对于大部分选项,Intel编译器在Win上的格式为:/Qopt,那么对应于Lin上的选项是:-opt。禁用某一个选项的方式是/Qopt-和-opt-。
在Win上,编译器为icl.exe,链接器为xilink.exe,VS的编译器为cl.exe,链接器为link.exe。
在Linux下,C编译器为icc,C++编译器为icpc(但是也可以使用icc编译C++文件),链接器为xild,打包为xiar,其余工具类似命名。
GNU的C编译器为gcc,C++编译器为g++,链接器为ld,打包为ar
如果选项 O2 或更高版本有效,则启用 OpenMP* SIMD 编译。
告诉自动并行程序为可以安全地并行执行的循环生成多线程代码。
要使用此选项,您还必须指定选项 O2 或 O3。
如果还指定了选项 O3,则此选项设置选项 [q 或 Q]opt-matmul。
启用或禁用编译器生成的矩阵乘法(matmul)库调用。
必须至少与-O2一起使用,在Linux系统上,如果既不指定-x也不指定-m,则默认值为-msse2。
On macOS* systems: -ipo, -mdynamic-no-pic,-O3, -no-prec-div,-fp-model fast=2, and -xHost
On Windows* systems: /O3, /Qipo, /Qprec-div-, /fp:fast=2, and /QxHost
On Linux* systems: -ipo, -O3, -no-prec-div,-static, -fp-model fast=2, and -xHost
指定选项 fast 后,您可以通过在命令行上指定不同的特定于处理器的 [Q]x 选项来覆盖 [Q]xHost 选项设置。但是,命令行上指定的最后一个选项优先。
必须至少与-O2一起使用,如果同时指定 -ax 和 -march 选项,编译器将不会生成特定于 Intel 的指令。
指定 -march=pentium4 设置 -mtune=pentium4。
告诉编译器它可以针对哪些处理器功能,包括它可以生成哪些指令集和优化。
AMBERLAKE
BROADWELL
CANNONLAKE
CASCADELAKE
COFFEELAKE
GOLDMONT
GOLDMONT-PLUS
HASWELL
ICELAKE-CLIENT (or ICELAKE)
ICELAKE-SERVER
IVYBRIDGE
KABYLAKE
KNL
KNM
SANDYBRIDGE
SILVERMONT
SKYLAKE
SKYLAKE-AVX512
TREMONT
WHISKEYLAKE

告诉编译器它可能针对哪些功能,包括它可能生成的指令集。
生成基于多个指令集的代码。
High-level Optimizations,高级(别)优化。O1不属于
更广泛的优化。英特尔推荐通用。
在O2和更高级别启用矢量化。
在使用IA-32体系结构的系统上:执行一些基本的循环优化,例如分发、谓词Opt、交换、多版本控制和标量替换。
此选项还支持:
内部函数的内联
文件内过程间优化,包括:
内联
恒定传播
正向替代
常规属性传播
可变地址分析
死静态函数消除
删除未引用变量
以下性能增益功能:
恒定传播
复制传播
死码消除
全局寄存器分配
全局指令调度与控制推测
循环展开
优化代码选择
部分冗余消除
强度折减/诱导变量简化
变量重命名
异常处理优化
尾部递归
窥视孔优化
结构分配降低与优化
死区消除
O3选项对循环转换(loop transformations)进行更好的处理来优化内存访问。
比-O2更激进,编译时间更长。建议用于涉及密集浮点计算的循环代码。
既执行O2优化,并支持更积极的循环转换,如Fusion、Block Unroll和Jam以及Collasing IF语句。
此选项可以设置其他选项。这由编译器决定,具体取决于您使用的操作系统和体系结构。设置的选项可能会因版本而异。
当O3与options-ax或-x(Linux)或options/Qax或/Qx(Windows)一起使用时,编译器执行的数据依赖性分析比O2更严格,这可能会导致更长的编译时间。
O3优化可能不会导致更高的性能,除非发生循环和内存访问转换。在某些情况下,与O2优化相比,优化可能会减慢代码的速度。
O3选项建议用于循环大量使用浮点计算和处理大型数据集的应用程序。
与非英特尔微处理器相比,共享库中的许多例程针对英特尔微处理器进行了高度优化。
-O3 plus some extras.
Interprocedural Optimizations,过程间优化。
典型优化措施包括:过程内嵌与重新排序、消除死(执行不到的)代码以及常数传播和内联等基本优化。
过程间优化,当程序链接时检查文件间函数调用的一个步骤。在编译和链接时必须使用此标志。使用这个标志的编译时间非常长,但是根据应用程序的不同,如果与-O*标志结合使用,可能会有明显的性能改进。
内联或内联展开,简单理解,就是将函数调用用函数体代替,主要优点是省去了函数调用开销和返回指令的开销,主要缺点是可能增大代码大小。
PGO优化是分三步完成的,是一个动态的优化过程。
PGO,即Profile-Guided Optimizations,档案导引优化。
此标志对特定的处理器类型进行额外的调整,但是它不会生成额外的SIMD指令,因此不存在体系结构兼容性问题。调优将涉及对处理器缓存大小、指令优先顺序等的优化。
为支持指定英特尔处理器或微体系结构代码名的处理器优化代码。
不启用 提高浮点除法的精度。
不用动态库
自动向量化时按照固定精度,与OpenMP的选项好像有兼容性的问题
展开所有循环,即使进入循环时迭代次数不确定。此选项可能会影响性能。
此选项决定编译器是否对某些循环使用更激进的展开。期权的积极形式可以提高绩效。
此选项可对具有较小恒定递增计数的回路进行积极的完全展开。
将循环对齐到 2 的幂次字节边界。
-falign-loops[=n]是最小对齐边界的可选字节数。它必须是 1 到 4096 之间的 2 的幂,例如 1、2、4、8、16、32、64、128 等。如果为 n 指定 1,则不执行对齐;这与指定选项的否定形式相同。如果不指定 n,则默认对齐为 16 字节。
关闭所有优化选项,-O等于-O2 (Linux and macOS)
在保证代码量不增加的情况下编译,
- 实现全局优化;这包括数据流分析、代码运动、强度降低和测试替换、分割生存期分析和指令调度。
- 禁用某些内部函数的内联。
icpc -dM -E -x c++ SLIC.cpp
https://stackoverflow.com/questions/34310546/how-can-i-see-which-compilation-options-are-enabled-on-intel-icc-compiler
parallel 与mpicc 或者mpiicc有什么区别呢
讲实话,IPO PGO我已经晕了,我先列个list,之后再研究
https://blog.csdn.net/gengshenghong/article/details/7034748
按字母顺序排列的intel c++编译器选项列表


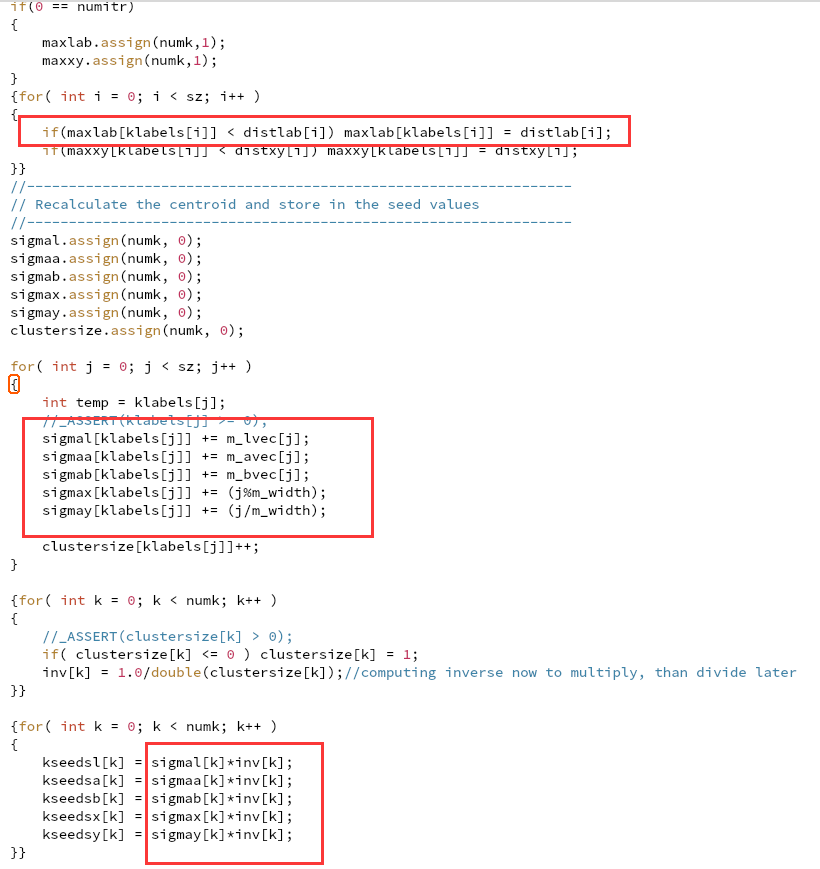
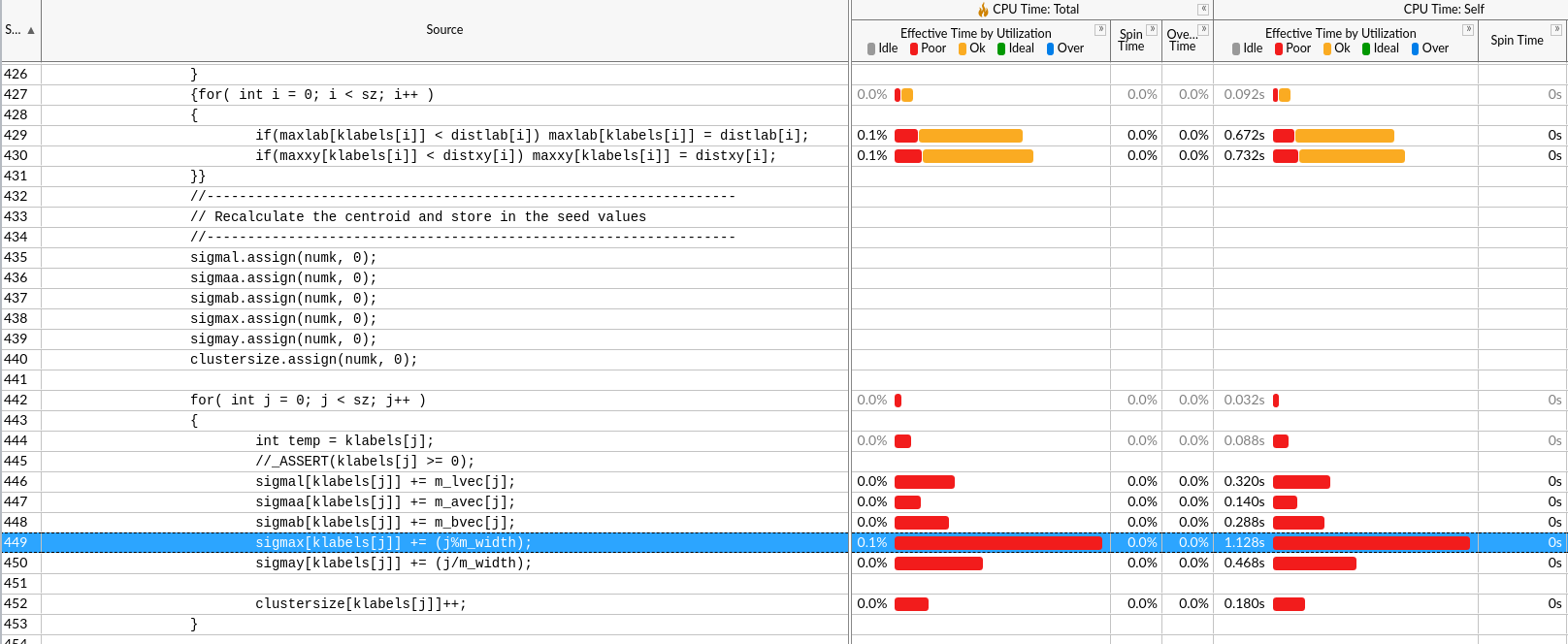
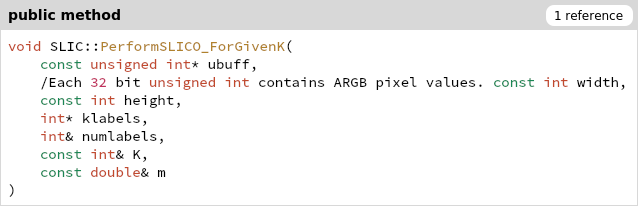 一开始所有的RGB颜色在ubuff里,klabel存分类结果
一开始所有的RGB颜色在ubuff里,klabel存分类结果
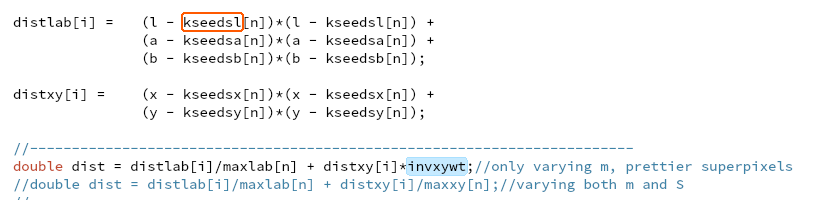
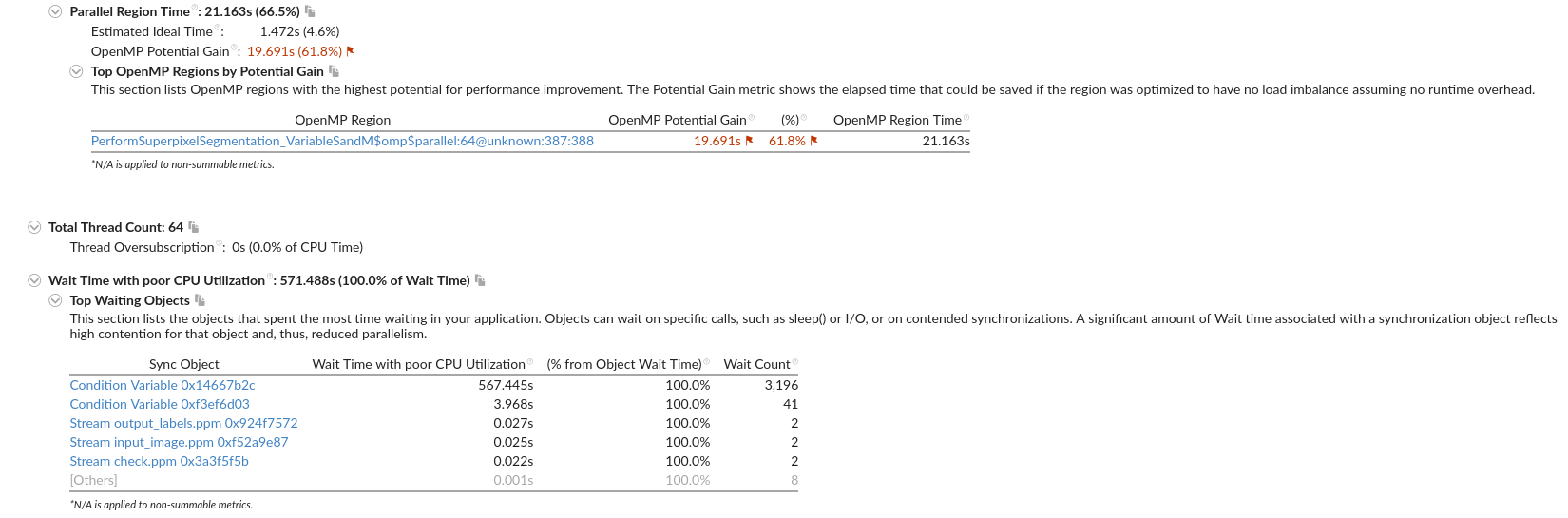
 计算出的全体edges,只有一部分在后面一个地方用了196个中心以及周围8个节点。
计算出的全体edges,只有一部分在后面一个地方用了196个中心以及周围8个节点。