URLs
导言
frequently-used out-of-work urls
导言
frequently-used out-of-work urls
导言
Summary your life and work in the anniversary to step into a better cycle.
导言
QCC(Quality Control Cycle) 自发的改进效率。
Situation:
Target:细化项目开发日志记录到一个Tomato周期,
Action:
vpn:英文全称是“Virtual Private Network”,翻译过来就是“虚拟专用网络”。vpn通常拿来做2个事情:
一句话,vpn在IP层工作,而ss在TCP层工作。

理解 VPN 路由(以及任何网络路由)配置的关键是认识到一个 IP packet 如何被传输,以下描述的是极度简化后的单向传输过程:
为什么机器 A 的本地路由表里会有 172.29.1.0/24 这个网段的路由规则?通常情况下,这是 OpenVPN 服务端推送给客户端,由客户端在建立 VPN 连接时自动添加的。也可以由服务端自定义,比如wireguard
这个时候,如果机器 B 想要回复 A(比如发个 ACK),就会出问题,因为 packet 的来源地址还是 10.8.0.123, 而 10.8.0.0/24 网段并不属于当前局域网,是 VPN 服务端私有的——机器 B 往 10.8.0.123 发送的 ACK 会在某个位置(比如默认网关)遇到 "host unreachable" 而被丢弃。对于机器 A 来说,表面现象可能是连接超时或 ping 不通。
解决方法是,在 packet 离开 VPN 服务端时,将其「伪装」成来自 172.29.0.3(举例VPN 服务端的局域网地址),这样机器 B 发送的 ACK 就能顺利回到 VPN 服务端,然后发给机器 A. 这就是所谓的 SNAT。
在 Linux 系统中由 iptables 来管理,具体命令是:
连接 OpenVPN 的两个 client 之间可以互相通信,这是因为服务端推送的路由里包含了对应的网段。但是想从 Client A 到达 Client B 所在局域网的其他机器,还需要额外的配置。因为 OpenVPN 服务端缺少 Client B 局域网相关的路由规则。
# server.conf
push "route 172.29.0.0 255.255.0.0" # client -> Client B 给客户端推送 172.29.0.0/16 网段的路由(即这个网段的IP的信息都经过VPN)
route 172.29.0.0 255.255.0.0 #在 OpenVPN Server 上添加 172.29.0.0/16 网段的路由,具体下一跳是哪里,由 client-config 里的 iroute 指定
# 启用 client-config, 目录里的文件名对应 client.crt 的 Common Name
client-config-dir /etc/openvpn/ccd
# /etc/openvpn/ccd/client-b
iroute 172.29.0.0 255.255.0.0 # 告诉 OpenVPN Server, 172.29.0.0/16 的下一跳应该是 client-b (根据名字来)
在前两节所给的配置基础上,只需要再加一点配置,就能实现 OpenVPN 服务端所在局域网与客户端所在局域网的互访。配置内容是,在各自局域网的默认网关上添加路由,将对方局域网网段的下一跳设为 OpenVPN 服务端 / 客户端所在机器,同时用 iptables 配置相应的 SNAT 规则。
Based on the info in clashio, we select some cheap vpns to try.
| name | 每月价格(¥/GB/off on holiday) | 每月单价(GB/¥) | 每年单价(GB/¥) | 节点数与稳定性 | 使用速度感觉 |
|---|---|---|---|---|---|
| fastlink 2019 | 20/100/-30% | 5 | 100+, 节点速度高达5Gbps | 峰值 5Gbps (1) | |
| totoro 2023 | 15/100/-20%(2) | 6.6 | ??? | ??? | |
| 冲浪猫 2022 | 16/200/-12%(3) | 12.5 | ??? | 峰值 1Gbps | |
| 奈云机场 2021 | 10.6/168/-30%(4) | 15.8 | 230624购买,240109几天全面掉线 | 峰值 5Gbps (6) | |
| FatCat 2023 | 6/60/-20% | 10 | ??? | 峰值 xx Gbps |
detail info in table
150¥*0.88My Choice: 单价,大小,速度,优惠码有效期
现在组合:奈云机场(2) + fastlink。 等fastlink过期了(1),看要不要转成 冲浪猫。
&flag=clash下载config.yamlNyacloud 喵云:只有10个节点 8¥/40GB/0.03Gbps or 17¥/128GB/0.2Gbps 平均 5GB/¥
边界网关协议(Border Gateway Protocol,BGP)就是互联网的邮政服务。当有人把一封信投进邮筒时,邮政服务就会处理这封邮件,并选择一条快速、高效的路线将这封信投递给收件人。同样地,当有人通过互联网提交数据时,BGP 负责寻找数据能传播的所有可用路径,并选择最佳的路由,这通常意味着在自治系统之间跳跃。1
BGP不仅能够解决速度问题,还可以解决绕过线路故障: 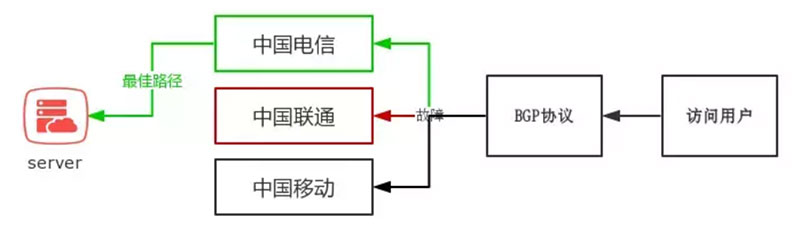
中文翻译是国际私用出租线路,是指用户专用的跨国的数据、话音等综合信息业务的通信线路。通俗地说,也就是指传统的跨境专线。
延迟更低40ms、速度更快, 但是价格贵1 元 / GB。
Anycast 是一种网络寻址和路由方法,可以将传入请求路由到各种不同的位置或“节点”。在 CDN 的上下文中,Anycast 通常会将传入的流量路由到距离最近并且能够有效处理请求的数据中心。选择性路由使 Anycast 网络能够应对高流量、网络拥塞和 DDoS 攻击。
brook vpn+ Amazon American node

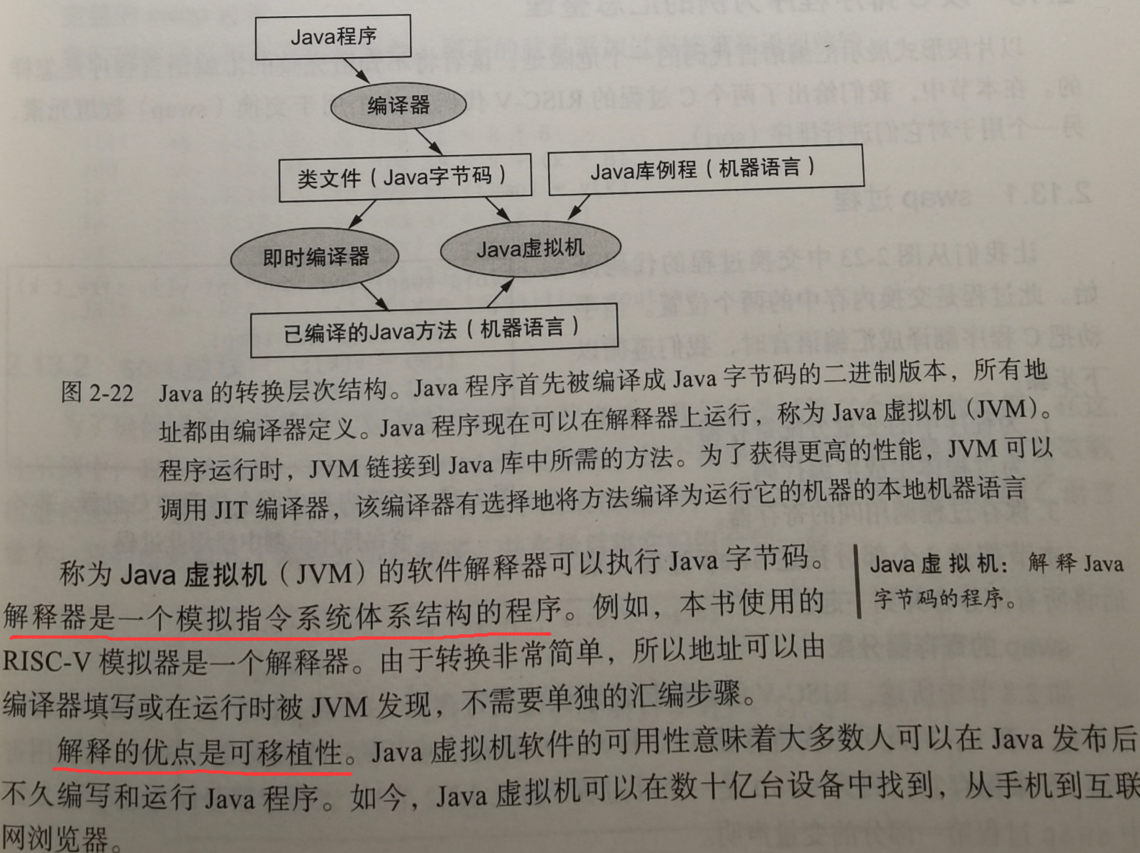

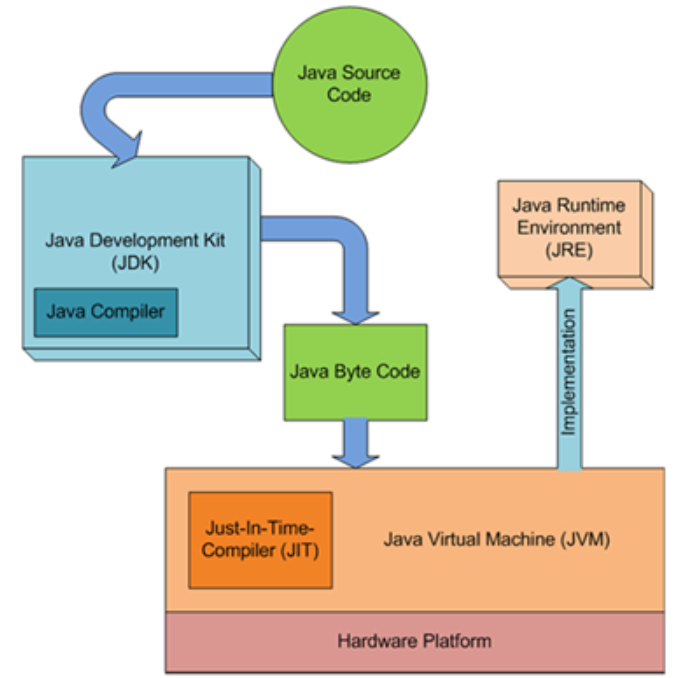
java 21 SDK seems not contain Java Control Panel (javacpl.exe), you need to install Java SE Development Kit 8u381 which include JDK 1.8 and JRE 1.8https://www.topcoder.com to allowed website (Attention: https)ContestAppletProd.jnlp127.0.0.1 proxy and HTTP TUNE 1 to connect to server暂无
暂无
无
简介
C 盘没空间了,啊啊啊~
It's a fucking crazy thing when you reuse a Bluetooth device, because forget how to make pair.
My keyboard encounter Poor contact of keyboard keys, esepeacially the ctrl
iOS fn + i
Mac OS X fn + o
Windows fn + p
Read more: official ref and ref_photo
It seems that just
you can Turn on the Bluetooth.
连接蓝牙方法:(我们键盘没有送蓝牙适配器)需要您电脑有蓝牙功能,
Windows weird option 输入 FC980MBT 的PIN,也可以选择关闭,尤其是鼠标也需要输入时:
00000 using original keyboard,click confirm.00000 using new keyboard, enter.暂无
暂无
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无
导言
常见的排行榜,国内外的GPT-like工具。
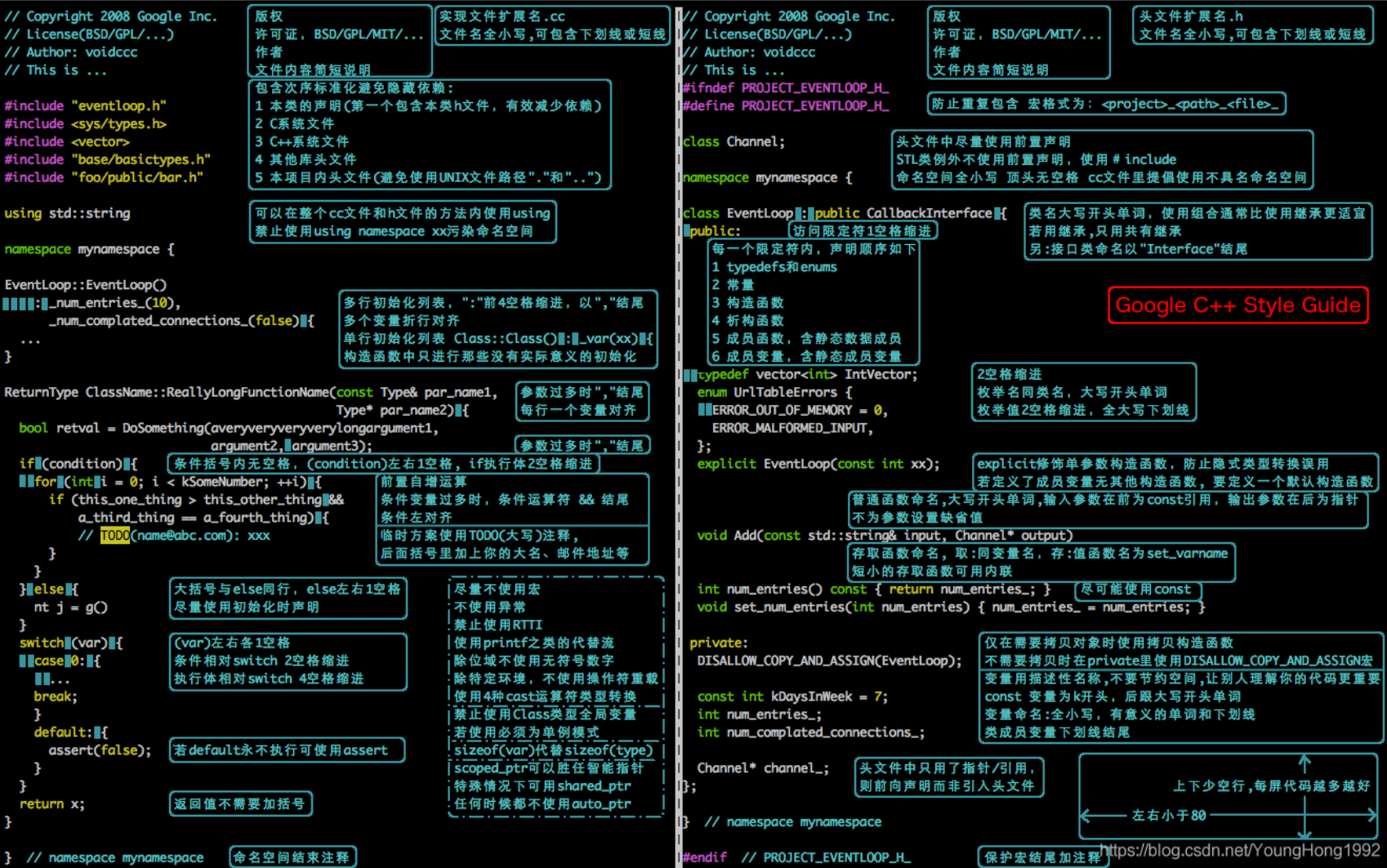
更宏观的问题:
面试官提问的:(生活相关的)
我提问的内容
暂无
暂无
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无