Interview in english
Interview Preparation:
There is no set structure or format for your interview; it really just depends on the interviewer, and the direction the conversation goes, etc. You will likely be asked to explain something you worked on, and that would include some core skillset questions to check your understanding of your projects. Here are a few general suggestions to help you prepare:
1) Be prepared to speak at depth regarding any core skillset details in your background, for example: coding/technology-based questions; the two best ways to prepare for this would be to review your resume, and make sure you are able to talk at depth about skills you mentioned there, and to review the job description, and brush up on anything you might know, but feel you might not be able to go into detail about.
2) Ask good questions – about team, what we are up to, possible role/roles you might be a good fit for.
3) Read up on our website about our products and the company (many interviewers will ask what you know about us, and it is better to be prepared to answer - it shows interest in the company and what we are up to).
4) Access to a computer with an internet connection is typically required for your interviews
self-introduction in English
"Hello, I am a graduate student majoring in Computer Science and Technology at the University of Science and Technology of China. I am currently pursuing/pəˈsjuːɪŋ/ a master's degree. I completed my undergraduate studies at the same university and had the opportunity to participate in both the ASC and ISC competitions during my undergraduate years.
In my graduate studies, I have primarily focused on research related to High-Performance Computing. This includes projects such as static code analysis for Kunpeng processors, participation in program parallelization and acceleration optimization competitions, and exploring PIM (Processing in Memory) computing.
Through my academic and research experiences, I have developed a dual/ˈduːəl/ expertise /ˌekspɜːˈtiːz/ in computer microarchitecture and practical/ˈpræktɪkl/ application optimization. I have honed/hoʊnd/ the ability to swiftly identify program hotspots when faced with new applications, leveraging/ˈlevərɪdʒ/ the unique characteristics of computer systems to achieve efficient deployment and enhance program performance.
Furthermore, I have taken a keen/kiːn/ interest in emerging technologies such as artificial intelligence and machine learning. I aspire to apply these skills flexibly in fields like AI for science/HPC and AI program deployment. Thank you for considering my candidacy/ˈkændɪdəsi/ for this opportunity."
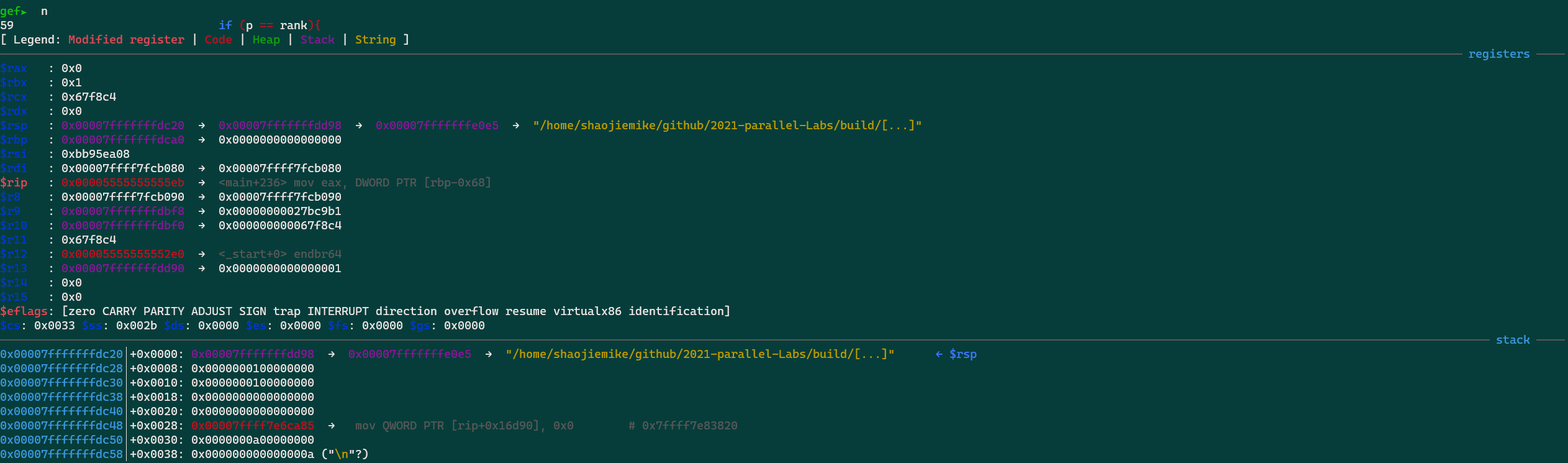
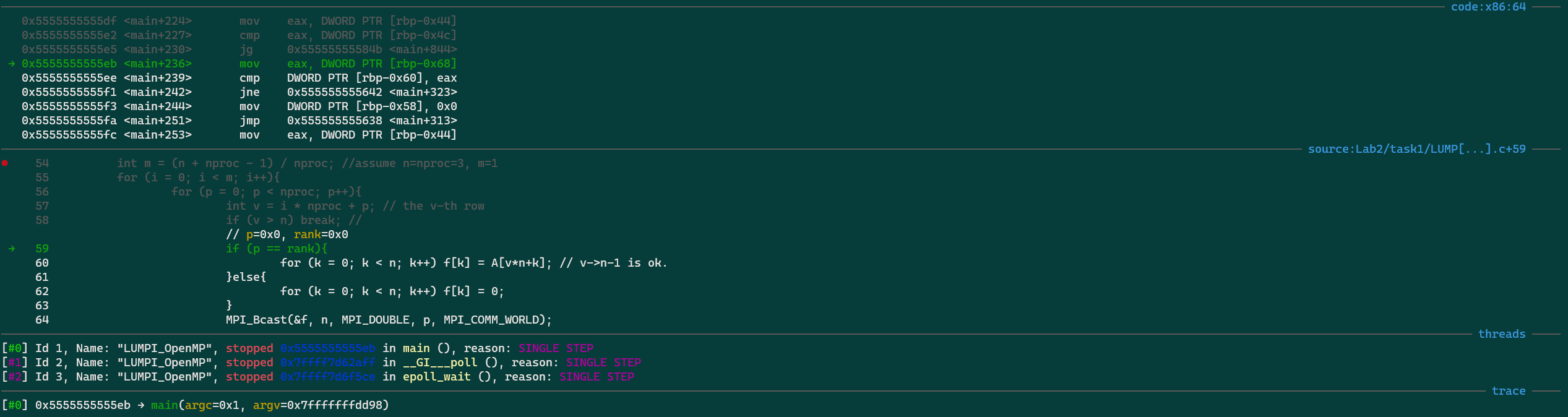
项目的介绍和关键字
参考文献
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
https://www.nowcoder.com/discuss/401041683767468032