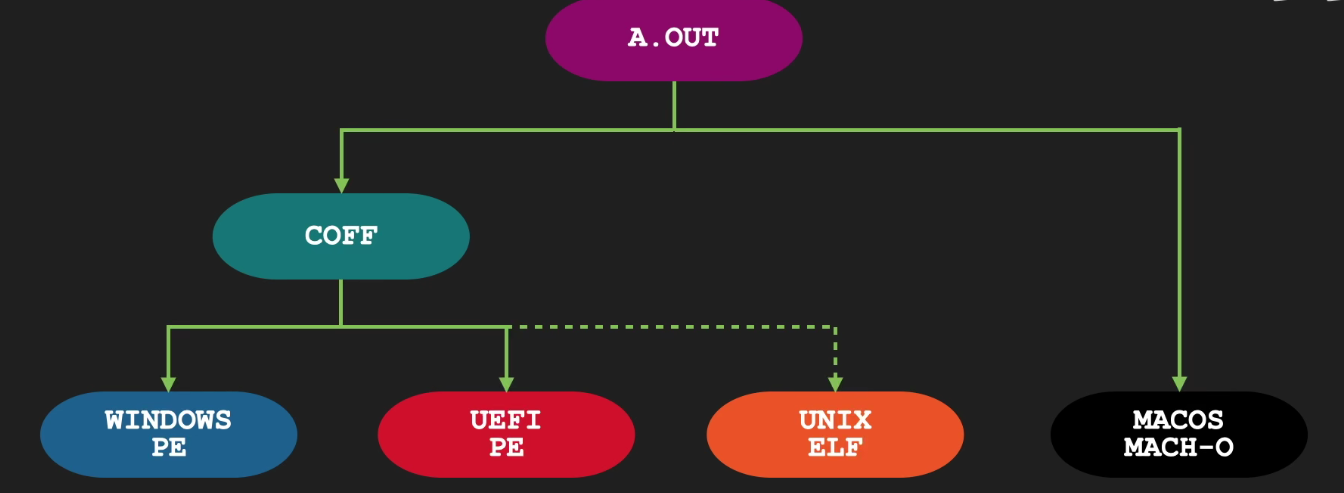
- COFF是32位System V平台上使用的一种格式。
- 它允许使用共享库和调试信息。
- 然而,它在节的最大数量和节名称的长度限制方面存在缺陷。
- 它也不能提供C++等语言的符号调试信息。
- 然而,像XCOFF(AIX)和ECOFF(DEC,SGI)这样的扩展克服了这些弱点,并且有一些版本的Unix使用这些格式。
- Windows的PE+格式也是基于COFF的。
可见可执行文件在不同平台上的规则还是有所不同的,后续会以UNIX ELF来分析

可执行目标文件的格式类似于可重定位目标文件的格式。
- ELF 头描述文件的总体格式。它还包括程序的入口点(entry point),也就是当程序运行时要执行的第一条指令的地址。
.text、.rodata 和 .data 节与可重定位目标文件中的节是相似的,除了这些节已经被重定位到它们最终的运行时内存地址以外。.init 节定义了一个小函数,叫做 _init,程序的初始化代码会调用它。- 因为可执行文件是完全链接的(已被重定位),所以它不再需要
.rel 节。
- 下面内容来自 深入理解计算机系统(CSAPP)的
7.4 可重定位目标文件一节
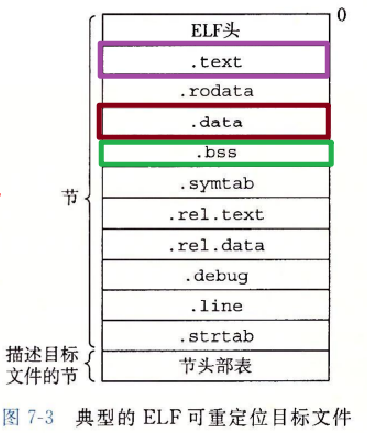
- 图 7-3 展示了一个典型的 ELF 可重定位目标文件的格式。
- ELF 头(Executable Linkable Format header)
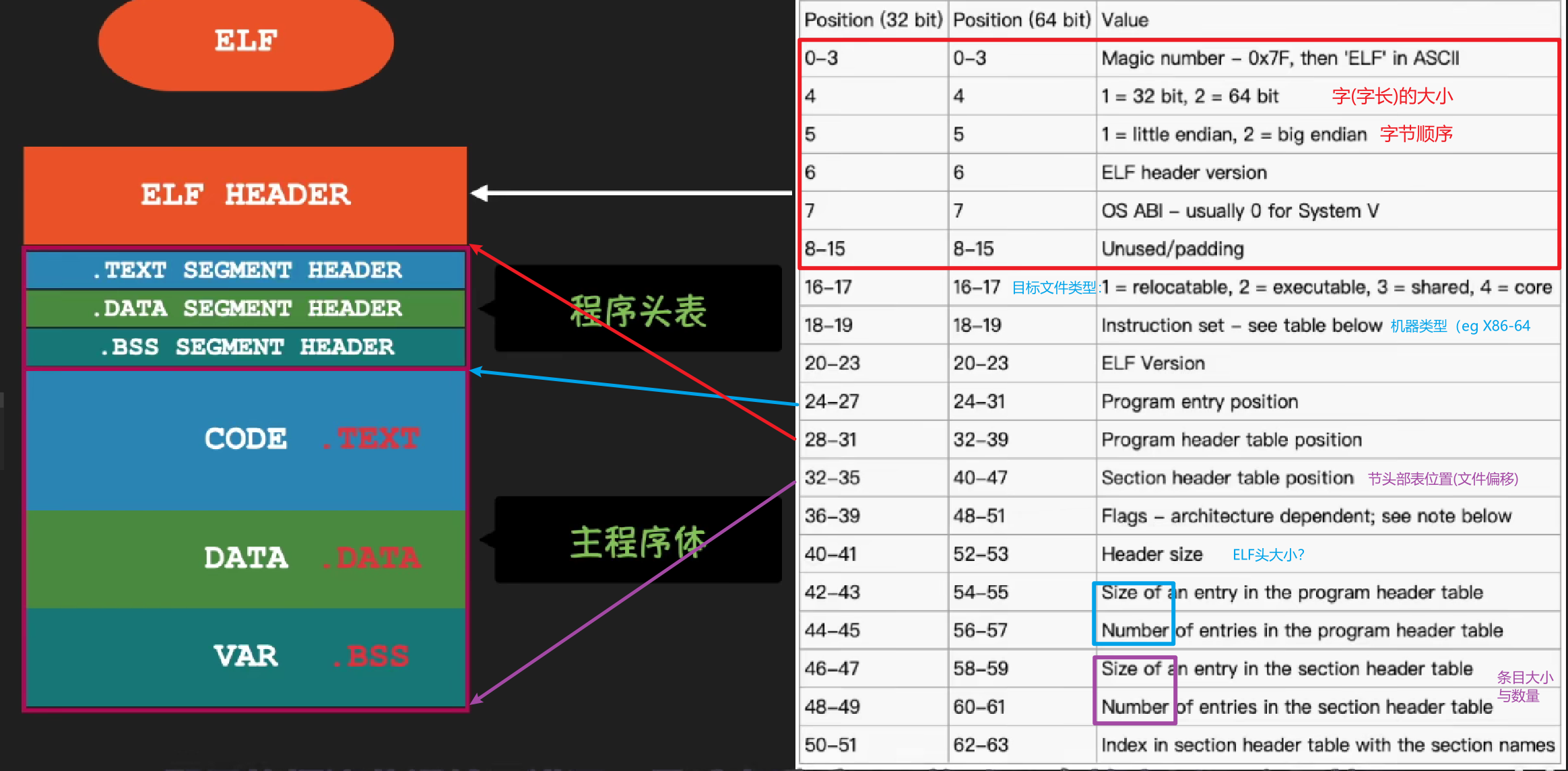
- 以一个 16 字节的序列开始,这个序列描述了生成该文件的系统的字的大小和字节顺序。
- ELF 头剩下的部分包含帮助链接器语法分析和解释目标文件的信息。
- 其中包括 ELF 头的大小、目标文件的类型(如可重定位、可执行或者共享的)、机器类型(如 X86-64)、节头部表(section header table)的文件偏移,以及节头部表中条目的大小和数量。
- 节头部表描述不同节的位置和大小,其中目标文件中每个节都有一个固定大小的条目(entry)。
夹在 ELF 头和节头部表之间的都是节。一个典型的 ELF 可重定位目标文件包含下面几个节:
- .text:已编译程序的机器代码。
- 通常代码区是可共享的(即另外的执行程序可以调用它),使其可共享的目的是对于频繁被执行的程序,只需要在内存中有一份代码即可。
- 代码区通常是只读的,使其只读的原因是防止程序意外地修改了它的指令。
- .rodata:只读数据,比如 printf 语句中的格式串和开关语句的跳转表。
- .data:已初始化的全局和静态 C 变量。
- 已经初始化的全局变量、已经初始化?的静态变量(包括全局静态变量和局部静态变量)和常量数据(如字符串常量)。
- 局部 C 变量在运行时被保存在栈中,既不岀现在
.data 节中,也不岀现在 .bss 节中。
- .bss:未初始化的全局和静态 C 变量,以及所有被初始化为 0 的全局或静态变量。
- 在目标文件中这个节不占据实际的空间,它仅仅是一个占位符。
- 目标文件格式区分已初始化和未初始化变量是为了空间效率:在目标文件中,未初始化变量不需要占据任何实际的磁盘空间。运行时,在内存中分配这些变量,初始值为 0。
- 用术语
.bss 来表示未初始化的数据是很普遍的。它起始于 IBM 704 汇编语言(大约在 1957 年)中“块存储开始(Block Storage Start)”指令的首字母缩写,并沿用至今。
- 区分
.data 和 .bss 节的简单方法是把 “bss” 看成是“更好地节省空间(Better Save Space)” 的缩写。
- .symtab:一个符号表,它存放在程序中定义和引用的函数和全局变量的信息。
- 一些程序员错误地认为必须通过 -g 选项来编译一个程序,才能得到符号表信息。实际上,每个可重定位目标文件在
.symtab 中都有一张符号表(除非程序员特意用 STRIP 命令去掉它)。
- 然而,和编译器中的符号表不同,
.symtab 符号表不包含局部变量的条目。
- .rel.text:一个 .text 节中位置的列表,当链接器把这个目标文件和其他文件组合时,需要修改这些位置。
- 一般而言,任何调用外部函数或者引用全局变量的指令都需要修改。另一方面,调用本地函数的指令则不需要修改。
- 注意,可执行目标文件中并不需要重定位信息,因此通常省略,除非用户显式地指示链接器包含这些信息。
- .rel.data:被模块引用或定义的所有全局变量的重定位信息。
- 一般而言,任何已初始化的全局变量,如果它的初始值是一个全局变量地址或者外部定义函数的地址,都需要被修改。
- .debug:一个调试符号表,其条目是
- 程序中定义的局部变量和类型定义,
- 程序中定义和引用的全局变量,
- 以及原始的 C 源文件。
- 只有以
-g 选项调用编译器驱动程序时,才会得到这张表。
- .line:原始 C 源程序中的行号和
.text 节中机器指令之间的映射。
- 只有以
-g 选项调用编译器驱动程序时,才会得到这张表。
- .strtab:一个字符串表,其内容包括
.symtab 和 .debug 节中的符号表,以及节头部中的节名字。字符串表就是以 null 结尾的字符串的序列。
每个可重定位目标模块 m 都有一个符号表.symtab,它包含 m 定义和引用的符号的信息。在链接器的上下文中,有三种不同的符号:
使用命令readelf -s simple.o 可以读取符号表的内容。
示例程序的可重定位目标文件 main.o 的符号表中的最后三个条目。

- 开始的 8 个条目没有显示出来,它们是链接器内部使用的局部符号。
- 全局符号 main 定义的条目,
- 它是一个位于 .text 节
- 偏移量为 0(即 value 值)处的 24 字节函数。
- 其后跟随着的是全局符号 array 的定义
- 位于 .data 节
- 偏移量为 0 处的 8 字节目标。
-
外部符号 sum 的引用。
-
type 通常要么是数据,要么是函数。
- 符号表还可以包含各个节的条目,以及对应原始源文件的路径名的条目。
- binding 字段表示符号是本地的还是全局的。
- Ndx=1 表示 .text 节
- Ndx=3 表示 .data 节。
- ABS 代表不该被重定位的符号;
- UNDEF 代表未定义的符号,也就是在本目标模块中引用,但是却在其他地方定义的符号;

# read ELF header
readelf -h naive
- 调度:进程是资源管理的基本单位,线程是程序执行的基本单位。
- 切换:线程上下文切换比进程上下文切换要快得多。
- TLB是每个核私有的,如果一个核从一个进程切换到另一个进程,TLB要全部清空。
- 但是线程不需要,因为线程共享相同的虚拟地址空间。
- 所以线程切换开销远小于进程切换开销。
- 拥有资源: 进程是拥有资源的一个独立单位,线程不拥有系统资源,但是可以访问隶属于进程的资源。
- 系统开销: 创建或撤销进程时,系统都要为之分配或回收系统资源,如内存空间,I/O设备等,OS所付出的开销显著大于在创建或撤销线程时的开销,进程切换的开销也远大于线程切换的开销。
线程和进程都可以用多核,但是线程共享进程内存(比如,openmp)
超线程注意也是为了提高核心的利用率,当有些轻量级的任务时(读写任务)核心占用很少,可以利用超线程把一个物理核心当作多个逻辑核心,一般是两个,来使用更多线程。AMD曾经尝试过4个。

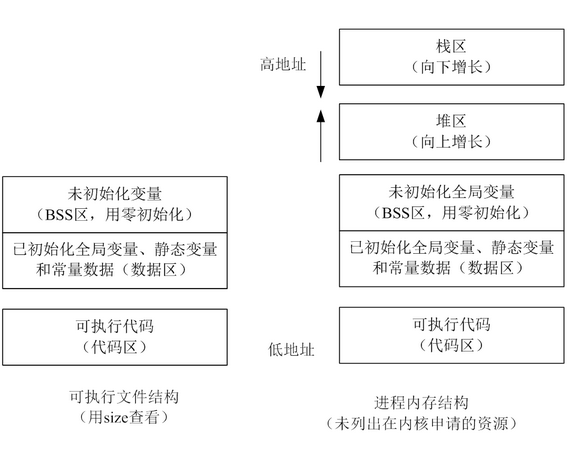
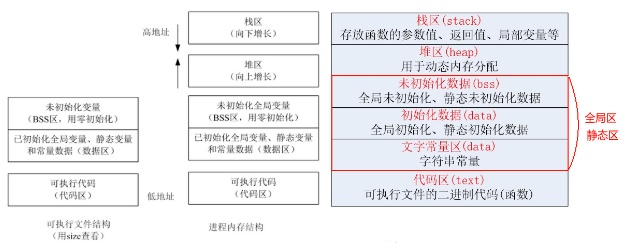
正在运行的程序,叫进程。每个进程都有完全属于自己的,独立的,不被干扰的内存空间。此空间,被分成几个段(Segment),分别是Text, Data, BSS, Heap, Stack。
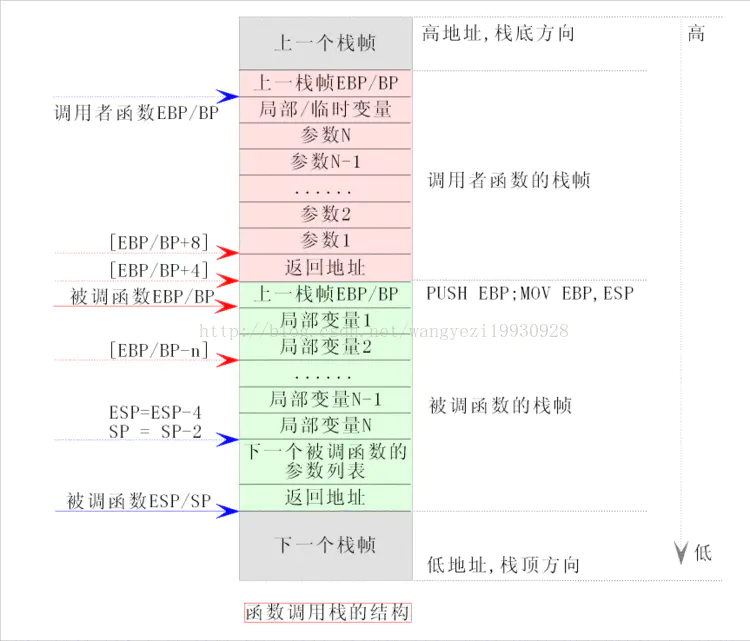
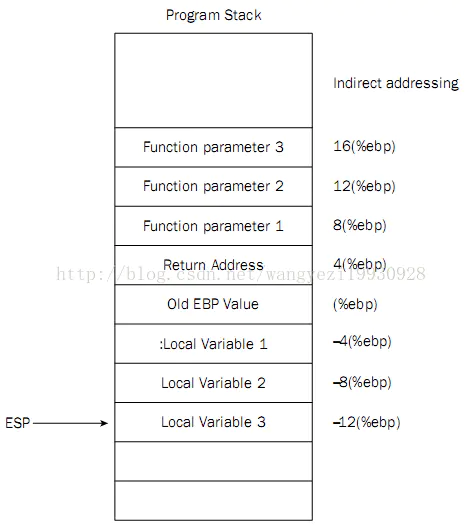
push pop %ebp 涉及到编译器调用函数的处理方式 application binary interface (ABI).- 如何保存和恢复寄存器
- 比如:cdecl(代表 C 声明)是 C 编程语言的调用约定,被许多 C 编译器用于 x86 体系结构。 在 cdecl 中,子例程参数在堆栈上传递。整数值和内存地址在
EAX 寄存器中返回,浮点值在 ST0 x87 寄存器中返回。寄存器 EAX、ECX 和 EDX 由调用方保存,其余寄存器由被叫方保存。x87 浮点寄存器 调用新函数时,ST0 到 ST7 必须为空(弹出或释放),退出函数时ST1 到 ST7 必须为空。ST0 在未用于返回值时也必须为空。
0000822c <func>:
822c: e52db004 push {fp} ; (str fp, [sp, #-4]!) 如果嵌套调用 push {fp,lr}
8230: e28db000 add fp, sp, #0
8234: e24dd014 sub sp, sp, #20
8238: e50b0010 str r0, [fp, #-16]
823c: e3a03002 mov r3, #2
8240: e50b3008 str r3, [fp, #-8]
8244: e51b3008 ldr r3, [fp, #-8]
8248: e51b2010 ldr r2, [fp, #-16]
824c: e0030392 mul r3, r2, r3
8250: e1a00003 mov r0, r3
8254: e24bd000 sub sp, fp, #0
8258: e49db004 pop {fp} ; (ldr fp, [sp], #4) 如果嵌套调用 pop {fp,lr}
825c: e12fff1e bx lr ; MOV PC,LR
00008260 <main>:
8260: e92d4800 push {fp, lr}
8264: e28db004 add fp, sp, #4
8268: e24dd008 sub sp, sp, #8
826c: e3a03019 mov r3, #25
8270: e50b3008 str r3, [fp, #-8]
8274: e51b0008 ldr r0, [fp, #-8]
8278: ebffffeb bl 822c <func>
827c: e3a03000 mov r3, #0
8280: e1a00003 mov r0, r3
8284: e24bd004 sub sp, fp, #4
8288: e8bd8800 pop {fp, pc}
arm PC = x86 EIP
ARM 为什么这么设计,就是为了返回地址不存栈,而是存在寄存器里。但是面对嵌套的时候,还是需要压栈。
由编译器自动分配释放,存放函数的参数值、返回值、局部变量等。在程序运行过程中实时加载和释放,因此,局部变量的生存周期为申请到释放该段栈空间。
WIndow系统一般是2MB。Linux可以查看ulimit -s ,通常是8M
栈空间最好保持在cache里,太大会存入内存。持续地重用栈空间有助于使活跃的栈内存保持在CPU缓存中,从而加速访问。进程中的每个线程都有属于自己的栈。向栈中不断压入数据时,若超出其容量就会耗尽栈对应的内存区域,从而触发一个页错误。
函数参数传递一般通过寄存器,太多了就存入栈内。
栈区(stack segment):由编译器自动分配释放,存放函数的参数的值,局部变量的值等。
局部变量空间是很小的,我们开一个a[1000000]就会导致栈溢出;而全局变量空间在Win 32bit 下可以达到4GB,因此不会溢出。
或者malloc使用堆的区域,但是记得free。
用于动态内存分配。堆在内存中位于BSS区和栈区之间。一般由程序员分配和释放,若程序员不释放,程序结束时有可能由OS回收。
分配的堆内存是经过字节对齐的空间,以适合原子操作。堆管理器通过链表管理每个申请的内存,由于堆申请和释放是无序的,最终会产生内存碎片。堆内存一般由应用程序分配释放,回收的内存可供重新使用。若程序员不释放,程序结束时操作系统可能会自动回收。
用户堆,每个进程有一个,进程中的每个线程都从这个堆申请内存,这个堆在用户空间。所谓内训耗光,一般就是这个用户堆申请不到内存了,申请不到分两种情况,一种是你 malloc 的比剩余的总数还大,这个是肯定不会给你了。第二种是剩余的还有,但是都不连续,最大的一块都没有你 malloc 的大,也不会给你。解决办法,直接申请一块儿大内存,自己管理。
除非特殊设计,一般你申请的内存首地址都是偶地址,也就是说你向堆申请一个字节,堆也会给你至少4个字节或者8个字节。
堆有一个堆指针(break brk),也是按照栈的方式运行的。内存映射段是存在在break brk指针与esp指针之间的一段空间。
在Linux中当动态分配内存大于128K时,会调用mmap函数在esp到break brk之间找一块相应大小的区域作为内存映射段返回给用户。
当小于128K时,才会调用brk或者sbrk函数,将break brk向上增长(break brk指针向高地址移动)相应大小,增长出来的区域便作为内存返回给用户。
两者的区别是
内存映射段销毁时,会释放其映射到的物理内存,
而break brk指向的数据被销毁时,不释放其物理内存,只是简单将break brk回撤,其虚拟地址到物理地址的映射依旧存在,这样使的当再需要分配小额内存时,只需要增加break brk的值,由于这段虚拟地址与物理地址的映射还存在,于是不会触发缺页中断。只有在break brk减少足够多,占据物理内存的空闲虚拟内存足够多时,才会真正释放它们。
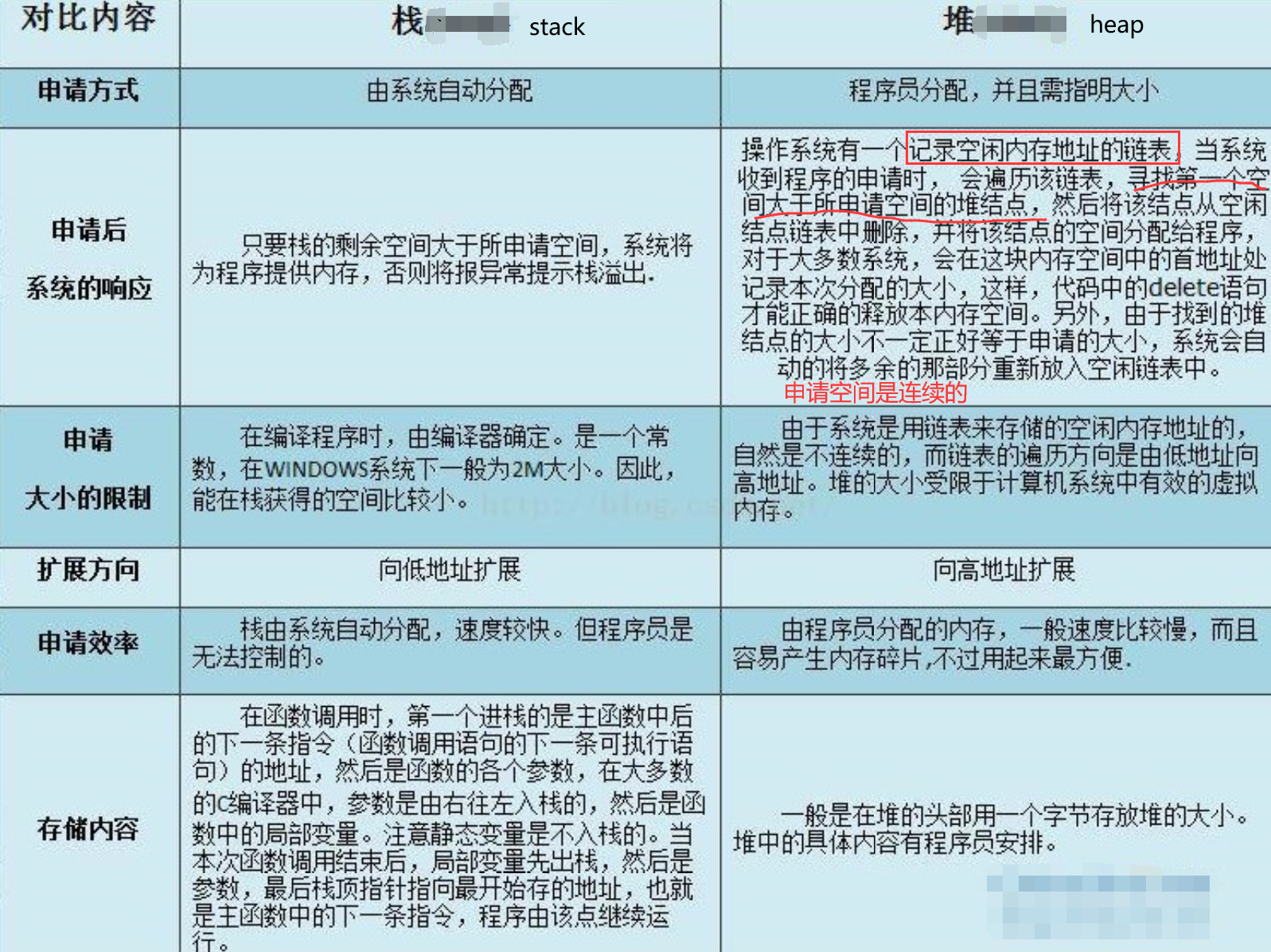
- 产生碎片不同
对堆来说,频繁的new/delete或者malloc/free势必会造成内存空间的不连续,造成大量的碎片,使程序效率降低。
对栈而言,则不存在碎片问题,因为栈是先进后出的队列,永远不可能有一个内存块从栈中间弹出。
- 代码段和数据段分开,运行时便于分开加载,在哈佛体系结构的处理器将取得更好得流水线效率。
- 代码时依次执行的,是由处理器 PC 指针依次读入,而且代码可以被多个程序共享,数据在整个运行过程中有可能多次被调用,如果将代码和数据混合在一起将造成空间的浪费。
- 临时数据以及需要再次使用的代码在运行时放入栈中,生命周期短,便于提高资源利用率。
- 堆区可以由程序员分配和释放,以便用户自由分配,提高程序的灵活性。
- 缓冲区溢出(Buffer Overflow)是一种常见的软件漏洞,它发生在程序中使用缓冲区(一块内存区域)来存储数据时,输入的数据超过了缓冲区的容量,导致多余的数据溢出到相邻的内存区域。
- 常见栈上分配空间,然后溢出直接覆盖前面的返回地址,使得返回到任意代码片段执行。如果开启了栈上执行代码,甚至能栈上注入代码并执行。
用户进程内存空间,也是系统内核分配给该进程的VM(虚拟内存),但并不表示这个进程占用了这么多的RAM(物理内存)。这个空间有多大?命令top输出的VIRT值告诉了我们各个进程内存空间的大小(进程内存空间随着程序的执行会增大或者缩小)。
虚拟地址空间在32位模式下它是一个4GB的内存地址块。在Linux系统中, 内核进程和用户进程所占的虚拟内存比例是1:3,如下图。而Windows系统为2:2(通过设置Large-Address-Aware Executables标志也可为1:3)。这并不意味着内核使用那么多物理内存,仅表示它可支配这部分地址空间,根据需要将其映射到物理内存。
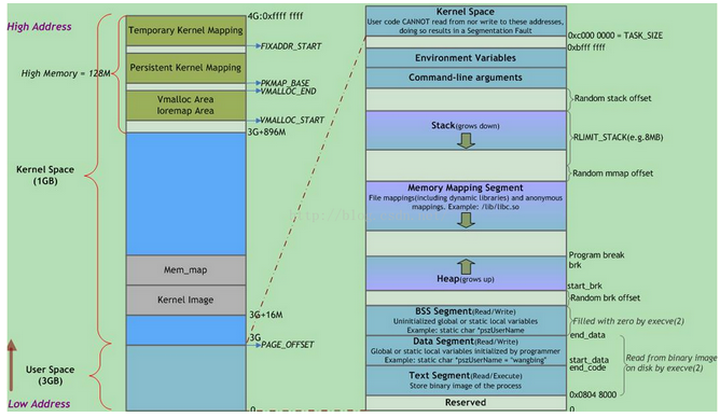
值得注意的是,每个进程的内核虚拟地址空间都是映射到相同的真实物理地址上,因为都是共享同一份物理内存上的内核代码。除此之外还要注意内核虚拟地址空间总是存放在虚拟内存的地址最高处。
其中,用户地址空间中的蓝色条带对应于映射到物理内存的不同内存段,灰白区域表示未映射的部分。这些段只是简单的内存地址范围,与Intel处理器的段没有关系。
上图中Random stack offset和Random mmap offset等随机值意在防止恶意程序。Linux通过对栈、内存映射段、堆的起始地址加上随机偏移量来打乱布局,以免恶意程序通过计算访问栈、库函数等地址。
execve(2)负责为进程代码段和数据段建立映射,真正将代码段和数据段的内容读入内存是由系统的缺页异常处理程序按需完成的。另外,execve(2)还会将BSS段清零。
VIRT = SWAP + RES # 总虚拟内存=动态 + 静态
RES >= CODE + DATA + SHR. # 静态内存 = 代码段 + 静态数据段 + 共享内存
MEM = RES / RAM
DATA CODE RES VIRT
before allocation: 124 4 408 3628
after 5MB allocation: 5008 4 476 8512 //malloc 5M, DATA和VIRT增加5M, RES不变
after 2MB initialization: 5008 4 2432 8512 //初始化 2M, DATA和VIRT不变, RES增加2M
//如果最后加上free(data), DATA, RES, VIRT又都会相应的减少,回到最初的状态
top 里按f 可以选择要显示的内容。
- Swapping的大部分时间花在数据传输上,交换的数据也越多,意味时间开销也随之增加。对于进程而言,这个过程是透明的。
- so(swap out):由于RAM资源不足,PFRA会将部分匿名页框的数据写入到交换区(swap area),备份之。
- si(swap in) : 当发生内存缺页异常的时候,缺页异常处理程序会将交换区(磁盘)的页面又读回物理内存。
- 每次Swapping,都有可能不只是一页数据,不管是si,还是so。Swapping意味着磁盘操作,更新页表等操作,这些操作开销都不小,会阻塞用户态进程。所以,持续飚高的si/so意味着物理内存资源是性能瓶颈。
- 在内存空间设计早期只有分段没有分页时,SWAP还可以用来内存交换(暂存内存数据,重新排列内存),来消除内存碎片。
暂无
暂无
Light-weight Contexts: An OS Abstraction for Safety and Performance
https://blog.csdn.net/zy986718042/article/details/73556012
https://blog.csdn.net/qq_38769551/article/details/103099014
https://blog.csdn.net/ywcpig/article/details/52303745
https://zhuanlan.zhihu.com/p/23643064
https://www.bilibili.com/video/BV1N3411y7Mr?spm_id_from=444.41.0.0