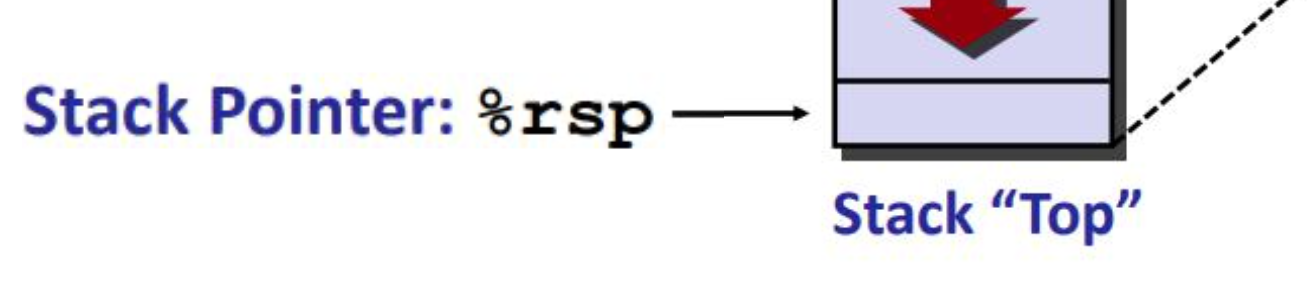1981年,被Intel拒绝的Acorn(橡子) Computer Ltd公司,一气之下觉得基于当时新型处理器的研究——简化指令集,自己设计一款微处理器。
1985年,第一款芯片问世Acorn RISC Machine,简称ARM。
1990年,Acorn为了和苹果合作,专门成立了一家公司,名叫ARM,但是全称是Advanced RISC Machines。
虽然有苹果的合资,但是初期极其艰难,ARM决定改变他们的产品策略——他们不再生产芯片,转而以授权的方式,将芯片设计方案转让给其他公司,即“Partnership”开放模式。
通过IP(Intellectual Property,知识产权)授权,授权费和版税就成了ARM的主要收入来源。这种授权模式,极大地降低了自身的研发成本和研发风险。风险共担、利益共享的模式使得低成本创新成为可能。
-
1993年,ARM将产品授权给德州仪器,给ARM公司带来了重要的突破。也给ARM公司树立了声誉,证实了授权模式的可行性。
-
ARM+Nokia,诺基亚6110成为了第一部采用ARM处理器的GSM手机,上市后获得了极大的成功,成为当年的机皇。
1998年4月17日,业务飞速发展的ARM控股公司,同时在伦敦证交所和纳斯达克上市。
虽然后来苹果公司,逐步卖掉了所持有的ARM股票,鉴于苹果研究人员对ARM芯片架构非常熟悉,iPod也继续使用了ARM芯片。
-
ARM+Apple:创造移动互联网、iPhone、ARM指令集的黄金时代。
第一代iPhone,使用了ARM设计、三星制造的芯片。Iphone的热销,App Store的迅速崛起,让全球移动应用彻底绑定在ARM指令集上。
- 苹果的A系列处理器是基于ARM指令集架构授权自研内核的成功典范。
- 2012年9月,苹果随iPhone5上市发布了A6处理器SoC,这颗SoC基于ARMv7架构打造的Swift内核微架构开启了苹果基于ARM架构自研处理器内核的序幕。
- 2013年9月,苹果率先发布搭载基于ARMv8架构研发的64位Cyclone架构的双核A7处理器。A7作为世界首款64位智能手机处理器,在性能表现力压还在32位四核方案上竞争的安卓阵营。
- 2020年,苹果宣称新发布的A14 Bionic芯片性能已经堪比部分笔记本处理器。
- 2021年,M1诞生
紧接着,2008年,谷歌推出了Android(安卓)系统,也是基于ARM指令集。
从ARM角度来看,苹果M1一旦成功也将帮助ARM实现一直以来希望撕开X86垄断的个人计算机市场的野心。
2016年7月18日,曾经投资阿里巴巴的孙正义和他的日本软银集团,以243亿英镑(约309亿美元)收购了ARM集团。
至此,ARM成为软银集团旗下的全资子公司。不过,当时软银集团表示,不会干预或影响ARM未来的商业计划和决策。
在2020年6月22日,日本超算“富岳”(Fugaku)成为史上第一台基于ARM芯片的全球超算TOP500冠军。
小结:轻资产、开放合作、共赢。 ARM在低功耗方面的DNA,刚好赶上了移动设备爆发式发展的时代,最终造就了它的辉煌。在即将到来的万物互联时代,可以预见,ARM极有可能取得更大的成功。
2020年9月13日,NVIDIA(英伟达)和软银集团 (SoftBank Group Corp., SBG) 宣布了一项最终协议,根据此协议,NVIDIA 将以 400 亿美元的价格从软银集团和软银愿景基金(统称“软银”)收购 Arm Limited。
但是这场收购在全球IT行业掀起轩然大波,包括苹果、Intel、高通、三星、特斯拉等大部分巨头均表示反对。英国也反对。至今悬而未决。
主要区别在
- 通用寄存器一个是64位,一个是32位,
- 指令寻址能力增加,32位只能内存寻址4GB=4*1024*1024*1024 bytes
一些常见问题:
- 64位机器会比32位更快吗?
- 理论上计算不会,但是由于处理器一般先进,访存空间更大,会有些影响。和寄存器数量什么都有关。
- 32位机器就只有4GB内存?错误
- 其实32位处理器是可以使用4GB以上内存的,比如Pentium Pro的处理器具有36位物理地址,它就具有64GB(2^36b=64GB)的寻址空间,Intel称之为PAE(Physical Address Extension)。
Intel并没有开发64位版本的x86指令集。64位的指令集名为x86-64(有时简称为x64),实际上是AMD设计开发的。Intel想做64位计算,它知道如果从自己的32位x86架构进化出64位架构,新架构效率会很低,于是它搞了一个新64位处理器项目名为IA64。由此制造出了Itanium系列处理器。
同时AMD知道自己造不出能与IA64兼容的处理器,于是它把x86扩展一下,加入了64位寻址和64位寄存器。最终出来的架构,就是 AMD64,成为了64位版本的x86处理器的标准。IA64项目并不算得上成功,现如今基本被放弃了。Intel最终采用了AMD64。Intel当前给出的移动方案,是采用了AMD开发的64位指令集(有些许差别)的64位处理器。
x86-64架构诞生颇有时代意义。当时,处理器的发展遇到了瓶颈,内存寻址空间由于受到32位CPU的限制而只能最大到约4G。AMD主动把32位x86(或称为IA-32)扩充为64位。它以一个称为AMD64的架构出现(在重命名前也称为x86-64),且以这个技术为基础的第一个产品是单内核的Opteron和Athlon 64处理器家族。由于AMD的64位处理器产品线首先进入市场,且微软也不愿意为Intel和AMD开发两套不同的64位操作系统,Intel也被迫采纳AMD64指令集且增加某些新的扩充到他们自己的产品,命名为EM64T架构(显然他们不想承认这些指令集是来自它的主要对手),EM64T后来被Intel正式更名为Intel 64。这两者被统称为x86-64或x64,开创了x86的64位时代。
而ARM在看到移动设备对64位计算的需求后,于2011年发布了ARMv8 64位架构,这是为了下一代ARM指令集架构工作若干年后的结晶。为了基于原有的原则和指令集,开发一个简明的64位架构,ARMv8使用了两种执行模式,AArch32和AArch64。顾名思义,一个运行32位代码,一个运行64位代码。ARM设计的巧妙之处,是处理器在运行中可以无缝地在两种模式间切换。这意味着64位指令的解码器是全新设计的,不用兼顾32位指令,而处理器依然可以向后兼容。
在cpu同制程工艺下,
ARM的处理器有个特点,就是乱序执行能力不如X86。
X86为了增强对随机操作命令情况下的处理能力,加强了乱序指令的执行、单核的多线程能力。
缺点就是,无法很有效的关闭和恢复处理器子模块,因为一旦关闭,恢复起来就很慢,从而造成低性能。为了保持高性能,就不得不让大部分的模块都保持开启,并且时钟也保持切换。这样做的直接后果就是耗电高。
ARM的指令强在确定次序的执行,并且依靠多核而不是单核多线程来执行。这样容易保持子模块和时钟信号的关闭,显然就更省电。
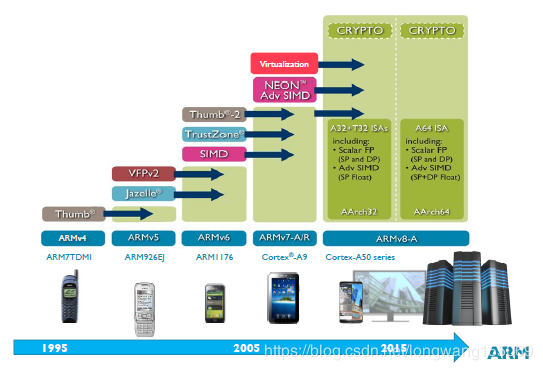
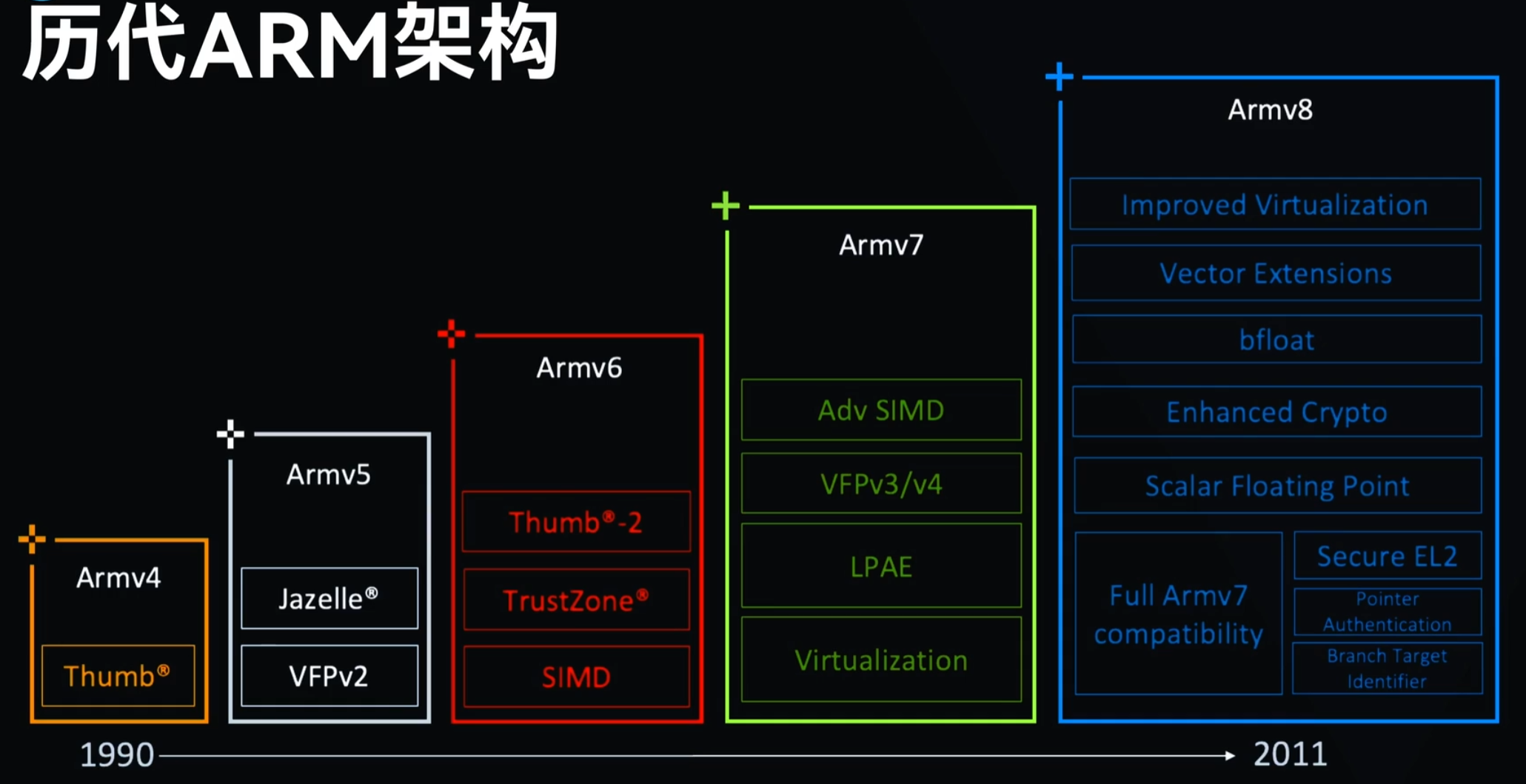
ARM11芯片之后,也就是从ARMv7架构开始,改以Cortex命名,并分为三个系列,分别是Cortex-A,Cortex-R,Cortex-M。呵呵,发现了没,三个字母又是A、R、M。
-
Cortex-A系列(A:Application)
针对日益增长的消费娱乐和无线产品设计,用于具有高计算要求、运行丰富操作系统及提供交互媒体和图形体验的应用领域,如智能手机、平板电脑、汽车娱乐系统、数字电视等。
Cortex-A目前有A7x系列为代表的性能大核产品线和A5x系列为代表低功耗小核产品线。
其中大核运行短时间的高性能需求任务;小核运行低性能需求的任务或者在待机状态支持背景任务运行。
-
Cortex-R系列 (R:Real-time)
针对需要运行实时操作的系统应用,面向如汽车制动系统、动力传动解决方案、大容量存储控制器等深层嵌入式实时应用。
-
Cortex-M系列(M:Microcontroller)
该系列面向微控制器microcontroller (MCU) 领域,主要针对成本和功耗敏感的应用,如智能测量、人机接口设备、汽车和工业控制系统、家用电器、消费性产品和医疗器械等。智能互联时代应用前景非常广阔。
-
Cortex-SC系列(SC:SecurCore)
其实,除了上述三大系列之外,还有一个主打安全的(SC:SecurCore),主要用于政府安全芯片。
自 2011 年 10 月 Arm 首次公布 Armv8架构以来,已经有近 10 年的时间了
- 支持SVE2(可以打通512位矢量寄存器和128等各层次的使用,不用重新写)和矩阵乘法
- 安全、AI 以及改进矢量扩展(Scalable Vector Extensions,简称SVE)和 DSP 能力
- 新的可变向量长度 SIMD 指令集的首次迭代范围相当有限,而且更多的是针对 HPC 工作负载,缺少了许多通用性较强的指令
- 具有保密功能的计算架构
2021年3月31日,ARM V9发布

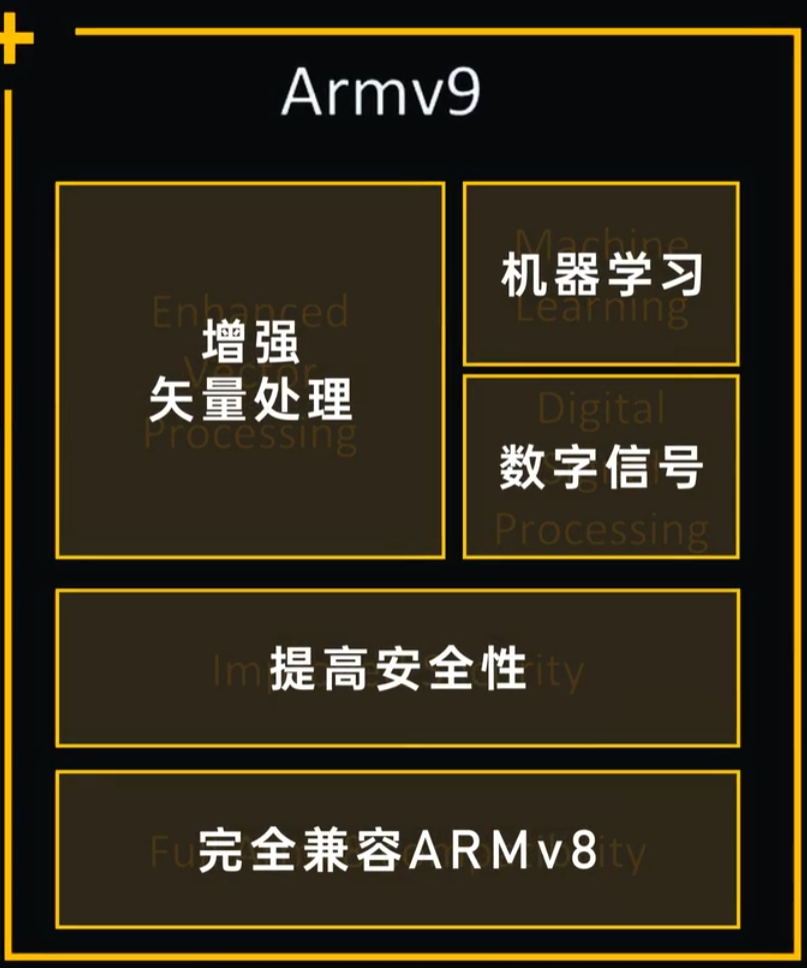
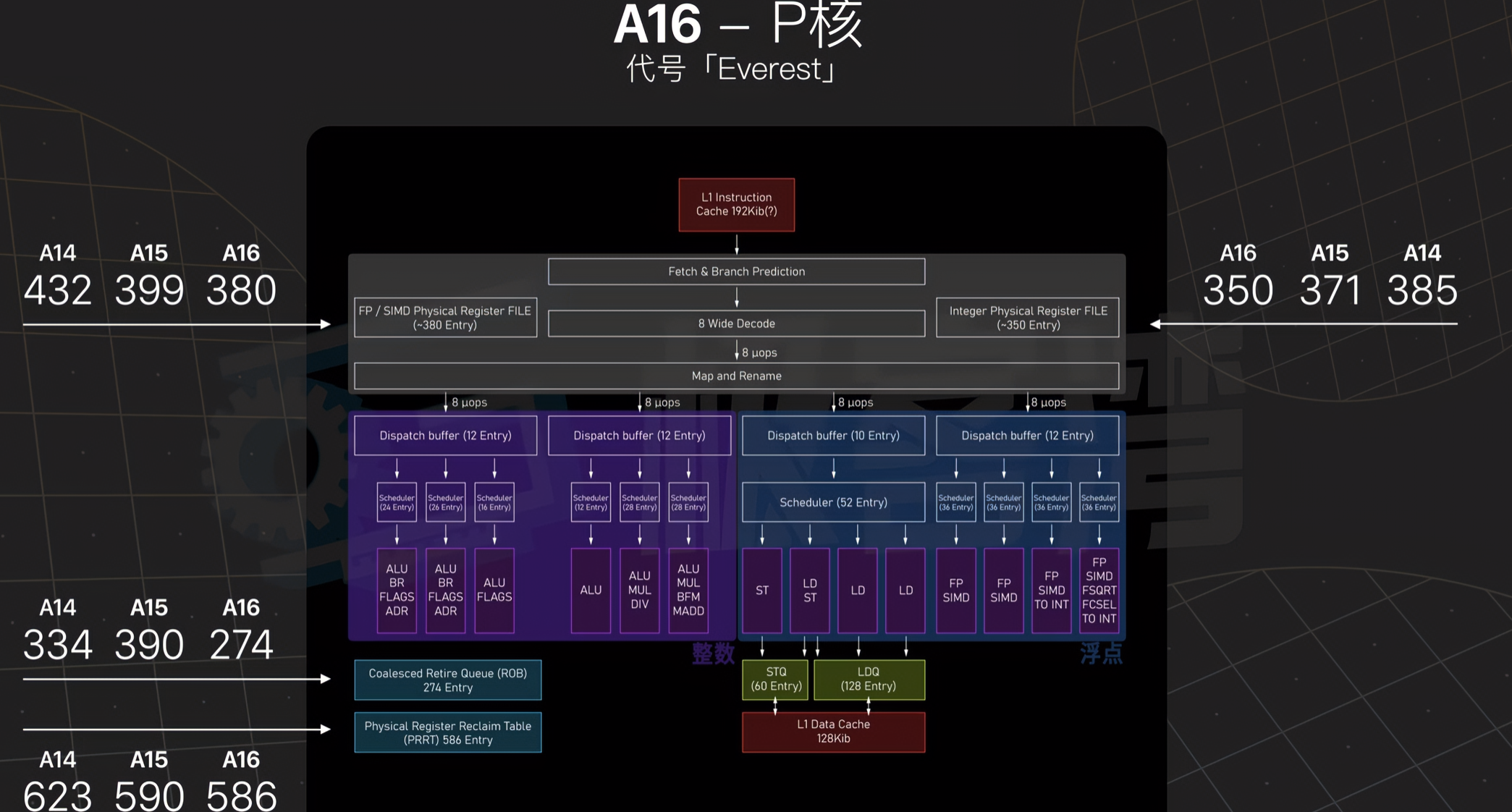
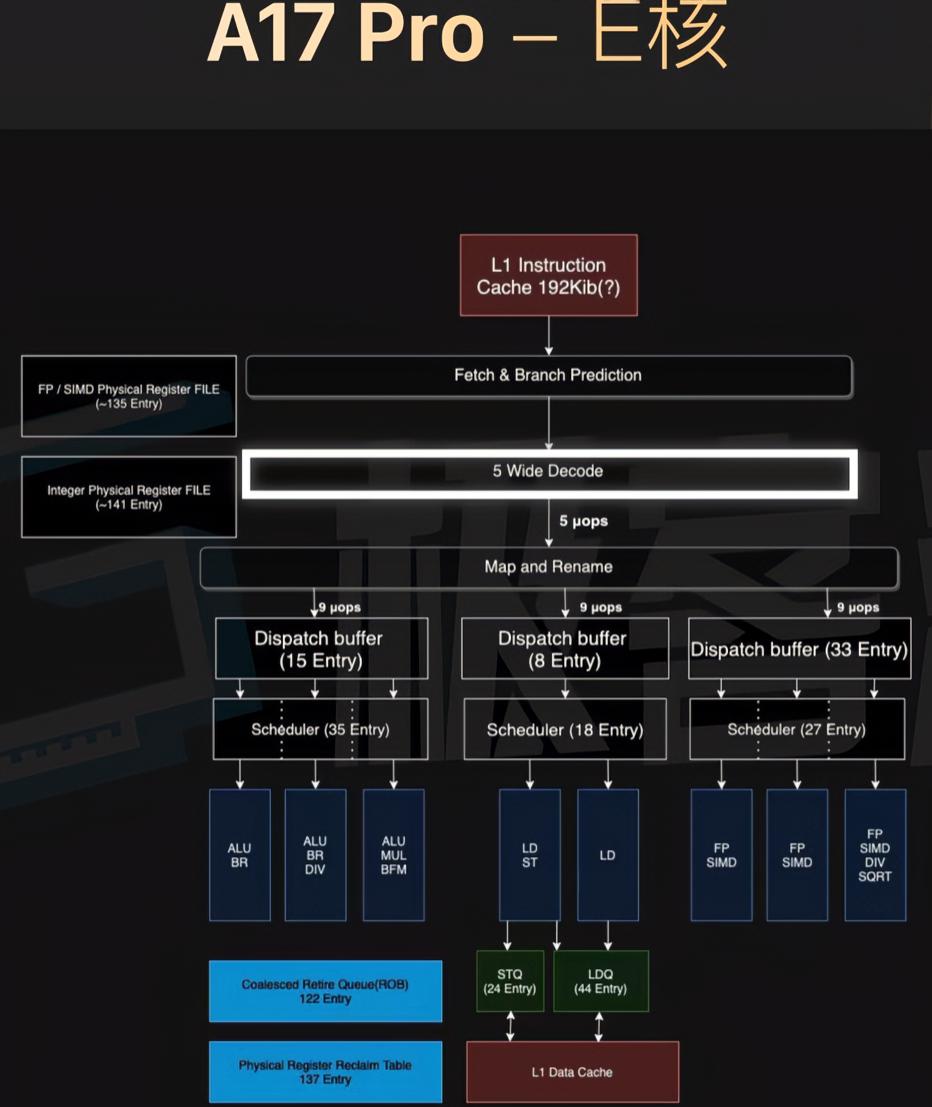
来自极客湾
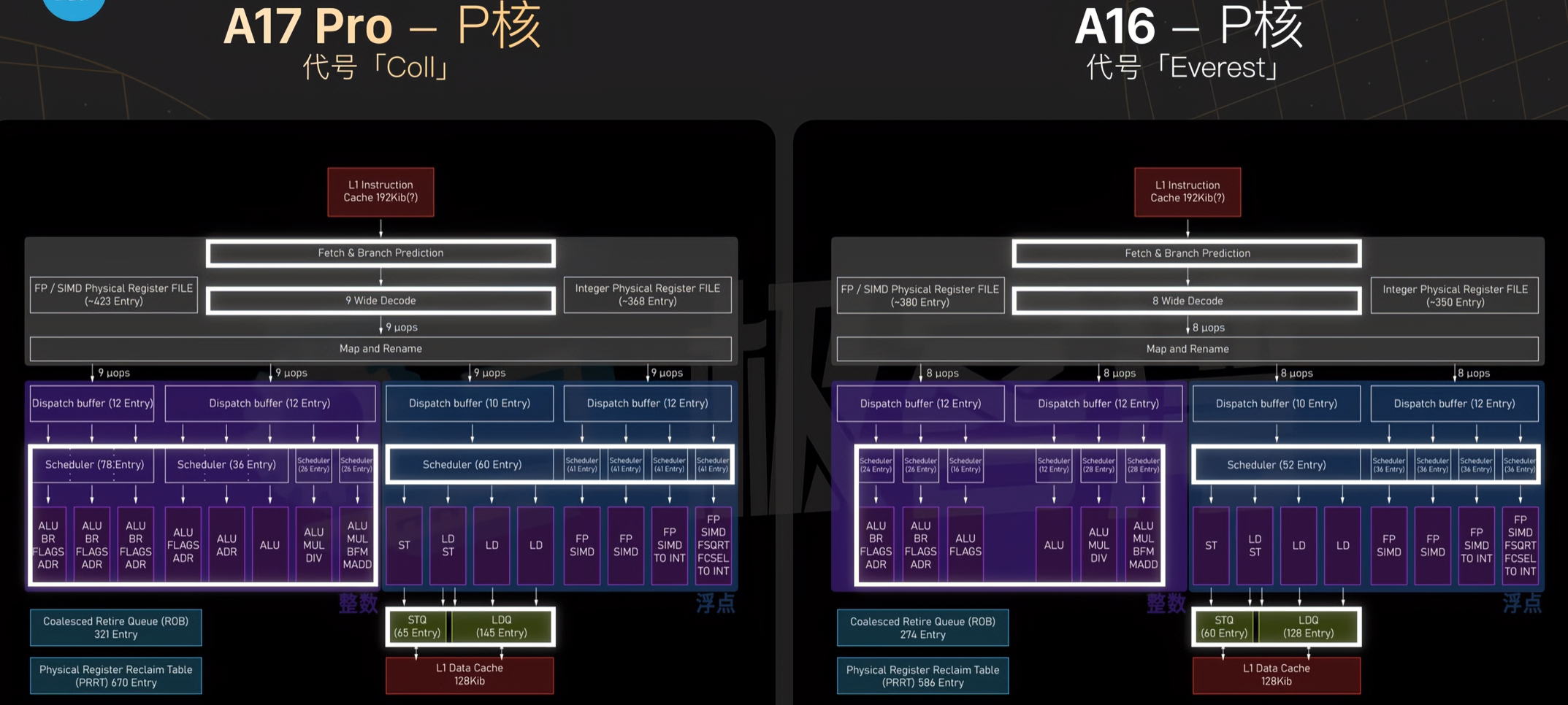
白色部分为加宽的部分
AArch64:AArch64 state只支持A64指令集。这是一个固定长度的指令集,使用32位指令编码。
Arch32:AArch32 state支持以下指令集:
A32:这是一个固定长度的指令集,使用32位指令编码。它是与ARMv7 ARM指令集兼容。
T32:这是一个可变长度指令集,它同时使用16位和32位指令编码。它与ARMv7 Thumb®指令集兼容。
而CISC指令集都是变长的。
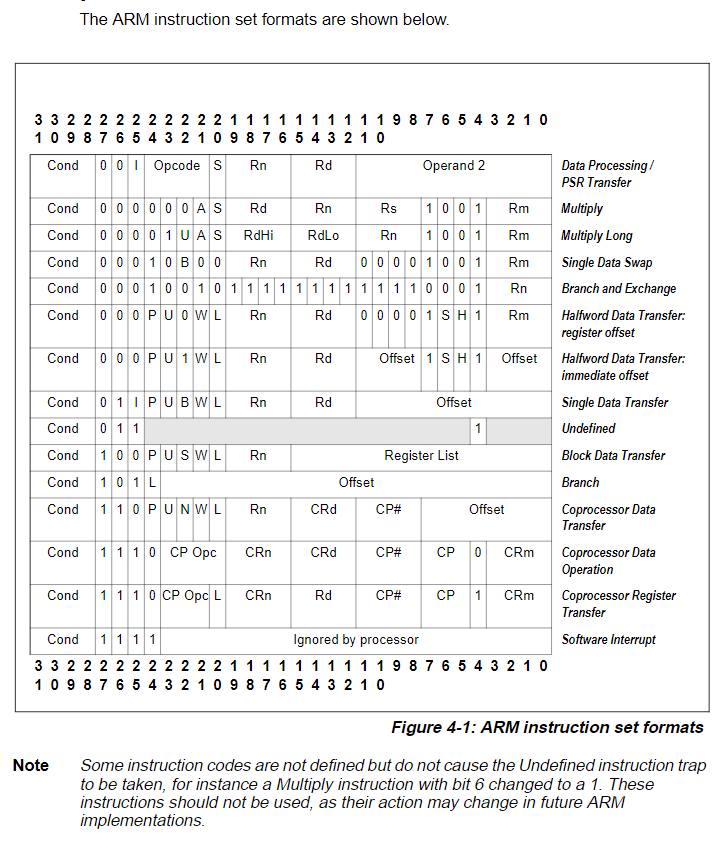
指令长度的范围可以说是相当广泛,从微控制器的4 bit,到VLIW系统的数百bit。在个人电脑,大型机,超级电脑内的处理器,其内部的指令长度介于8到64 bits(在x86处理器结构内,最长的指令长达15 bytes,等于120 bits)。在一个指令集架构内,不同的指令可能会有不同长度。在一些结构,特别是大部分的精简指令集(RISC),指令是固定的长度,长度对应到结构内一个字的大小。在其他结构,长度则是byte的整数倍或是一个halfword。
https://www.eet-china.com/mp/a23067.html
https://winddoing.github.io/post/7190.html
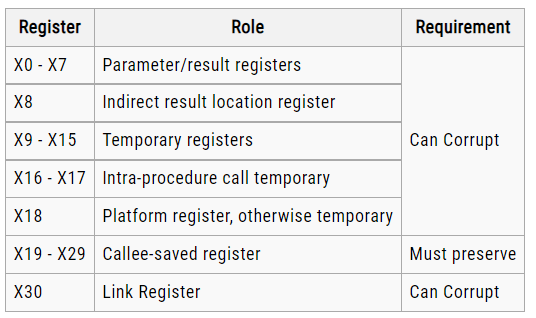
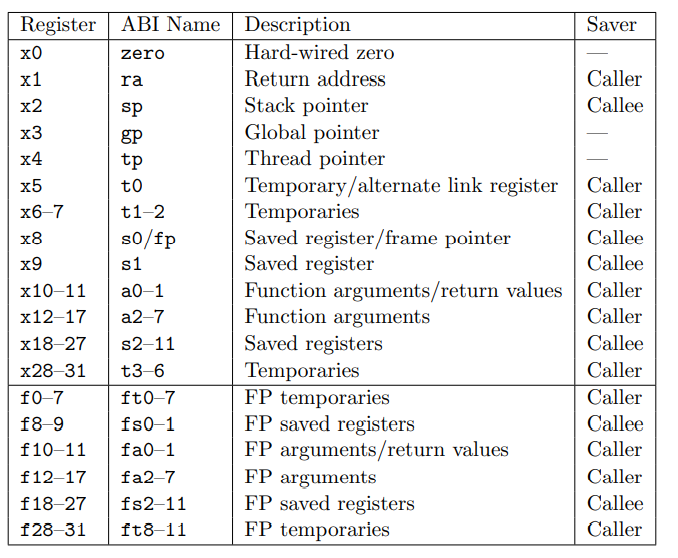
In AArch64 state, the following registers are available:
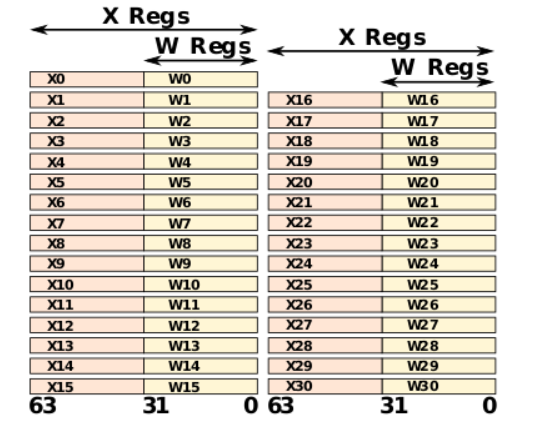
- Thirty-one 64-bit general-purpose registers X0-X30, the bottom halves of which are accessible as W0-W30.
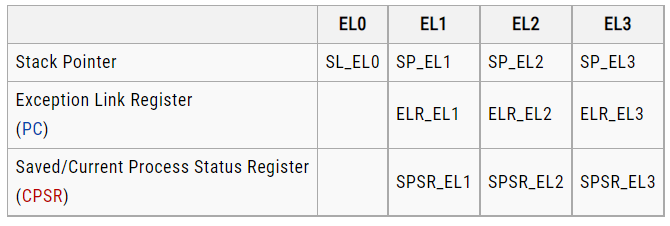
- Four stack pointer registers SP_EL0, SP_EL1, SP_EL2, SP_EL3.
- Three exception link registers ELR_EL1, ELR_EL2, ELR_EL3.
- Three saved program status registers SPSR_EL1, SPSR_EL2, SPSR_EL3.
- One program counter.
 X31 stack pointer
X31 stack pointer
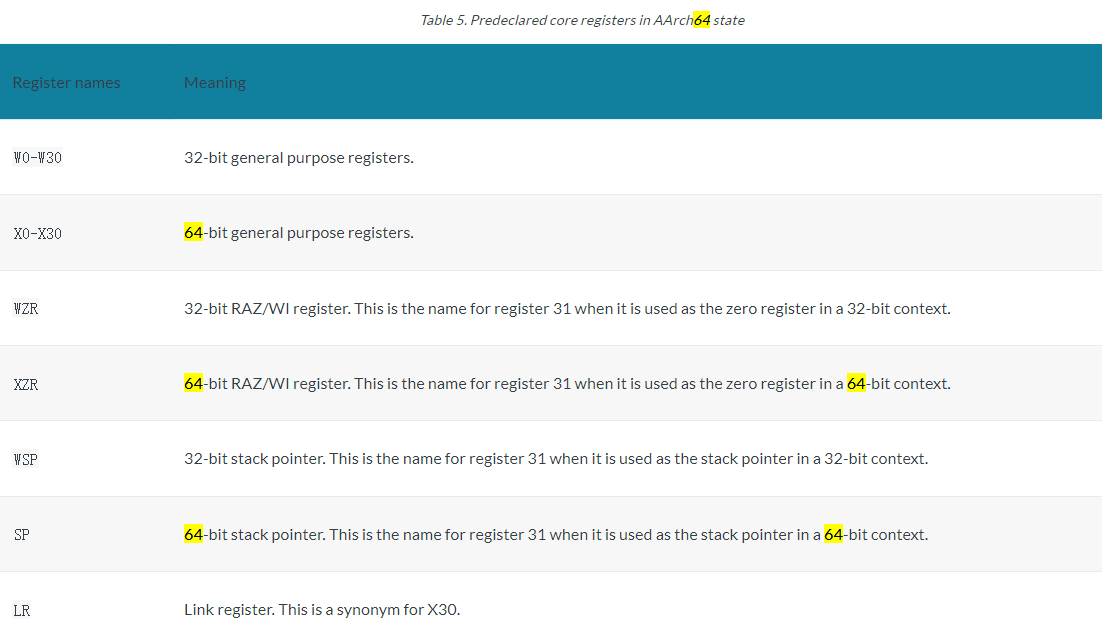
You can write the register names either in all upper case or all lower case.
In AArch64 state, the PC is not a general purpose register and you cannot access it by name.
All these registers are 64 bits wide except SPSR_EL1, SPSR_EL2, and SPSR_EL3, which are 32 bits wide.
Most A64 integer instructions can operate on either 32-bit or 64-bit registers.
The names Wn and Xn, where n is in the range 0-30. W means 32-bit and X means 64-bit.
更具体的细节请看 ARMv8 Instruction Set Overview 4.4.1 General purpose (integer) registers
更具体的细节请看 ARMv8 Instruction Set Overview 4.4.2 FP/SIMD registers 或者 Assembly Arm文章
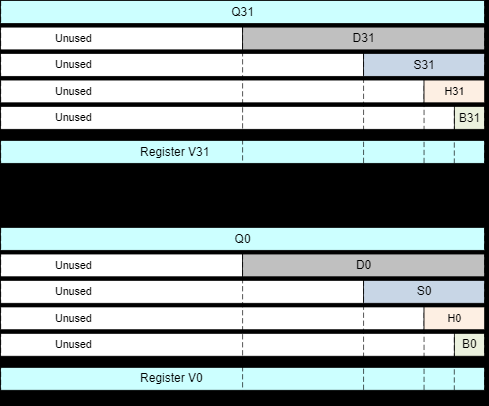
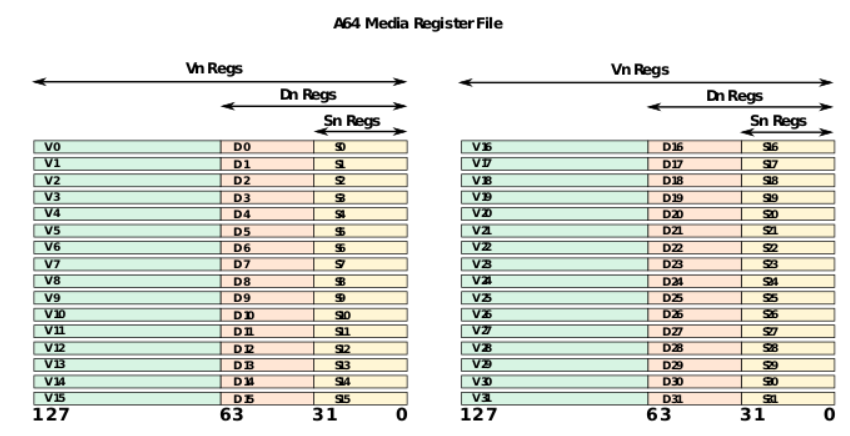
 向量寄存器有32个v0 - v31, 由于表示方法 Qn 也是 128位,所以汇编有时以 %qn出现(n为第几个寄存器)
向量寄存器有32个v0 - v31, 由于表示方法 Qn 也是 128位,所以汇编有时以 %qn出现(n为第几个寄存器)
In all ARM processors in AArch32 state, the following registers are available and accessible in any processor mode:
- 15 general-purpose registers R0-R12, the Stack Pointer (SP), and Link Register (LR).
- 1 Program Counter (PC).
- 1 Application Program Status Register (APSR).
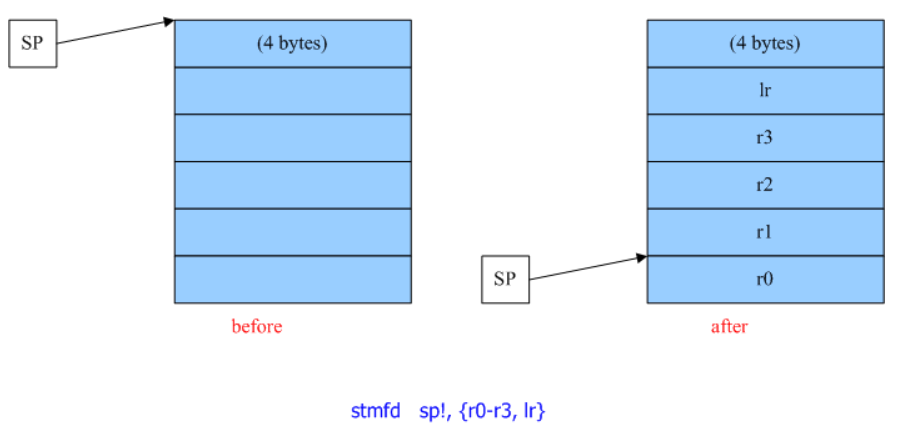
r11是optional的,backtrace时候会启用,被称为FP,即frame pointer。
r12 IP The Intra-Procedure-call scratch register. (可简单的认为暂存SP)
r13 SP The Stack Pointer.
r14 LR The Link Register. 用于保存函数调用的返回地址
r15 PC The Program Counter.
x86的bp寄存器其实有两个功能:
- 指向栈底
- 指向返回地址
arm却把这两个功能拆开了,用两个存,为的就是减少一步访存。
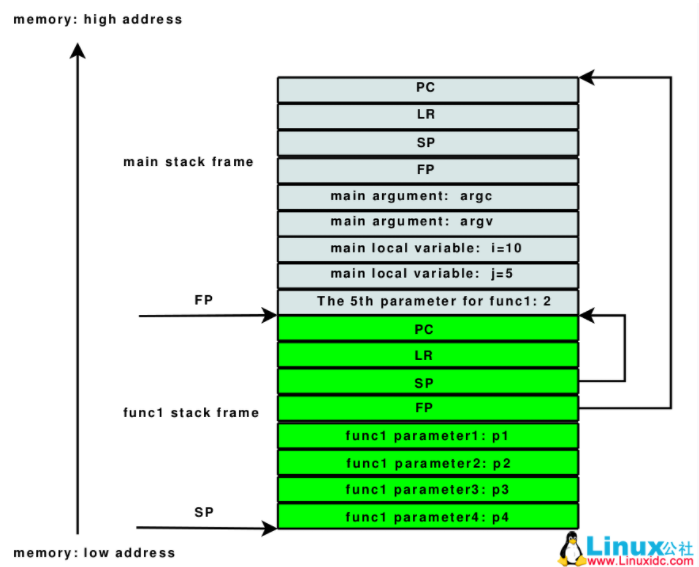
https://blog.csdn.net/tangg555/article/details/62231285
The x86 architecture has 8 General-Purpose Registers (GPR), 6 Segment Registers, 1 Flags Register and an Instruction Pointer. 64-bit x86 has additional registers.

- General-Purpose Registers (GPR) - 16-bit naming conventions
- Accumulator register (AX). Used in arithmetic operations
- Counter register (CX). Used in shift/rotate instructions and loops.
- Data register (DX). Used in arithmetic operations and I/O operations.
- Base register (BX). Used as a pointer to data (located in segment register DS, when in segmented mode).
- Stack Pointer register (SP). Pointer to the top of the stack.
- Stack Base Pointer register (BP). Used to point to the base of the stack.
- Source Index register (SI). Used as a pointer to a source in stream operations.
- Destination Index register (DI). Used as a pointer to a destination in stream operations.
- Segment Registers
- Stack Segment (SS). Pointer to the stack.
- Code Segment (CS). Pointer to the code.
- Data Segment (DS). Pointer to the data.
- Extra Segment (ES). Pointer to extra data ('E' stands for 'Extra').
- F Segment (FS). Pointer to more extra data ('F' comes after 'E').
- G Segment (GS). Pointer to still more extra data ('G' comes after 'F').
- General-Purpose Registers 64-bit
- rax - register a extended
- rbx - register b extended
- rcx - register c extended
- rdx - register d extended
- rbp - register base pointer (start of stack)
- rsp - register stack pointer (current location in stack, growing downwards)
- rsi - register source index (source for data copies)
- rdi - register destination index (destination for data copies)
RIP (EIP)

http://home.ustc.edu.cn/~shaojiemike/posts/simd/#simd%E5%AF%84%E5%AD%98%E5%99%A8
某个寄存器是只读的,存的值一直为0
Most RISC architectures have a “zero register”(WZR/XZR reg31 for ARM) which always reads as zero and cannot be written to.
While the x86/x64 architectures do not have an architectural zero register.
通过zero Idiom :
The register renamer detects certain instructions (xor reg, reg and sub reg, reg and various others) that always zero a register
2019年1月,华为跟进一步发布自研服务器芯片鲲鹏920。该服务器芯片搭载了64颗海思基于ARMv8架构自研的泰山内核。整体服务器性能较市场现有竞品提升20%。2019年5月,华为宣布获得ARMv8架构永久授权,并且强调华为海思有持续自行开发设计基于ARM授权架构的处理器。
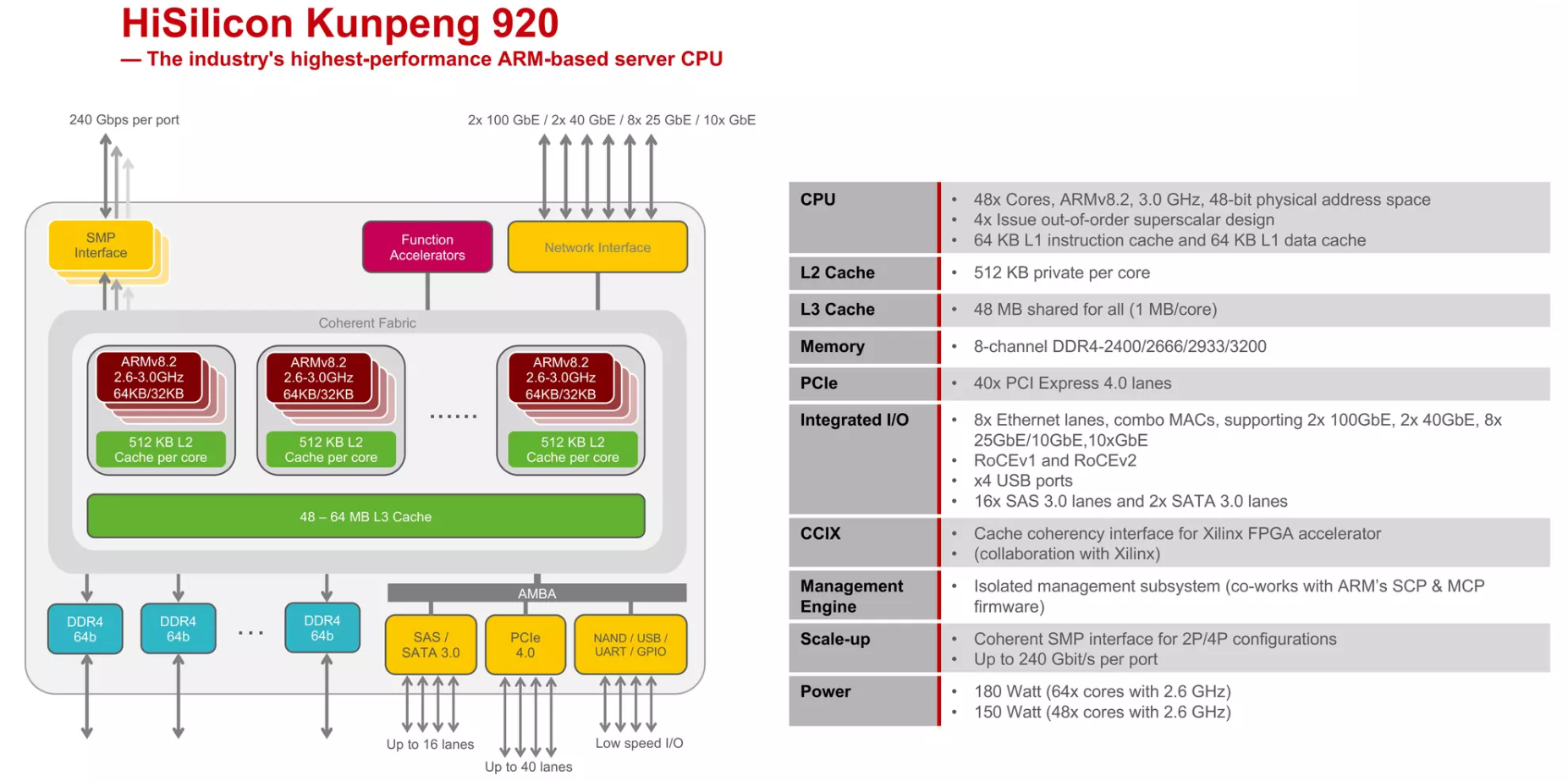
- AMBA(Advanced Microcontroller Bus Architecture)是ARM公司定义的一个总线架构,用来连接不同的功能模块(如CPU核心、内存控制器、I/O端口等)。AMBA是一种开放标准,用于连接和管理集成在SOC(System on Chip)上的各种组件。它是为了高带宽和低延迟的内部通信而设计的,确保不同组件之间的高效数据传输。
- ARM的SCP和MCP固件(System Control Processor & Management Control Processor firmware)则是指ARM提供的用于系统控制处理器和管理控制处理器的固件。这些固件通常负责处理系统管理任务,例如电源管理、系统启动和监控、安全性管理等。SCP和MCP是ARM架构中用于系统级管理和控制的专门处理器或子系统。
wikiChip https://en.wikichip.org/wiki/hisilicon/microarchitectures/taishan_v110
Architecture: aarch64
CPU op-mode(s): 64-bit
Byte Order: Little Endian
CPU(s): 96
On-line CPU(s) list: 0-95
Thread(s) per core: 1
Core(s) per socket: 48
Socket(s): 2
NUMA node(s): 4
Vendor ID: 0x48
Model: 0
Stepping: 0x1
CPU max MHz: 2600.0000
CPU min MHz: 200.0000
BogoMIPS: 200.00
L1d cache: 6 MiB
L1i cache: 6 MiB
L2 cache: 48 MiB
L3 cache: 192 MiB
NUMA node0 CPU(s): 0-23
NUMA node1 CPU(s): 24-47
NUMA node2 CPU(s): 48-71
NUMA node3 CPU(s): 72-95
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Spec store bypass: Not affected
Vulnerability Spectre v1: Mitigation; __user pointer sanitization
Vulnerability Spectre v2: Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid asimdrdm j
scvt fcma dcpop asimddp asimdfhm
鲲鹏920明显的几个特点,96个核,4个NUMA node, cache相较于Intel特别大
暂无
暂无
致谢ARM、驭势资本、EETOP...等原编著者,来源华为云社区
https://bbs.huaweicloud.com/blogs/262835
https://developer.arm.com/documentation
RIP register
https://stackoverflow.com/questions/42215105/understanding-rip-register-in-intel-assembly






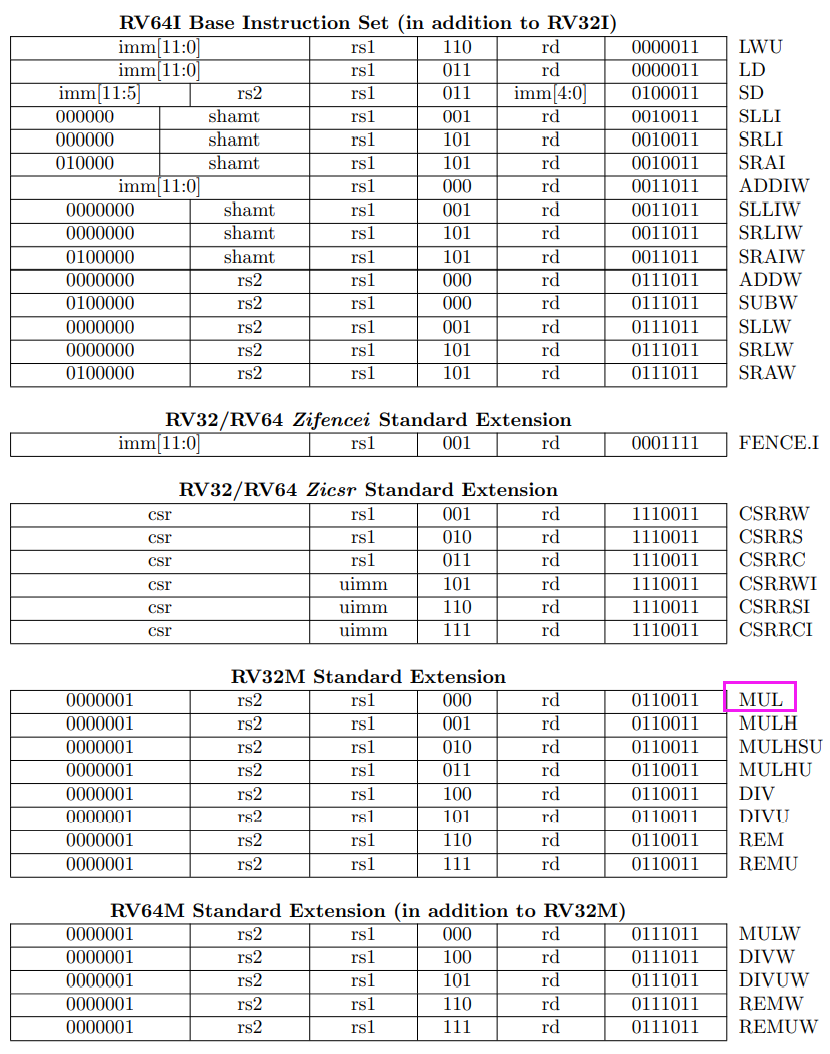
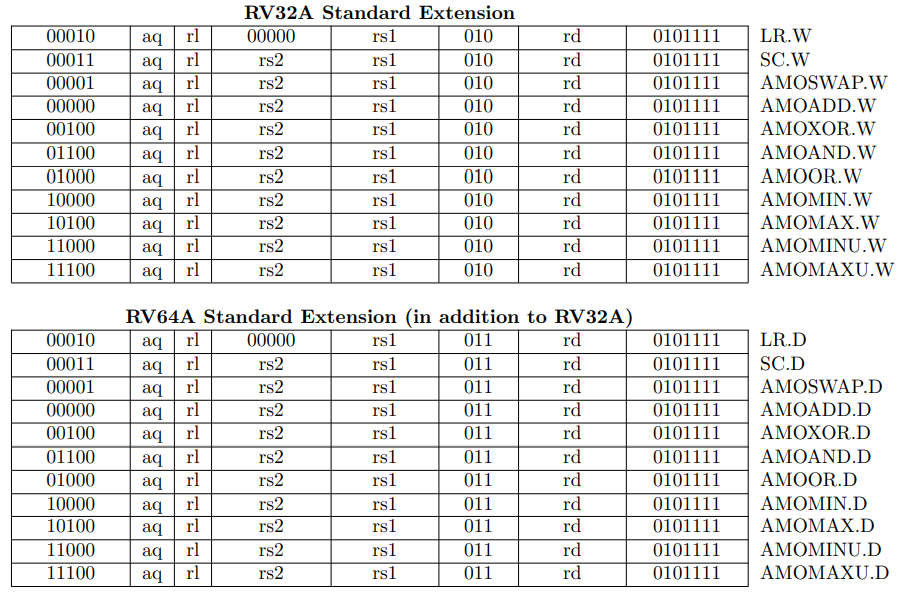
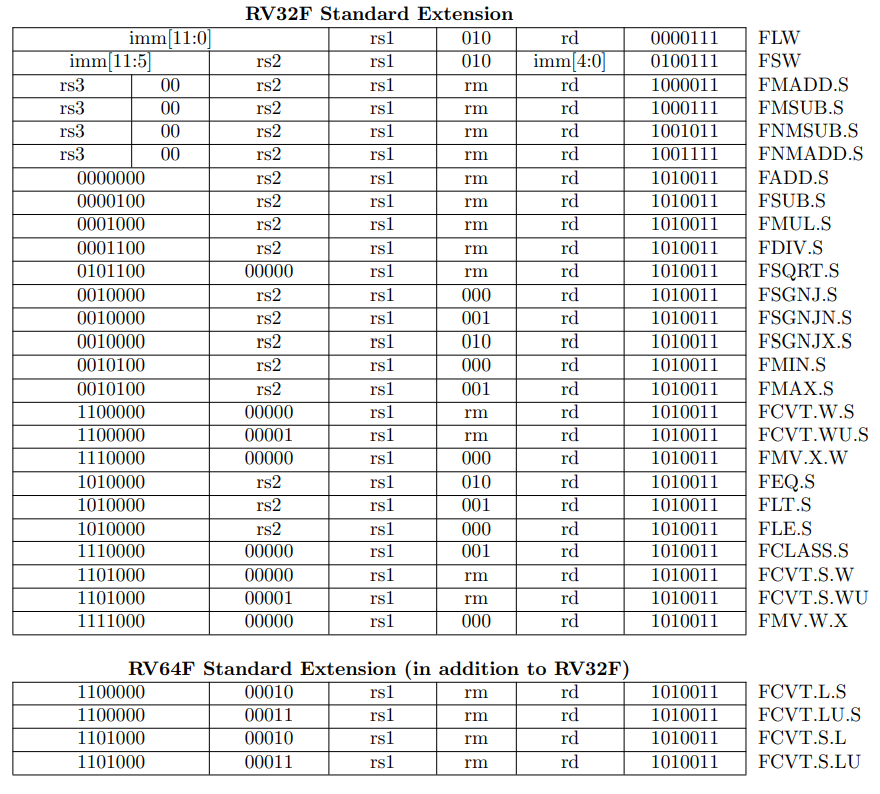
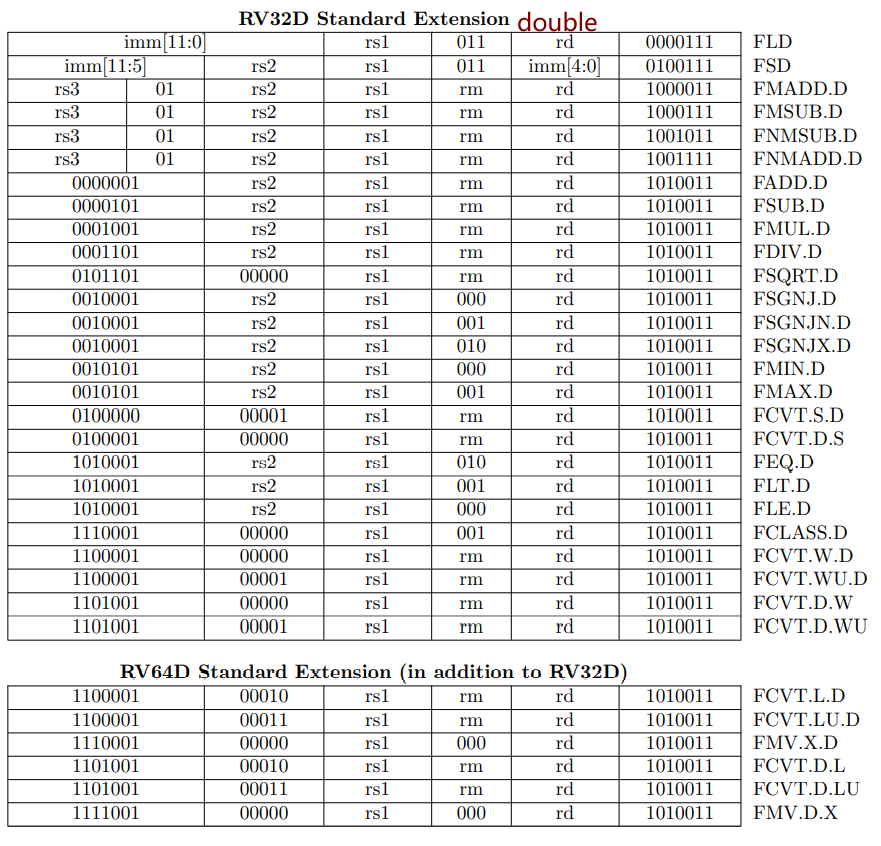
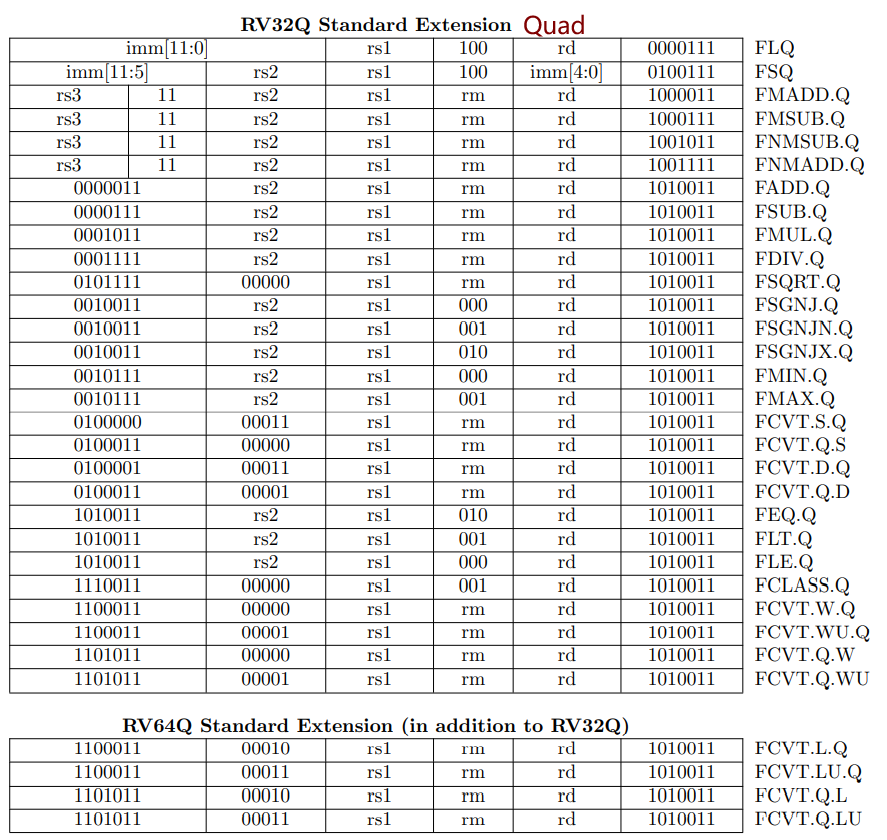


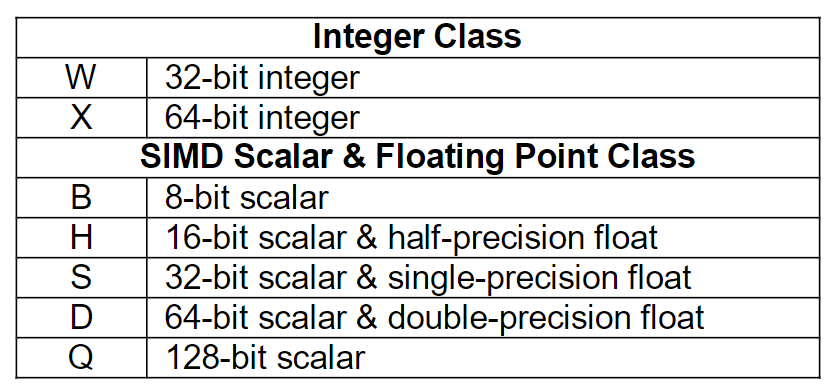
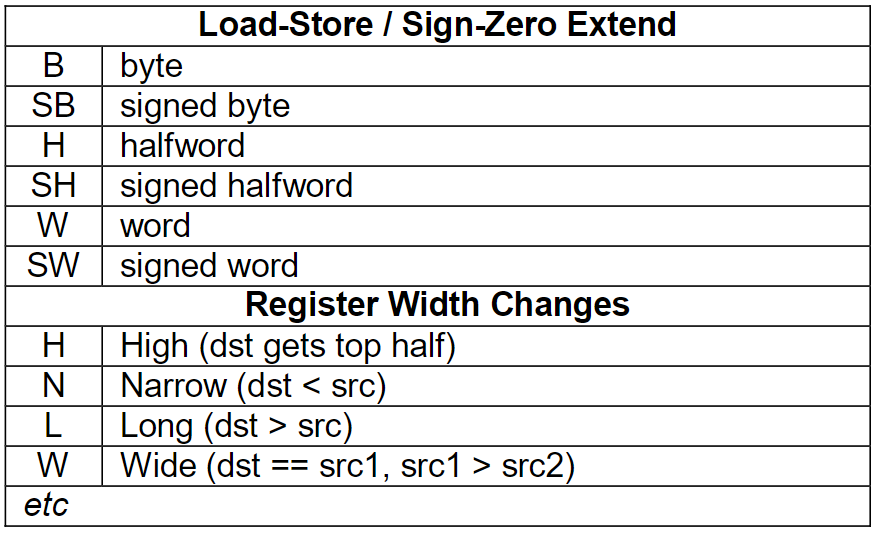
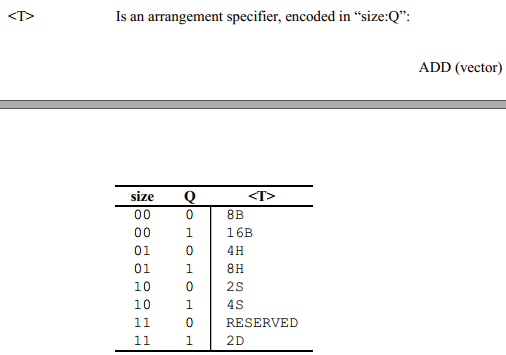


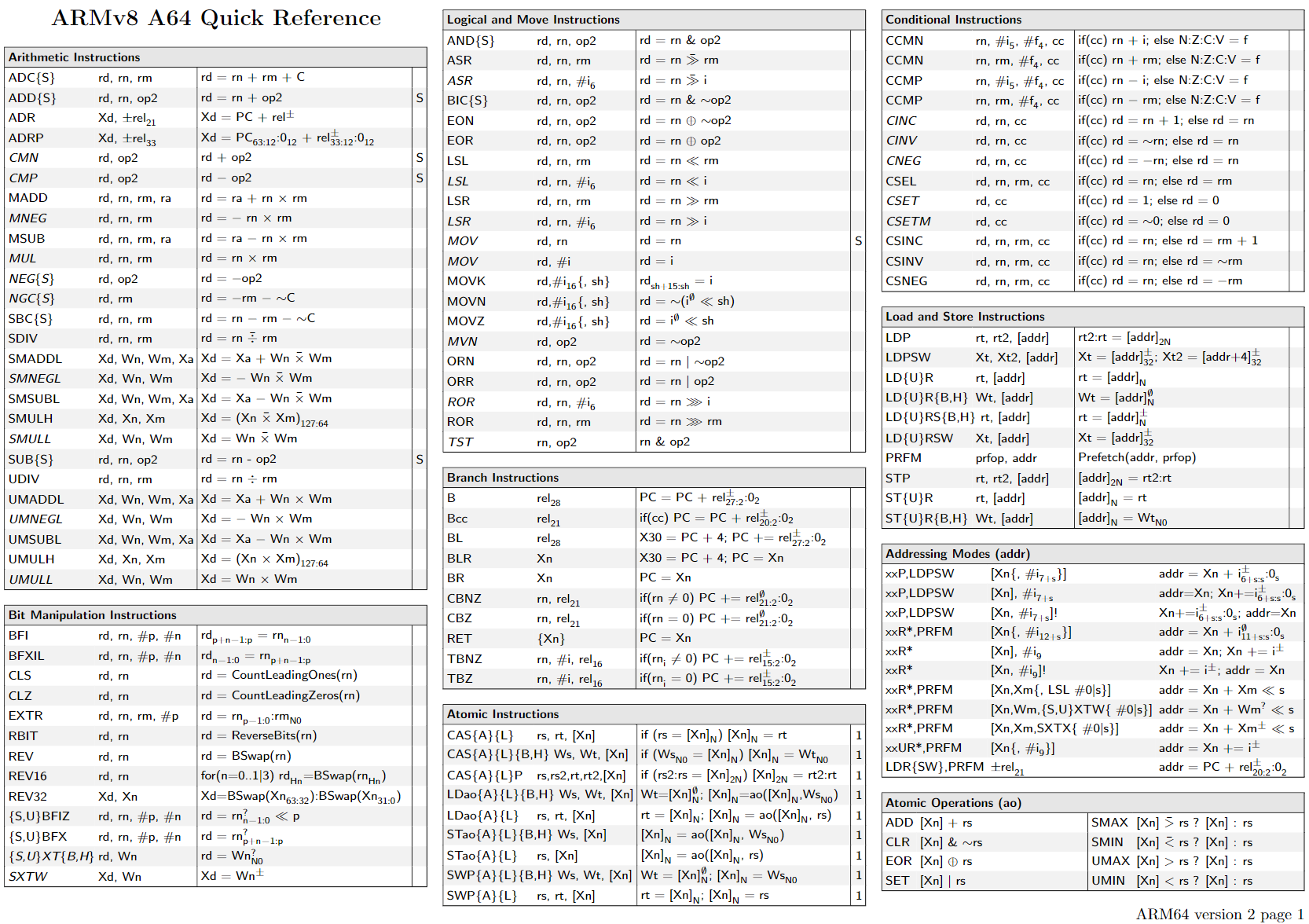


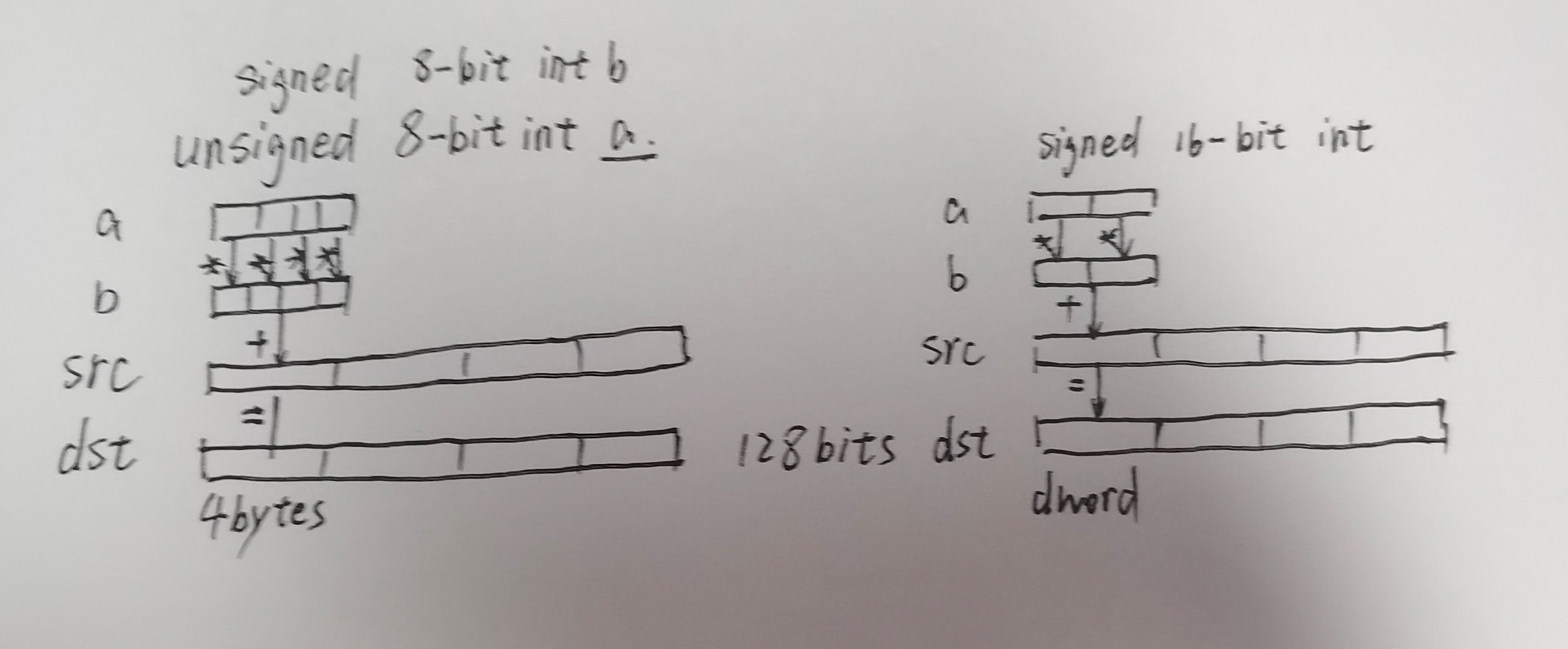
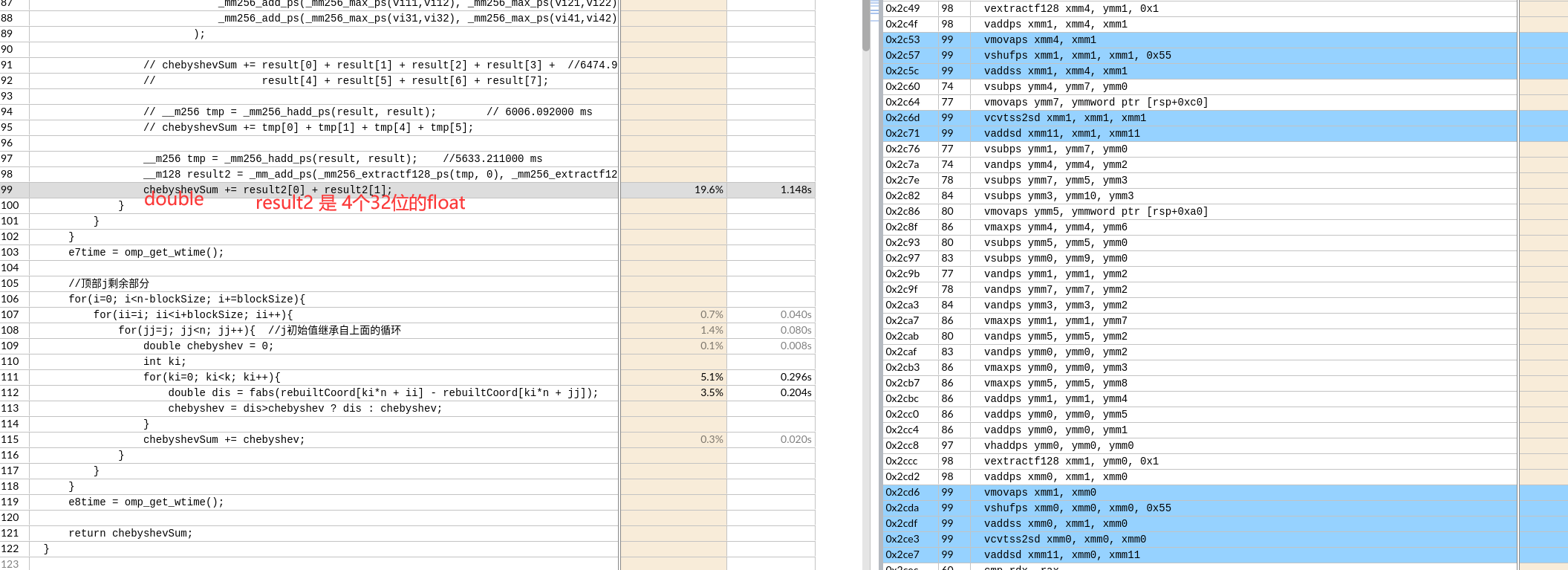
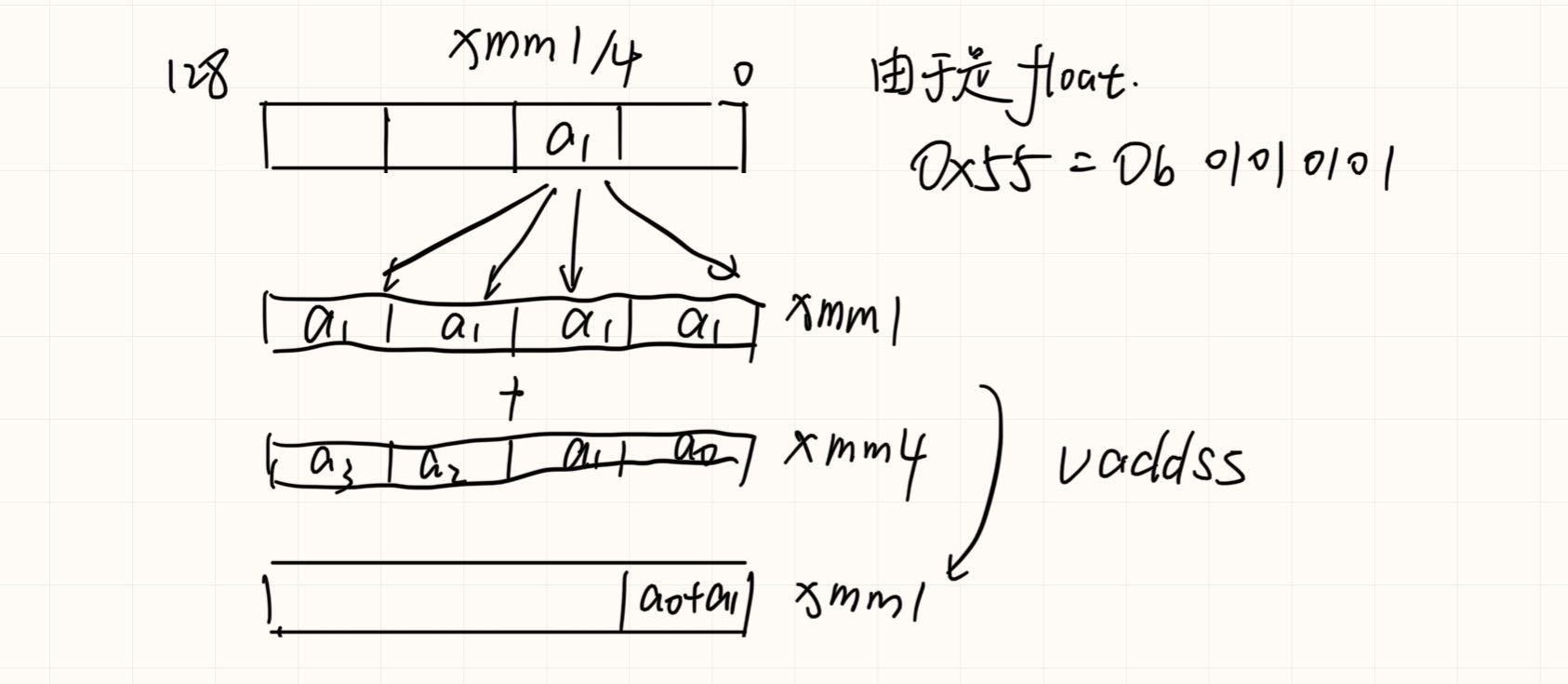 之后float类型转换为double,再求和。
之后float类型转换为double,再求和。