CPU / GPU Performance Model based on Interval Analysis
导言
在与袁福焱交流他的GPU Design Space Exploration的工作内容时,发现和我PIM模拟器Zsim, Sniper的原理是异曲同工,师出本源的方法。
简介¶
虽然这些模拟器不是cycle-accuracy的,但是最终误差距离cycle-accuracy竟然只有10%3
Interval analysis¶
Interval analysis is a relatively accurate performance modeling technique, which traverses the instruction trace and uses functional simulators, e.g., cache simulator, to track the stall events that cause performance loss.1
high Speed and better accuracy: It shows hundred times(97x) of speedup compared to detailed timing simulations and better accuracy compared to pure analytical models.1
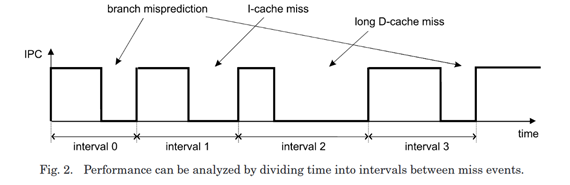
Interval Model on CPU¶
CPU Model¶
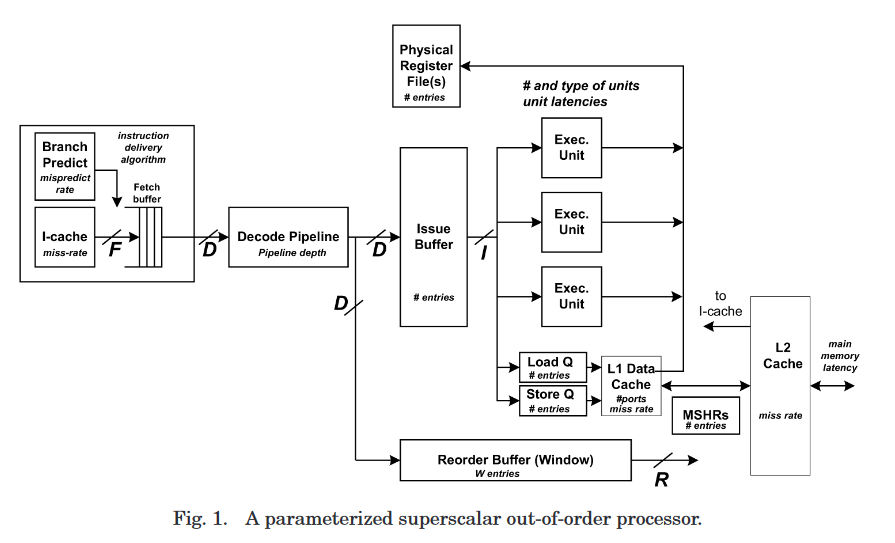
- fetch width
F, dispatch widthD, issue widthI, and retire widthR. ROB window sizeW - It is assumed that the front-end decode and rename pipeline stages match the dispatch width
D
Balanced Processor¶
Balanced Processor: OOO处理器如果对于给定的dispatch width D, ROB(window size)和其他资源(如the issue buffer(s), load/store buffers, rename registers, MSHRs, functional units, write buffers,等)的大小足以在没有miss event的情况下实现每个周期D条指令的持续处理器性能。
重点在于平衡:
- 其他资源(Buffer)变小,就吃不满dispatch width
D的带宽。 - 其他资源(Buffer)增大,也无法跨越dispatch width
D的限制。
既然dispatch width往往是瓶颈,为什么不做大呢?
能问出这个问题,说明没有理解balanced的概念。dispatch width要增大,前端后端的设计都要变大,电路变复杂。
- 复杂性和功耗:需要更多的执行单元、更大的调度队列和更复杂的逻辑来处理这些指令。这不仅增加了处理器的设计复杂性,也会导致更高的功耗和热输出。
- 指令级并行度的局限性:程序的指令流中并不总是存在足够的独立指令来充分利用更宽的带宽。这意味着即使有更宽的带宽,处理器也可能无法始终填满这个带宽,因为指令之间的依赖关系限制了它们可以并行执行的程度。
- 维持处理器频率:随着带宽的增加,处理器的每个周期内的工作量也会增加。这可能导致难以维持高处理器频率,因为更大的带宽可能需要更长的时钟周期来完成工作。
- 设计和成本权衡:处理器设计是一种平衡艺术,设计师必须在性能、成本、能耗、热设计功率(TDP)和市场需求之间权衡。更宽的带宽可能会导致成本增加,而这可能不符合市场需求或目标应用场景。
Machine Balance¶
这与 95 年的计算访存的一个概念有些相似:7
应用在app kernel 就是 compute indensity.
formula¶
- N : instruction number
- D : Dispatch width - refers to the movement of instructions from the front-end pipeline into the reorder and issue buffers.5
- 发射(dispatch)到执行单元并执行的整个过程
- 在大部分CPU里,D都是最小宽度,F>D, I>D 。有时也叫
processor width
Issue Width vs Dispatch Width vs Commit/Squash Width
Issue Width: How many instructions can be pushed by decode into execute (EX) stage. Typically limited by size of issue queue (IQ) (in EX, instructions are first pushed into IQ and then "dispatched" to ALUs/Functional-Units for "real" execution)6 Issue Width:有多少指令可以被decode推入execute(EX)阶段。通常受发布队列(IQ)的大小限制(在EX中,指令首先被推入IQ,然后“分派”到ALU/功能单元以进行“真实的”执行)
Dispatch Width: How many instructions can move from IQ to ALUs/FUs. Limited by the number of ALUs/FUs, or how much of the IQ we read/cycle. 调度宽度:有多少指令可以从IQ移动到ALU/FU。受限于ALU/FU的数量,或者我们读取/循环的IQ的多少。
Commit/Squash Width: How many instructions are committed/squashed per cycle. GEM5 seems to be modelling bandwidth requirements that are associated with commit/squash per cycle (typically it involves removing entries from ROB and adjusting rename tables) 提交/压缩宽度:每个周期提交/压缩多少条指令。GEM 5似乎正在建模与每个周期的提交/压缩相关的带宽需求(通常涉及从ROB中删除条目并调整重命名表)
Dispatch Inefficiency.¶
ceiling function + “edge effect”:
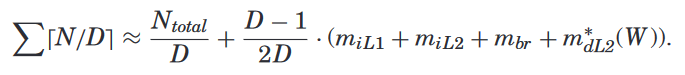
Putting It Together: The Overall Model.¶
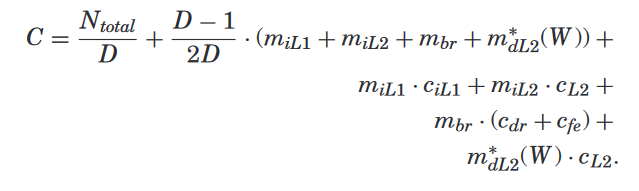
Example¶
Short Back-End Miss Events¶
- L1 D-cache miss
- miss latency can be hidden by out-of-order execution
Long Back-End Miss Events.¶
- miss from the L2 cache to main memory,
- 长延迟会依次导致:
- ROB fill
- dispatch stalls
- issue and commit cease
-
miss data 读取到之后,依次发生:
- ROB unlocked
- dispatch resumes
-
导致
load miss的指令,要依次- 先fetch到
decode buffer。 - 再dispatch到
issue buffer - 最后issue到
load unit,来访问memory
- 先fetch到
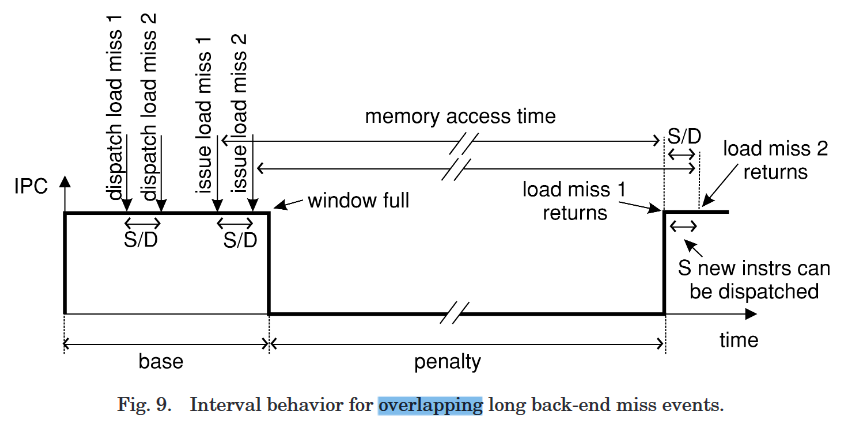
Interval Model on GPU¶
Baseline¶
Penalty 1 : Sub-core model¶
Consider Warp Switch to hide latency1 2
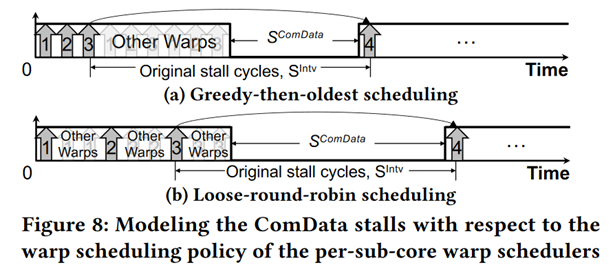
Penalty 2 : Intra-SM Contention¶
FU, L1 bank limited 3
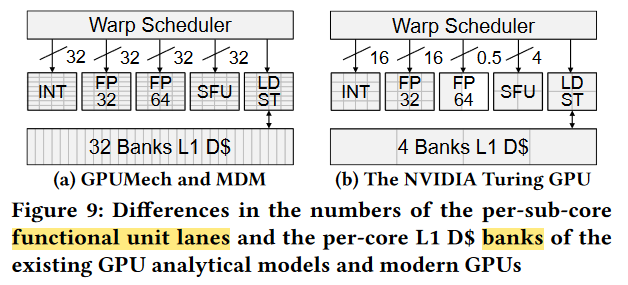
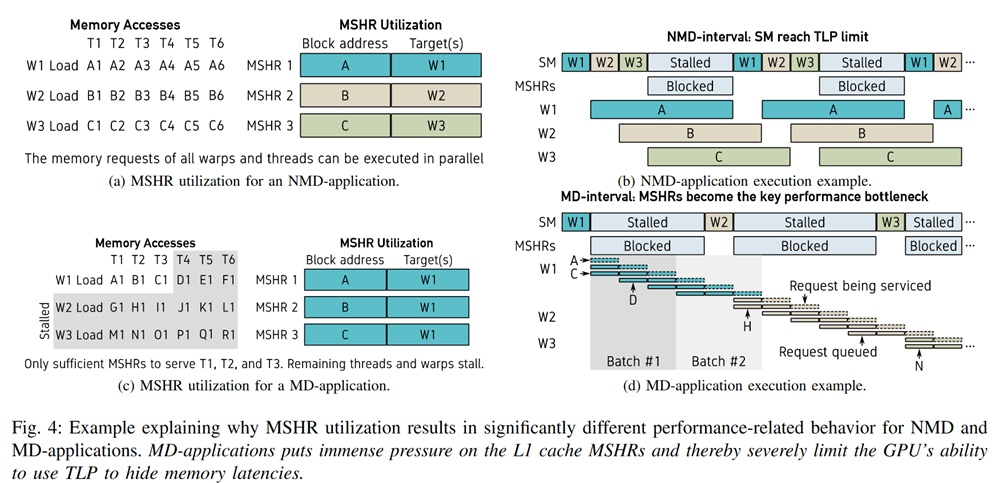
Penalty 3 : Memory contention¶
memory divergence,L1 MSHR Full,NoC, DRAM queue2
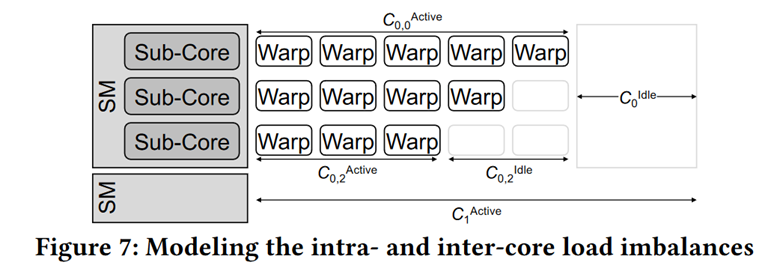
Penalty 4 : SM Load Imbalance¶
Some Warp fast, some slow.3
CPU vs GPU model¶
Mechanistic Performance Model 是根据物理设计结构来模拟的。
由于GPU的sub-core(warp-scheduler)相对于CPU简单,所以能用公式抽象出来:
- base IPC = 1,Don’t consider frontend stall
- In-order execute
读论文时的疑问,需要回答的问题¶
GPUMech¶
- 之前的GPU performance model 聚焦于 应用优化,而不是 DSE。这些分析模型的不同
- CPU的Interval Model和GPU的有何不同,两者的区别?
- CPU侧的几个假设: 1. Under optimal conditions (no miss events), the processor sustains a level of performance more-or-less equal to its pipeline front-end dispatch width 2. front-end pipeline , the reorder buffer and issue queues.
研究路径分叉点¶
Analytical Model¶
- CPU
- (JPDC91) An analytical approach to performance/cost modeling of parallel computers.
- (MICRO94)Theoretical modeling of superscalar processor performance.
- (HPCA09) A First-Order Fine-Grained Multithreaded Throughput Model
- GPU
- (ISCA ’09.) An analytical model for a GPU architecture with memory-level and thread-level parallelism awareness.
- (PPoPP10) An adaptive performance modeling tool for gpu architectures.
- (HPCA ’11) A quantitative performance analysis model for GPU architectures.
- (PPoPP ’12) A performance analysis framework for identifying potential benefits in GPGPU applications.
CPU侧¶
- KARKHANIS,T.,AND SMITH的5篇 interval analysis 相关的文章
- (ISCA04) A first-order superscalar processor model.
- (ASPLOS’06) A performance counter architecture for computing accurate CPI components
- (ISPASS06) Characterizing the branch misprediction penalty.
- (ISCA07) Automated design of application specific superscalar processors: an analytical approach
- (TOCS09) A mechanistic performance model for superscalar out-of-order processors
- (HPCA10)Interval Simulation
GPU侧¶
- (ISCA04) A first-order superscalar processor model.
- (TOCS09) A mechanistic performance model for superscalar out-of-order processors.
- GPUMech1
Recent Model¶
- GPU
- (PPoPP18) POSTER: A Microbenchmark to Study GPU Performance Models
- (PPoPP18) POSTER: Performance Modeling for GPUs using Abstract Kernel Emulation
- (ISCA19) MGPUSim: Enabling Multi-GPU Performance Modeling and Optimization
- more
- Interval 确实没有顶会了除了前面23
参考文献¶
-
(MICRO14) GPUMech: GPU Performance Modeling Technique based on Interval Analysis ↩↩↩↩
-
(MICRO20) MDM: The GPU Memory Divergence Model ↩↩↩
-
(ISCA22) GCoM: A Detailed GPU Core Model for Accurate Analytical Modeling of Modern GPUs ↩↩↩↩
-
(ISCA04) A first-order superscalar processor model. ↩
-
(TOCS09) A mechanistic performance model for superscalar out-of-order processors ↩↩
-
(1995) Memory bandwidth and machine balance in high performance computers ↩