并行算法设计(详细见陈国良教材)
设计并发程序的四个阶段(PCAM设计方法学):
- 划分(Partitioning):分解成小的任务,开拓并发性
- 通讯(Communication):确定诸任务间的数据交换,监测划分的合理性;
- 组合(Agglomeration):依据任务的局部性,组合成更大的任务;
- 映射(Mapping):将每个任务分配到处理器上,提高算法的性能。
- 从问题开始全新设计并行算法
- 前缀和改成线性方程组的问题来并行
- 有向环的k-着色并行算法
- 将coreId作为颜色,进行二进制处理来颜色压缩。压缩到0-5之后再单独消除颜色
- 最短路径动态规划转换成矩阵乘法
- 平衡树
- 求n个最大值,先串行求部分最大,再用树,成本(处理器个数*时间)最低
- 访问存储次数/成本也不是最低的
- 倍增技术,指针跳跃
- 分治策略
- 划分原理(以两个有序数列到归并排序为例)
- 均匀划分
- 对数划分
- 方根划分
- 功能划分:基于硬件的Batcher实现,奇偶归并排序,双调序列的实现可以简化网络
- 流水线技术
- 脉动阵列
- 加速级联策略
- 先采用最快的方法将问题规模先减小到一个阈值,然后用其余最优的算法求出原问题的解。
- 思想其实类似机器学习里的变学习率。例子有平衡树的
- 破对称技术
- 打破数据的对称,便于分类
编译器和硬件级别的,一般不会引起程序员的注意。
- 真数据相关
- 名称相关:两条指令使用了相同的寄存器或者存储器位置,但实际并没有数据流动。寄存器重命名处理
- 控制相关:主要指指令的执行与分支指令存在先后关系。
硬件推测是一种技术,通过它,处理器可以在不完全确定某些操作结果的情况下,提前执行后续指令。这种技术主要用于提高处理器的性能和执行效率。以下是硬件推测的几个关键方面:
- 分支预测(Branch Prediction):处理器使用分支预测来猜测条件跳转指令的结果(即跳转或不跳转)。如果预测正确,提前执行的指令就可以直接使用,从而避免等待分支决策的延迟。
- 数据依赖性推测(Data Dependency Speculation):处理器可能会提前执行依赖于尚未计算完成的数据的指令。例如,即使前一条指令的结果尚未确定,它也会继续执行依赖于该结果的后续指令。
- 乱序执行(Out-of-Order Execution):这是硬件推测的另一种形式。在这里,处理器根据资源的可用性而不是指令在程序中的顺序来调度指令的执行。
- 内存访问推测(Memory Access Speculation):处理器可能会在所有必要的内存访问权限检查完成之前开始执行依赖于特定内存操作的指令。
这些推测性技术的共同目标是减少因等待数据依赖、分支决策或其他延迟而导致的空闲处理器周期。如果推测正确,这可以显著提高执行速度。然而,如果推测错误,处理器必须“倒回”并重新执行正确的指令路径,这可能导致性能损失。因此,现代处理器设计的一个关键方面是优化这些推测机制以最大限度地减少错误预测的影响。
与前面的区分
前面的技术是为了消除数据与控制停顿,使得CPI达到理想值1,如果我们想CPI小于一,每个时钟周期就需要发射多条指令。
多发射是一个更广泛的术语,指的是在一个时钟周期内发射(开始执行)多条指令的能力。
主要有三类:
- In order superscalar processor
- out-of-order superscalar processor
- VLIW
超标量处理器通常具有多个执行单元,如多个整数、浮点和其他专用执行单元,以及复杂的调度和分支预测机制来支持同时处理多条指令。
VLIW(Very Long Instruction Word)是一种处理器架构设计,其特点是使用非常长的指令字来编码多个操作,这些操作可以在单个处理器周期内并行执行。VLIW架构的关键特征如下:
- 长指令字:VLIW架构的指令字长度远超常规处理器。这些长指令字包含了多个操作(如算术、逻辑操作),这些操作在一个时钟周期内同时执行。
- 编译器优化:在VLIW架构中,指令的并行性是在编译时确定的,而不是在运行时。这意味着编译器负责识别可以并行执行的操作,并将它们组合成单个长指令字。
- 硬件简化:由于指令级并行性是在编译时处理的,VLIW处理器的硬件可以相对简化,因为它们不需要复杂的运行时指令调度和分支预测机制。这使得VLIW处理器在设计上更简单,功耗更低。
- 应用依赖:VLIW架构的效率高度依赖于编译器的优化能力和应用程序代码的特性。在指令流中并行性高的应用中,VLIW架构可以实现很高的性能。
VLIW架构在某些特定的应用场景(如数字信号处理DSP)中效果显著,但在通用计算领域的适用性受到限制,主要是因为编译器在处理普通程序时面临更大的挑战来有效地利用指令级并行性。
- ARM Cortex-A8 Core 双发射、静态调度(In-order)超标量处理器
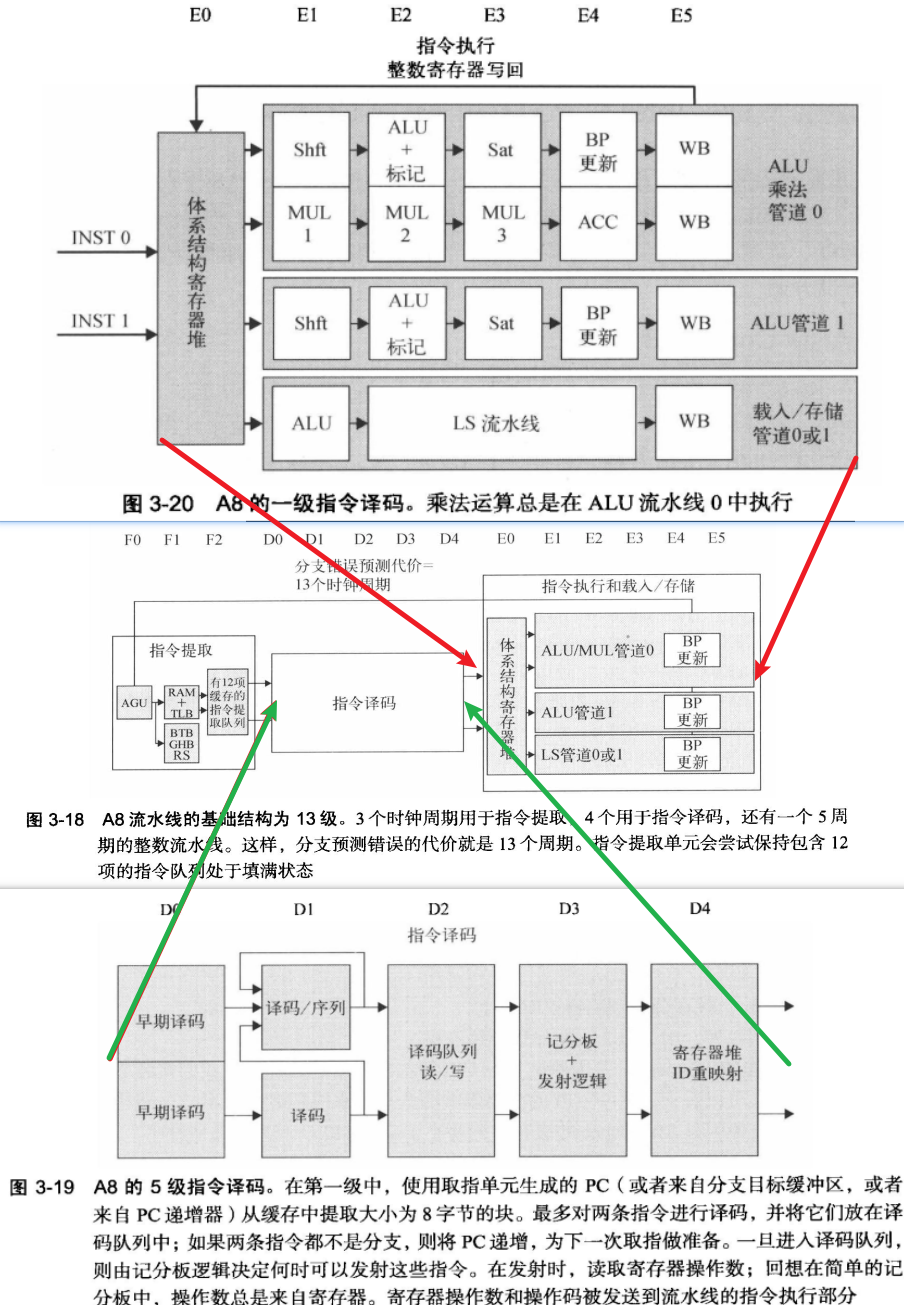
- Intel Core i7 四发射、动态调度(out-of-order execution)超标量处理器
- 向量张量、SIMD、以及GPU的结构
- 区别和MLP 概念的不同:MLP(访存并行)是一种通过同时处理多个内存访问来实现并行性的概念。MLP的目标是提高对存储器系统的效率,减少内存访问的延迟时间。它可以通过预取、缓存和内存操作的重叠等技术来实现。
- 单机多核系统
- 运行一组紧密耦合的线程,协同完成任务
- 缓存一致性协议
- 请求级并行:由一个或者多个用户发起的多个相对独立的进程
- 环境: 云计算。
- 关注成本与收益

ILP 指令级并行
TLP 线程级并行
SMT 同步多线程(Simultaneous Multi-Threading,SMT)是一种在一个CPU 的时钟周期内能够执行来自多个线程的指令的硬件多线程技术。
CMP 单芯片多处理器(Chip multiprocessors)
- 共享内存模式(The shared memory model)
- 多线程模式(The multithread model)
- 分布式内存/消息传递模式(The distributed memory/message passing model)
- 数据并行模式(The data parallel model)
- IPCC Preliminary SLIC Optimization 4: EnforceLabelConnectivity
SM : shared Memory
LM : Local Memory
DM :distribute memory
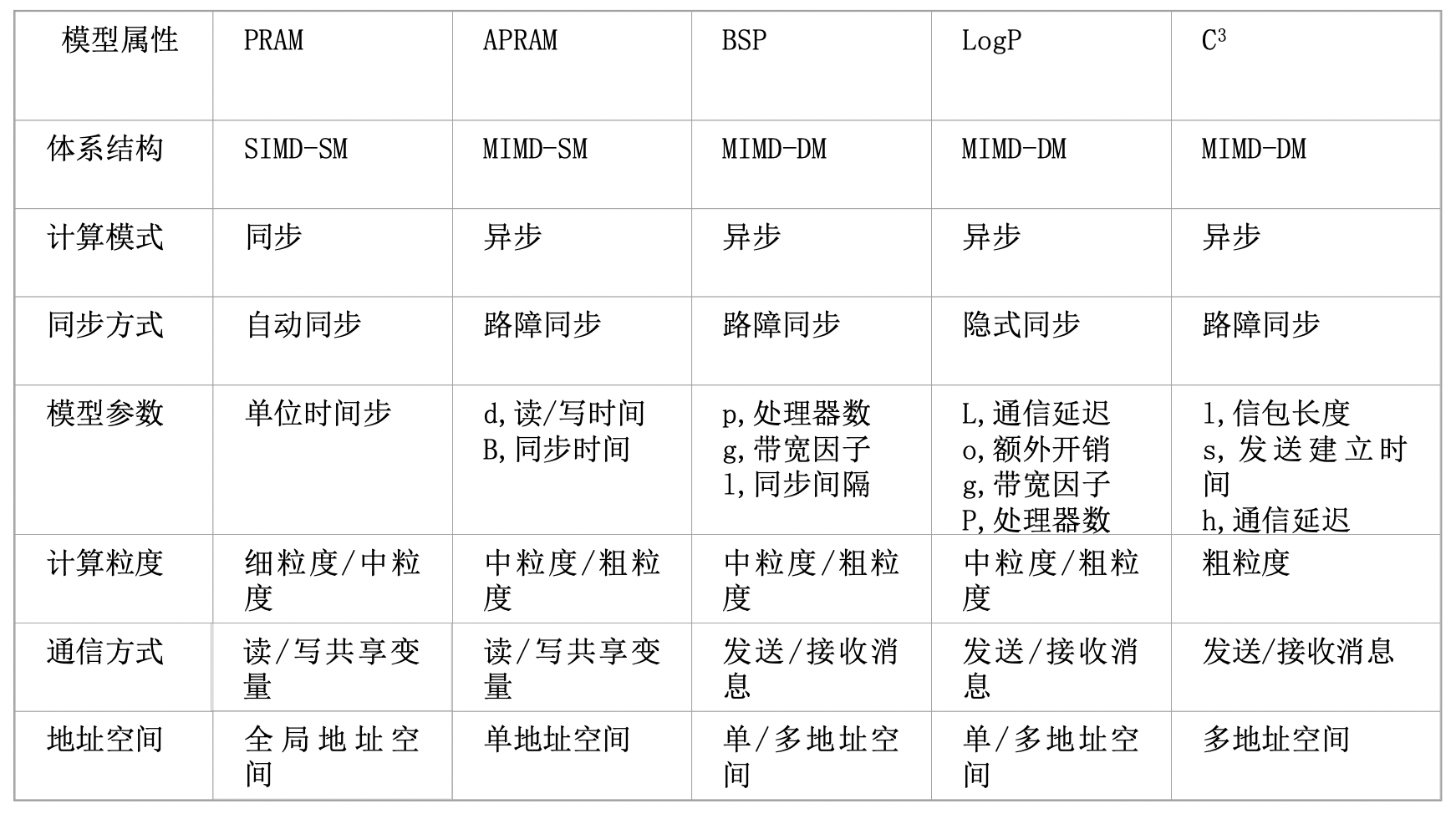
均匀访存模型(UMA)、非均匀访存模型(NUMA)、全高速缓存访存模型(COMA)、一致性高速缓存非均匀存储访问模型(CC-NUMA)和非远程存储访问模型(NORMA)。
UMA(Uniform Memory Access)均匀存储訪问:物理存储器被全部处理器均匀共享,全部处理器对全部SM訪存时间相同,每台处理器可带有快速私有缓存,外围设备共享。
NUMA非均匀存储訪问:共享的SM是由物理分布式的LM逻辑构成,处理器訪存时间不一样,訪问LM或CSM(群内共享存储器)内存储器比訪问GSM(群间共享存储器)快
COMA(Cache-Only MA)全快速缓存存储訪问:NUMA的特例、全快速缓存实现
CC-NUMA(Coherent-Cache NUMA)快速缓存一致性NUMA:NUMA+快速缓存一致性协议。实际是分布共享的DSM机器
NORMA(No-Remote MA)非远程存储訪问:无SM,全部LM私有。通过消息传递通信
NUMA : NUMA (non-uniform memory access) is a method of configuring a cluster of microprocessor in a multiprocessing system so that they can share memory locally, improving performance and the ability of the system to be expanded. NUMA is used in a symmetric multiprocessing ( SMP ) system.
在NUMA下,處理器存取它自己的本地記憶體的速度比非本地記憶體快一些。 非統一記憶體存取架構的特點是:被共享的記憶體物理上是分散式的,所有這些記憶體的集合就是全域位址空間。
Remote Direct Memory Access (RDMA) is an extension of the Direct Memory Access (DMA) technology, which is the ability to access host memory directly without CPU intervention. RDMA allows for accessing memory data from one host to another.
远程直接内存访问(英语:Remote Direct Memory Access,RDMA)是一种从一台计算机的内存到另一台计算机的内存的直接内存访问,而不涉及任何一台计算机的操作系统。这允许高吞吐量、低延迟联网,这在大规模并行计算机集群中特别有用。
重点是zero-copy, 不再需要机器缓存,然后拷贝传递信息。 InfiniBand网络默认支持,另一种就是RoCE
Most high performance computing clusters are nowadays composed of large multicore machines that expose Non-Uniform Memory Access (NUMA), and they are interconnected using modern communication paradigms, such as Remote Direct Memory Access (RDMA).
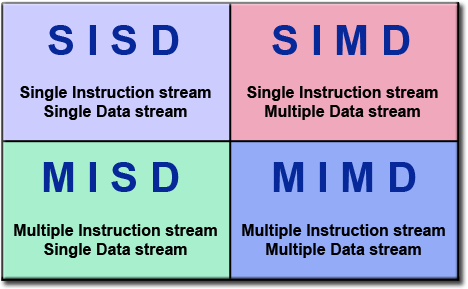
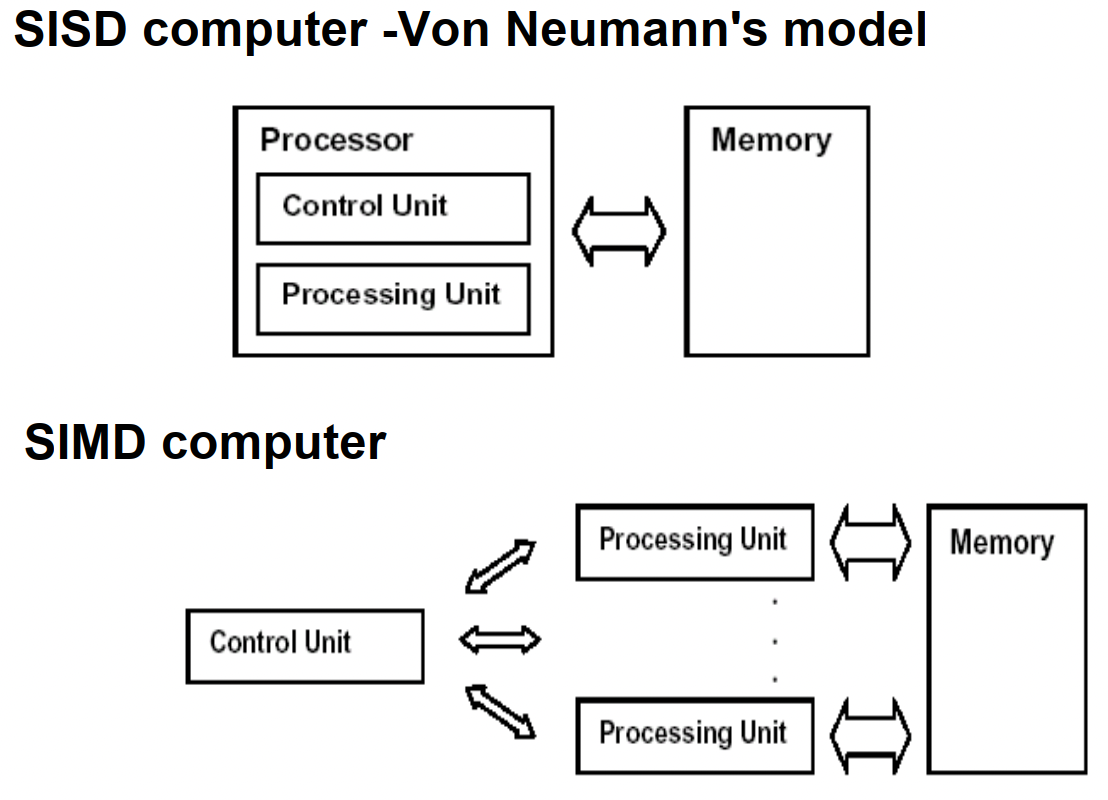
SISD:单指令流单数据流计算机(冯诺依曼机)
SIMD:单指令流多数据流计算机
MISD:多指令流单数据流计算机, 实际不存在
MIMD:多指令流多数据流计算机
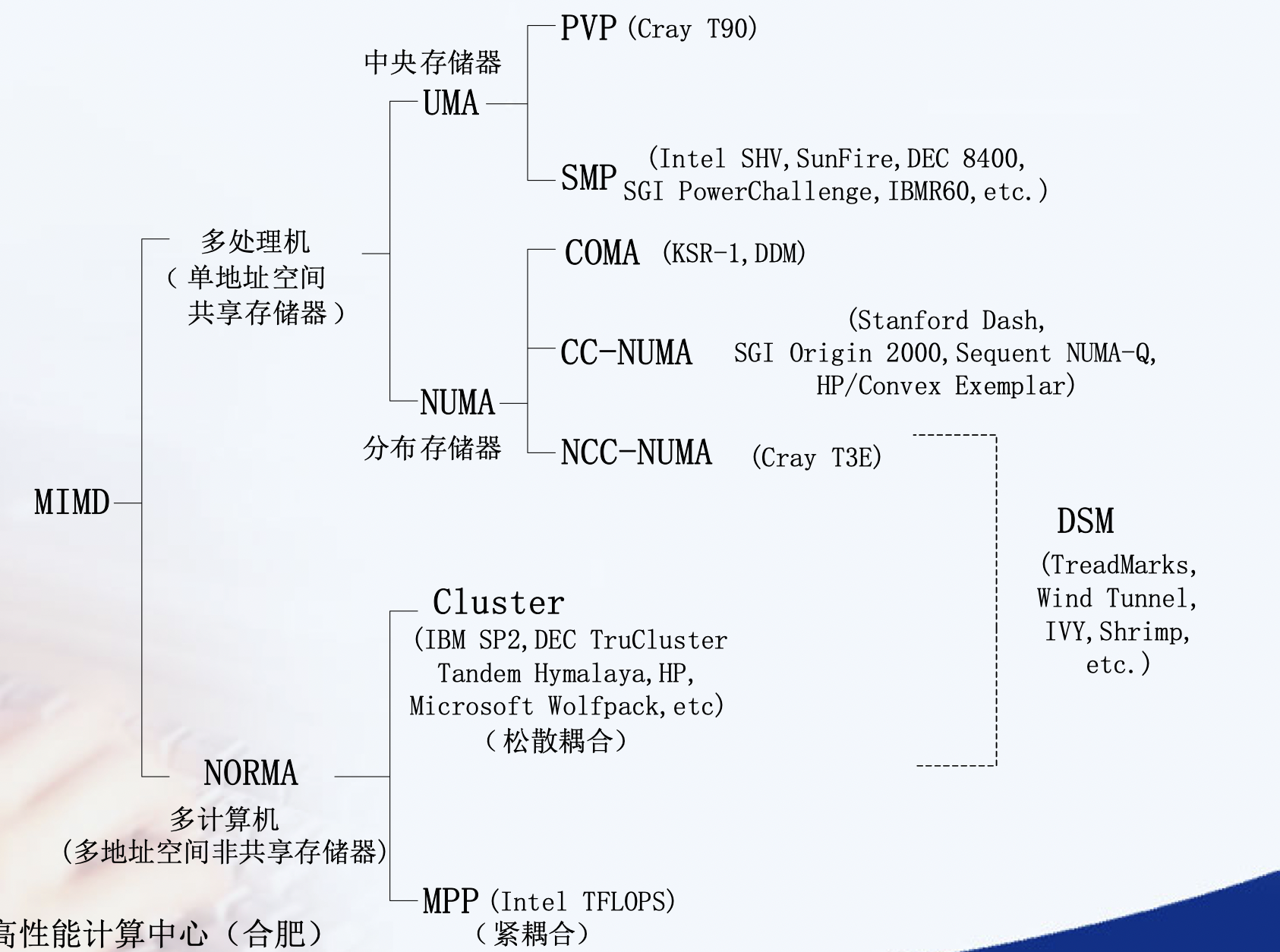
PRAM(Parallel Random Access Machine)模型是单指令流多数据流(SIMD)并行机中的一种具有共享存储的模型。
它假设有对其容量大小没有限制的一个共享存储器,并且有多个功能相同的处理器,在任意时刻处理器可以访问共享存储单元。根据是否可以同时读写,它又分为以下三类:PRAM-EREW,PRAM-CREW,PRAM-CRCW(其中C代表Concurrent,意为允许并发操作,E-代表Exclusive,意味排斥并发操作)。在PRAM中有一个同步时钟,所有的操作都是同步进行的。
具有局部存储器的PRAM模型称作LPRAM模型,具有异步时钟的PRAM模型称作APRAM模型。
在《并行算法的设计和分析》的第二十章-并行计算理论有额外的定义:
- 允许任意处理器自由读写的 SIMD-SM。简记为 APRAM-CRCW
- 只允许所有处理器并发写同一数的SIMD-SM。简记为CPRAM-CRCW
- 只允许最小号码处理器优先写的SIMD-SM。称作优先PRAM-CRCW。简记为PPRAM-CRCW
- 一个具有p个处理器的优先PRAM-CRCW模型。称作p-处理器的PPRAM-CRCW。
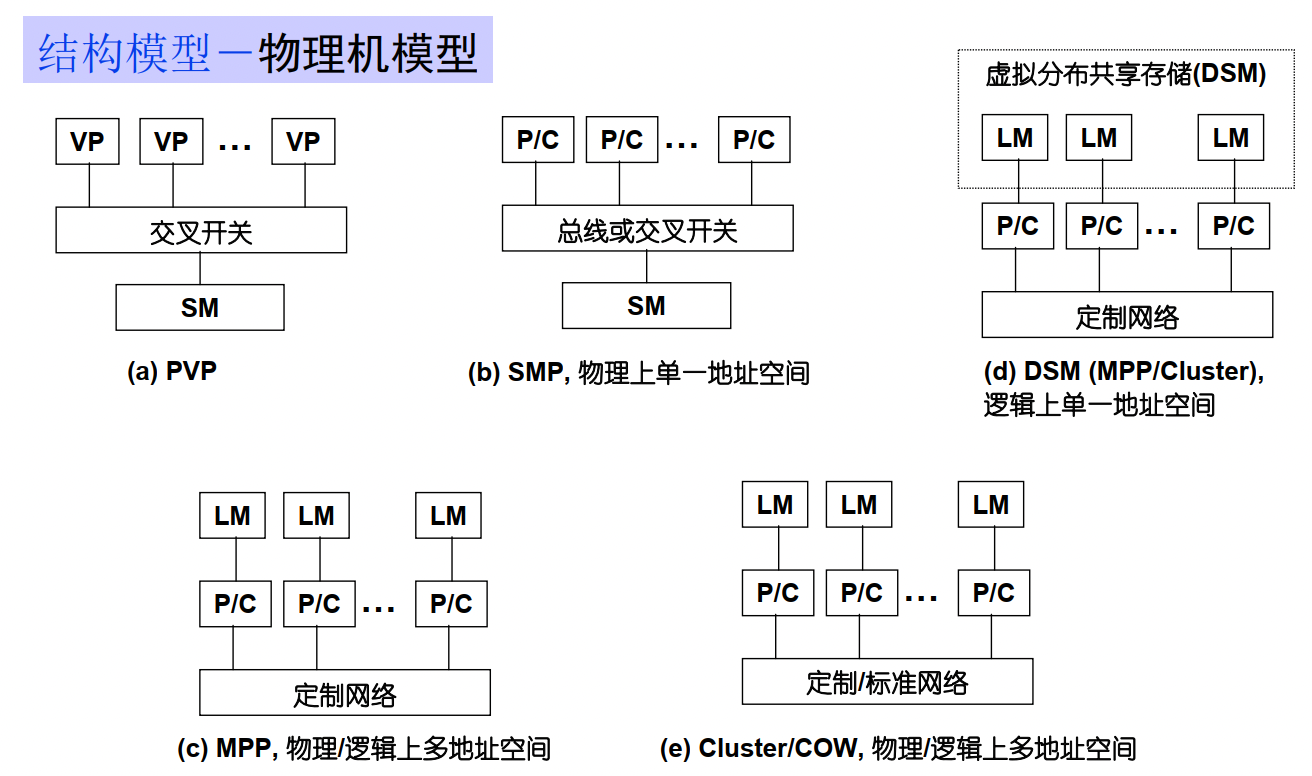
PVP并行向量处理机:多VP(向量处理器)通过交叉开关和多个SM(共享内存)相连
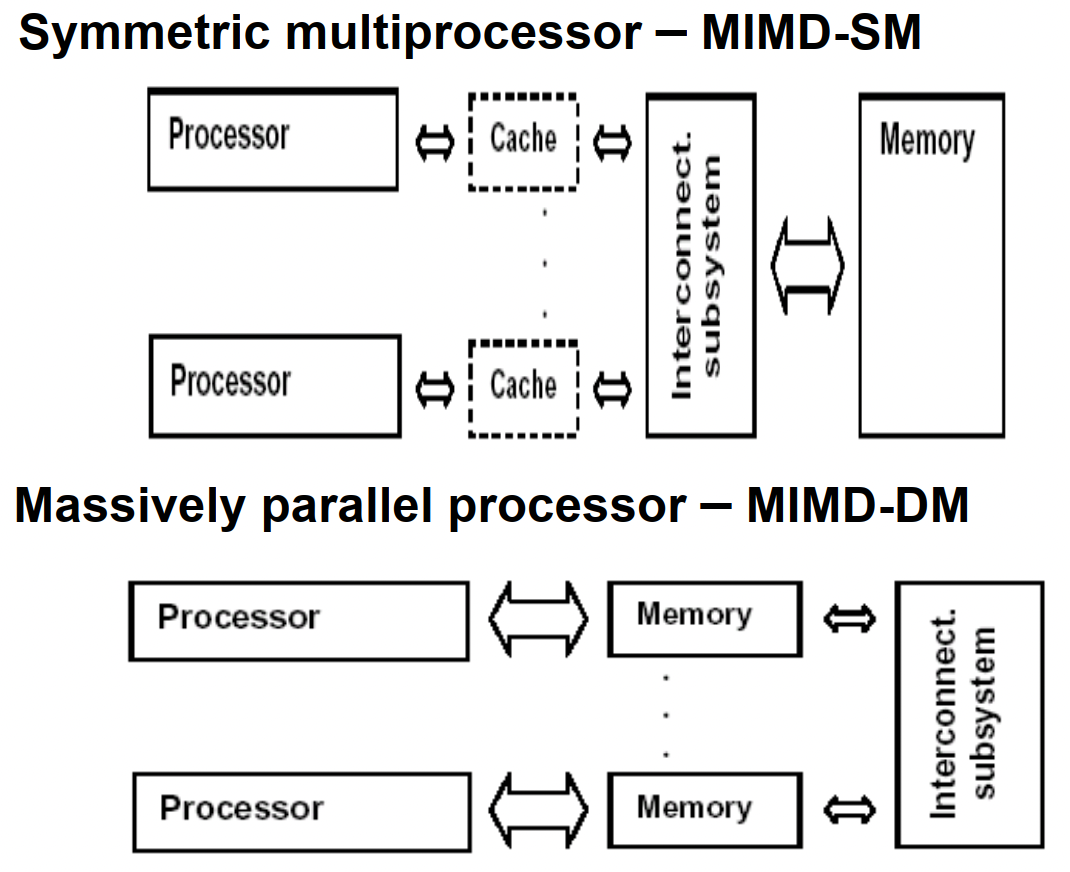
SMP对称多处理机:多P/C(商品微处理器)通过交叉开关/总线和多个SM(共享内存)相连
MPP大规模并行处理机:处理节点有商品微处理器+LM(分布式本地内存)。节点间通过高带宽低延迟定制网络互联,异步MIMD,多个进程有自己的地址空间,通过消息传递机制通信
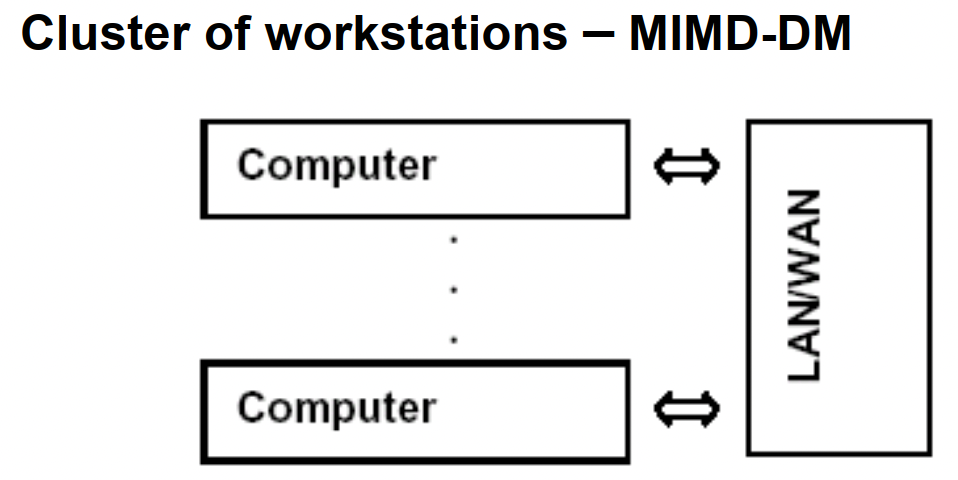
COW工作站机群:节点是完整操作系统的工作站,且有磁盘
DSM分布共享存储处理机:快速缓存文件夹DIR确保缓存一致性。将物理分布式LM组成逻辑共享SM从而提供统一地址的编程空间

暂无
暂无


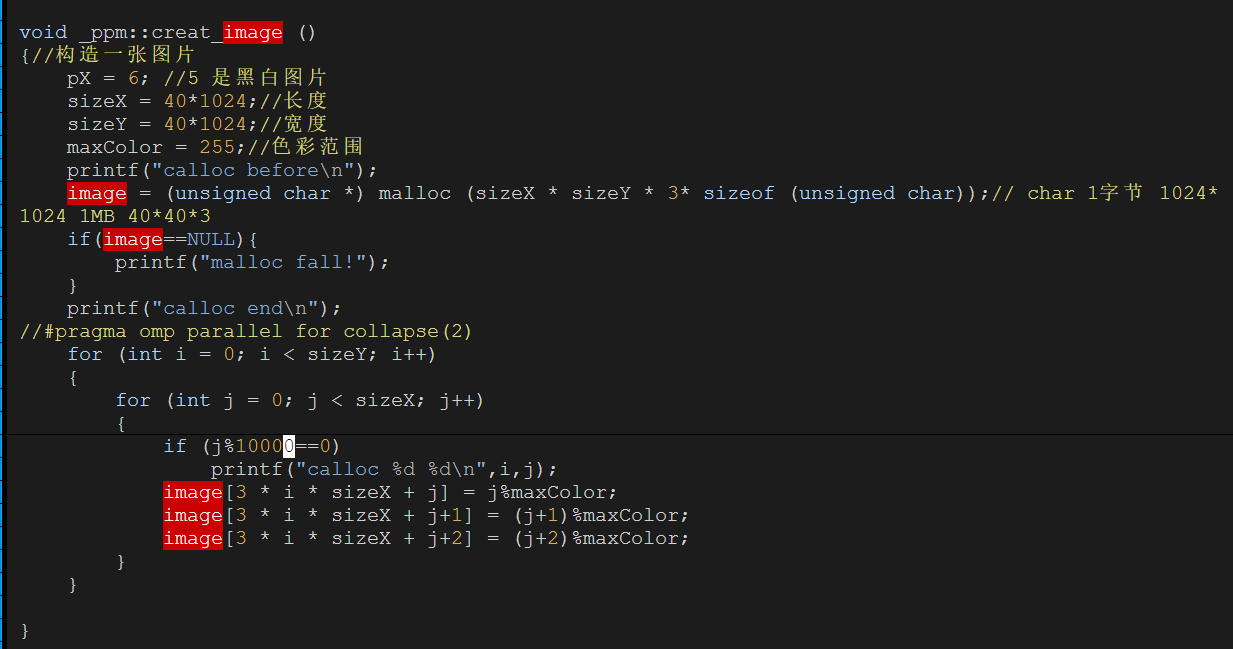
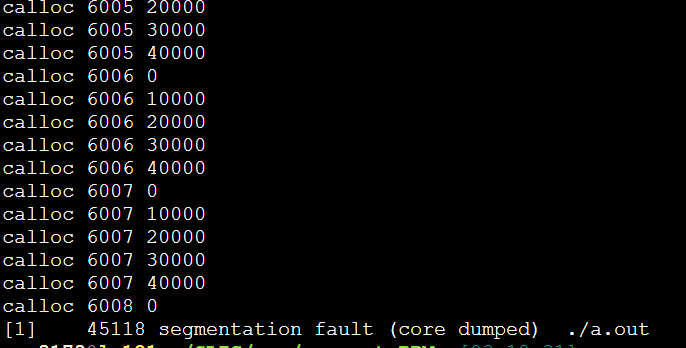 每次都是6008这里,40000*6008*3/1024/1024=687MB
每次都是6008这里,40000*6008*3/1024/1024=687MB
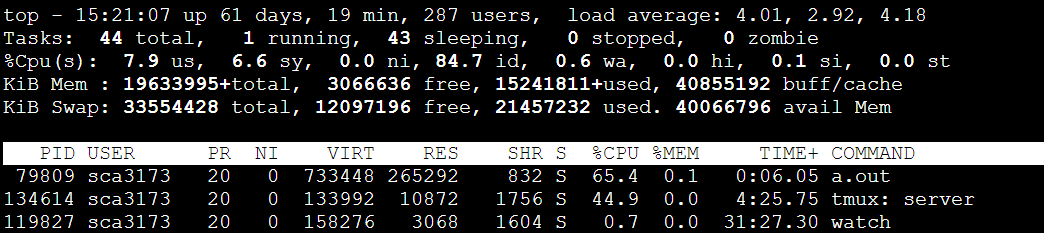 733448/1024=716MB
733448/1024=716MB
 问了大师兄,问题竟然是malloc的传入参数错误的类型是int,导致存不下3*40*1024*40*1024。应该用size_t类型。(size_t是跨平台的非负整数安全类型)
问了大师兄,问题竟然是malloc的传入参数错误的类型是int,导致存不下3*40*1024*40*1024。应该用size_t类型。(size_t是跨平台的非负整数安全类型)