New Generation Shenwei System
神威超算系统 与 申威众核处理器¶
神威超算系统¶
神威系列超级计算机作为国家重点支持研发的超算系统,多次获得世界超 算排名第一,自研制以来一直与国家科技自强紧密连在一起,不仅成为国家科 技水平和创新能力的重要标志,也是支撑国防建设、产业转型升级和推动经济 社会发展不可替代的大国重器。
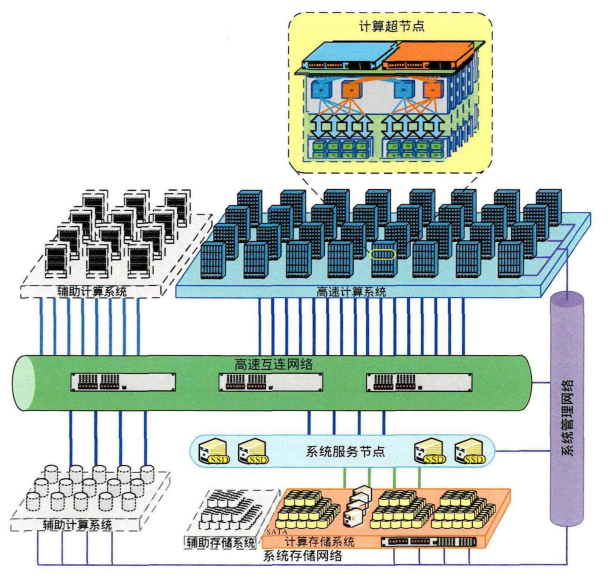
高速计算系统有72个计算机柜,每个机柜内
有4个超节点,每个超节点包含256个计算节点,计算节点即为新一代申威众
核处理器。因此系统共由73728块申威处理器构成,访存总带宽为4473.2TB/s,
峰值运算性能1.3 EFLOPS,持续运算性能1.05 EFLOPS。1
申威众核处理器¶
新一代申威异构众核处理器完全由我国自主研发设计,采用高效可扩展的 异构众核架构。
如图所示,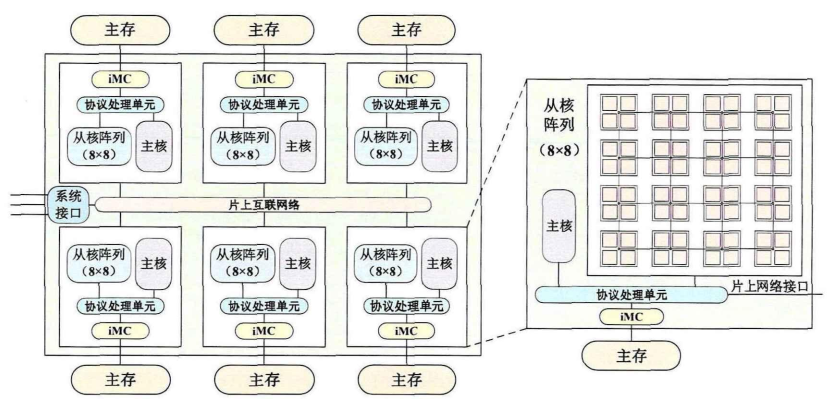
- 申威处理器由环形网络(Network On Chip,NoC)连接的6个核组构成,其物理空间统一编址,支持核组间的Cache一致性。
- 每个核组包含1个主核(控制核心)和64个从核(运算核心),均采用64位申威指令集,并通过主存控制器(Memory Controller,MC)共享
16GBDDR4内存。
主从核参数¶
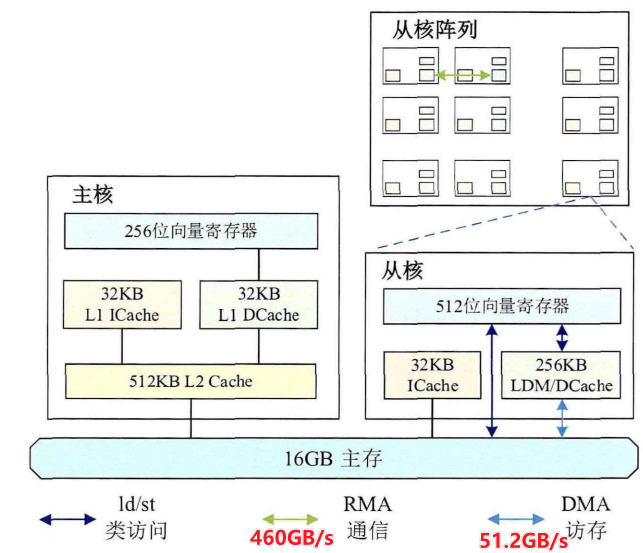
- 主核负责任务调度,工作频率为
2.lGHz,L1指令Cache和L1数据Cache空间均为32KB,L2混合Cache空间为512KB,支持256位向量指令扩展。 - 主核支持完整中断、内存管理和乱序执行,主要用于任务分配和调度、数据通信和I/O以及从核不擅长的小规模稀疏问题处理
-
主核通过对从核任务的调度管理可以最大程度实现全核组的协同并行。
-
从核负责稠密计算,工作频率为
2.25GHz,指令Cache空间为32KB,采用64个64位的统一结构寄存器,由整数执行部件和浮点执行部件共享,其中32个寄存器支持512位向量指令扩展。 - 处理器从核阵列的设计初衷是尽量简化微架构设计,使有限的芯片面积集成更多的计算核心,因此从核并没有采用通用处理器的多级Cache方案,而是每个从核配备了
256KB的局部存储器(Local Data Memory,LDM)。- LDM可配置为软件显式管理(Scratch Pad Memory,SPM)或硬件自动管理(Data Cache,.DCache),其中硬件管理支持0KB、32KB和128KB三档空间配置,Cache行大小为256字节。硬件管理简单方便,但缺乏对程序的针对性优化,性能欠佳。而软件管理保证了从核对LDM的访问总是命中,有利于充分利用存储空间,但同时也给用户编程带来巨大挑战。
片上存储器 层次结构 和 通信互联方式¶
- 与上一代处理器不同的是,新一代申威处理器的从核阵列以簇为单位组织,
64个从核以8X8的CMesh(Concentrated Mesh)网络方式构成从核阵列,从核之间和从核与外部之间通过阵列内网络互连。 4个邻近从核共享从核簇管理部件和路由器,簇管理部件主要负责阵列内网络的数据交互和流量控制,同时集成了用于批量访存的DMA引擎和从核间批量通信的RMA引擎(见前图)。
从核与主存的数据传输: gld/gst¶
- 从核计算时可以通过全局访问指令(Global Load,gld/Global Store,gst)直接访问主存。
- 全局访问指从核通过gld/gst指令直接将主存中数据读入寄存器或将寄存器中数据写入主存,此方式操作简便,数据无需经过LDM暂存即可直接参与计算。
- 但基准测试显示gd/gt指令的延迟很高,达到上百节拍数,在密集访存时一般不作考虑。
从核与主存的数据传输: DMA¶
- 从核计算时也可以通过直接存储访问(Direct Memory Access,DMA)批量访问主存.
- DMA指从核LDM和主存之间的批量数据传输,其理论访存带宽可达
51.2GB/s。实际使用时,在DMA数据传输量为1024字节倍数时即可达到80%的带宽利用率,此时全核组读取带宽为44.94GB/s,写入带宽为41.35GB/s。
DMA支持功能细节
- DMA只能由从核发起请求,分为单播、行多播和列多播模式,且支持阻塞和非阻塞形式。
- DMA接口主要有读、写、广播、行广播和列广播。单播模式支持读和写操作,但行广播、列广播和广播模式只支持读操作,并提供集合方式接口。
- DMA所有的数据地址和长度都必须为4字节的整数倍,即要求4字节对齐。但DMA引擎会把单条DMA请求拆分成以128字节为单位的多次请求,非128字节对齐的DMA操作会产生更多请求。因此DMA传输在主存地址为128字节对齐,且传输量为128字节倍数的时候能更好地发挥其性能优势。
- 此外,DMA还支持跨步传输,即按照一定跨步间隔连续访问主存,其中跨步间隔大小固定。跨步DMA提供了编程上的更多可能,借助跨步DMA可以访问不连续的主存数据。
从核LDM之间的数据传输: RMA¶
- RMA指从核阵列内各从核LDM之间的远程数据传输,由单个从核主动发起请求,其他从核通过判断回答字的值确定操作是否完成。
- RMA的最大通信带宽为
460GB/S,明显高于DMA带宽,因此从核可以通过RMA与其他从核进行数据交换,以增大片上数据重用,降低对主存数据的需求。
RMA支持功能细节
- RMA支持单播、行多播和列多播模式,且支持阻塞和非阻塞形式。
- RMA接口主要有读、写、广播、行广播、行多播、列广播和列多播,其中行广播、列广播和广播可提供集合方式接口。
- RMA所有的数据地址和长度都必须为4字节的整数倍,即要求4字节对齐。
- 与DMA不同的是,RMA不支持跨步访问。
节点间通讯(短板)¶
没有采用InfiniBand(400Gbps), 而是万兆PCIe+以太网络(10Gbps)
功耗,电费和成本¶
目前机时费是单节点6毛一小时,假如一半是电费0.3元/小时。工业用电按照1元每度。单节点功耗是300W. 约等于单卡A100.
总花费:按照100机柜 10w节点跑1天。150w左右。
从LLM训练角度看神威设计¶
首先神威出于国产化和通用性的考量,硬件肯定是无法与A100比的。加上软件栈(cuda)的差距。这里只是简单的分析。
LLM应用特点¶
- 从算子层面看, 就是矩阵乘和访存 占比top2
浮点计算峰值¶
- A100 FP32
19.5TFFP16312TF - 单节点 FP16
50TF - 峰值利用率:
8%(fp32)2.8%(fp16) 应该是从核利用率的问题 - 单看峰值性能比 神威单节点约等于百分之一a1003
访存带宽¶
- A100 HBM2
1.5TB/s - 单节点访存
300GB/s. DMA是64个从核均分50,目前大模型的最小并行粒度是一个节点, 用1主核带6*64从核, 零零散散凑下来也能有个理论300+的带宽.
计算访存比¶
和a100看纸面数据 fp16是人家的六分之一 带宽是五分之一到六分之一, 计算访存比的出入不大。
神威的优势¶
- 节点数:哪怕五十个节点打一张a100, 10w节点能对标2k张a100 也很满足了。
- 通用性设计:单节点6*(1+64)=390核心,在设计时是希望能进行类似GPU的并行计算的。
神威的需要补足的点¶
- 单节点的访存带宽
- 浮点的计算峰值和利用率
后续补足:神威加速卡¶
- 神威的智能计算卡(全面对标A100 PCIe版)
- 是无锡那边的太初团队在做,
- 单卡有4核组, 共
340TF的fp16,1.6TB/s的访存带宽。 - 太初那边还打算搞一套所谓的 护城河(类似cuda) 3