Vscode
导言
VSCODE 是 windows 项目开发的桥梁
导言
VSCODE 是 windows 项目开发的桥梁

: to change mode?/ to search? to up search* to search cursor current word1,3表示替换第一行至第三行,1,$表示替换第一行到最后一行,也可以直接用%表示。c: confirm,每次替换前都会询问 e:不显示error g: globe,不询问,整个替换 i: ignore,即不区分大小写:new[CTRL] [W] s[CTRL] [W] v:split [FILENAME] #或 :sp [FILENAME]:vsplit [FILENAME] #或 :vs [FILENAME]:only[CTRL] W o:q #或者: :quitsudo apt-get install exuberant-ctagsctags -R . /path/another/include will generate tags fileecho "set tags=$PWD/tags" >> ~/.vimrc
# or
vim ~/.vimrc
# set tags=~/Download/llvm-project-main/llvm/tags
huawei programming : dev machine 使用tmux和zsh可以实现统一的开发环境
导言
作为程序员,最经常遇到的问题就是无法访问github,这无异于和世界断开连接。
linux下通过按照如下修改.ssh/config设置账号密码,并 ssh -vT [email protected],成功后输出Hi Kirrito-k423! You've successfully authenticated, but GitHub does not provide shell access.。
# .ssh/config
Host github.com
User 943648187@qq.com
Hostname ssh.github.com
PreferredAuthentications publickey
ProxyCommand nc -X 5 -x 127.0.0.1:7890 %h %p #如果通过代理需要这句话
IdentityFile ~/.ssh/id_rsa
Port 443
Host *
# Win报错取消下面三行 getpeername failed: Not a socket getsockname failed: Not a socket
ControlMaster auto
ControlPath /tmp/sshcontrol-%C
ControlPersist 1d
ServerAliveInterval 30
nc: invalid option -- 'X'
使用 yum install nmap-ncat -y
假如是windows下,如果安装了git bash,会有connect.exe的程序
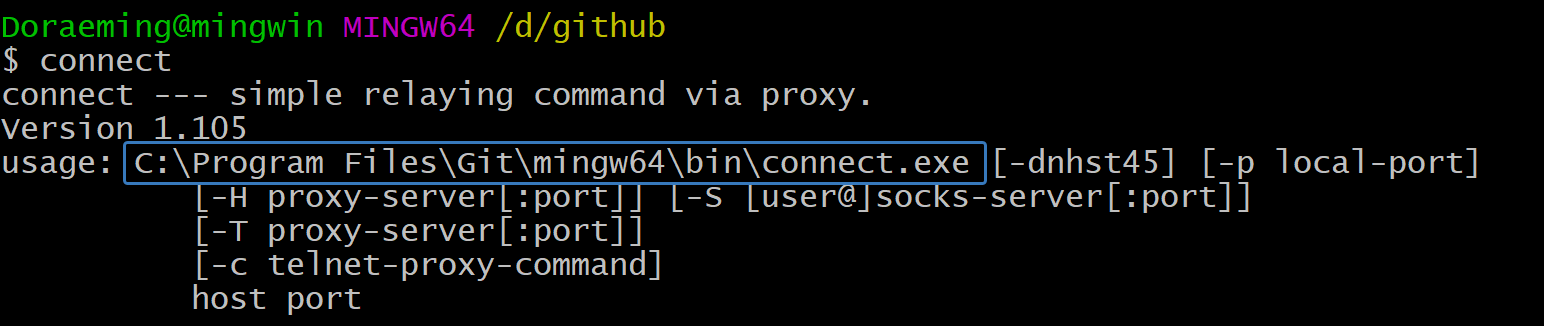
配置如下1
Host github.com
User git
Port 22
Hostname github.com
# 注意修改路径为你的路径
IdentityFile "C:\Users\Administrator\.ssh\id_rsa"
TCPKeepAlive yes
# 这里的 -a none 是 NO-AUTH 模式,参见 https://bitbucket.org/gotoh/connect/wiki/Home 中的 More detail 一节
ProxyCommand E:\\commonSoftware\\Git\\mingw64\\bin\\connect.exe -S 127.0.0.1:7890 -a none %h %p
Host ssh.github.com
User git
Port 443
Hostname ssh.github.com
# 注意修改路径为你的路径
IdentityFile "C:\Users\Administrator\.ssh\id_rsa"
TCPKeepAlive yes
ssh-git 与 https-git的不同
git config --global http.proxy localhost:7890 # PowerShell proxy
git config --global http.proxy "http://127.0.0.1:7890"
git config --global https.proxy "http://127.0.0.1:7890"
GIT_CURL_VERBOSE=1 GIT_TRACE=1 git clone [email protected]:Kirrito-k423/autoUpdateIpconfigPushGithub.git

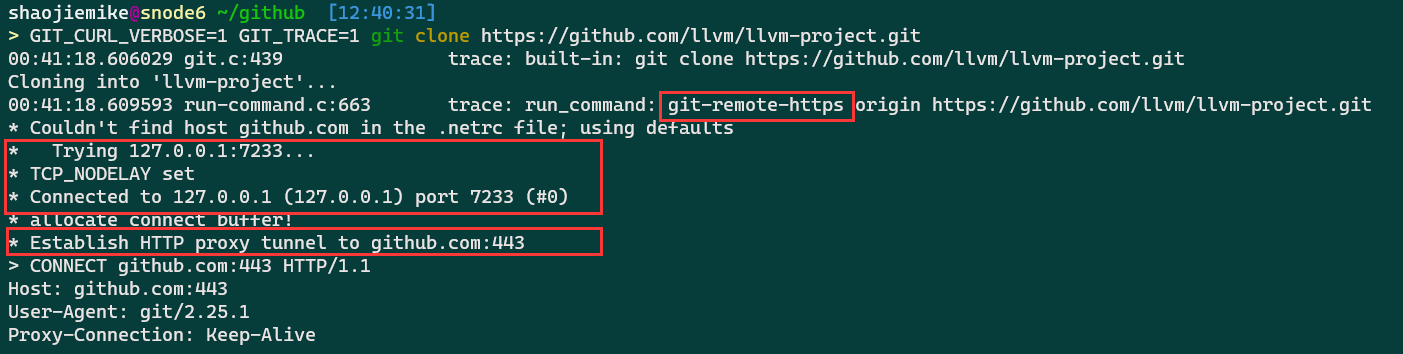
不同于linux平台的GIT_TRACE=1 git push,Windows PowerShell 平台应该如下设置:
没使用上指定config文件,git操作需要明确指定。
There are tons of identical solutions over the internet for defining proxy tunnel for git's downloads like this one, which all is by setting git's https.proxy & http.proxy config. but those answers are not working when you try to clone/push/pull etc. over the ssh protocol!
For example, by setting git config --global https.proxy socks5://127.0.0.1:9999 when you try to clone git clone [email protected]:user/repo.git it does not go through the defined sock5 tunnel!
环境实在是只有https代理, 可以利用github_token的https协议
# Method 1. git http + proxy http
git config --global http.proxy "http://127.0.0.1:1080"
git config --global https.proxy "http://127.0.0.1:1080"
# Method 2. git http + proxy shocks
git config --global http.proxy "socks5://127.0.0.1:1080"
git config --global https.proxy "socks5://127.0.0.1:1080"
# to unset
git config --global --unset http.proxy
git config --global --unset https.proxy
# Method 3. git ssh + proxy http
vim ~/.ssh/config
Host github.com
HostName github.com
User git
ProxyCommand socat - PROXY:127.0.0.1:%h:%p,proxyport=1087
# Method 4. git ssh + proxy socks
vim ~/.ssh/config
Host github.com
HostName github.com
User git
ProxyCommand nc -v -x 127.0.0.1:1080 %h %p
%h %p 是host和post的意思
或者
After some visiting so many pages, I finally find the solution to my question:
# [step 1] create a ssh-proxy
ssh -D 9999 -qCN [email protected]
# [step 2] make git connect through the ssh-proxy
# [current script only]
export GIT_SSH_COMMAND='ssh -o ProxyCommand="connect -S 127.0.0.1:9999 %h %p"'
# OR [git global setting]
git config --global core.sshCommand 'ssh -o ProxyCommand="connect -S 127.0.0.1:9999 %h %p"'
# OR [one-time only use]
git clone -c=core.sshCommand 'ssh -o ProxyCommand="connect -S 127.0.0.1:9999 %h %p"' [email protected]:user/repo.git
# OR [current repository use only]
git config core.sshCommand 'ssh -o ProxyCommand="connect -S 127.0.0.1:9999 %h %p"'
To install connect on Ubuntu:
ssh -vT -o "ProxyCommand connect -S 127.0.0.1:7890 %h %p" [email protected]
ssh -vT -o "ProxyCommand nc -X 5 -x 127.0.0.1:7890 %h %p" [email protected]
# 使用HTTP 代理
ssh -o ProxyCommand='corkscrew proxy.net 8888 %h %p' [email protected]
ssh -o ProxyCommand='proxytunnel -p proxy.net:8888 -P username -d %h:%p' [email protected]
post request forward is an all-in-one solution.
interface: warp
public key: fcDZCrGbcpz3sKFqhBw7PtdInygUOtEJfPAs08Wwplc=
private key: (hidden)
listening port: 51825
peer: bmXOC+F1FxEMF9dyiK2H5/1SUtzH0JuVo51h2wPfgyo=
endpoint: [2606:4700:d0::a29f:c001]:1701
allowed ips: 172.16.0.0/24, 0.0.0.0/0, ::/0
latest handshake: 89 days, 23 hours, 15 minutes, 28 seconds ago
transfer: 3.51 GiB received, 1.71 GiB sent
persistent keepalive: every 25 seconds
latest handshake: 89 days ago demonstrate wg is done for a long time. At the same time mtr github.com shows no output prove the bad situation.
STEP1: first try is to bring the wg-proxy up again
python register.py #自动生成warp-op.conf,warp.conf和warp-helper
mv warp-helper /etc/default
vim /etc/config/network #填写warp-op.conf内容,修改只用替换option private_key 和 ipv6 的 list addresses 即可
ifup warp #启动warp, 代替wg-quick up warp.conf
and test brainiac machine is back online
Sometimes,it‘s the big log fault.
# find file
find . -type f -name "zsim.log.0" -size +10M
# find the most repeated lines
head -n 10000 your_file.txt | sort | uniq -c | sort -nr | head
# delete partten line in files
sed -i '/\[S 0\] WARN: \[6\] ContextChange, reason SIGRETURN, inSyscall 1/d' /staff/shaojiemike/github/PIA_huawei/log/zsim/chai-n/hsti/1000/cpu_tlb/zsim.log.0
# conbine two command
find . -type f -name "zsim.log.0" -size +10M -print0 | xargs -0 sed -i '/字符串模式/d'
# or just save the tail (sth wrong needed test)
find . -type f -name "zsim.log.0" -size +1M -exec bash -c 'tail -n 2000 "$1" > "$1"_back ' _ {} \;
t00906153@A2305023964 MINGW64 ~/github
$ git clone https://github.com/jeremy-rifkin/cpptrace.git
Cloning into 'cpptrace'...
fatal: unable to access 'https://github.com/jeremy-rifkin/cpptrace.git/': SSL certificate problem: self-signed certificate in certificate chain
error: RPC failed; curl 18 transfer closed with outstanding read data remaining
出现于使用https协议,下载大仓库时,出现该错误。
depth=1参数,只下载最新提交。之后下好后能适应unshallow复原
设置mtu解决:
STEP1:
eno0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 202.38.73.217 netmask 255.255.255.0 broadcast 202.38.73.255
inet6 fe80::ae1f:6bff:fe8a:e4ba prefixlen 64 scopeid 0x20<link>
inet6 2001:da8:d800:811:ae1f:6bff:fe8a:e4ba prefixlen 64 scopeid 0x0<global>
inet6 2001:da8:d800:730:ae1f:6bff:fe8a:e4ba prefixlen 64 scopeid 0x0<global>
ether ac:1f:6b:8a:e4:ba txqueuelen 1000 (以太网)
RX packets 12345942 bytes 2946978044 (2.9 GB)
RX errors 0 dropped 1438318 overruns 0 frame 0
TX packets 4582067 bytes 675384424 (675.3 MB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
STEP2:
STEP3:
内存为两根8GB DDR4-3200内存组成双通道。 如果要拓展,需要全部升级为 16GB * 2。 拓展视频和图文教程
可以加装一条2280的固态, 但是无法加机械了。
PCIe 3.0的数据传输速度每通道1GB/s,PCIe 2.0是其一半
B450迫击炮有两个M2插槽,一个是满速pcie3.0×4(4GB/s) 一个是半速的pcie2.0×4(2GB/s)。价格差不多的话还是用M2 nvme协议 的SSD
一点没人提过的,b450m迫击炮装上第二个m2以后,第二个pcie2.0*16的扩展(pcie_4)是没法用的。
暂无
暂无
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无
导言
Git命令的基本使用。
暂无
暂无
周报是一周的总结和思考,
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无
AI相关的基础知识。 可以参考华为昇腾架构师的博客。
导言
做了30天的leetcode,发现不会的还是不会。我就知道我
学而不思则罔
脑中一团浆糊,虽然学习了一些常见题型的框架、解法以及例题。
但是遇到新题目,是否能使用这些方法,以及如何转换使用还是没考虑清楚。
for(auto x : range).for(auto && x : range)for(const auto & x : range).使用begin end
vector<int>& nums1
unordered_set<int> nums_set(nums1.begin(), nums1.end());
unordered_set<int> result;
return vector<int>(result.begin(), result.end());
以下是整理和改正后的迭代器笔记。
运算支持:
+ 和 - 运算符,允许轻松地在迭代器位置上进行移动。[],使其用法与指针类似。it,可以通过 *(it + i) 或 it[i] 语法访问第 i 个元素。使用场景:
vector 和 deque 都提供随机访问迭代器。std::sort、std::nth_element)要求输入的迭代器必须是随机访问迭代器,以便快速定位和排序。begin() 到 end())和反向迭代器(rbegin() 到 rend()),二者在遍历方向上相反。转换:正向迭代器和反向迭代器可以相互转换,但类型不同,需要显式转换。
base() 成员函数可以返回一个指向反向迭代器当前元素的下一个位置的正向迭代器。注意:
rit.base() 指向的并不是 rit 当前元素本身,而是 rit 指向元素的下一个位置。C++ 提供了 rbegin() 和 rend() 来支持容器的反向遍历:
rbegin() 返回一个反向迭代器,指向容器的最后一个元素。rend() 返回一个反向迭代器,指向容器反向遍历时的“结束位置”,即第一个元素之前的一个位置。++it 而非 --it,因为反向迭代器的递增操作相当于在正向迭代器上进行递减操作。for (auto it = collection.rbegin(); it != collection.rend(); ++it) {
std::cout << *it << std::endl;
// 或者如果是键值对容器:
// std::cout << it->first << ", " << it->second << std::endl;
}
end() 和 begin()可以这样写:
std::prev 函数接受两个参数:一个是指向迭代器的参数,另一个是整数偏移量。它返回从指定迭代器开始向前移动指定偏移量后的迭代器。std::next 函数接受两个参数:一个是指向迭代器的参数,另一个是整数偏移量。它返回从指定迭代器开始向后移动指定偏移量后的迭代器。advance
std::advance 形似index的随机访问,函数的实现方式取决于迭代器的类型:
+= 运算符来实现移动。std::advance 的一个简单实现, 这个实现使用了 C++17 的 if constexpr 特性,以便在编译时选择不同的实现方式。:template <typename InputIt, typename Distance>
void advance(InputIt& it, Distance n) {
if constexpr (std::is_same_v<std::random_access_iterator_tag,
typename std::iterator_traits<InputIt>::iterator_category>) {
it += n; //如果迭代器是随机访问迭代器(后面解释),它会使用 += 运算符来移动;
} else {
if (n >= 0) {
while (n--) {
++it; //否则,它会使用循环来移动。
}
} else {
while (n++) {
--it;
}
}
}
}
bitset类型存储二进制数位。
std::bitset<16> foo;
std::bitset<16> bar (0xfa2);
std::bitset<16> baz (std::string("0101111001"));
//foo: 0000000000000000
//bar: 0000111110100010
//baz: 0000000101111001
将数转化为其二进制的字符串表示
int i = 3;
string bin = bitset<16>(i).to_string(); //bin = "0000000000000011"
bin = bin.substr(bin.find('1')); //bin = "11"
#include <utility>
pair<T1, T2> p1; //创建一个空的pair对象(使用默认构造),它的两个元素分别是T1和T2类型,采用值初始化。
pair<T1, T2> p1(v1, v2); //创建一个pair对象,它的两个元素分别是T1和T2类型,其中first成员初始化为v1,second成员初始化为v2。
make_pair(v1, v2); // 以v1和v2的值创建一个新的pair对象,其元素类型分别是v1和v2的类型。
p1 < p2; // 两个pair对象间的小于运算,其定义遵循字典次序:如 p1.first < p2.first 或者 !(p2.first < p1.first) && (p1.second < p2.second) 则返回true。
p1 == p2; // 如果两个对象的first和second依次相等,则这两个对象相等;该运算使用元素的==操作符。
p1.first; // 返回对象p1中名为first的公有数据成员
p1.second; // 返回对象p1中名为second的公有数据成员
#include <tuple> // 包含 tuple
std::tuple<int, std::string, double> t1(1, "one", 1.0);
// 使用 make_tuple 函数
auto t2 = std::make_tuple(2, "two", 2.5);
//使用 tuple 时,访问/修改元素使用 std::get<index>。
std::cout << "Tuple t2: ("
<< std::get<0>(t2) << ", "
<< std::get<1>(t2) << ", "
<< std::get<2>(t2) << ")"
<< std::endl;
std::string s0 ("Initial string");
// constructors used in the same order as described above:
std::string s1;
std::string s2 (s0);
std::string s3 (s0, 8, 3);
std::string s4 ("A character sequence");
std::string s5 ("Another character sequence", 12);
std::string s6a (10, 'x');
std::string s6b (10, 42); // 42 is the ASCII code for '*'
std::string s7 (s0.begin(), s0.begin()+7);
std::cout << "s1: " << s1 << "\ns2: " << s2 << "\ns3: " << s3;
std::cout << "\ns4: " << s4 << "\ns5: " << s5 << "\ns6a: " << s6a;
std::cout << "\ns6b: " << s6b << "\ns7: " << s7 << '\n';
//output
s1:
s2: Initial string
s3: str
s4: A character sequence
s5: Another char
s6a: xxxxxxxxxx
s6b: **********
s7: Initial
读取空格分割的
使用insert()在指向位置的右边插入
// inserting into a string
#include <iostream>
#include <string>
std::string str="to be question";
std::string str2="the ";
std::string str3="or not to be";
std::string::iterator it;
// used in the same order as described above:
str.insert(6,str2); // to be (the )question
str.insert(10,"to be "); // to be not (to be )that is the question
it = str.insert(str.begin()+5,','); // to be(,) not to be: that is the question
str.insert(6,str3,3,4); // to be (not )the question
str.insert(10,"that is cool",8); // to be not (that is )the question
str.insert(str.end(),3,'.'); // to be, not to be: that is the question(...)
str.insert(15,1,':'); // to be not to be(:) that is the question
// ???
str.insert (it+2,str3.begin(),str3.begin()+3); // (or )
插入char不同的方法
str3 = str1;
三种情况
// string::erase
#include <iostream>
#include <string>
int main ()
{
std::string str ("This is an example sentence.");
std::string str1(str) ;
std::cout << str << '\n';
// "This is an example sentence."
str.erase (10,8); // ^^^^^^^^
//去除index=10的连续8个元素,
//去除从index=3开始的所有元素, 后面全删除
str1.erase (3);
// "Thi"
std::cout << str << '\n';
// "This is an sentence."
str.erase (str.begin()+9); // ^
//去除itr指向的元素
std::cout << str << '\n';
// "This is a sentence."
str.erase (str.begin()+5, str.end()-9); // ^^^^^
//去除[first,last).的元素
std::cout << str << '\n';
// "This sentence."
return 0;
}
npos是一个常数,表示size_t的最大值(Maximum value for size_t)。许多容器都提供这个东西,用来表示不存在的位置,类型一般是std::container_type::size_type。
isdigit 是 C 标准库中的函数,用于检查一个字符是否为数字字符。它定义在
要检查一个 std::string 是否以某个前缀开头,std::string 没有直接提供“检查前缀”的方法,但可以使用 compare 或 find 方法实现。
方法 1:使用 compare 检查前缀
std::string::compare 可以比较字符串的部分内容,适合用于前缀检查。
#include <iostream>
#include <string>
bool hasPrefix(const std::string& str, const std::string& prefix) {
return str.compare(0, prefix.size(), prefix) == 0;
}
int main() {
std::string text = "Hello, world!";
std::string prefix = "Hello";
if (hasPrefix(text, prefix)) {
std::cout << "The string starts with the prefix." << std::endl;
} else {
std::cout << "The string does not start with the prefix." << std::endl;
}
return 0;
}
方法 2:使用 find 检查前缀
可以使用 std::string::find,但需要确认找到的位置是否是 0 才能确定是前缀。
#include <iostream>
#include <string>
bool hasPrefix(const std::string& str, const std::string& prefix) {
return str.find(prefix) == 0;
}
int main() {
std::string text = "Hello, world!";
std::string prefix = "Hello";
if (hasPrefix(text, prefix)) {
std::cout << "The string starts with the prefix." << std::endl;
} else {
std::cout << "The string does not start with the prefix." << std::endl;
}
return 0;
}
方法 3:使用 std::string::starts_with (C++20)
如果你使用的是 C++20 或更高版本,可以直接使用 starts_with 方法。
#include <iostream>
#include <string>
int main() {
std::string text = "Hello, world!";
std::string prefix = "Hello";
if (text.starts_with(prefix)) {
std::cout << "The string starts with the prefix." << std::endl;
} else {
std::cout << "The string does not start with the prefix." << std::endl;
}
return 0;
}
总结
starts_with。compare 或 find,推荐 compare,因为它可以直接比较前缀而不需要判断位置。std::string::rfind 是 C++ 标准库提供的一个方法,用于从字符串的末尾向前查找指定的子字符串或字符。它的功能与 find 类似,但查找方向是从右向左,适用于需要从字符串末尾开始定位子字符串的情况。
函数原型
size_t rfind(const std::string& str, size_t pos = std::string::npos) const;
size_t rfind(const char* s, size_t pos = std::string::npos) const;
size_t rfind(char c, size_t pos = std::string::npos) const;
参数说明
const char*)。pos 位置向前查找,默认值为 std::string::npos,表示从末尾开始查找。返回值
std::string::npos。使用示例
#include <iostream>
#include <string>
int main() {
std::string text = "Hello, world! Hello, C++!";
size_t pos = text.rfind("Hello");
if (pos != std::string::npos) {
std::cout << "'Hello' found at position: " << pos << std::endl;
} else {
std::cout << "'Hello' not found." << std::endl;
}
return 0;
}
输出:
#include <iostream>
#include <string>
int main() {
std::string text = "abcdefgabc";
size_t pos = text.rfind('a');
if (pos != std::string::npos) {
std::cout << "'a' found at position: " << pos << std::endl;
} else {
std::cout << "'a' not found." << std::endl;
}
return 0;
}
输出:
如果想要从特定位置向前查找,可以指定 pos 参数。例如,从索引 10 向前查找字符 'o':
#include <iostream>
#include <string>
int main() {
std::string text = "Hello, world! Hello, C++!";
size_t pos = text.rfind('o', 10);
if (pos != std::string::npos) {
std::cout << "'o' found at position: " << pos << std::endl;
} else {
std::cout << "'o' not found." << std::endl;
}
return 0;
}
输出:
在这些示例中,rfind 帮助我们从右向左查找字符串或字符,适用于查找最后一次出现的位置或从右边指定位置向左查找的需求。
undo xxx aaa 4 to 10在 C++ 中,可以使用 std::regex、std::stringstream 或 std::find_if 等方法对字符串进行解析和分割。以下提供一种基于 std::regex 的方法来提取单个数字和范围(如 4 to 10)。
#include <vector>
#include <regex> //important
// 解析字符串中的所有单个数字和范围
void parseNumbers(const std::string& input, std::vector<std::pair<int, int>>& ranges) {
// 在 C++ 中,使用 R"(...)" 定义原始字符串,可以避免转义字符
std::regex rangePattern(R"(\b(\d+)\s+to\s+(\d+)\b)"); // 匹配范围形式
std::smatch match;
std::string::const_iterator searchStart(input.cbegin());
// 找到所有的范围
while (std::regex_search(searchStart, input.cend(), match, rangePattern)) {
int start = std::stoi(match[1]);
int end = std::stoi(match[2]);
ranges.emplace_back(start, end);
searchStart = match.suffix().first; // 更新搜索起点
}
}
int main() {
std::string input = "undo xxx aaa 1 2 4 to 10";
std::vector<std::pair<int, int>> ranges;
parseNumbers(input, ranges);
// 输出范围
return 0;
}
顺序容器包括vector、deque、list、forward_list、array、string,
关联容器包括set、map,
关联容器和顺序容器有着根本的不同:关联容器中的元素是按关键字来保存和访问的。与之相对,顺序容器中的元素是按它们在容器中的位置来顺序保存和访问的。
为何map和set的插入删除效率比用其他序列容器高?
因为对于关联容器来说,不需要做内存拷贝和内存移动。说对了,确实如此。map和set容器内所有元素都是以节点的方式来存储,其节点结构和链表差不多,指向父节点和子节点。
插入的时候只需要稍做变换,把节点的指针指向新的节点就可以了。删除的时候类似,稍做变换后把指向删除节点的指针指向其他节点就OK了。这里的一切操作就是指针换来换去,和内存移动没有关系。
链表,或者数组(如果父节点的数组下标是 i,那么它的左孩子就是 i * 2 + 1,右孩子就是 i * 2 + 2。)
链式结构如下,注意左右孩子节点
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x) : val(x), left(NULL), right(NULL) {}
};
TreeNode* a = new TreeNode();
a->val = 9;
a->left = NULL;
a->right = NULL;
深度遍历: 前/中/后序遍历。
注意:这里前中后,其实指的就是中间节点/根节点的遍历顺序
堆(Heap)是计算机科学中一类特殊的数据结构的统称。
堆通常是一个可以被看做一棵完全二叉树的数组对象。
堆满足下列性质:
堆总是一棵完全二叉树。
make_heap()将区间内的元素转化为heap.
push_heap()对heap增加一个元素.pop_heap()对heap取出下一个元素.sort_heap()对heap转化为一个已排序群集.#include <algorithm>
int myints[] = {10,20,30,5,15};
vector<int> v(myints,myints+5);
vector<int>::iterator it;
make_heap (v.begin(),v.end());//male_heap就是构造一棵树,使得每个父结点均大于等于其子女结点
cout << "initial max heap : " << v.front() << endl;
pop_heap (v.begin(),v.end());//pop_heap不是删除某个元素而是把第一个和最后一个元素对调后[first,end-1]进行构树,最后一个不进行构树
v.pop_back();//删除最后一个的结点
cout << "max heap after pop : " << v.front() << endl;
v.push_back(99);//在最后增加一个结点
push_heap (v.begin(),v.end());//重新构树
cout << "max heap after push: " << v.front() << endl;
//请在使用这个函数前,确定序列符合堆的特性,否则会报错!
sort_heap (v.begin(),v.end());//把树的结点的权值进行排序,排序后,序列将失去堆的特性
std::cout << "sorted array : ";
for (int i = 0; i < v.size(); ++i) {
std::cout << v[i] << ' ';
}
std::cout << std::endl;
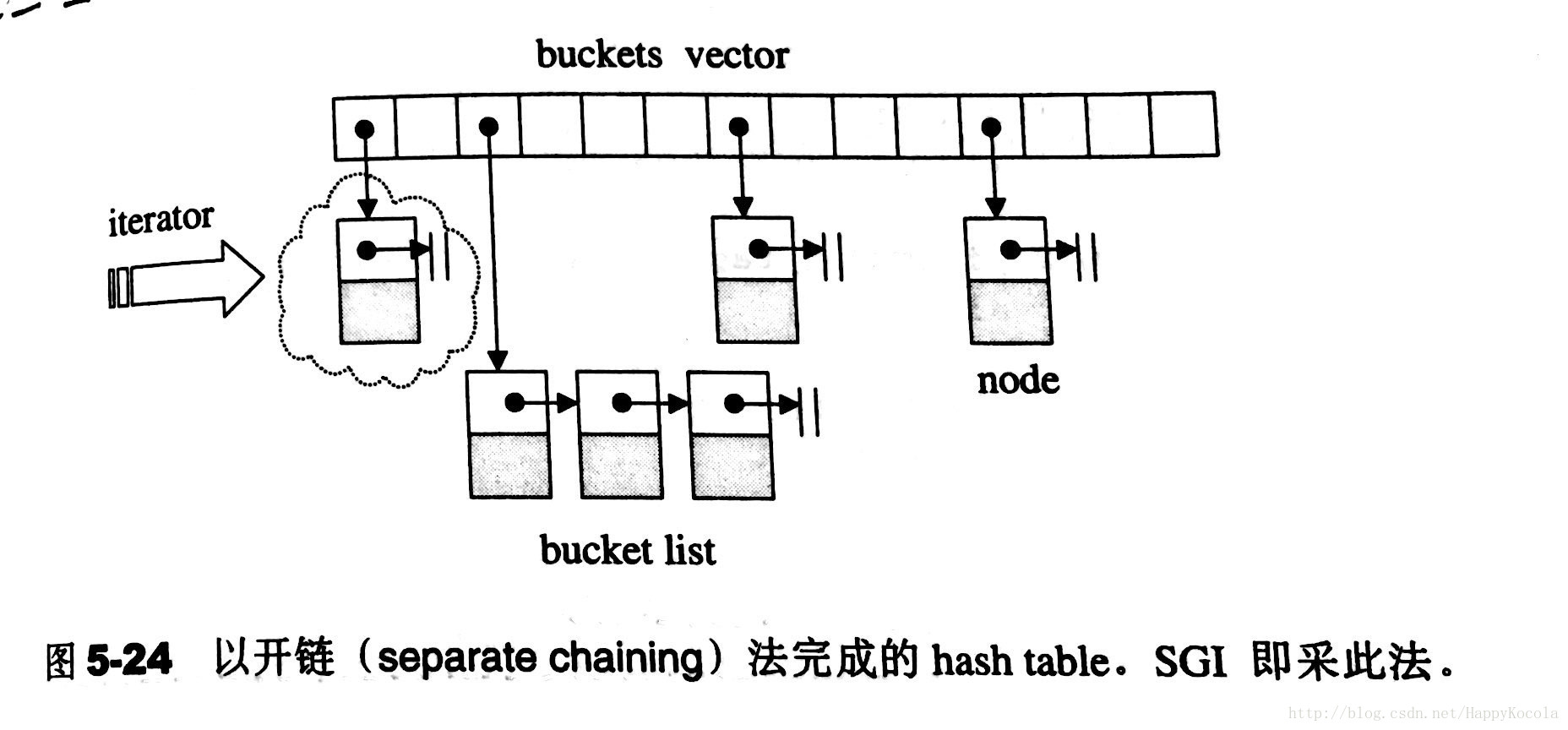
hash_map VS unordered_map
hash_map,unordered_map本质是一样的,只不过 unordered_map被纳入了C++标准库标准:
hash_map,标准库的不同实现者将提供一个通常名为hash_map的非标准散列表。因为这些实现不是遵循标准编写的,所以它们在功能和性能保证上都有微妙的差别。unordered_map,以防止与这些非标准实现的冲突,并防止在其代码中有hash_table的开发人员无意中使用新类。unordered_map更具描述性,因为它暗示了类的映射接口和其元素的无序性质。map不允许相同key值存在,multimap则允许相同的key值存在。
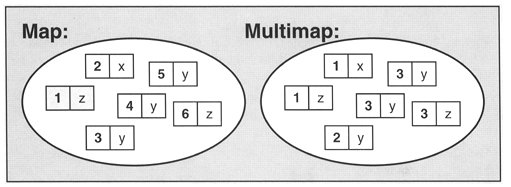
| 特性 | map | unordered_map |
|---|---|---|
| 元素排序 | 严格弱序 | 无 |
| 常见实现 | 平衡树或红黑树 | 哈希表 |
| 查找时间 | O(log(n)) | 平均 O(1),最坏 O(n)(哈希冲突) |
| 插入时间 | O(log(n)) + 重新平衡 | 同查找时间 |
| 删除时间 | O(log(n)) + 重新平衡 | 同查找时间 |
| 需要比较器 | 只需 < 运算符 |
只需 == 运算符 |
| 需要哈希函数 | 不需要 | 需要 |
| 常见用例 | 当无法提供良好哈希函数或哈希 | 在大多数其他情况下。当顺序不重要时 |
| 函数太慢,或者需要有序时 |
自己实现的map需要自己去new一些节点,当节点特别多, 而且进行频繁的删除和插入的时候,内存碎片就会存在,而STL采用自己的Allocator分配内存,以内存池的方式来管理这些内存,会大大减少内存碎片,从而会提升系统的整体性能。
注意到很多代码使用 std::unordered_map 因为“哈希表更快”。但是对于小map,具有很高的内存开销。
网上有许多map和unorderd_map的比较,但是都是大例子。
下载一个,比较N比较小时的速度。前面是插入,后面是读取时间。编译g++ -std=c++11 -O3 map.cpp -o main
map的value是int,默认为0。可以直接++
#include <map>
#include <unordered_map>
//c++11以上
map<string,int> m3 = {
{"string",1}, {"sec",2}, {"trd",3}
};
map<string,string> m4 = {
{"first","second"}, {"third","fourth"},
{"fifth","sixth"}, {"begin","end"}
};
operator[]为不存在键,构造默认值
比如对于std::map<std::string, int> m; m["apple"]++;
m["apple"]++ 会首先检查 apple 是否存在于容器中。在 C++ 中,map 和 unordered_map 容器的默认值取决于它们存储的值类型的默认构造方式。具体来说:
int, long 等),默认值是 0。对于浮点型(如 float, double 等),默认值是 0.0。
指针类型:
指针类型的默认值是 nullptr。
自定义类型:
自定义类型的默认值是该类型默认构造函数构造的对象。如果没有显式定义默认构造函数,则编译器会提供一个默认的构造函数,通常将所有成员初始化为默认值。
标准库类型:
std::string),默认值是空字符串 ""。std::vector,默认值是一个空的 vector。// insert 不能覆盖元素,已经存在会失败
mapStudent.insert(map<int, string>::value_type (1, "student_one"));
// 数组方式可以覆盖
mapStudent[1] = "student_one";
用pair来获得是否insert成功,程序如下
pair<map<int, string>::iterator, bool> Insert_Pair;
Insert_Pair = mapStudent.insert(map<int, string>::value_type (1, "student_one"));
我们通过pair的第二个变量来知道是否插入成功,它的第一个变量返回的是一个map的迭代器,如果插入成功的话Insert_Pair.second应该是true的,否则为false。
//unordered_map 类模板中,还提供有 at() 成员方法,和使用 [ ] 运算符一样,at() 成员方法也需要根据指定的键,才能从容器中找到该键对应的值;
//不同之处在于,如果在当前容器中查找失败,该方法不会向容器中添加新的键值对([]会插入默认值),而是直接抛出out_of_range异常。
cnt.at(num)
// c++17 支持
for (auto &[num, c] : cnt) {
}
for (auto &[x, _] : cnt) {
//sth
}
// 否则
for (auto it = cnt.begin(); it != cnt.end(); ++it) {
auto& key = it->first;
auto& value = it->second;
// 使用 key 和 i 进行操作
}
通过 find() 方法得到的是一个正向迭代器,有 2 种情况:
常用于 一个值是否存在 的相关问题
set(关键字即值,即只保存关键字的容器);使用红黑树,自动排序,关键字唯一。multiset(关键字可重复出现的set);unordered_set(用哈希函数组织的set);unordered_multiset(哈希组织的set,关键字可以重复出现)。map和set都是C++的关联容器,其底层实现都是红黑树(RB-Tree)。由于 map 和set所开放的各种操作接口,RB-tree 也都提供了,所以几乎所有的 map 和set的操作行为,都只是转调 RB-tree 的操作行为。
map和set区别在于:
[ ]将关键码作为下标去执行查找,如果关键码不存在,则插入一个具有该关键码和mapped_type类型默认值的元素至map中,因此下标运算符[ ]在map应用中需要慎用,默认红黑树,使用std::less 作为比较器, 升序序列。
| 存放数据类型 | 排序规则 |
|---|---|
| 整数、浮点数等 | 按从小到大的顺序排列 |
| 字符串 | 按字母表顺序排列 |
| 指针 | 按地址升序排列 |
| 指向某元素的指针 | 按指针地址递增的顺序排列 |
| 类(自定义) | 可以自定义排序规则 |
// 自定义比较器,按降序排列
struct Greater {
bool operator()(const int& a, const int& b) const {
return a > b;
}
};
std::set<int, Greater> s = {5, 3, 8, 1, 4};
template < class T, // set::key_type/value_type
class Compare = less<T>, // set::key_compare/value_compare
class Alloc = allocator<T> // set::allocator_type
> class set;
//初始化
set<char> vowel {'a','e','i','o','u'};
template <class T, class Compare, class Alloc>
bool operator== ( const set<T,Compare,Alloc>& lhs,
const set<T,Compare,Alloc>& rhs ); // 和map类似的,重载相等判断
auto hash_p = [](const pair<int, int> &p) -> size_t {
static hash<long long> hash_ll;
return hash_ll(p.first + (static_cast<long long>(p.second) << 32));
};
unordered_set<pair<int, int>, decltype(hash_p)> points(0, hash_p); //(0,hash_p)分别为迭代器的开始和结束的标记(数组多为数据源)
//多用于数组 set<int> iset(arr,arr+sizeof(arr)/sizeof(*arr));
类似的例子1
auto hash = [](const std::pair<int, int>& p){ return p.first * 31 + p.second; };
std::unordered_set<std::pair<int, int>, decltype(hash)> u_edge_(8, hash);
上面的不是用lambda expression隐函数,而是定义函数的写法
//增改
insert()–在集合中插入元素
emplace() 最大的作用是避免产生不必要的临时变量
erase()–删除集合中的元素
//删除 set 容器中值为 val 的元素
//第 1 种格式的 erase() 方法,其返回值为一个整数,表示成功删除的元素个数;
size_type erase (const value_type& val);
//删除 position 迭代器指向的元素
//后 2 种格式的 erase() 方法,返回值都是迭代器,其指向的是 set 容器中删除元素之后的第一个元素。
iterator erase (const_iterator position);
//删除 [first,last) 区间内的所有元素
iterator erase (const_iterator first, const_iterator last);
clear()–删除集合中所有元素
//查询
find()–返回一个指向被查找到元素的迭代器。返回值:该函数返回一个迭代器,该迭代器指向在集合容器中搜索的元素。如果找不到该元素,则迭代器将指向集合中最后一个元素之后的位置end
count()- 查找的bool结果
size()–集合中元素的数目
swap()–交换两个集合变量
并查集的基本操作
UnionFind(int n):每个元素初始化为自己的父节点。int find(int x):查找某个元素的根节点,并进行路径压缩以优化后续查找。int find(int x):将两个元素所在的集合合并为一个集合。核心是
#include <iostream>
#include <vector>
using namespace std;
class UnionFind {
public:
vector<int> parent;
vector<int> rank;
UnionFind(int n) {
parent.resize(n);
rank.resize(n, 0);
for (int i = 0; i < n; ++i) {
parent[i] = i;
}
}
int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]); // 路径压缩
}
return parent[x];
}
void unite(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX != rootY) {
if (rank[rootX] < rank[rootY]) {
parent[rootX] = rootY;
} else if (rank[rootX] > rank[rootY]) {
parent[rootY] = rootX;
} else {
parent[rootY] = rootX;
rank[rootX]++;
}
}
}
bool connected(int x, int y) {
return find(x) == find(y);
}
};
int main() {
int n = 5;
UnionFind uf(n);
uf.unite(0, 1);
uf.unite(1, 2);
uf.unite(3, 4);
cout << "Is 0 and 2 connected? " << (uf.connected(0, 2) ? "Yes" : "No") << endl; // Yes
cout << "Is 0 and 3 connected? " << (uf.connected(0, 3) ? "Yes" : "No") << endl; // No
return 0;
}
#include <iostream>
#include <map>
using namespace std;
class UnionFind {
public:
map<int, int> parent;
map<int, int> rank;
// 初始化
void makeSet(int x) {
parent[x] = x;
rank[x] = 0;
}
// 查找根节点,并进行路径压缩
int find(int x) {
if (parent.find(x) == parent.end()) {
makeSet(x); // 如果 x 不存在,先初始化
}
if (parent[x] != x) {
parent[x] = find(parent[x]); // 路径压缩
}
return parent[x];
}
// 合并两个集合
void unite(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX != rootY) {
if (rank[rootX] < rank[rootY]) {
parent[rootX] = rootY;
} else if (rank[rootX] > rank[rootY]) {
parent[rootY] = rootX;
} else {
parent[rootY] = rootX;
rank[rootX]++;
}
}
}
// 判断两个元素是否在同一个集合中
bool connected(int x, int y) {
return find(x) == find(y);
}
};
int main() {
UnionFind uf;
// 初始化一些元素
uf.makeSet(1);
uf.makeSet(2);
uf.makeSet(3);
uf.makeSet(4);
uf.makeSet(5);
// 合并一些集合
uf.unite(1, 2);
uf.unite(2, 3);
uf.unite(4, 5);
// 查询
cout << "Is 1 and 3 connected? " << (uf.connected(1, 3) ? "Yes" : "No") << endl; // Yes
cout << "Is 1 and 4 connected? " << (uf.connected(1, 4) ? "Yes" : "No") << endl; // No
// 动态添加新元素并合并
uf.unite(6, 7);
cout << "Is 6 and 7 connected? " << (uf.connected(6, 7) ? "Yes" : "No") << endl; // Yes
return 0;
}
C++ 中的容器适配器 stack、queue 和 priority_queue 依赖不同的基础容器来实现特定的数据结构行为。每种容器适配器都有特定的成员函数要求,默认选择的基础容器是为了更好地满足这些要求。
| 容器适配器 | 基础容器筛选条件 | 默认使用的基础容器 |
|---|---|---|
| stack | 基础容器需包含以下成员函数: | deque |
- empty() |
||
- size() |
||
- back() |
||
- push_back() |
||
- pop_back() |
||
满足条件的基础容器有 vector、deque、list。 |
||
| queue | 基础容器需包含以下成员函数: | deque |
- empty() |
||
- size() |
||
- front() |
||
- back() |
||
- push_back() |
||
- pop_front() |
||
满足条件的基础容器有 deque、list。 |
||
| priority_queue | 基础容器需包含以下成员函数: | vector |
- empty() |
||
- size() |
||
- front() |
||
- push_back() |
||
- pop_back() |
||
满足条件的基础容器有 vector、deque。 |
堆栈,先进先出
stack<int> minStack;
minStack = stack<int>();
// 支持初始化,但是注意将整个数组元素推入堆栈,堆栈的顶部元素top将是数组的第一个元素。
std::vector<int> elements = {1, 2, 3, 4, 5};
std::stack<int> myStack(elements.begin(), elements.end());
//增
s.push(x); // 复制 x 到栈中
std::stack<std::pair<int, int>> s;
s.emplace(1, 2); // 在栈中直接构造 std::pair<int, int> (1, 2)
//删
minStack.pop(); //该函数仅用于从堆栈中删除元素,并且没有返回值。因此,我们可以说该函数的返回类型为void。
//改
//查
!minStack.empty()
top_value = minStack.top();
stIn.size() //该函数返回堆栈容器的大小,该大小是堆栈中存储的元素数量的度量。
push() adds a copy of an already constructed object into the queue as a parameter.
emplace() constructs a new object in-place at the end of the queue.
If your usage pattern is one where you create a new object and add it to the container, you shortcut a few steps(creation of a temporary object and copying it) by using emplace().
注意pop仅用于从堆栈中删除元素,并且没有返回值, 一般用法如下
stack不支持clear, 除开一个个pop
#include <queue>
// 初始化
queue<int> q;
// 相对于stack的操作, 没有top(), 但新增
q.front() 返回队首元素的值,但不删除该元素
q.back() 返回队列尾元素的值,但不删除该元素
直接用空的队列对象赋值
使用swap,这种是最高效的,定义clear,保持STL容器的标准。
deque 容器也擅长在序列尾部添加或删除元素(时间复杂度为O(1)),而不擅长在序列中间添加或删除元素。
#include <deque>
using namespace std;
std::deque<int> d;
//相对于stack queue支持迭代器,前两者可以强制通过reinterpret_cast来使用迭代器
begin() 返回指向容器中第一个元素的迭代器。
end() 返回指向容器最后一个元素所在位置后一个位置的迭代器,通常和 begin() 结合使用。
rbegin() 返回指向最后一个元素的迭代器。
rend() 返回指向第一个元素所在位置前一个位置的迭代器。
cbegin() 和 begin() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。
cend() 和 end() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。
crbegin() 和 rbegin() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。
crend() 和 rend() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。
size() 返回实际元素个数。
max_size() 返回容器所能容纳元素个数的最大值。这通常是一个很大的值,一般是 232-1,我们很少会用到这个函数。
resize() 改变实际元素的个数。
empty() 判断容器中是否有元素,若无元素,则返回 true;反之,返回 false。
shrink _to_fit() 将内存减少到等于当前元素实际所使用的大小。
at() 使用经过边界检查的索引访问元素。
front() 返回第一个元素的引用。
back() 返回最后一个元素的引用。
assign() 用新元素替换原有内容。
push_back() 在序列的尾部添加一个元素。
push_front() 在序列的头部添加一个元素。
pop_back() 移除容器尾部的元素。
pop_front() 移除容器头部的元素。
insert() 在指定的位置插入一个或多个元素。
erase() 移除一个元素或一段元素。
clear() 移出所有的元素,容器大小变为 0。
swap() 交换两个容器的所有元素。
emplace() 在指定的位置直接生成一个元素。
emplace_front() 在容器头部生成一个元素。和 push_front() 的区别是,该函数直接在容器头部构造元素,省去了复制移动元素的过程。
emplace_back() 在容器尾部生成一个元素。和 push_back() 的区别是,该函数直接在容器尾部构造元素,省去了复制移动元素的过程。
// 但是对于原始数据需要提供类型
vec.emplace_back<std::array<int, 4>>({1,2,3,4});
// or
vec.emplace_back(std::array<int, 4>{{1, 2, 3, 4}});
//降序队列(默认less<>), map/set默认也是使用less,但是是升序序列
priority_queue <int>q;
priority_queue <int,vector<int>,less<int> >q;
//升序队列
priority_queue <int,vector<int>,greater<int> > q;
自定义降序1 : class & struct
class _c{
public:
bool operator () (const pair<int, int> &p, const pair<int, int> &q) const {
return p.first < q.first;
}
};
priority_queue<pair<int, int>, vector<pair<int, int>>, _c> pq;
struct Compare {
bool operator()(const std::pair<TimeType, ipType>& a, const std::pair<TimeType, ipType>& b) const {
if (a.first == b.first)
return a.second < b.second; // 第一元素相等时按第二元素降序
return a.first > b.first; // 第一元素按升序排列
}
};
class MyClass {
public:
std::priority_queue<std::pair<TimeType, ipType>, std::vector<std::pair<TimeType, ipType>>, Compare> _arpQueue;
};
自定义降序2 : decltype
class MyClass {
public:
// 比较函数作为静态成员函数
static bool cmp(const std::pair<TimeType, ipType>& a, const std::pair<TimeType, ipType>& b) {
if (a.first == b.first)
return a.second < b.second; // 第一元素相等时按第二元素降序
return a.first > b.first; // 第一元素按升序排列
}
// 使用比较函数指针初始化优先队列
std::priority_queue<std::pair<TimeType, ipType>, std::vector<std::pair<TimeType, ipType>>, decltype(&MyClass::cmp)> _arpQueue{cmp};
};
一般是题目要求自己实现链表,而不是使用STL提供的链表list。
// 单链表
struct ListNode {
int val; // 节点上存储的元素
ListNode *next; // 指向下一个节点的指针
ListNode(int x) : val(x), next(NULL) {} // 节点的构造函数
};
ListNode* head = new ListNode(5);
//或者
ListNode* head = new ListNode();
head->val = 5;
while(result != nullptr && result->val == val){
ListNode* tmp_free = result;
result = result->next;
delete tmp_free; // 注意释放空间
}
nullptr是一个关键字,可以在所有期望为NULL的地方使用。
STL list 容器,又称双向链表容器,即该容器的底层是以双向链表的形式实现的。
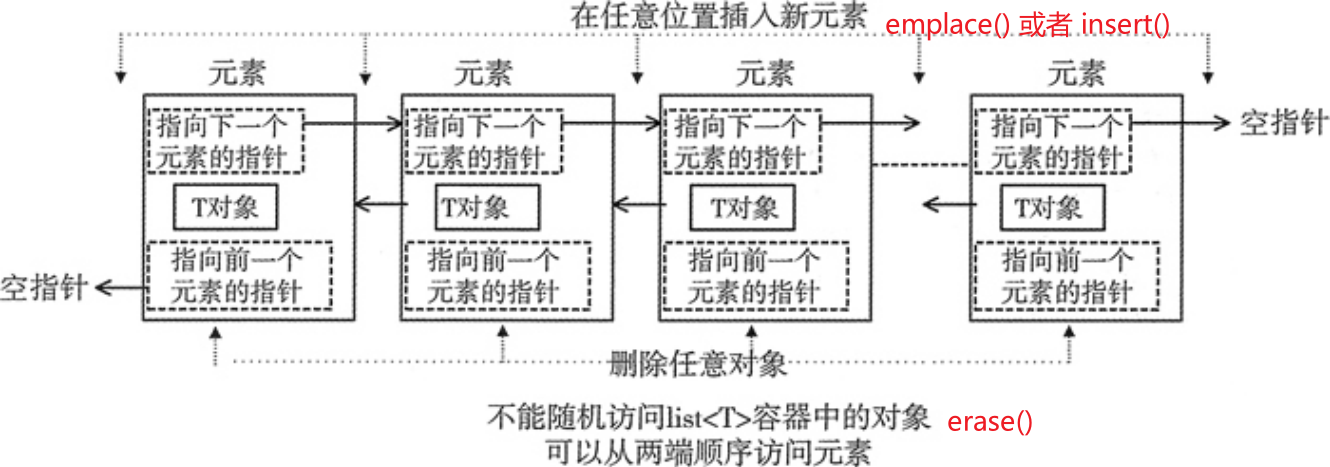
find()语法,经常使用unorder_map<key, list<xxx>::iterator> listMap保存元素位置来加速查找。for (it = list.begin(); it != list.end(); it++) if (it->key == key) break;//插入
push_front:在链表头部插入元素。
emplace_front(value_type&& val)
push_back:在链表尾部插入元素。
emplace_back(value_type&& val)
insert:在指定位置插入元素。list1.insert(list1.begin(), 0);
emplace(iterator pos, value_type val)
//删除
pop_front:删除链表头部的元素。
pop_back:删除链表尾部的元素。
erase:删除指定位置的元素。
remove:删除所有匹配的元素。
clear:清空链表。
//查询
size:返回链表的大小。
empty:检查链表是否为空。
front:返回链表的第一个元素。
back:返回链表的最后一个元素。
reverse:反转链表。
sort:对链表进行排序。
数组 int a[1000] = {0}; 的分配位置
在 C/C++ 中,数组 int a[1000] = {0}; 的分配位置取决于它的声明位置。具体来说:
static 类型,那么它会被分配在栈上。栈上的内存分配速度快,但栈的大小有限,通常为几 MB 到几十 MB,具体取决于操作系统和编译器设置。
静态区(Static):
static 类型,那么它会被分配在静态区。静态区的内存分配在程序启动时完成,持续到程序结束,不会在每次函数调用时重新分配。
堆上(Heap):
malloc、calloc、new 等)分配的,那么它会被分配在堆上。总结
static 数组。static 数组。malloc、calloc、new)分配的数组。//直接初始化为0
int a[SIZE]={0};
#include<string.h>
int a[SIZE];
memset(a, 0, sizeof(a));
memset(a, 0, sizeof(int)*1000);//这里的1000是数组大小,需要多少替换下就可以了。
注意 memset是按照字节进行赋值,即对每一个字节赋相同值。除开0和-1,其他值都是不安全的,不会赋值期望的值。比如int是四个字节。
memset(a,127,sizeof(a)),全部初始化为int的较大值,即2139062143(int 最大值为2147483647);memset(a,128,sizeof(a)),全部初始化为一个很小的数,比int最小值略大,为-2139062144。//区分
//calloc() 函数是动态申请内存函数之一,相当于用malloc函数申请并且初始化一样,calloc函数会将申请的内存全部初始化为0。
int *res = (int*)calloc(numsSize, sizeof(int));
//方法二:
int *res = (int*)malloc(numsSize * sizeof(int));
memset(res, 0, numsSize * sizeof(int));
//错误写法: memset(res, 0, sizeof(res)); res是指针变量,不管 res 指向什么类型的变量,sizeof( res ) 的值都是 4。
int *p = new int();//此时p指向内存的单变量被初始化为0
int *p = new int (5);//此时p指向内存的单变量被初始化为5
int *p = new int[100]()//此时p指向数组首元素,且数组元素被初始化为0
//c++11 允许列表初始化,因此也有了以下几种形式形式
int *p = new int{}//p指向的单变量被初始化为0
int *p = new int{8}//p指向变量被初始化为8
int *p = new int[100]{}//p指向的数组被初始化为0
int *p = new int[100]{1,2,3}//p指向数组的前三个元素被初始化为1,2,3,后边97个元素初始化为0;
建议老实用vector
int ***array;
// 假定数组第一维为 m, 第二维为 n, 第三维为h
// 动态分配空间
array = new int **[m];
for( int i=0; i<m; i++ )
{
array[i] = new int *[n];
for( int j=0; j<n; j++ )
{
array[i][j] = new int [h];
}
}
//释放
for( int i=0; i<m; i++ )
{
for( int j=0; j<n; j++ )
{
delete[] array[i][j];
}
delete[] array[i];
}
delete[] array;
Leetcode support VLA
#include <array>
// array<typeName, nElem> arr;
array<int, 5> ai;
array<double, 4> ad = {1.1,1.2,1.2,1.3};
//通过如下创建 array 容器的方式,可以将所有的元素初始化为 0 或者和默认元素类型等效的值:
std::array<double, 10> values {};
//使用该语句,容器中所有的元素都会被初始化为 0.0。
//二维
std::array<std::array<int, 2>, 3> m = { {1, 2}, {3, 4}, {5, 6} };

vector是变长的连续存储:
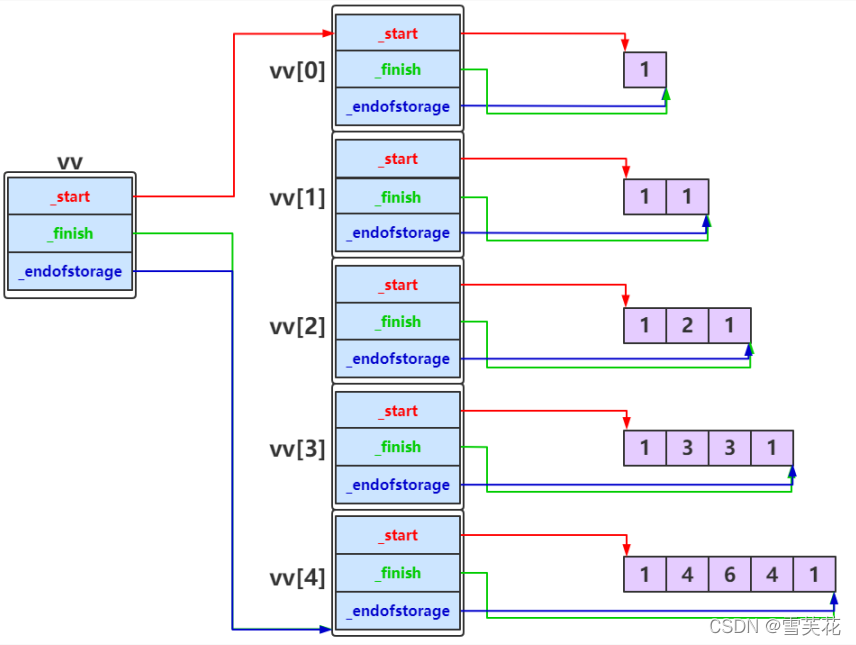
vector<vector<int>> v2d(3,vector<int>(0)); // 间隔 6 个int
// vector<set<int>> v2d(3); // 间隔 12 个int
// vector<unordered_set<int>> v2d(3); // 间隔 14 个int
// vector<map<int,int>> v2d(3); // 间隔 12 个int
// vector<unordered_map<int,int>> v2d(3); // 间隔 14 个int
const int STEP = 6;
for(int i = 0; i<v2d.size(); i++){
cout << " " << &v2d[i] << endl;
for(int j=0; j<STEP; j++)
cout << " " << hex << *(int *)((void *)(&v2d[i])+j*4);
cout << endl;
}
// add elements to v2d[0]
const int ADDNUM = 10;
for(int i = 0; i<ADDNUM; i++){
v2d[0].emplace_back(2);
// v2d[0].insert(i);
// v2d[0][i]=i*i;
}
// check the space change
cout << "Ele[0] size : " << v2d[0].size() << endl;
for(int i = 0; i<v2d.size(); i++){
cout << " " << &v2d[i] << endl;
}
//check ele[0] location
cout << endl;
for(int i = 0; i<ADDNUM; i++){
cout << " " << &v2d[0][i];
}
vector具体底层实现
(1)扩容
vector的底层数据结构是数组。
当vector中的可用空间耗尽时,就要动态第扩大内部数组的容量。直接在原有物理空间的基础上追加空间?这不现实。数组特定的地址方式要求,物理空间必须地址连续,而我们无法保证其尾部总是预留了足够空间可供拓展。一种方法是,申请一个容量更大的数组,并将原数组中的成员都搬迁至新空间,再在其后方进行插入操作。新数组的地址由OS分配,与原数据区没有直接的关系。新数组的容量总是取作原数组的两倍。
(2)插入和删除
插入给定值的过程是,先找到要插入的位置,然后将这个位置(包括这个位置)的元素向后整体移动一位,然后将该位置的元素复制为给定值。删除过程则是将该位置以后的所有元素整体前移一位。
(2)vector的size和capacity
size指vector容器当前拥有的元素个数,capacity指容器在必须分配新存储空间之前可以存储的元素总数,capacity总是大于或等于size的。
size() – 返回目前存在的元素数。即: 元素个数
capacity() – 返回容器能存储 数据的个数。 即:容器容量
reserve() --设置 capacity 大小
resize() --设置 size ,重新指定有效元素的个数 ,区别与reserve()指定 容量的大小
clear() --清空所有元素,把size设置成0,capacity不变
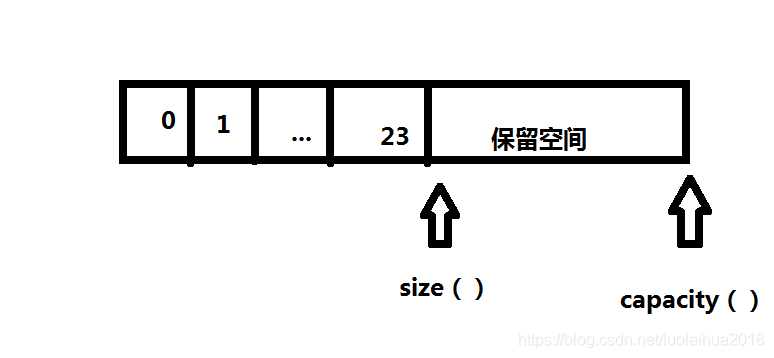
针对capacity这个属性,STL中的其他容器,如list map set deque,由于这些容器的内存是散列分布的,因此不会发生类似realloc()的调用情况,因此我们可以认为capacity属性针对这些容器是没有意义的,因此设计时这些容器没有该属性。
在STL中,拥有capacity属性的容器只有vector和string。
共同点
(1.)都和数组相似,都可以使用标准数组的表示方法来访问每个元素(array和vector都对下标运算符[ ]进行了重载)
(2.)三者的存储都是连续的,可以进行随机访问
不同点
(0.)数组是不安全的,array和vector是比较安全的(有效的避免越界等问题)
(1.)array对象和数组存储在相同的内存区域(栈)中,vector对象存储在自由存储区(堆)malloc和new的空间也是在堆上,原因是栈的空间在编译代码的时候就要确定好,堆空间可以运行时分配。
(2.)array可以将一个对象赋值给另一个array对象,但是数组不行
(3.)vector属于变长的容器,即可以根据数据的插入和删除重新构造容器容量;但是array和数组属于定长容器
(4.)vector和array提供了更好的数据访问机制,即可以使用front()和back()以及at()(at()可以避免a[-1]访问越界的问题)访问方式,使得访问更加安全。而数组只能通过下标访问,在写程序中很容易出现越界的错误
(5.)vector和array提供了更好的遍历机制,即有正向迭代器和反向迭代器
(6.)vector和array提供了size()和Empty(),而数组只能通过sizeof()/strlen()以及遍历计数来获取大小和是否为空
(7.)vector和array提供了两个容器对象的内容交换,即swap()的机制,而数组对于交换只能通过遍历的方式逐个交换元素
(8.)array提供了初始化所有成员的方法fill()
(9.)由于vector的动态内存变化的机制,在插入和删除时,需要考虑迭代的是否有效问题
(10.)vector和array在声明变量后,在声明周期完成后,会自动地释放其所占用的内存。对于数组如果用new[ ]/malloc申请的空间,必须用对应的delete[ ]和free来释放内存
//创建一个vector,元素个数为nSize
vector(int nSize)
//指定值初始化,ilist5被初始化为包含7个值为3的int
//vector(int nSize,const t& t)
//创建一个vector,元素个数为nSize,且值均为t
vector<int> ilist5(7,3);
//区分列表初始化, 包含7 和 3两个元素
vector<int> ilist5{7,3};
array 与 vector 默认初始化
std::array 和 std::vector 的默认初始化:对于类类型,未显式初始化的元素会调用默认构造函数进行初始化。
未初始化:
new 或其他方式动态分配内存并且没有显式初始化,那么这些元素将包含未定义的值(即“乱码”)。//改变大小,预分配空间,增加 vector 的容量(capacity),但 size 保持不变。
vals.reserve(cnt.size());
// 将 vector 大小调整为 10,用 0 填充新位置
vec.resize(10, 0);
二维vector
// 二维vector, 两个维度的长度都未知时:
std::vector<std::vector<int>> matrix;
// 假设我们知道行数,但列数未知
int numRows = 3;
// 预先分配行数
matrix.resize(numRows);
// 动态添加列
matrix[0].push_back(1);
matrix[0].push_back(2);
matrix[1].push_back(3);
matrix[1].push_back(4);
matrix[2].push_back(5);
其余情况
//已知一个维度,第二维度为空
// vector<vector<bool>> name (xSize, vector<bool>(ySize, false));
vector<vector<int>> alphaIndexList{26, vector<int>(0)};
//或者
vector<int> alphaIndexList[26];
alphaIndexList[i].push_back(x);
//两个都不知道 ,也可以使用指针
vector<int>* todo;
todo= &alphaIndexList[i];
int n = todo->size(); // (*todo).size();
for(auto &x: *todo)
vector 也支持中间insert元素,但是性能远差于list。
void push_back(const T& x) //向量尾部增加一个元素X
void emplace_back(const T& x)
//iterator insert(iterator it,const T& x) :向量中迭代器指向元素前增加一个元素x
result.insert(result.begin()+p,x); :在result的index为p的位置插入元素
iterator insert(iterator it,int n,const T& x) :向量中迭代器指向元素前增加n个相同的元素x
iterator insert(iterator it,const_iterator first,const_iterator last):向量中迭代器指向元素前插入另一个相同类型向量的[first,last)间的数据
iterator erase(iterator it) :删除向量中迭代器指向元素
iterator erase(iterator first,iterator last):删除向量中[first,last)中元素
void pop_back() :删除向量中最后一个元素
void clear() :清空向量中所有元素
void swap(vector&) :交换两个同类型向量的数据
void assign(int n,const T& x) :设置向量中前n个元素的值为x
void assign(const_iterator first,const_iterator last):向量中[first,last)中元素设置成当前向量元素
#include <algorithm> //或者#include <bits/stdc++.h>
reverse(a.begin(), a.end());
std::reverse(a,a+5); //转换0~5下标的元素
元素排序
如果需要元素有序,考虑stable_sort
#include <algorithm> // 包含 sort 函数
#include <functional> // 包含 std::greater 比较器
//默认是从低到高,加入std::greater<int>() 变成从高到低排序
sort(nums.begin(),nums.end(),std::greater<int>());
//vector of pair
vector<pair<int, char>> arr = {{a, 'a'}, {b, 'b'}, {c, 'c'}};
//c++11 using lambda and auto
std::sort(v.begin(), v.end(), [](auto &left, auto &right) {
return left.second < right.second;
});
// or
sort(arr.begin(), arr.end(),
[](const pair<int, char> & p1, const pair<int, char> & p2) {
return p1.first > p2.first;
}
);
//origin
struct sort_pred {
bool operator()(const std::pair<int,int> &left, const std::pair<int,int> &right) {
return left.second < right.second;
}
};
std::sort(v.begin(), v.end(), sort_pred());
vector<int> Arrs {1,2,3,4,5,6,7,8,9}; // 假设有这么个数组,要截取中间第二个元素到第四个元素:2,3,4
vector<int>::const_iterator First = Arrs.begin() + 1; // 找到第二个迭代器
vector<int>::const_iterator Second = Arrs.begin() + 3; // 找到第三个迭代器
vector<int> Arrs2(First, Second); // 将值直接初始化到Arrs2
迭代器是指可在容器对象上遍访的对象
或者assign()功能函数实现截取
assign() 功能函数是vector容器的成员函数。原型:
1:void assign(const_iterator first,const_iterator last);//两个指针,分别指向开始和结束的地方
2:void assign(size_type n,const T& x = T()); //n指要构造的vector成员的个数, x指成员的数值,他的类型必须与vector类型一致!
reference at(int pos) :返回pos位置元素的引用
reference front() :返回首元素的引用
reference back() :返回尾元素的引用
iterator begin() :返回向量头指针,指向第一个元素
iterator end() :返回向量尾指针,指向向量最后一个元素的下一个位置
reverse_iterator rbegin() :反向迭代器,指向最后一个元素
reverse_iterator rend() :反向迭代器,指向第一个元素之前的位置
// 判断函数
bool empty() const :判断向量是否为空,若为空,则向量中无元素
// 大小函数
int size() const :返回向量中元素的个数
int capacity() const :返回当前向量所能容纳的最大元素值
int max_size() const :返回最大可允许的vector元素数量值
返回表示
#include<functional>
auto hash_p = [](const pair<int, int> &p) -> size_t {
static hash<long long> hash_ll;
return hash_ll(p.first + (static_cast<long long>(p.second) << 32));//64位高低一半存储x和y
};
static_cast 用于良性类型转换,一般不会导致意外发生,风险很低。
hash <K> 模板专用的算法取决于实现,但是如果它们遵循 C++14 标准的话,需要满足一些具体的要求。这些要求如下:
https://www.runoob.com/w3cnote/cpp-vector-container-analysis.html
【C++容器】数组和vector、array三者区别和联系 https://blog.51cto.com/liangchaoxi/4056308
https://blog.csdn.net/y601500359/article/details/105297918
———————————————— 版权声明:本文为CSDN博主「stitching」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/qq_40250056/article/details/114681940
———————————————— 版权声明:本文为CSDN博主「FishBear_move_on」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/haluoluo211/article/details/80877558
———————————————— 版权声明:本文为CSDN博主「SOC罗三炮」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/luolaihua2018/article/details/109406092
———————————————— 版权声明:本文为CSDN博主「鱼思故渊」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/yusiguyuan/article/details/40950735
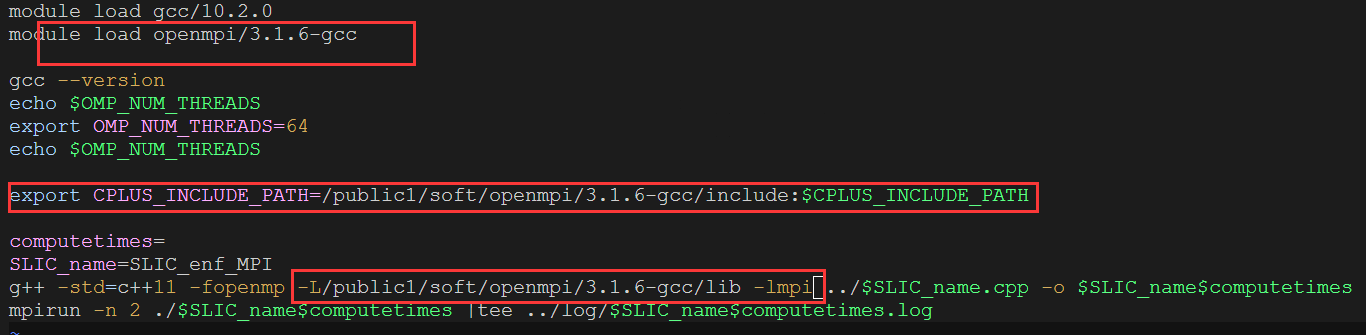
虽然MPI属于OSI参考模型的第5层和更高层,但实现可以覆盖大多数层,其中在传输层中使用套接字和传输控制协议(TCP)。
MPI hardware research focuses on implementing MPI directly in hardware, for example via processor-in-memory, building MPI operations into the microcircuitry of the RAM chips in each node. By implication, this approach is independent of language, operating system, and CPU, but cannot be readily updated or removed. MPI硬件研究的重点是直接在硬件中实现MPI,例如通过内存处理器,将MPI操作构建到每个节点中的RAM芯片的微电路中。通过暗示,这种方法独立于语言、操作系统和CPU,但是不能容易地更新或删除。
Another approach has been to add hardware acceleration to one or more parts of the operation, including hardware processing of MPI queues and using RDMA to directly transfer data between memory and the network interface controller(NIC 网卡) without CPU or OS kernel intervention. 另一种方法是将硬件加速添加到操作的一个或多个部分,包括MPI队列的硬件处理以及使用RDMA在存储器和网络接口控制器之间直接传输数据,而无需CPU或OS内核干预。
进程间通信都是Inter-process communication(IPC)的一种。常见有如下几种:
|mkfifo,具有p的文件属性线程共享存储器编程模型(如Pthreads和OpenMP)和消息传递编程(MPI/PVM)可以被认为是互补的,并且有时在具有多个大型共享存储器节点的服务器中一起使用。
后四个是MPI-2独有的
#include <unistd.h>
char hostname[100];
gethostname(hostname,sizeof(hostname));
printf( "Hello world from process %d of %d: host: %s\n", rank, size, hostname);
输出X个当前机器hostname
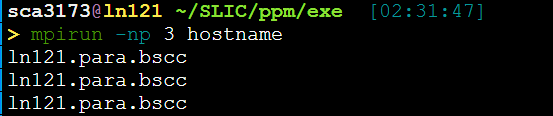
mpirun -np 6 -machinefile ./machinelist ./a.out 即可多节点执行。
MPI_Finalize()之后 ,MPI_Init()之前 https://www.open-mpi.org/doc/v4.0/man3/MPI_Init.3.php
不同的进程是怎么处理串行的部分的?都执行(重复执行?)。执行if(rank=num),那岂不是还要同步MPI_Barrier()。
而且写同一个文件怎么办?
MPI的两种最基本的并行程序设计模式 即对等模式和主从模式。
对等模式:各个部分地位相同,功能和代码基本一致,只不过是处理的数据或对象不同,也容易用同样的程序来实现。
主从模式:分为主进程和从进程,程序通信进程之间的一种主从或依赖关系 。MPI程序包括两套代码,主进程运行其中一套代码,从进程运行另一套代码。
 圈收缩(cycle shrinking)-此变换技术一般用于依赖距离大于1的循环中,它将一个串行循环分成两个紧嵌套循环,其中外层依然串行执行,而内层则是并行执行(一般粒度较小)
圈收缩(cycle shrinking)-此变换技术一般用于依赖距离大于1的循环中,它将一个串行循环分成两个紧嵌套循环,其中外层依然串行执行,而内层则是并行执行(一般粒度较小)
https://shaojiemike.notion.site/41b9f62c4b054a2bb379316f27da5836

MPI_PACKED预定义数据类型被用来实现传输地址空间不连续的数据项 。
int MPI_Pack(const void *inbuf,
int incount,
MPI_Datatype datatype, void *outbuf, int outsize, int *position, MPI_Comm comm)
int MPI_Unpack(const void *inbuf, int insize, int *position,
void *outbuf, int outcount, MPI_Datatype datatype, MPI_Comm comm)
 The input value of position is the first location in the output buffer to be used for packing. position is incremented by the size of the packed message,
The input value of position is the first location in the output buffer to be used for packing. position is incremented by the size of the packed message,
and the output value of position is the first location in the output buffer following the locations occupied by the packed message. The comm argument is the communicator that will be subsequently used for sending the packed message.
//Returns the upper bound on the amount of space needed to pack a message
int MPI_Pack_size(int incount, MPI_Datatype datatype, MPI_Comm comm, int *size)
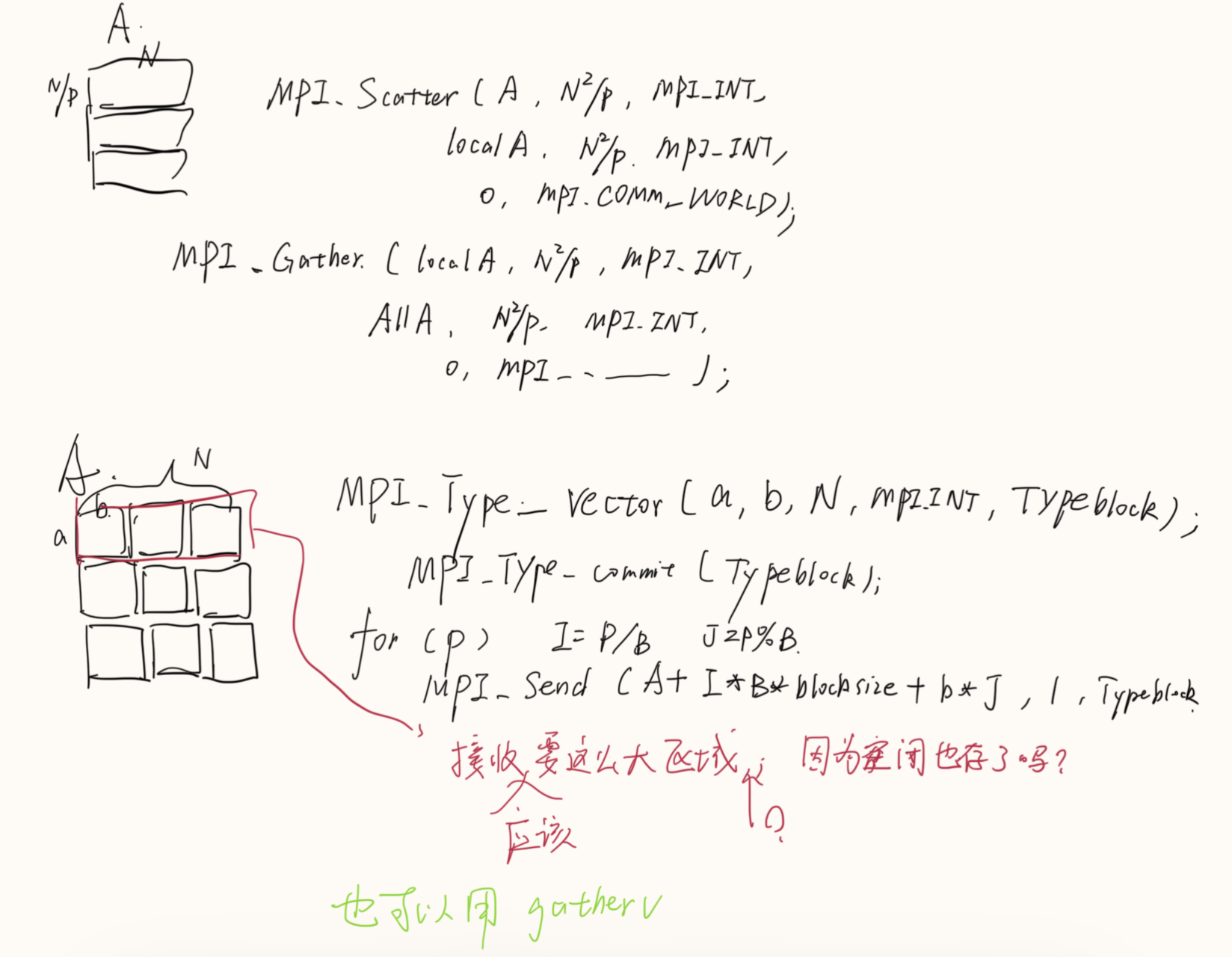
 例子:
例子:
 这里的
这里的A+i*j应该写成A+i*2吧???
来定义由数据类型不同且地址空间不连续的数据项组成的消息。

//启用与弃用数据类型
int MPI_Type_commit(MPI_Datatype * datatype)
int MPI_Type_free(MPI_Datatype * datatype)
//相同数据类型
int MPI_Type_contiguous(int count, MPI_Datatype oldtype, MPI_Datatype * newtype)
//成块的相同元素组成的类型,块之间具有相同间隔
int MPI_Type_vector(int count,
int blocklength, int stride, MPI_Datatype oldtype, MPI_Datatype * newtype)

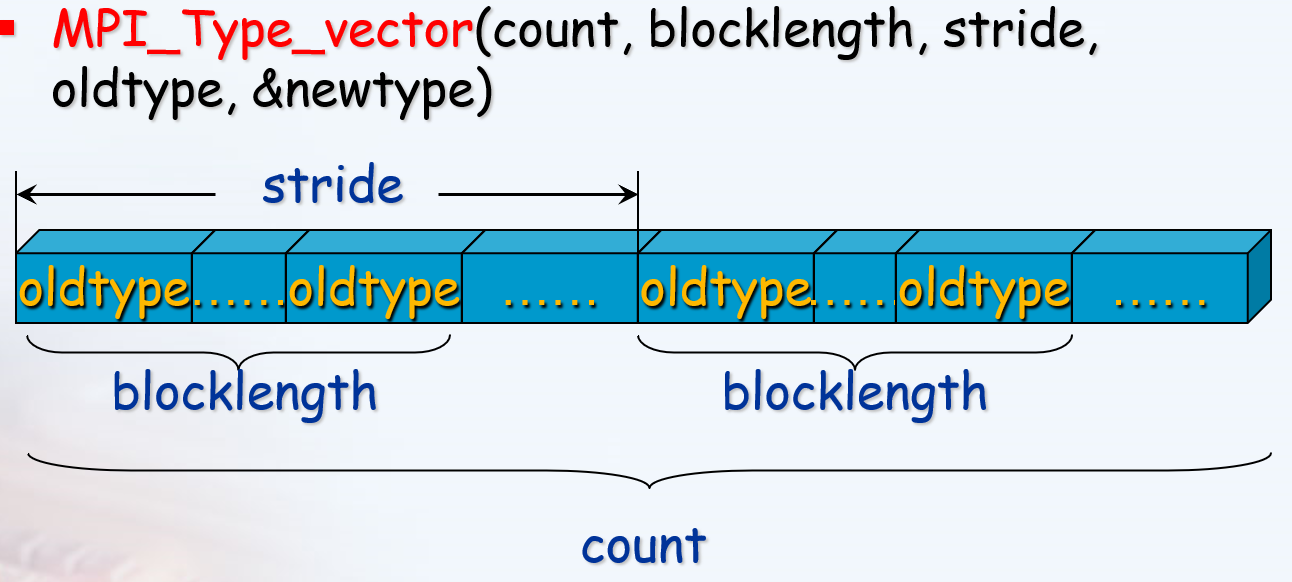
//成块的相同元素组成的类型,块长度和偏移由参数指定
int MPI_Type_indexed(int count,
const int *array_of_blocklengths,
const int *array_of_displacements,
MPI_Datatype oldtype, MPI_Datatype * newtype)

//由不同数据类型的元素组成的类型, 块长度和偏移(肯定也不一样)由参数指定
int MPI_Type_struct(int count,
int *array_of_blocklengths,
MPI_Aint * array_of_displacements,
MPI_Datatype * array_of_types, MPI_Datatype * newtype)

MPI_Cart_create 确定了虚拟网络每一维度的大小后,需要为这种拓扑建立通信域。组函数MPI_Cart_create可以完成此任务,其声明如下:
// Makes a new communicator to which topology拓扑 information has been attached
int MPI_Cart_create(
MPI_Comm old_comm,//旧的通信域。这个通讯域中的所有进程都要调用该函数
int dims,//网格维数 number of dimensions of cartesian grid (integer)
int* size,//长度为dims的数组,size[j]是第j维的进程数, integer array of size ndims specifying the number of processes in each dimension
int* periodic,//长度为dims的数组,如果第j维有周期性,那么periodic[j]=1,否则为0
int reorder,//进程是否能重新被编号,如果为0则进程在新的通信域中仍保留在旧通信域的标号
MPI_Comm* cart_comm//该函数返回后,此变量将指向新的笛卡尔通信域
);
int MPI_Cart_rank(MPI_Comm comm, const int coords[], int *rank)
//Determines process rank in communicator given Cartesian location
//该函数的作用是通过进程在网格中的坐标获得它的进程号
int MPI_Cart_coords(MPI_Comm comm, int rank, int maxdims, int coords[])
//Determines process coords in cartesian topology given rank in group
//该函数的作用是确定某个线程在虚拟网格中的坐标
int MPI_Comm_create(MPI_Comm comm, MPI_Group group, MPI_Comm * newcomm)
//Creates a new communicator
int MPI_Comm_split(MPI_Comm comm, int color, int key, MPI_Comm * newcomm)
将某个通信域进一步划分为几组
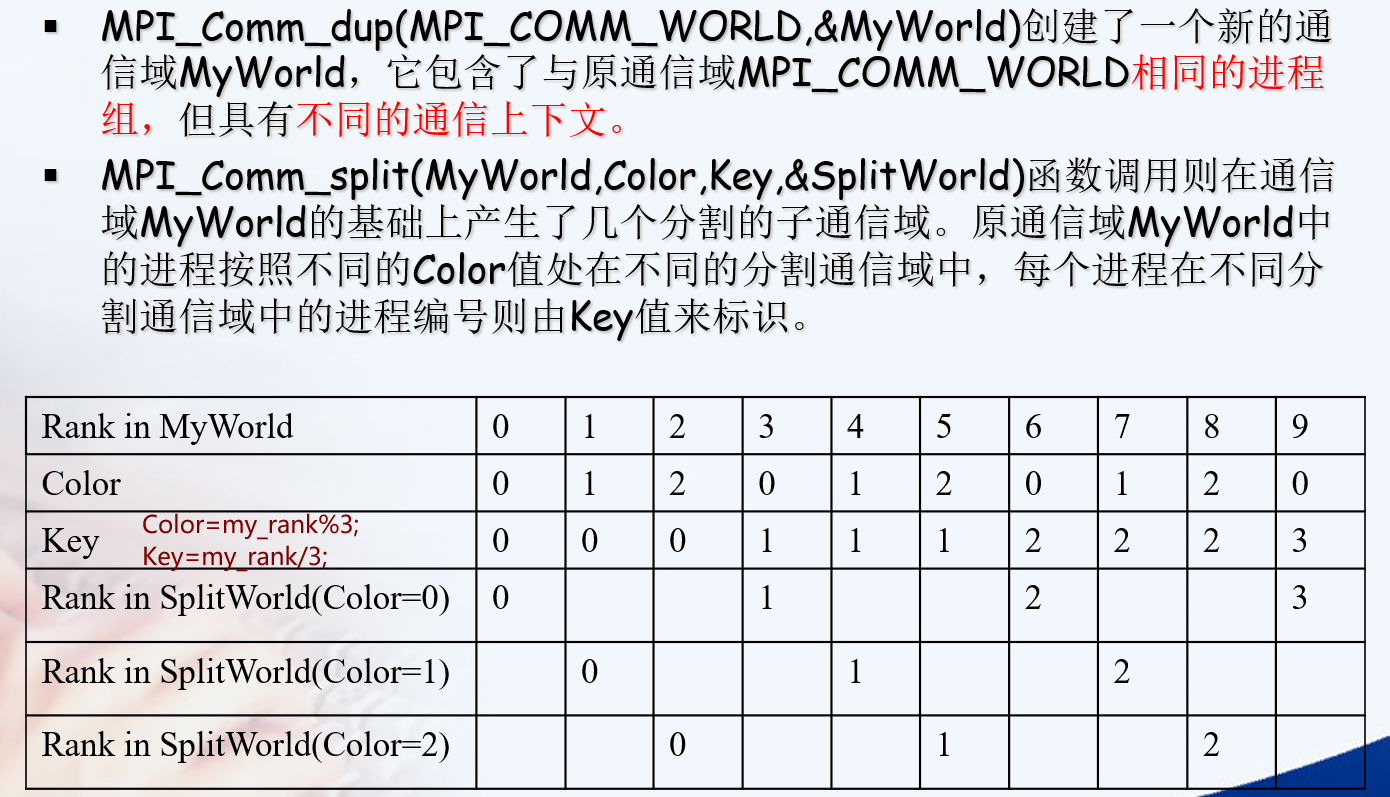
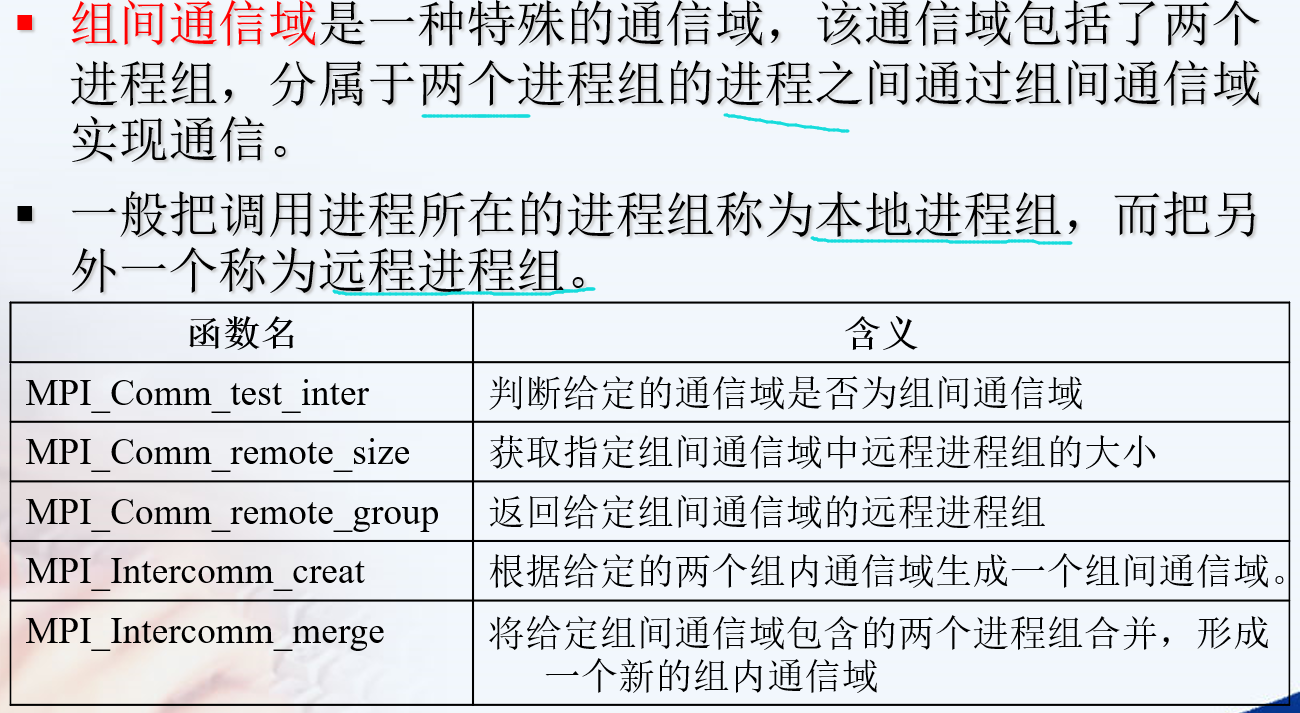
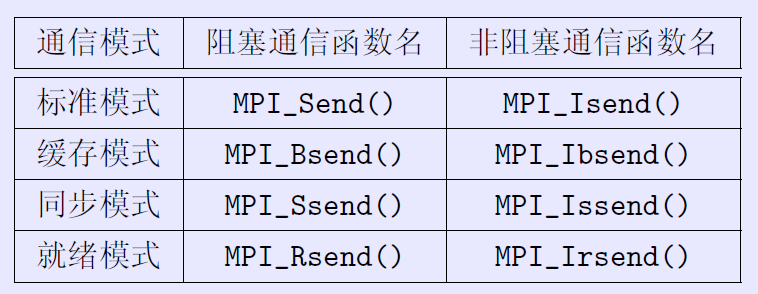
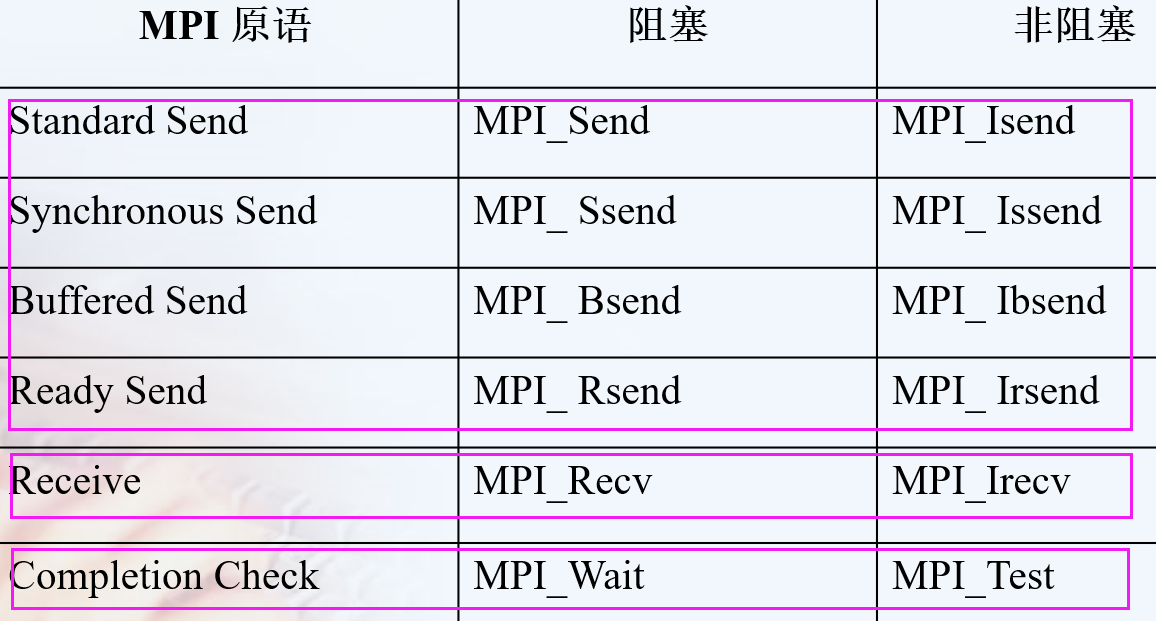 特殊的函数
特殊的函数
int MPI_Sendrecv(const void *sendbuf, int sendcount, MPI_Datatype sendtype,
int dest, int sendtag,
void *recvbuf, int recvcount, MPI_Datatype recvtype,
int source, int recvtag, MPI_Comm comm, MPI_Status * status)
int MPI_Sendrecv_replace(void *buf, int count, MPI_Datatype datatype,
int dest, int sendtag, int source, int recvtag,
MPI_Comm comm, MPI_Status * status)
There is also another error. The MPI standard requires that the send and the receive buffers be disjoint不相交 (i.e. they should not overlap重叠), which is not the case with your code. Your send and receive buffers not only overlap but they are one and the same buffer. If you want to perform the swap in the same buffer, MPI provides the MPI_Sendrecv_replace operation.
//MPI标准阻塞通信函数,没发出去就不会结束该命令。
MPI_Send(sb, buf_size, MPI_INT, other, 1, MPI_COMM_WORLD);
/*其中sb为发送缓冲区首地址,
buf_size为发送数据量,
MPI_INT 为发送数据的类型,
other为发送目标进程,(发送给other)
1的位置为tag,
MPI_COMM_WORLD为通信子*/
MPI_Recv(rb, buf_size, MPI_INT, other, 1, MPI_COMM_WORLD, &status);
/*与发送类似,从other接收消息,status见下面*/

可能大家会想到这会死锁,如下图:
但是实际情况可能并不会死锁,这与调用的MPI库的底层实现有关。

MPI_Send将阻塞,直到发送方可以重用发送方缓冲区为止。当缓冲区已发送到较低的通信层时,某些实现将返回给调用方。当另一端有匹配的MPI_Recv()时,其他一些将返回到呼叫者。
但是为了避免这种情况,可以调换Send与Recv的顺序,或者使用MPI_Isend()或MPI_Issend()代替非阻塞发送,从而避免死锁。
/*
梯形积分法,计算y=sin x 在[0,pi]上的积分
@ trap 梯形积分串行程序
@total_inte 最终积分结果
*/
#include "stdafx.h"
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <iostream>
#include<math.h>
#include "mpi.h"
using namespace std;
const double a = 0.0;
const double b = 3.1415926;
int n = 100;
double h = (b - a) / n;
double trap(double a, double b, int n, double h)
{
double*x = new double[n + 1];
double*f = new double[n + 1];
double inte = (sin(a) + sin(b)) / 2;
for (int i = 1; i<n + 1; i++) {
x[i] = x[i - 1] + h; /*x_0=a,x_n=b*/
f[i] = sin(x[i]);
inte += f[i];
}
inte = inte*h; /* inte=h*[f(a)/2+f(x_1)+...f(x_{n-1})+f(b)/2]*/
return inte;
}
int main(int argc, char * argv[])
{
int myid, nprocs;
int local_n;
double local_a;
double local_b;
double total_inte;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myid); /* get current process id */
MPI_Comm_size(MPI_COMM_WORLD, &nprocs); /* get number of processes */
local_n = n / nprocs; //任务划分
local_a = a + myid*local_n*h;
local_b = local_a + local_n*h;
double local_inte = trap(local_a, local_b, local_n, h);
if (myid != 0) //通信结果
{
MPI_Send(&local_inte, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD);
}
else
{
total_inte = local_inte;
for (int i = 1; i<nprocs; i++)
{
MPI_Recv(&local_inte, 1, MPI_DOUBLE, i, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
total_inte += local_inte;
}
}
if (myid == 0)
{
printf("integral output is %d", total_inte);
}
MPI_Finalize();
return 0;
}
一个进程组中的所有进程都参加的全局通信操作。
实现三个功能:通信、聚集和同步。 1. 通信功能主要完成组内数据的传输 2. 聚集功能在通信的基础上对给定的数据完成一定的操作 3. 同步功能实现组内所有进程在执行进度上取得一致
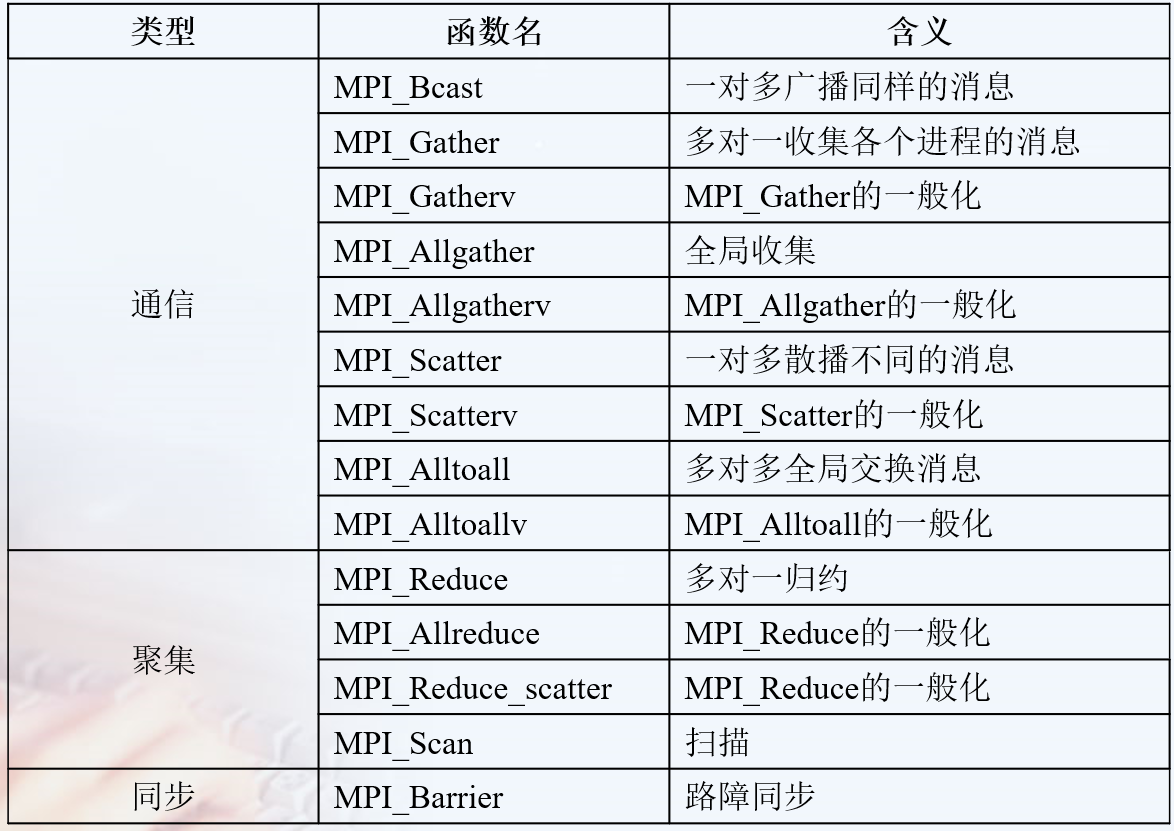
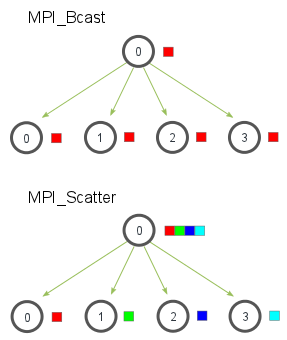
//将一个进程中得数据发送到所有进程中的广播函数
MPI_Bcast(void* data_p,int count,MPI_Datatype datatype, int scr_process,MPI_Comm comm);
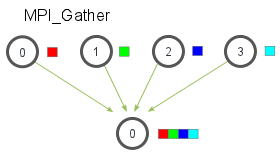
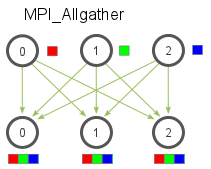
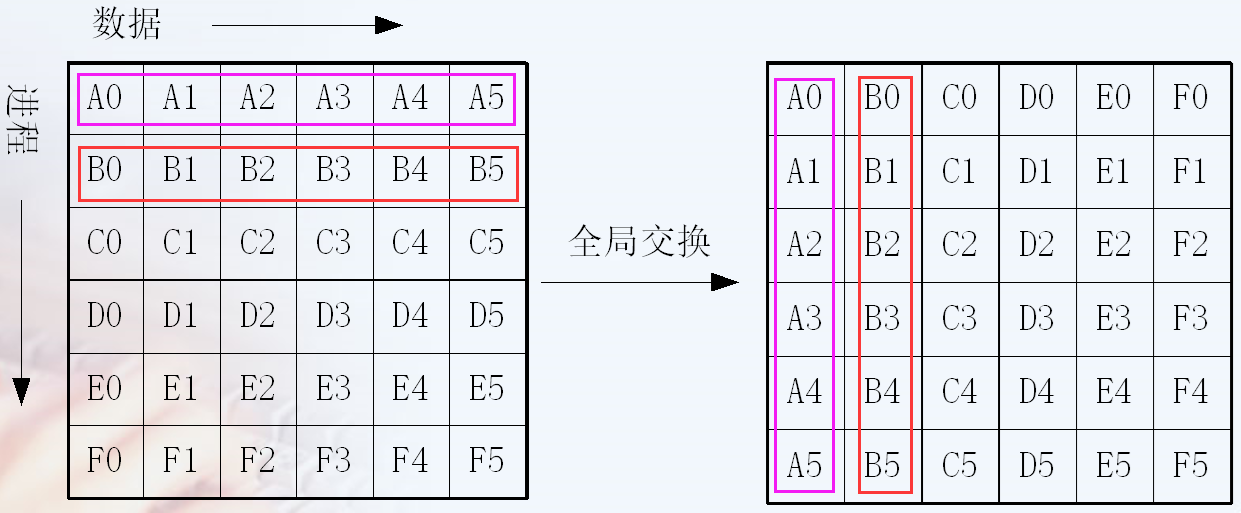
int MPI_Allgather(void * sendbuff, int sendcount, MPI_Datatype sendtype,
void * recvbuf, int recvcount, MPI_Datatype recvtype,
MPI_Comm comm)
int MPI_Allgatherv(void * sendbuff, int sendcount, MPI_Datatype sendtype,
void * recvbuf, int * recvcounts, int * displs,
MPI_Datatype recvtype, MPI_Comm comm)
number of elements received from any process (integer)

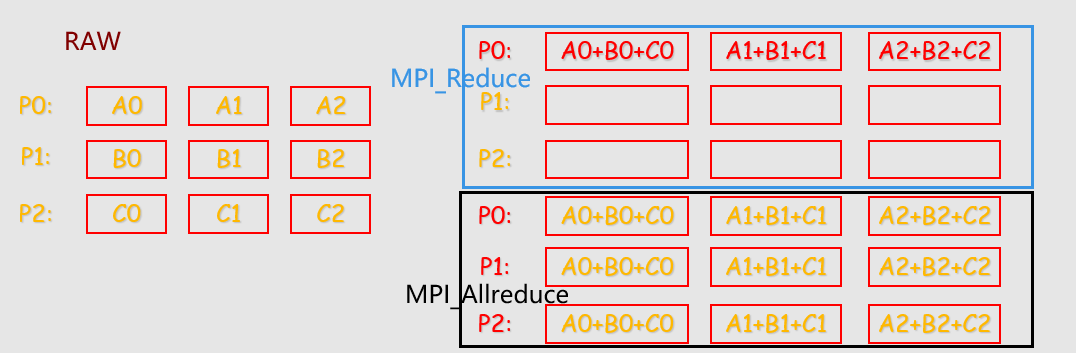
MPI聚合的功能分三步实现 * 首先是通信的功能,即消息根据要求发送到目标进程,目标进程也已经收到了各自需要的消息; * 然后是对消息的处理,即执行计算功能; * 最后把处理结果放入指定的接收缓冲区。
MPI提供了两种类型的聚合操作: 归约和扫描。
int MPI_Reduce(
void *input_data, /*指向发送消息的内存块的指针 */
void *output_data, /*指向接收(输出)消息的内存块的指针 */
int count,/*数据量*/
MPI_Datatype datatype,/*数据类型*/
MPI_Op operator,/*规约操作*/
int dest,/*要接收(输出)消息的进程的进程号*/
MPI_Comm comm);/*通信器,指定通信范围*/
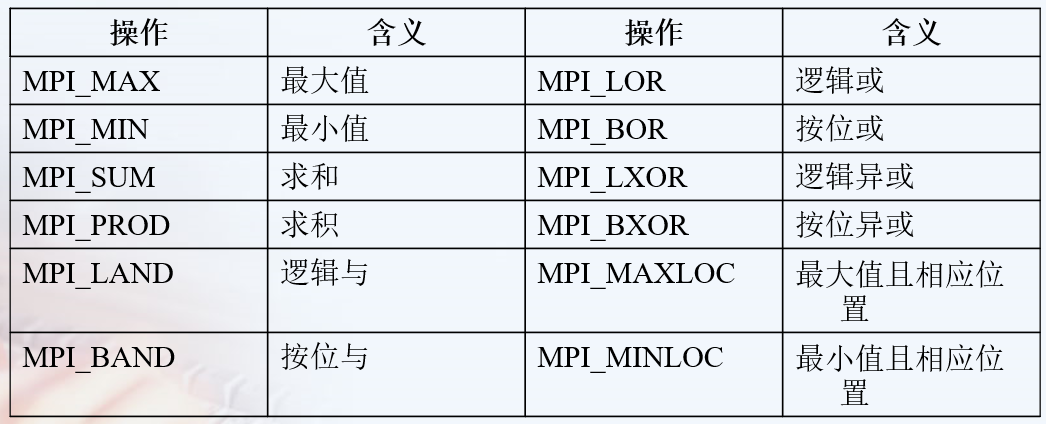
// operator可以有:求最大值 MPI_MAX 最小值 求累加和 累乘积 逻辑操作
// 求和语句
MPI_Reduce(&local_int,&total_int,1,MPI_DOUBLE,MPI_SUM,0,MPI_COMM_WORLD);
//另外有时候需要将得到的结果放入所有的线程中
MPI_Allreduce(void* input_data_p,void*output_data_p, int count,MPI_Datatype datatype,MPI_Op operator, MPI_Comm comm);
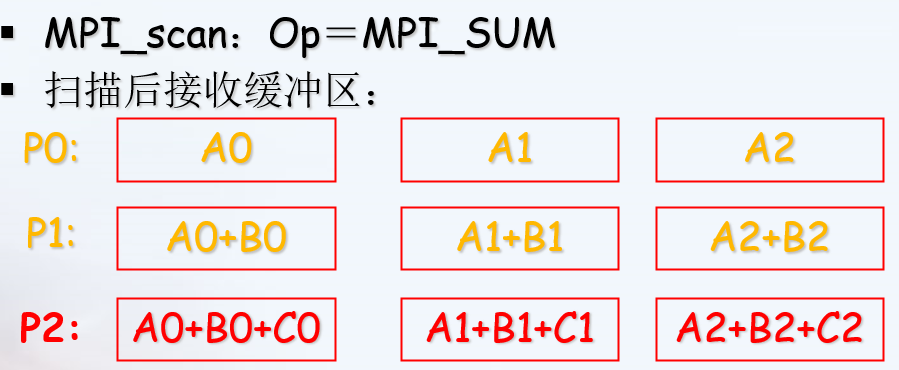
//每一个进程都对排在它前面的进程进行归约操作。
MPI_scan(SendAddress, RecvAddress, Count, Datatype, Op, Comm)
int MPI_Op_create(MPI_User_function *function, int commute, MPI_Op *op)
//function 用户自定义的函数(函数)
//commute 如果commute=ture, 则此操作同时也是可交换的。如果commute=false,则此操作不满足交换律。
else 按进程号升序进行Op操作
//op 自定义归约操作名
int MPI_Op_free(MPI_Op *op) //将用户自定义的归约操作撤销, 将op设置成MPI_OP_NULL。
typedef void MPI_User_function(void *invec, void *inoutvec, int *len, MPI_Datatype *datatype)
必须具备四个参数:
1. invec 和 inoutvec 分别指出将要被归约的数据所在的缓冲区的首地址,
2. len指出将要归约的元素的个数, datatype 指出归约对象的数据类型
也可以认为invec和inoutvec 是函数中长度为len的数组, 归约的结果重写了inoutvec 的值。
/*
@local_inte:send buffer;
@total_inte:receive buffer;
@MPI_SUM:MPI_Op;
@dest=0,rank of the process obtaining the result.
*/ 中间改成这个
MPI_Reduce(&local_inte, &total_inte, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
MPI_Group https://www.rookiehpc.com/mpi/docs/mpi_group.php
并行IO文件
1997年推出了MPI的最新版本MPI-2
MPI-2加入了许多新特性,主要包括 * 动态进程(Dynamic Process) * 远程存储访问(Remote Memory Access) * 并行I/O访问(Parallel I/O Access) * MPI-1没有对并行文件I/O给出任何定义,原因在于并行I/O过于复杂,很难找到一个统一的标准。 more
数据发送和收集
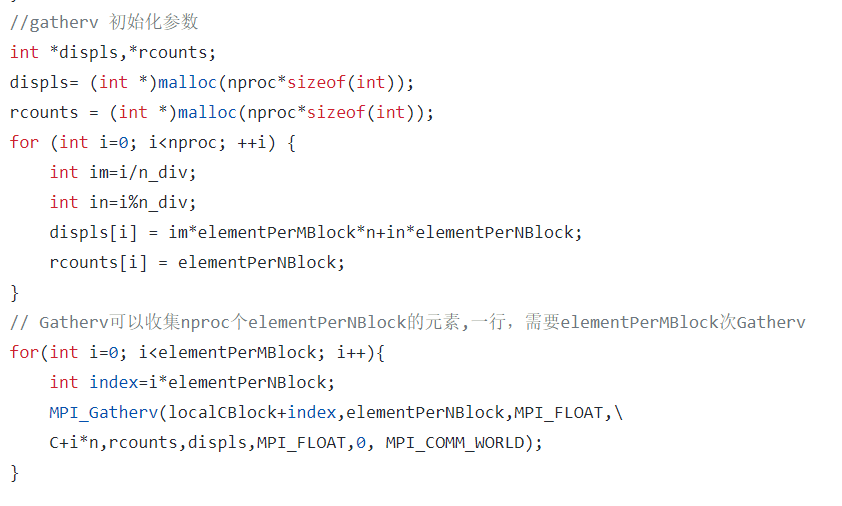
https://blog.csdn.net/susan_wang1/article/details/50033823
https://blog.csdn.net/u012417189/article/details/25798705
是否死锁: https://stackoverflow.com/questions/20448283/deadlock-with-mpi
https://mpitutorial.com/tutorials/
http://staff.ustc.edu.cn/~qlzheng/pp11/ 第5讲写得特别详细
https://www.mpich.org/static/docs/latest/www3/