指令集架构(Instruction Set Architecture)是指一种类型CPU中用来计算和控制计算机系统的一套指令的集合。
指令集架构主要规定了指令格式、寻址访存(寻址范围、寻址模式、寻址粒度、访存方式、地址对齐等)、数据类型、寄存器。指令集通常包括三大类主要指令类型:运算指令、分支指令和访存指令。此外,还包括架构相关指令、复杂操作指令和其他特殊用途指令。因此,一种CPU执行的指令集架构不仅决定了CPU所要求的能力,而且也决定了指令的格式和CPU的结构。X86架构和ARMv8架构就是指令集架构的范畴。
所以不要说Nvidia是属于x86还是arm了,显卡应该是有自己的架构的。比如NV Tesla架构 、Fermi架构、Maxwell架构、Kepler架构、Turing架构。
而且X86具体到Intel,也有Skylake 架构 Ice lake 架构 Haswell架构等具体的实现
复杂指令集(CISC,complex instruction set computer)
RISC:Reduced Instruction Set Computer
$\(p(performance)=\frac{IPC*f}{Instruction\ Count}\)$
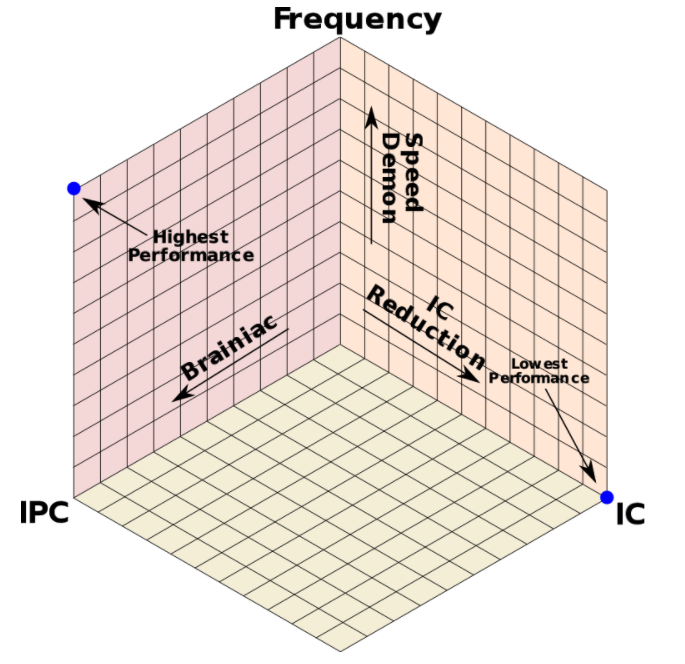
在计算机发展初期,计算机的优化方向是通过设置一些功能复杂的指令,把一些原来由软件实现的、常用的功能改用硬件的指令系统实现(减少IC),以此来提高计算机的执行速度。也就是为了减少程序的设计时间,逐渐开发出单一指令,复杂操作的程序代码。设计师只需写下简单的指令,再交给CPU去执行。
但是后来有人发现,整个指令集中,只有约20%的指令常常会被使用到,大约占了整个程序的80%;剩余80%的指令,只占了整个程序的20%。(典型的二八原则)
于是有人提出RISC尽量简化计算机指令功能的想法,主张硬件应该专心加速常用的指令,较为复杂的指令则利用常用的指令去组合。功能简单、能在一个节拍内执行完成的指令被保留,而较复杂的功能用一段子程序来实现,这种计算机系统就被称为精简指令系统计算机。
简单来说,CISC任务处理能力强,适合桌面电脑和服务器。RISC通过精简CISC指令种类,格式,简化寻址方式,达到省电高效的效果,适合手机、平板、数码相机等便携式电子产品。

1978年6月8日,Intel 发布了新款16位微处理器 8086,也同时开创了一个新时代:X86架构诞生了。
X86指令集是美国Intel公司为其第一块16位CPU(i8086)专门开发的,美国IBM公司1981年推出的世界第一台PC机中的CPU–i8088(i8086简化版)使用的也是X86指令。
为了保证电脑能继续运行以往开发的各类应用程序以保护和继承丰富的软件资源,所以Intel公司所生产的所有CPU仍然继续使用X86指令集。
IA64,又称英特尔安腾架构(Intel Itanium architecture),使用在Itanium处理器家族上的64位指令集架构,由英特尔公司与惠普公司共同开发,2001年首次推出。
见 arm.md
1981年出现,由MIPS科技公司开发并授权,它是基于一种固定长度的定期编码指令集,并采用 导入/存储(Load/Store)数据模型。
mips是一个学院派的cpu,授权门槛极低,因此很多厂家都做mips或者mips衍生架构。我们平时接触到的mips架构cpu主要用在嵌入式领域,比如路由器。
目前最活跃的mips是中国的龙芯,其loongisa架构其实是mips的扩展。
Alpha是DEC公司推出的RISC指令集系统,基于Alpha指令集的CPU也称为Alpha AXP架构,是64位的 RISC微处理器,最初由DEC公司制造,并被用于DEC自己的工作站和服务器中。作为VAX的后续被开发,支持VMS操作系统,如 Digital UNIX。
侧重超算,目前貌似最活跃是中国申威,神威太湖之光的cpu
2010年提出,受到大家的支持。USTC有团队研究。
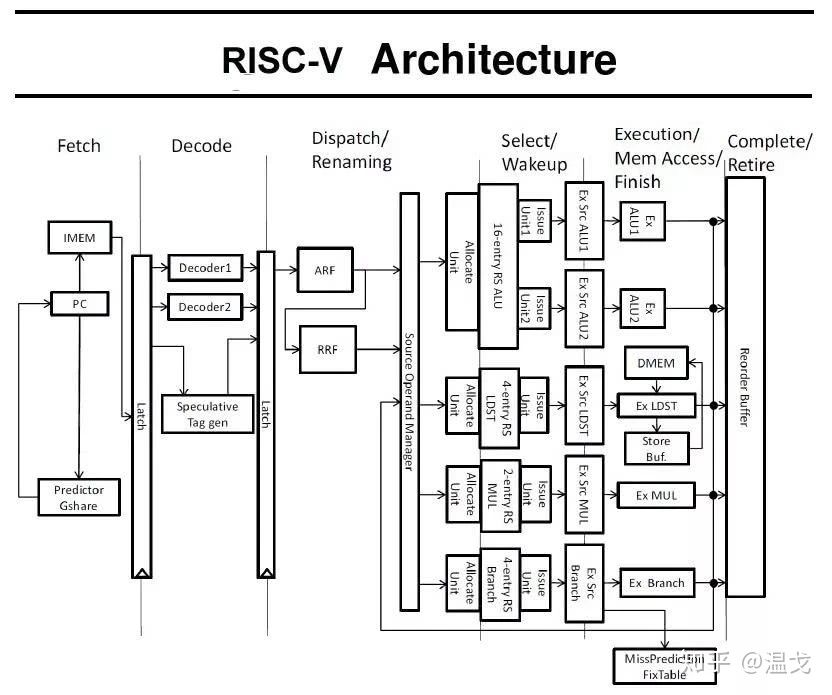
90年代,MIPS和Alpha作为知名RISC在与X86竞争计算机市场中失败,又在错过智能终端高速发展的机遇中走向衰弱。2010年发布的RISC-V作为从发明伊始即以开源为最大特色的RISC ISA受到全球学界、产业界的高度关注。全球顶级学府、科研机构、芯片巨头纷纷参与,各国政府出台政策支持RISC-V的发展和商业化。RISC-V有望成为X86和ARM之后ISA第三极。
实现指令集架构的物理电路被称为处理器的微架构(Micro-architecture)
大多数情况下,一种处理器的微架构是针对一种特定指令集架构进行物理实现。少部分处理器架构设计为了更好的兼容性,会在电路设计上实现多个指令集架构。虽然,指令集架构可以授权给多家企业,但微架构的设计细节,也就是对指令的物理实现方式是各家厂商绝对保密的。
暂无
暂无
https://www.zhihu.com/question/423489755/answer/1622380842
 使用了LLVM后端的调度模型参数。这种重用调度模型的选择对llvm cost 模型提供了经验。其准确性于调度模型有关。
使用了LLVM后端的调度模型参数。这种重用调度模型的选择对llvm cost 模型提供了经验。其准确性于调度模型有关。





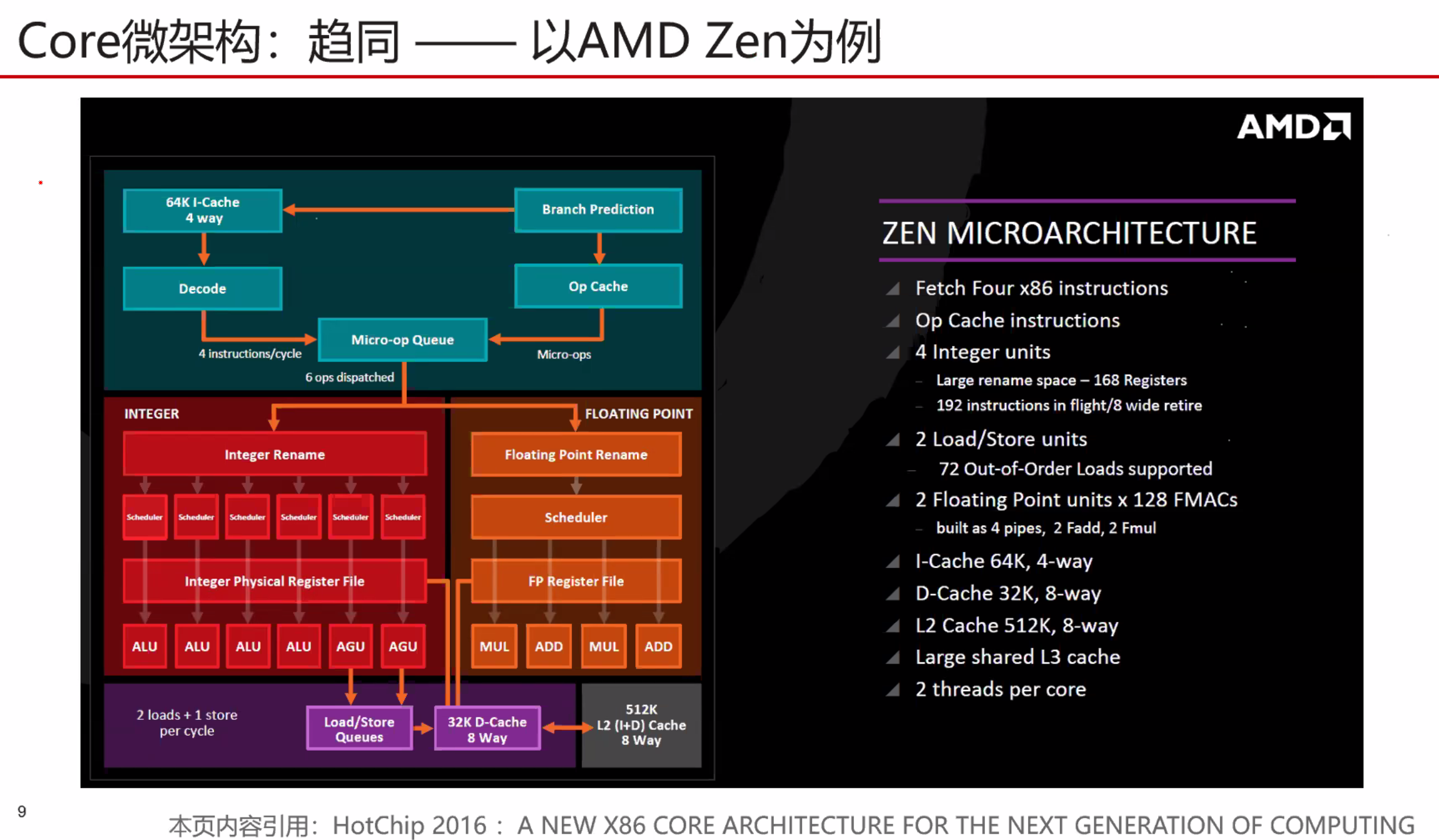
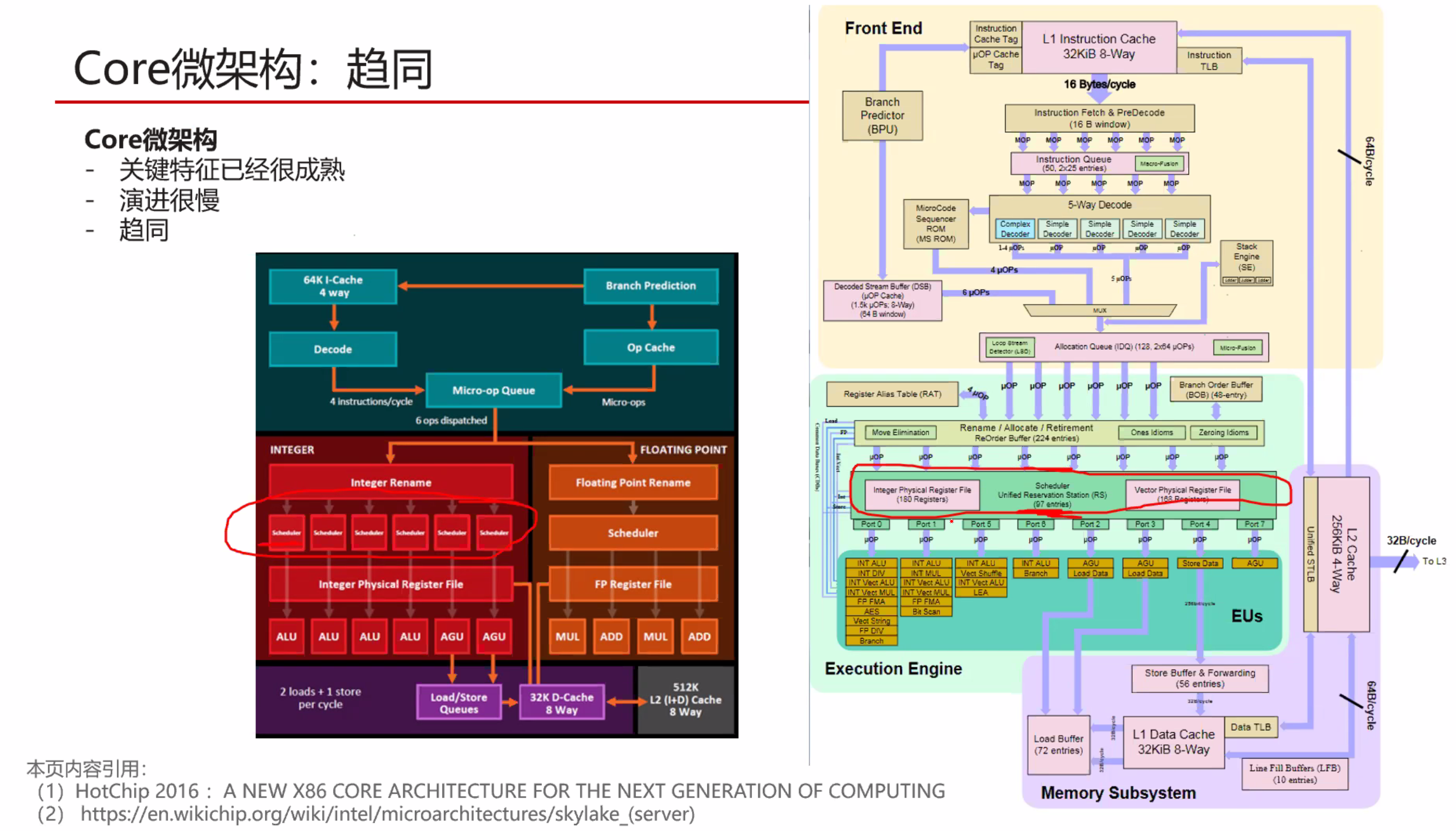 统一的调度器复杂度超级高,只有Intel实现了,但是效果很好。
统一的调度器复杂度超级高,只有Intel实现了,但是效果很好。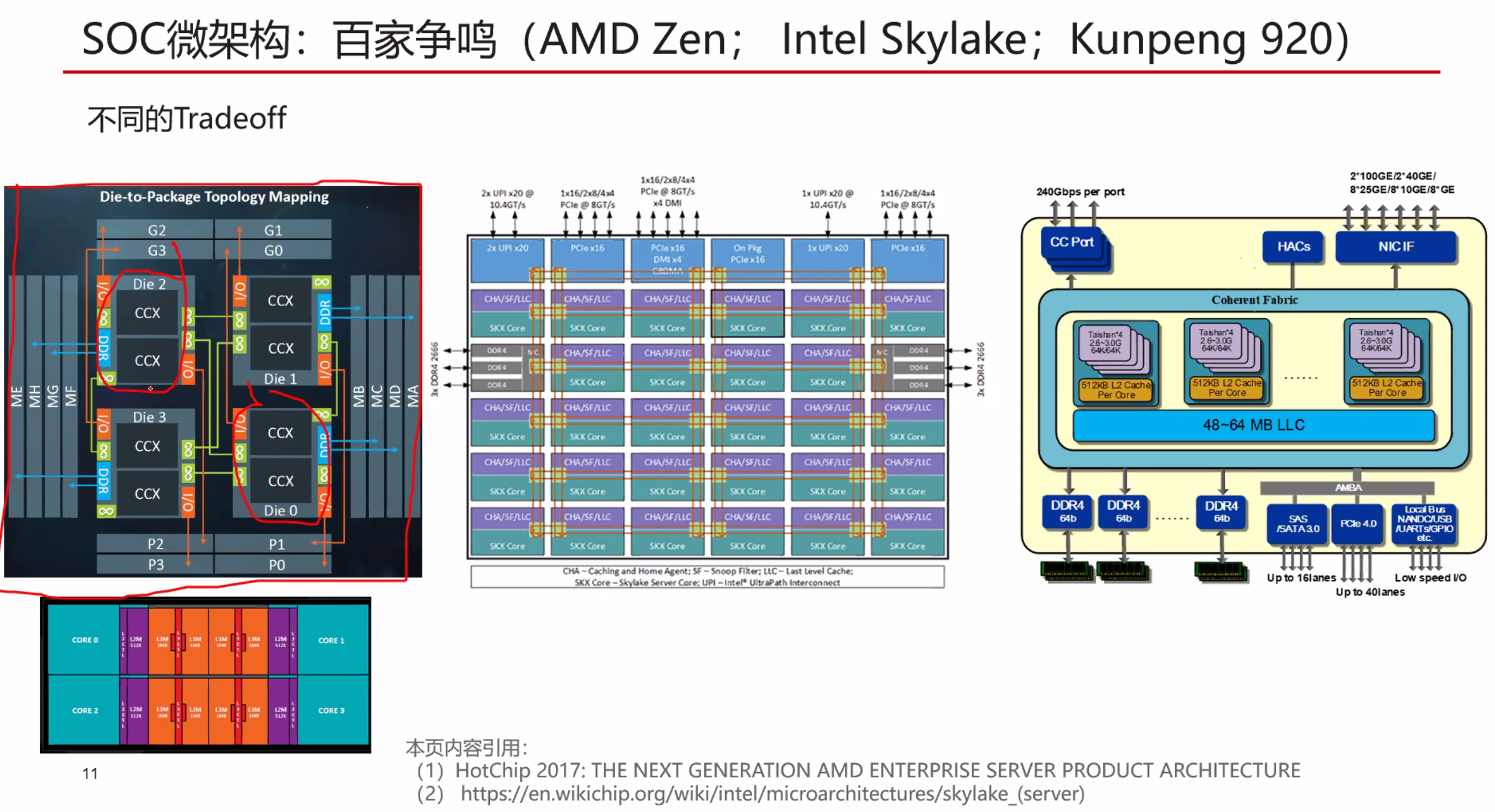
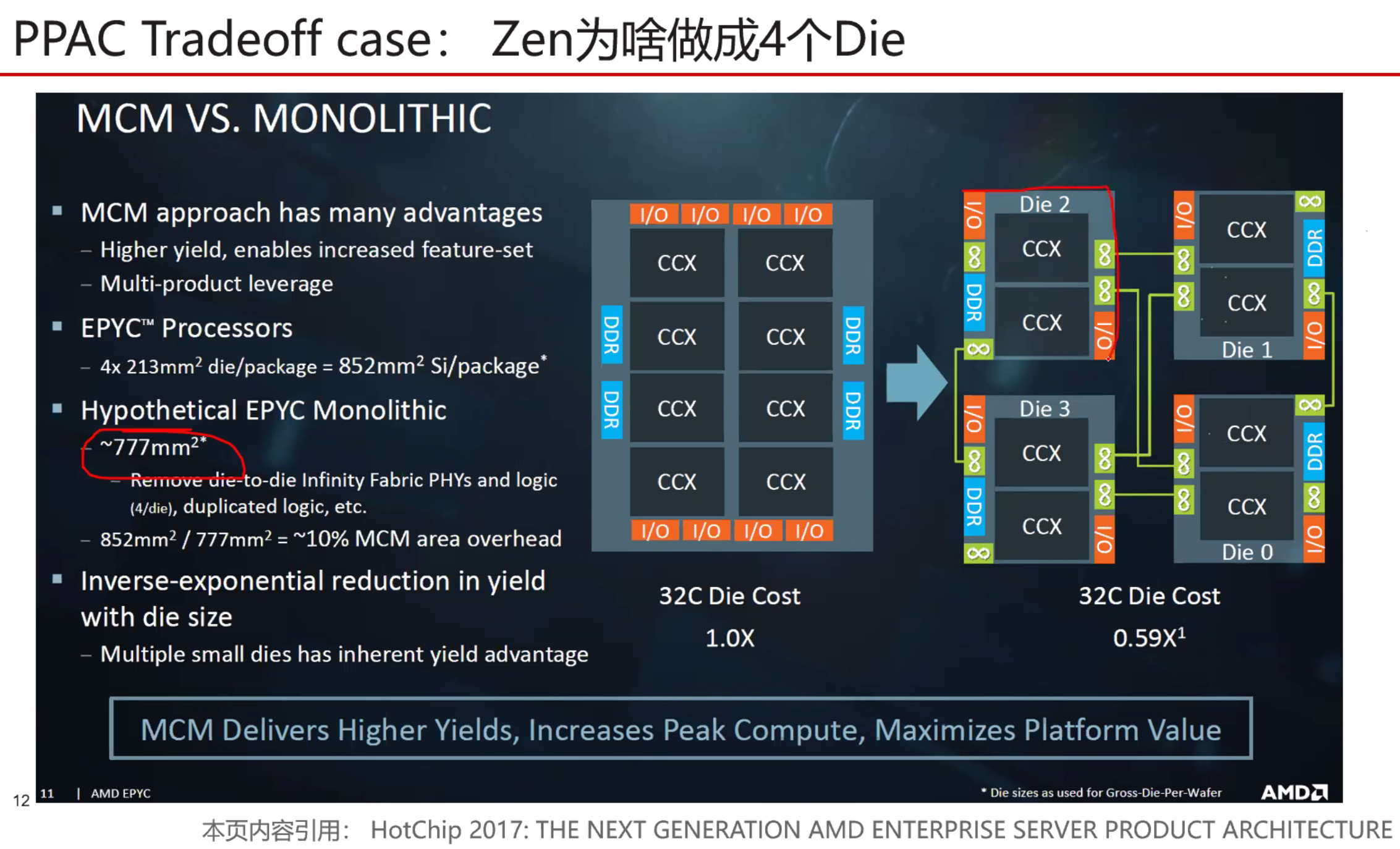 良品率会更高
良品率会更高
 自研OpenBLAS+ ,毕申编译器,自研MPI
自研OpenBLAS+ ,毕申编译器,自研MPI


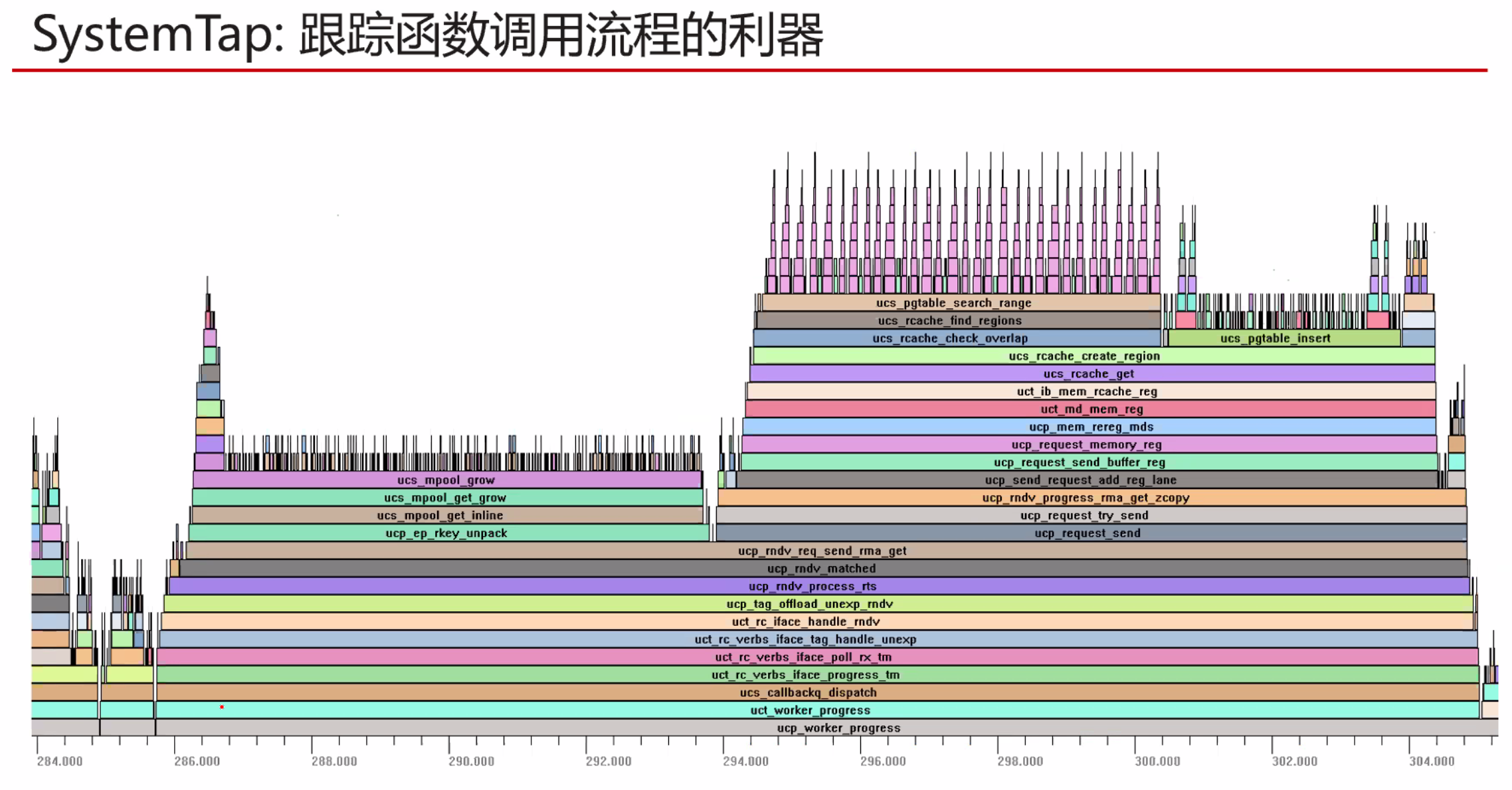
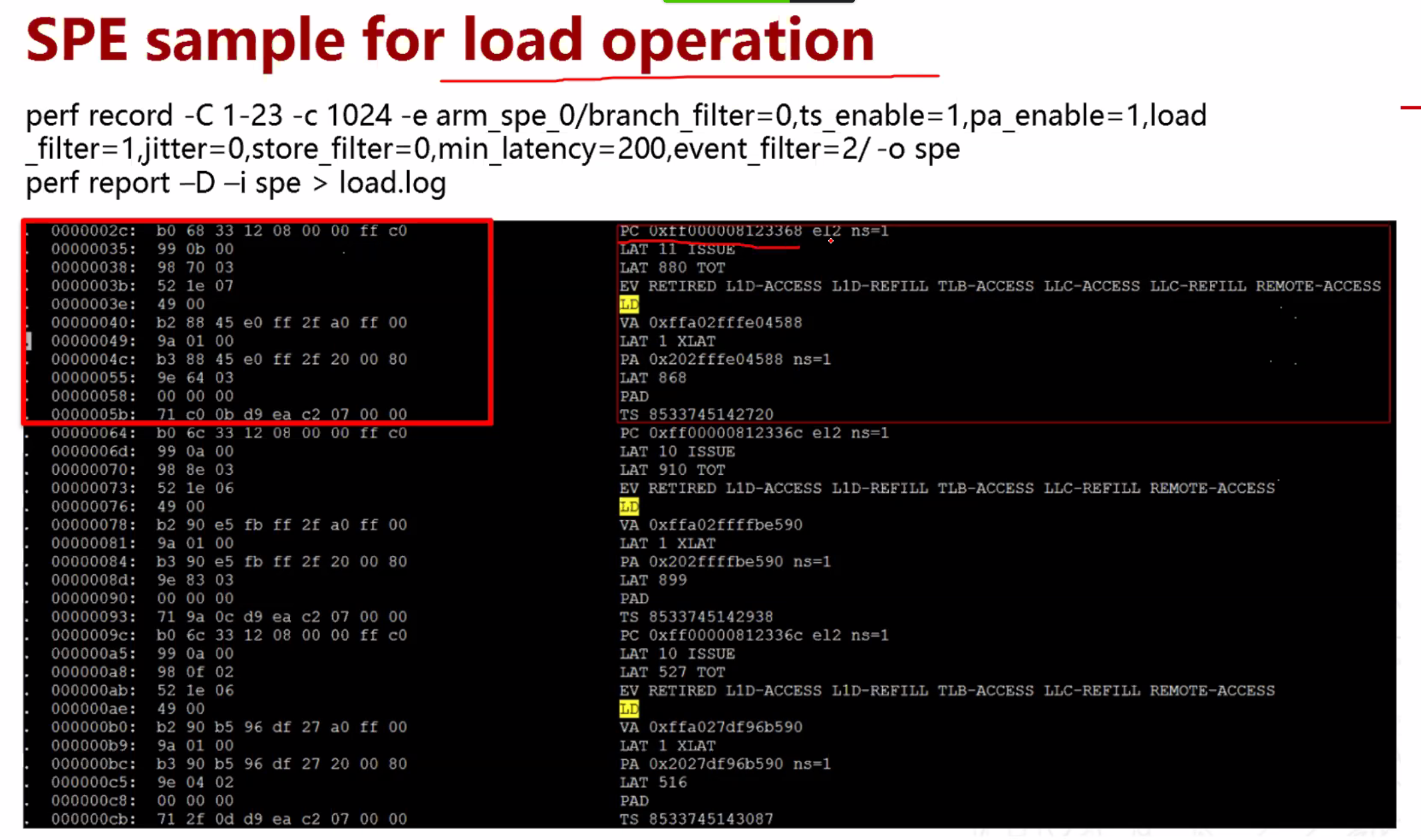
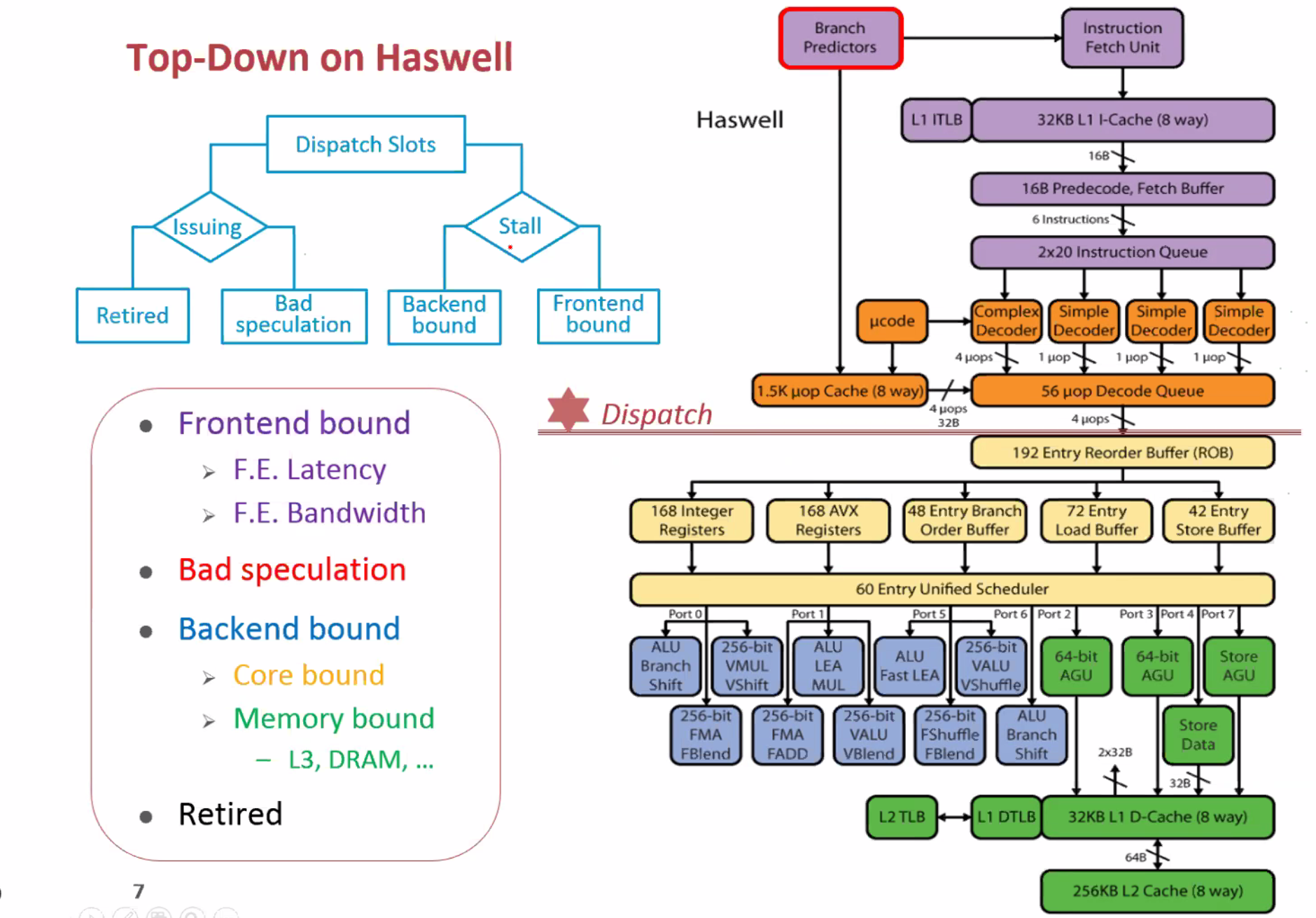
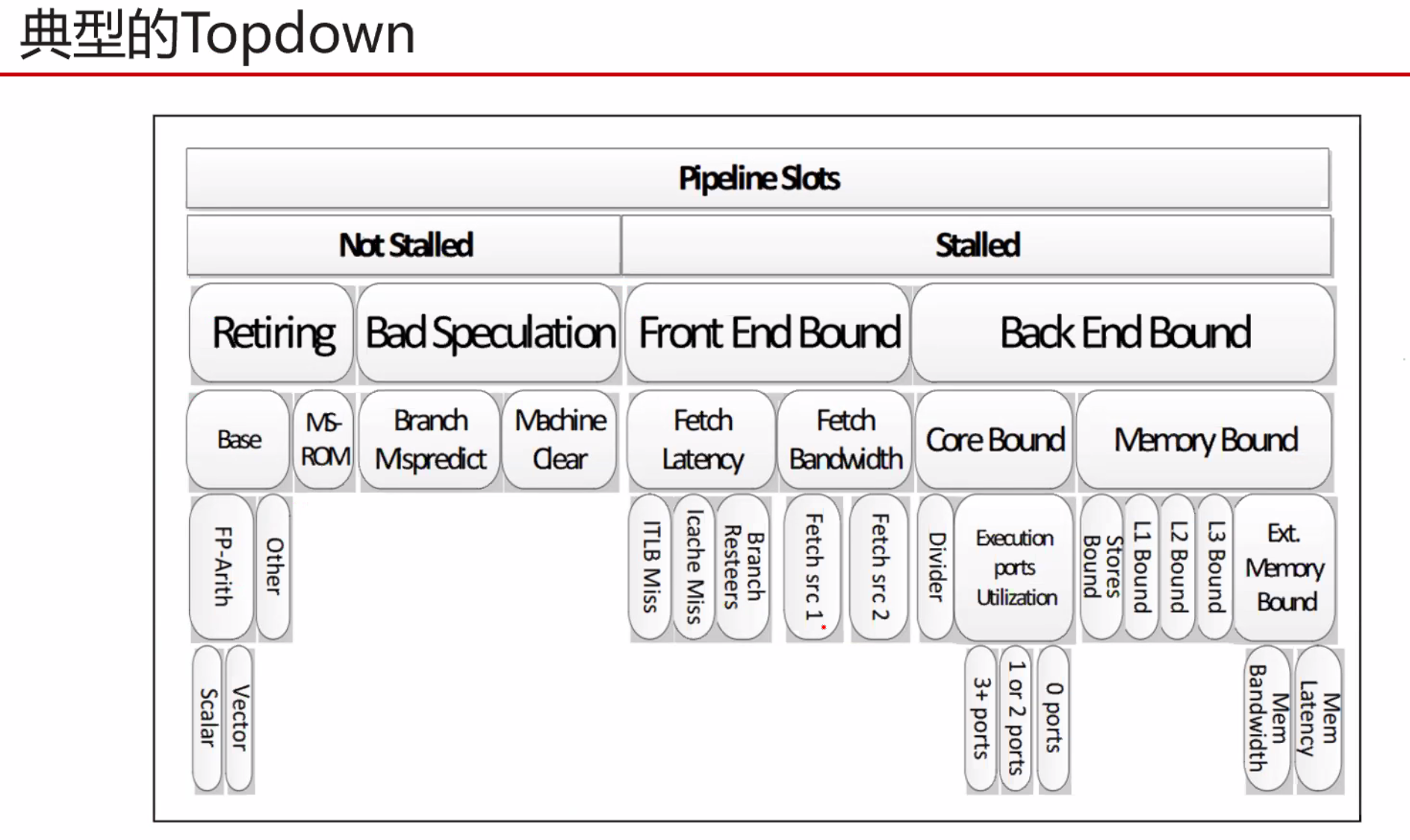

 s是并行部分的加速比,p是可并行部分。
s是并行部分的加速比,p是可并行部分。

