Motherboard & PCI-e & UPI
导言
CPU间互联,CPU 与 主板,显卡与内存间数据通信的速率
导言
CPU间互联,CPU 与 主板,显卡与内存间数据通信的速率
导言
Divide the bulky and outdated content about cuda runtime env into individual posts, ensuring both the thematic integrity and a balanced size for each blog entry.
导言
生产特殊的硬件:
常见的例子,用于并行计算的GPU, H265视频编解码单元, Google TPU芯片、车载芯片、手机AI芯片。
AI领域的至今不变的特点:
现在大火的transformer,除非它就是AGI的最理想模型,不然为一个模型专门定制硬件,很容易钱就打水漂了。为自己的算法模型定制一块AI芯片,如特斯拉。但应用面越窄,出货量就越低,摊在每颗芯片上的成本就越高,这反过来推高芯片价格,高价格进一步缩窄了市场,因此独立的AI芯片必须考虑尽可能适配多种算法模型。1
当然,也可以从workload的应用出发,分析有什么重复的热点,值得做成专用的电路单元。
导言
导言
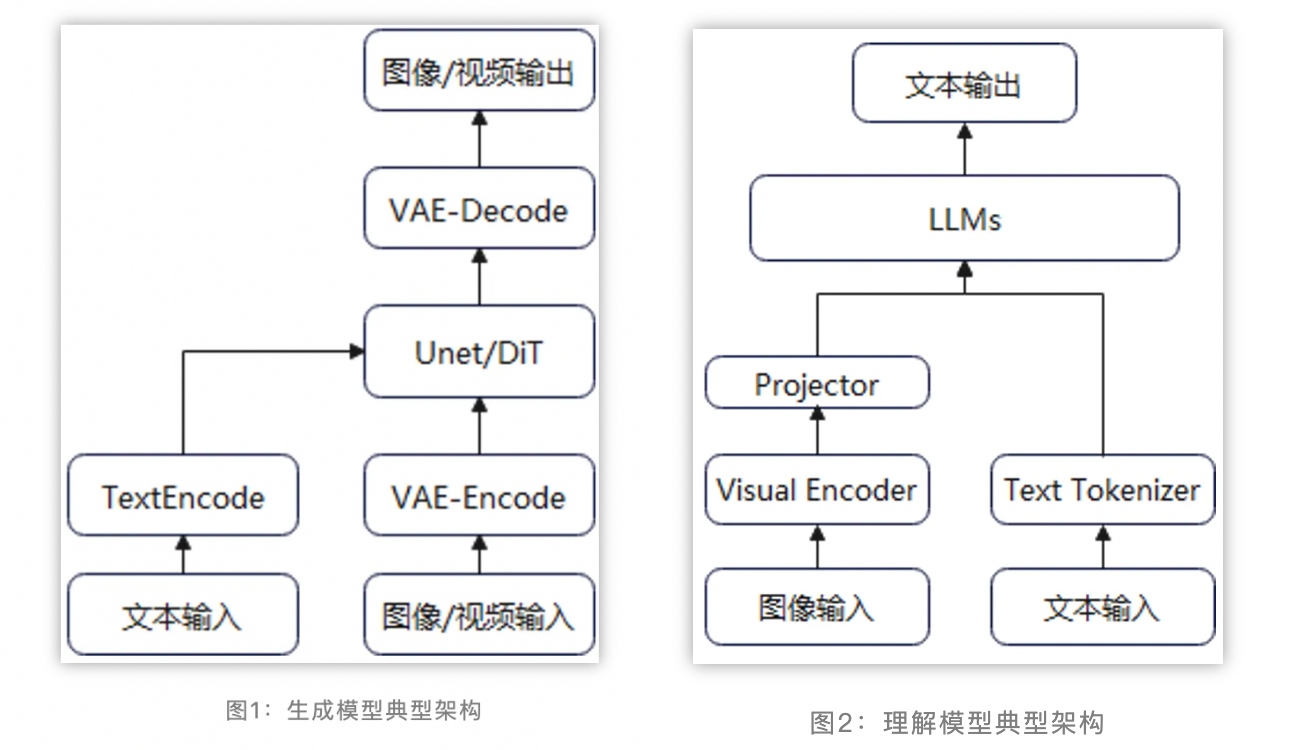
当前主流的多模态生成模型(如图像生成text2image和视频生成text2video)主要采用Latent Stable Diffusion的方案框架。为了减少计算量,图像/视频等模态的数据(噪声)先经过VAE压缩得到Latent Vector,然后在文本信息的指导下进行去噪,最后生成符合预期的图像或视频。
排行榜: (T2I, ImageEdit, T2V, I2V, )
当前主流的多模态生成模型(如图像生成和视频生成)主要采用Latent Stable Diffusion的方案框架。为了减少计算量,图像/视频等模态的数据(噪声)先经过VAE压缩得到Latent Vector,然后在文本信息的指导下进行去噪,最后生成符合预期的图像或视频。
导言
在回顾数理逻辑的时候,又想起了NP问题,和NP完全的问题
导言
明白设计(数据构造,模型设计, 训练流程)的有效性,是抓住问题核心的关键。有助于在众多的AI论文里筛选出有效结论。
通过这些宝贵的信息,才能渐渐知道能被时间检验过的经验是什么。
本文将聚焦于归档 有效性相关的工作。
导言
导言
和AIGC 生图相关
导言
RL 涉及到 推理,推理的流程细节不是很明晰。