Cache
导言
Cache is to reduce latency
Excellent Video Resource
We're still on the lookout for an exceptional blog or overview paper to complement our understanding of this topic. Stay tuned for updates!
历史¶
自1970s它们的诞生以来,基于微处理器的数字平台一直遵循着摩尔定律,即在相同面积上,大约每两年密度就翻一番。然而,微处理器和存储器制造技术一直在以两种截然相反的方式利用这种密度的增加。微处理器的制造技术专注于提高指令的执行速度,而存储器的制造技术则主要关注容量的提高,速度的增加可忽略不计。这种处理器和内存间的性能差异趋势导致了一种被称为“存储墙”的现象6。
为克服存储墙,设计者们引入了带有缓存(cache)的存储器体系层次(memory hierarchy),每层的延迟与容量都经过了权衡。缓存基于内存访问的局域性原理来缓解处理器与内存间的性能差距。但不幸的是,存在许多重要的工作负载会表现出不利的内存访问模式。这些模式会难住现代高速缓存层次结构中的简单更新策略(这些策略规定了指令和数据在缓存层次间移动的规则)。因此,对于在较高层缓存(L1、L2)中不存在的内存块,处理器往往需要花费大量时间获取它们。
预取(prefetching)——预测未来的内存访问,并在处理器显式访问前对就相应内存块发出请求。——其作为一种隐藏内存访问延迟的方法是非常具有前途的。已经存在了大量用于预期的软硬件方法。许多针对简单存取模式的硬件预取机制已被纳入现代微处理器中,以预取指令与数据。
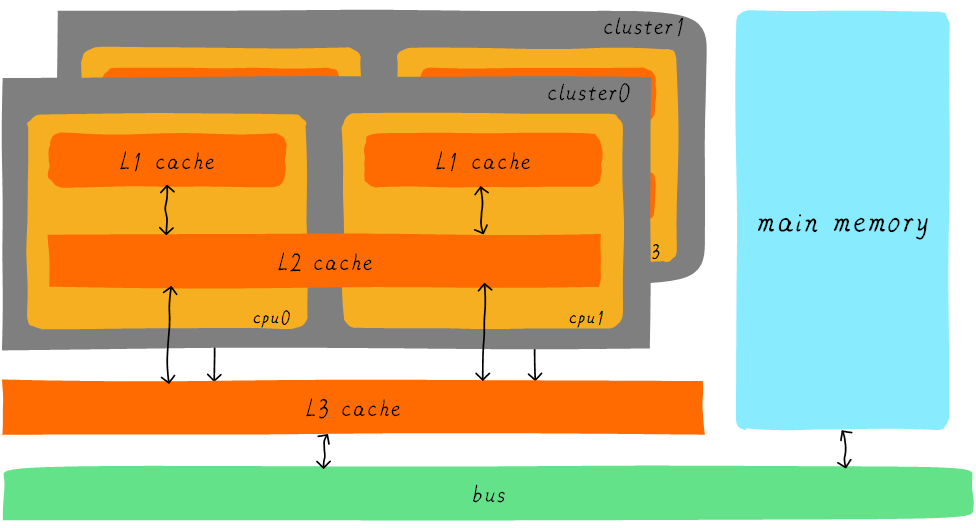
Cortex-A53 处理器高级缓存层次结构
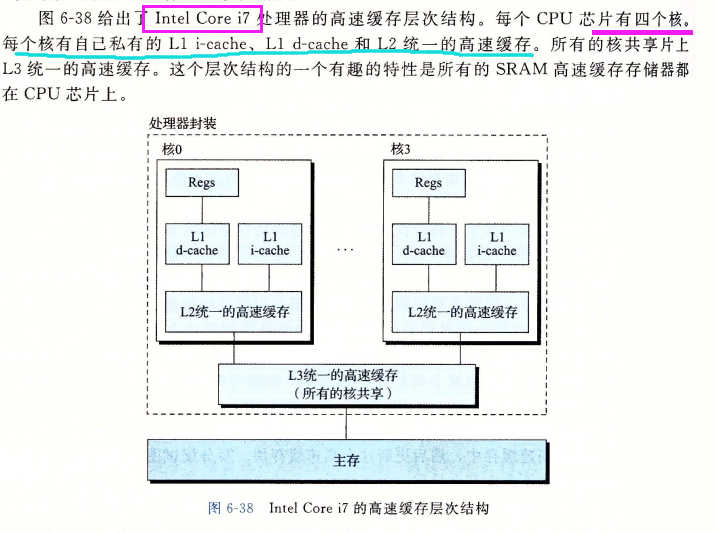
Intel Core i7 处理器高级缓存层次结构
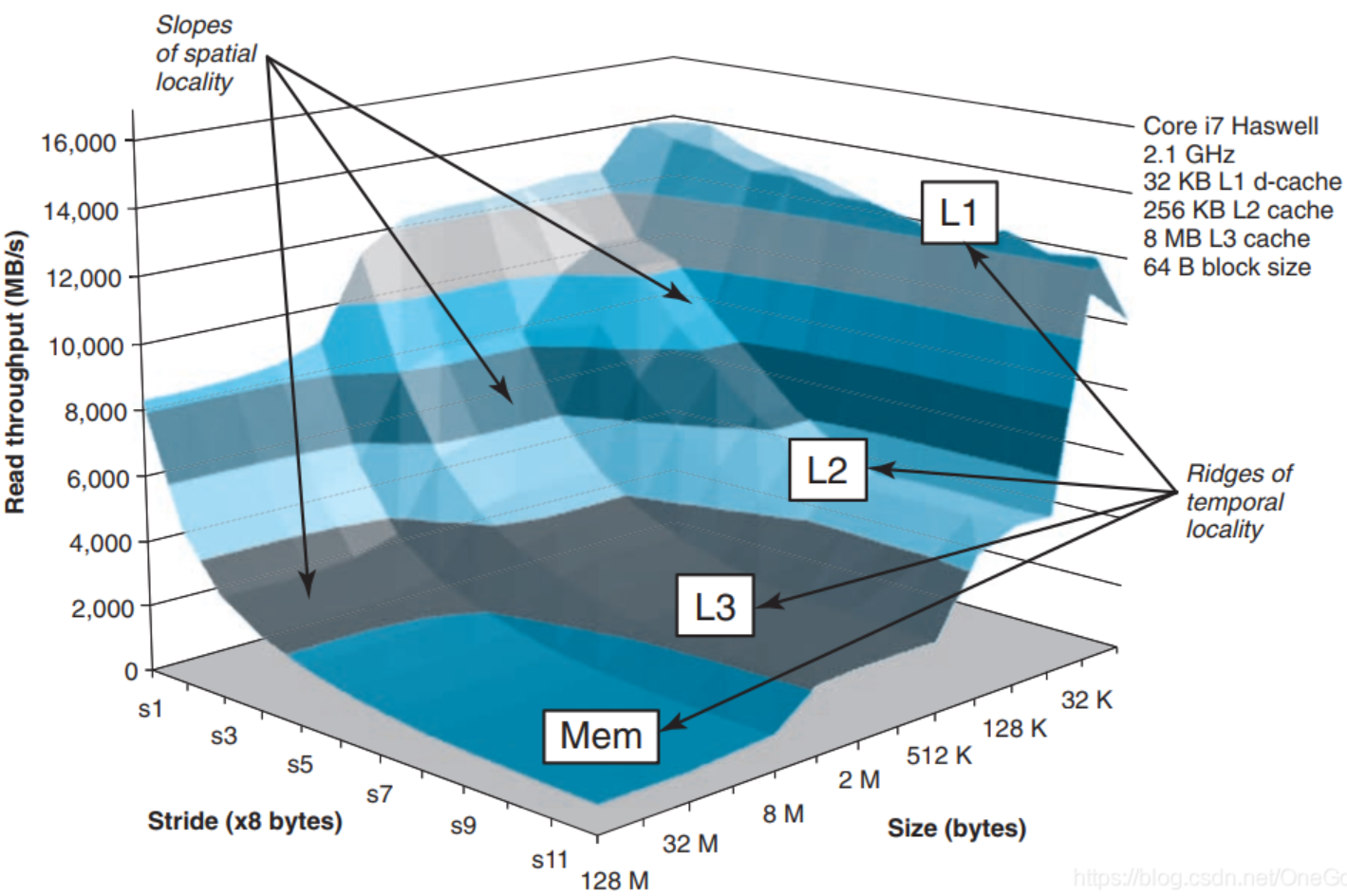
存储器山
stride步长意思是,相邻访问数据之间的间隔,越大空间局部性不好。
缓存的结构¶
整体逻辑¶
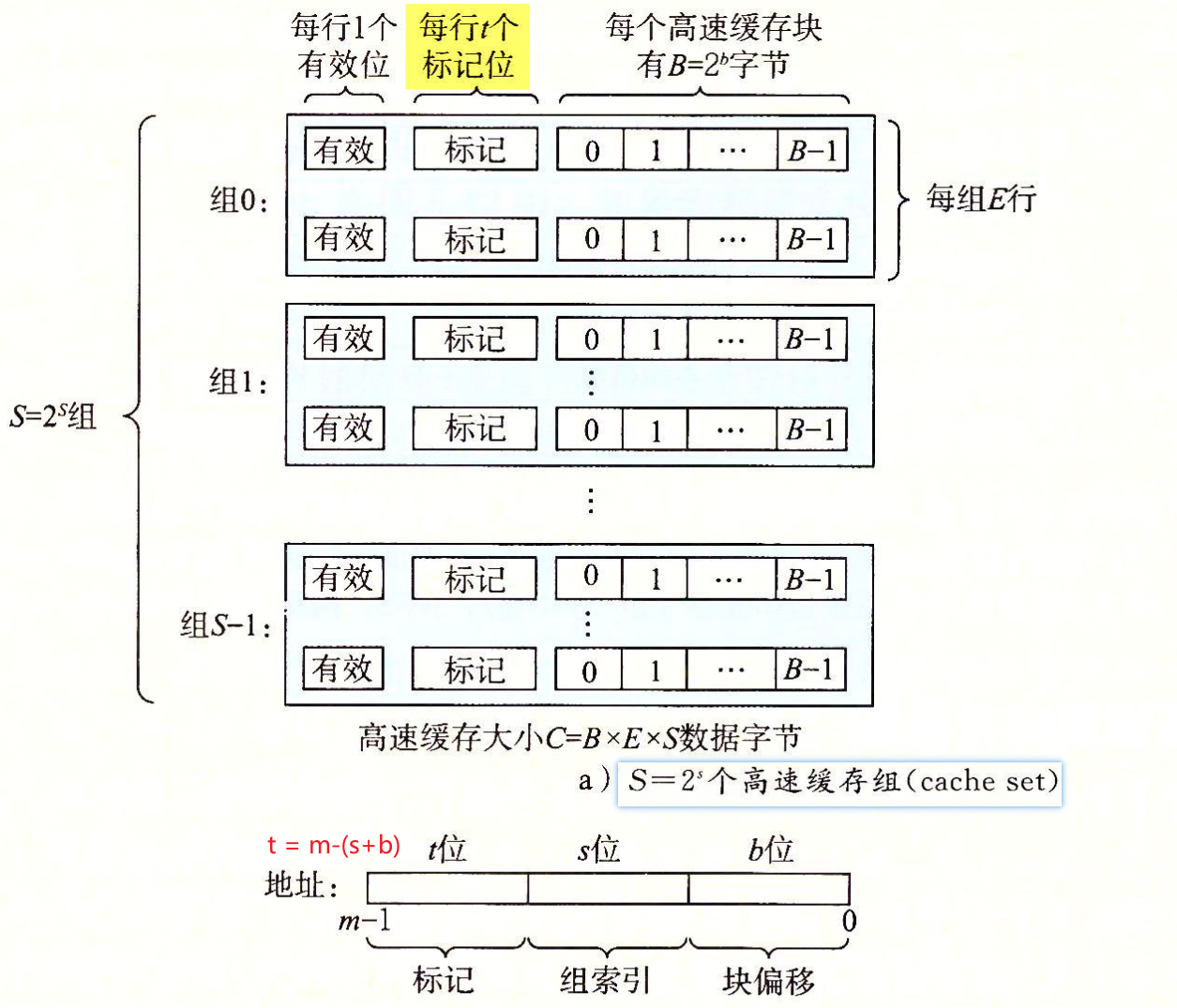
- 标记 tag
- 组索引 index(Index corresponds to bits used to determine the set of the Cache.)
- 偏移 offset
四路组相联 指一组里有四个 也就是E是4
calculation
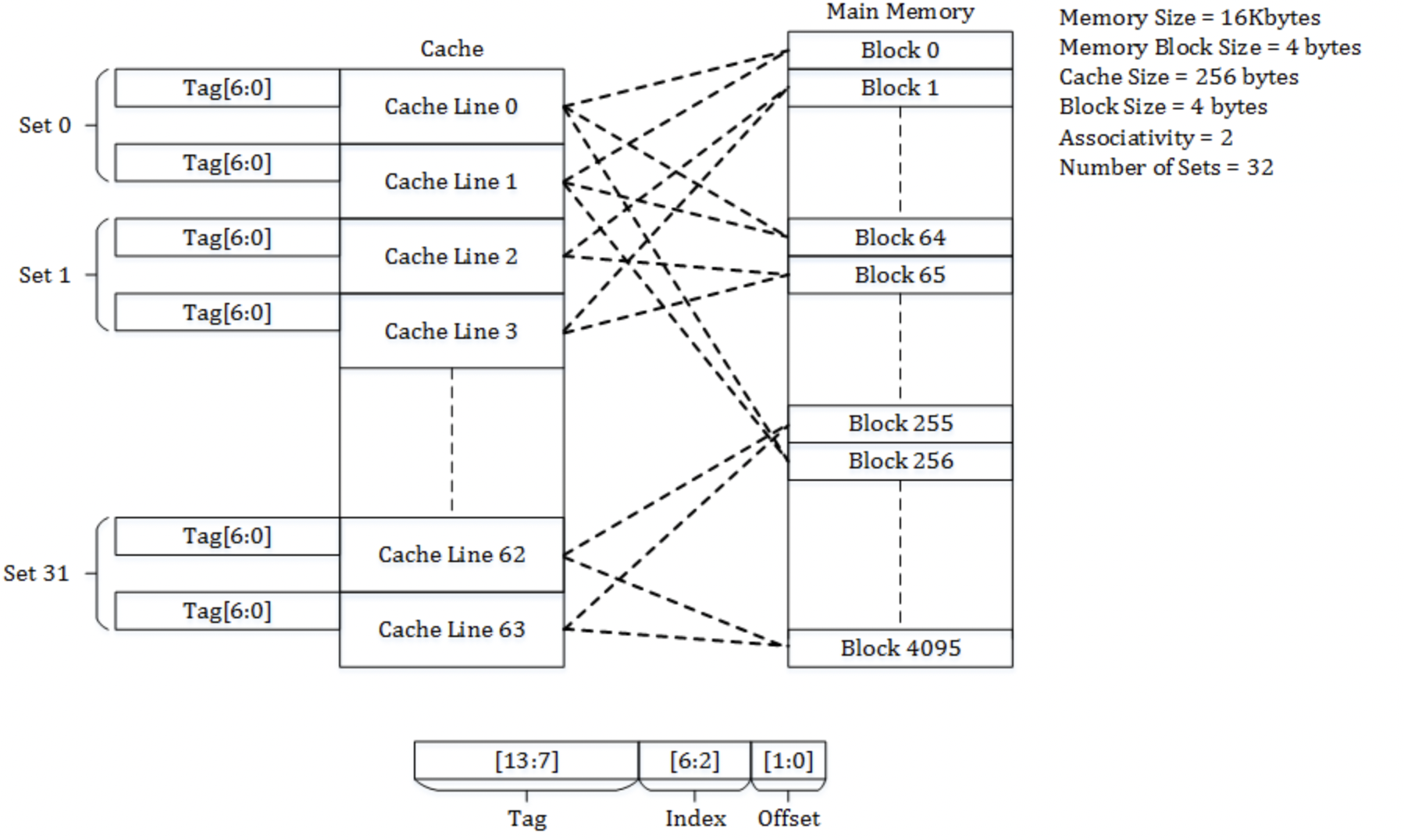
缓存的内容¶
Skylake架构:可以进一步阅读
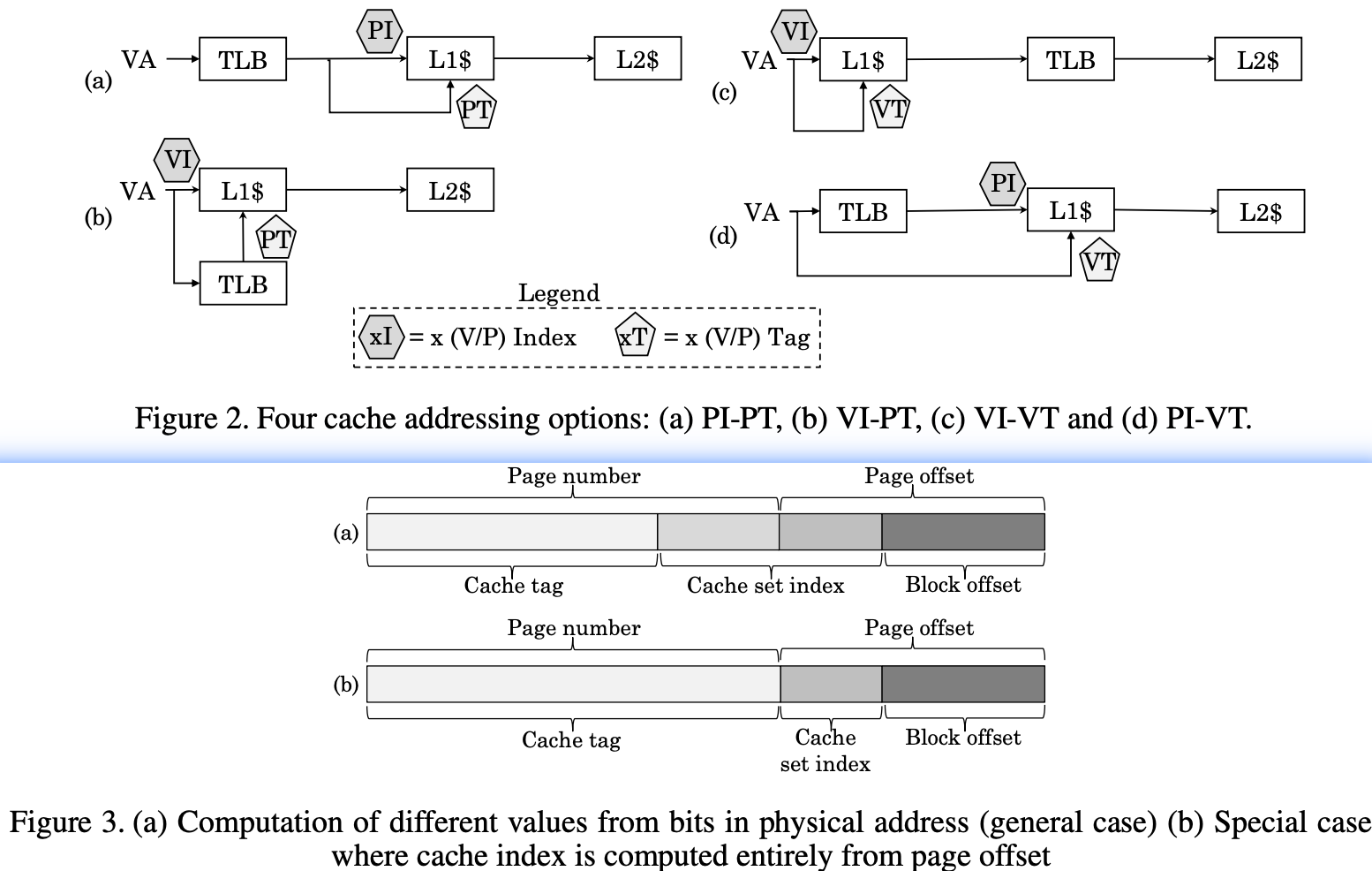
- Physically indexed, physically tagged (PIPT) caches use the physical address for both the index and the tag.
- Simple to implement but slow, as the physical address must be looked up (which could involve a TLB miss and access to main memory) before that address can be looked up in the cache.
- Virtually indexed, virtually tagged (VIVT) caches use the virtual address for both the index and the tag.
- Potentially much faster lookups.
- Problems when several different virtual addresses may refer to the same physical address(别名 Alias) -- addresses would be cached separately despite referring to the same memory, causing coherency problems.
- Additionally, there is a problem that virtual-to-physical mappings can change(比如,上下文切换时), which would require clearing cache blocks.
- Virtually indexed, physically tagged (VIPT) caches use the virtual address for the index and the physical address in the tag.
- To perform indexing with VA, virtual index bits should be same as physical index bits and this happens when index is taken from page offset
- cache associativity should be greater(有其他的标志位) than or equal to cache size divided by page size.For example, with 32KB L1 cache and 4KB page, associativity should be at least 8. This,however, increases cache energy consumption but may not provide corresponding miss rate reduction.
- Cortex-A8 设计:L1 cache is virtual index physical tag. L2 cache is physical address physical tag.
- 查找速度快:使用virtual page offset 来index索引与 physical tag的翻译能并行。所以能比PIPT快,
- 解决别名问题:使用物理地址作为tag,可以唯一标识缓存行,避免了VIVT中的别名问题。
- 缺点:Limitation is that one size of a VIPT cache can be no larger than the page size
- Intel L1 also VIPT1
More about paging 5
TLB的深入研究可以参考 2017 A_Survey_of_Techniques_for_Architecting_TLBs
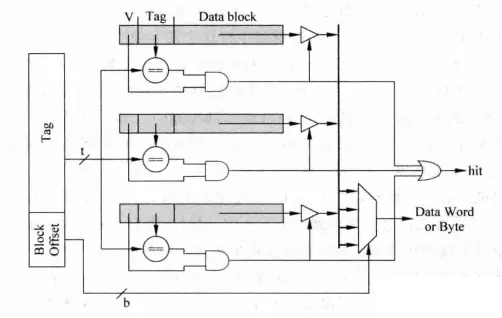
映射策略:直接映射 vs N路组相联 vs 全相联2¶
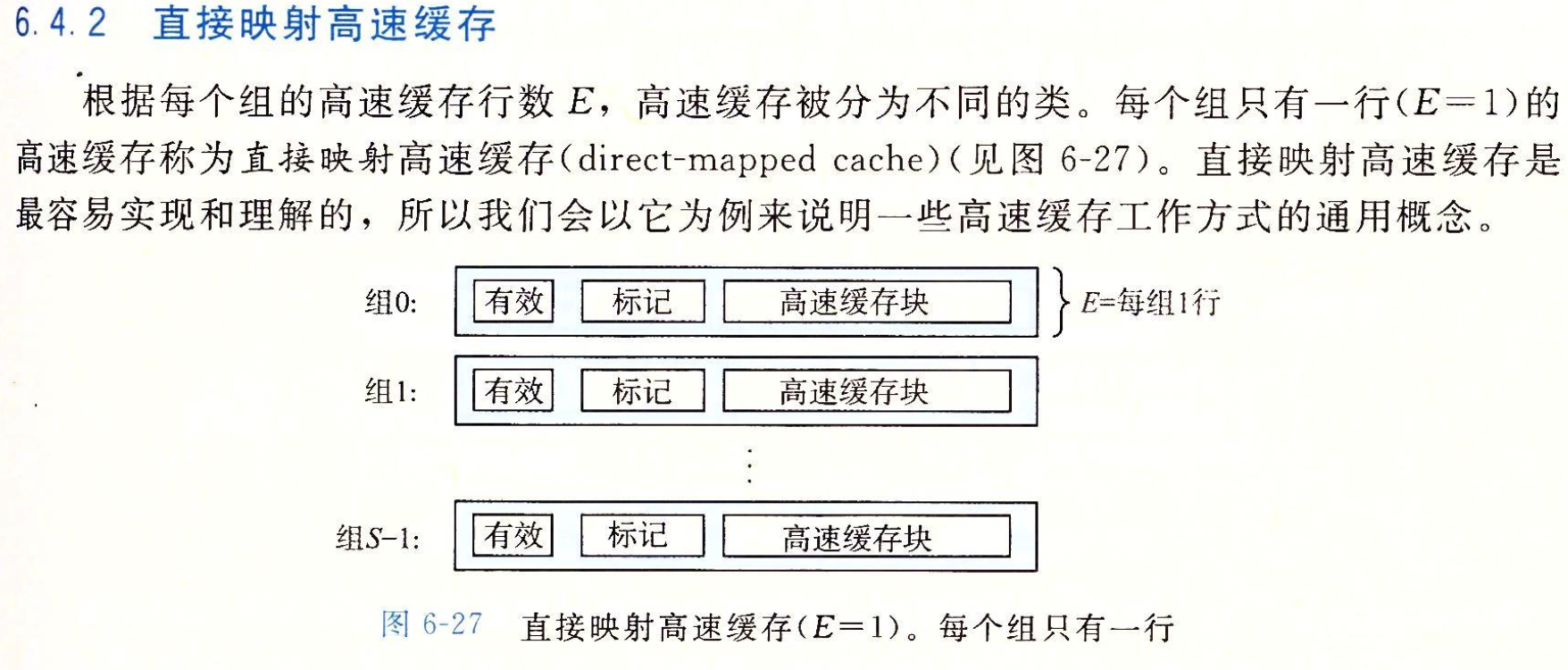
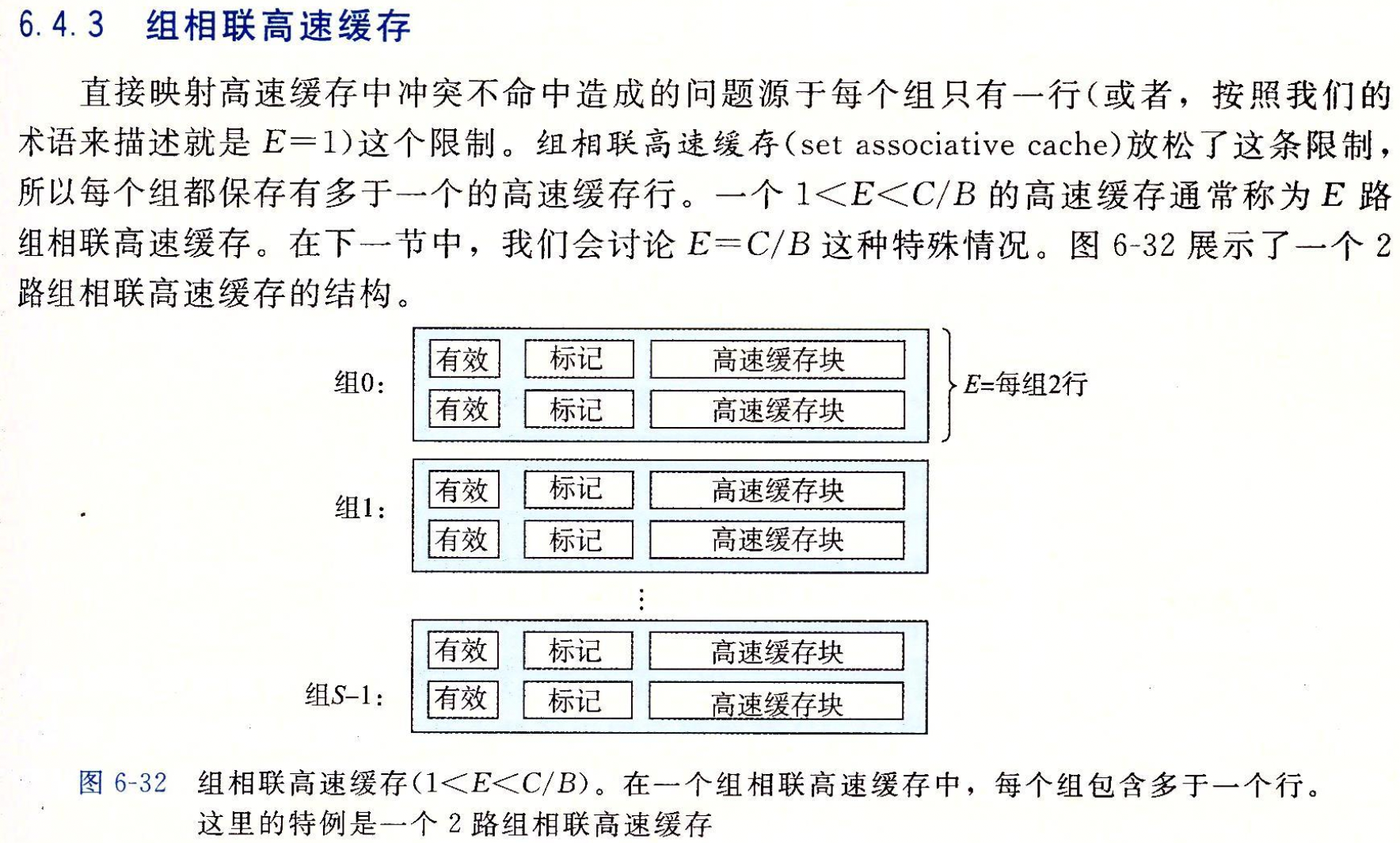
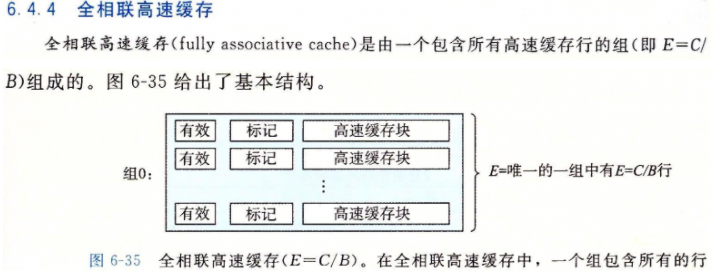
三者的比较 & 访问步骤细节
Set-associative caches offer lower miss rates than direct-mapped caches, but usually have a longer access time(tag comparator)(1).
- the access time for a two-way associative cache is 51%,46% and 40% times longer than the access time for a direct mapped cache for 8KB, 16KB and 32KB caches, respectively4
The energy consumption of set-associative cache tends to be higher than that of direct-mapped cache, because all the ways in a set are accessed in parallel although at most only one way has the desired data.
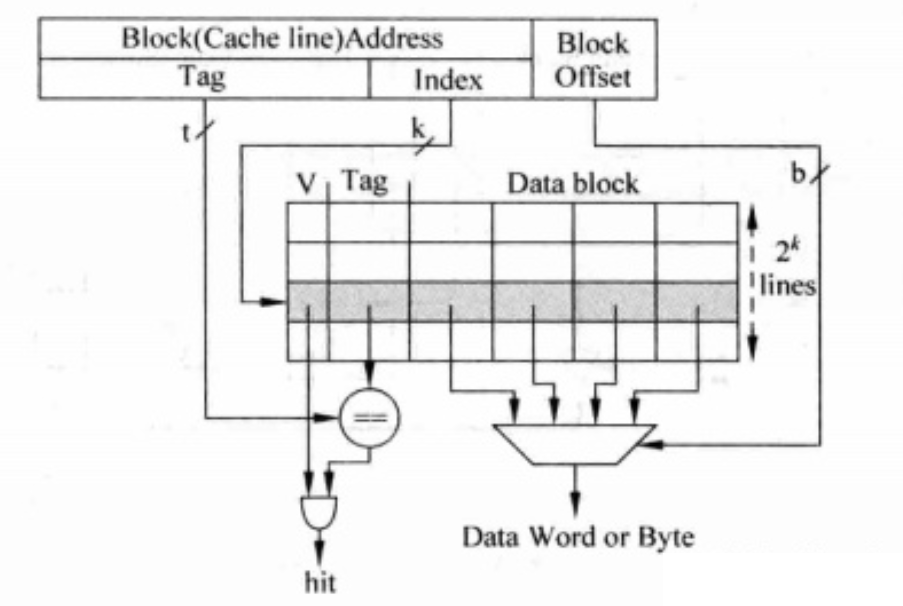
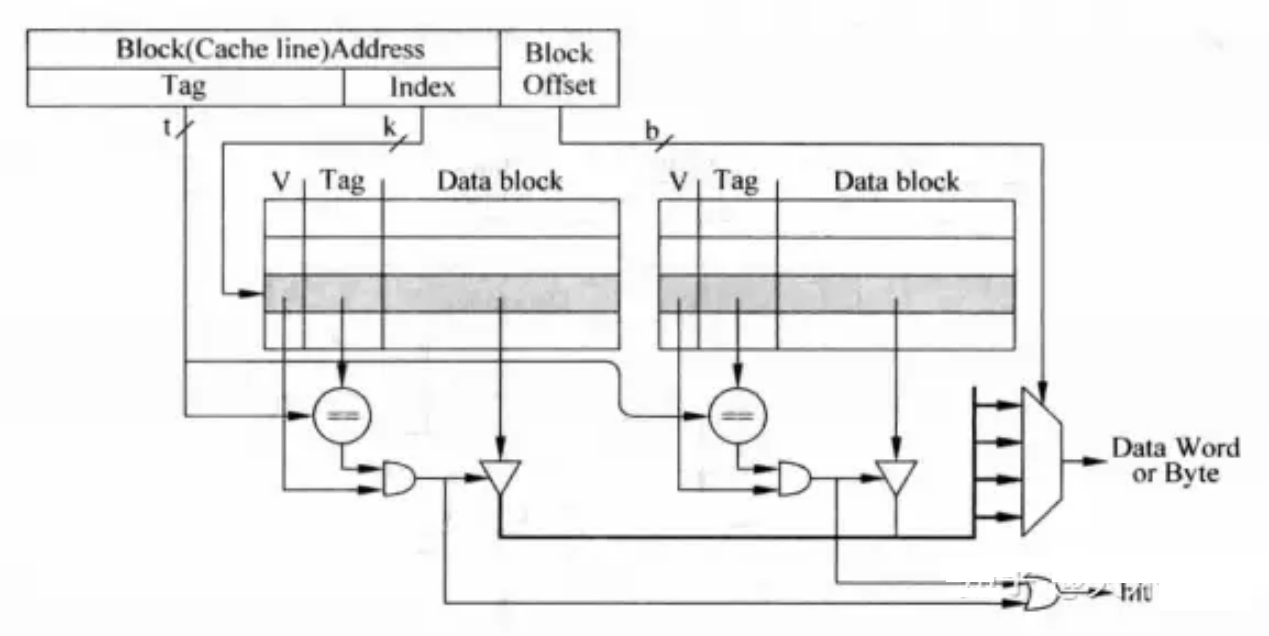
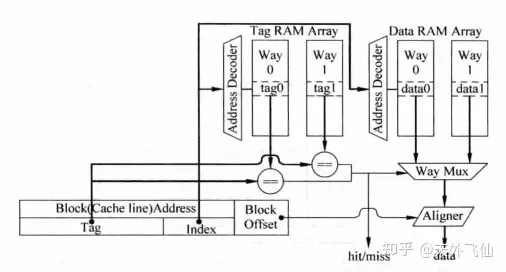
组相联tag/data分开情况:并行和串行tag比较实现的优劣
真实场景中组相联cache的tag和data往往被分开存储,因为分开存储,组相联实现电路分化成了并行和串行实现方式。8
- index同时送到
tag ram和data ram,同时译码,同时读取tag和data, - 并根据tag比较的结果来选择一组data进行输出,其中
aligner是字节选择器。
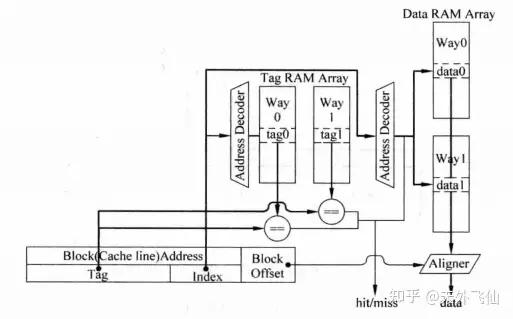
首先tag并行比较,然后才选中某一cache line的数据。
- 并行实现因为比串行多一个多路选择器,工作时间会变长,对应的时钟频率会下降,而且每次同时选中多个cache line,功耗较大;
- 串行实现在用流水线来实现cache时会明显增加所需时钟周期数(多一个时钟周期)。
因为高速缓存电路必须并行地搜索许多相匹配的标记,构造一个又大又快的全相联高速缓存很困难,而且很昂贵。因此,全相联高速缓存只适合做小的高速缓存,例如虚拟内存系统中的翻译备用缓冲器(TIB),它缓存页表项。
缺失状态处理寄存器 MSHR¶
(Miss Status Handling Register,MSHR)
当出现缓存缺失(cache miss)时,高性能处理器依然会继续发出存储访问请求。早期的缓存设计中,处理器发出的后续存储访问会被阻塞,直到前面缓存缺失的存储访问得到相应的数据。很显然,这会大大降低处理器的性能。9
现代缓存设计中,为了解决这一问题,引入了缺失状态处理寄存器(Miss Status Handling Register,MSHR)。当出现缓存缺失时,一个MSHR会用来记录缓存缺失状态,高速缓存可以继续响应其它的存储访问请求,当缓存缺失被满足后,这个MSHR会被释放。这种高速缓存设计也被称为非阻塞或者无锁高速缓存。
在给定的任意时间内,待处理的缓存缺失数量受MSHR数量的限制。因此,MSHR的数量会影响存储层的并行度。在设计MSHR数量时,要考虑处理器一个时钟周期内可以执行的指令数,访问外层存储层次的延迟和带宽,以及内层存储层次访问过滤的配置。
替换策略¶
Cache placement policies
- LRU(Least Recently Used)
- LFU(Least Frequently Used)
- Advanced policies
- RRIP7
缓存数据策略:写回和写直达¶
RMW cycle¶
写数据的时候,如果数据不在cache里,需要Read-Modify-Write,这个过程叫做RMW cycle。
Write-Back vs Write-Through¶
在缓存管理策略中,Write-Back(回写)和Write-Through(直写)是两种处理数据写入操作的常见方法。这些策略的选择对系统的性能和复杂度有显著影响。
Write-Through(直写)
定义: 在Write-Through策略中,每当缓存执行写操作时,数据不仅写入缓存,同时也直接写入到下一级存储(通常是主存或下一级缓存)。这保证了缓存与主存之间的数据一致性。
优点:
- 数据一致性:缓存和主存之间的数据始终保持一致,简化了数据一致性的管理。
- 简单性:由于数据立即写入主存,系统设计相对简单,特别是在处理设备断电或系统崩溃的情况下。
缺点:
- 性能影响:每次写操作都需要访问主存,这可能导致较高的延迟和降低系统的总体性能。
- 增加带宽压力:由于每个写操作都要写入主存,因此可能会增加系统的带宽需求。
Write-Back(回写)
定义: 在Write-Back策略中,数据首先被写入缓存。只有在缓存块被替换出缓存时,才会将数据写回到主存。这通常通过一个“脏位”来标记修改过的缓存行,表示这部分数据与主存中的数据不一致。
优点:
- 性能优化:由于数据写操作只修改缓存,不直接影响主存,可以显著减少访问主存的次数,从而提高性能。
- 减少带宽使用:只有在必需时才将数据写回主存,减少了对系统带宽的需求。
缺点:
- 数据一致性问题:由于缓存和主存之间的数据可能不同步,需要额外的策略来管理数据的一致性,尤其是在多处理器系统中。
- 复杂性:需要管理脏位以及在适当的时候将数据写回主存,增加了系统设计的复杂性。
选择依据¶
- 系统需求:如果系统对性能的需求高于对数据一致性的即时需求,那么Write-Back可能是更好的选择。反之,如果需要确保数据随时一致,特别是在高可靠性的环境中,Write-Through可能更合适。
- 应用场景:在大量写操作的环境中,Write-Back可以显著提高性能。而在需要频繁更新外部数据或易于数据恢复的环境中,Write-Through可以简化数据管理和恢复过程。
总结来说,每种策略都有其适用场景和权衡点。选择最合适的策略取决于特定应用和系统架构的具体需求和目标。
写直达有个问题,到底是写修改的数据,还是写整个cache line?
在处理缓存写入策略时,特别是在讨论写直达(Write-Through)缓存时,通常涉及到如何具体执行写入操作:是只写入修改过的数据,还是写入整个缓存行。这个决策对性能和带宽利用率有直接影响。
写直达策略中的写入操作
在写直达(Write-Through)缓存策略中,数据在写入缓存的同时也被写入到下一级存储(如主存或下一级缓存)。这样做的目的是确保缓存和主存之间的一致性。在这个过程中,通常涉及以下两种方法:
-
写整个缓存行:
- 操作方式:当缓存行中的任何数据被修改时,整个缓存行都会被写回到主存。这意味着不仅仅是被修改的数据部分,而是整行数据。
- 优点:
- 简化了缓存与主存之间的数据同步,因为整行数据都保持一致。
- 在某些情况下,这可以提高系统的预测加载效能,因为整行数据通常是连续存储的,可能包含将来会被访问的数据。
- 缺点:
- 可能导致不必要的数据传输,特别是当只修改了缓存行中很小的一部分数据时。
-
写修改的数据:
- 操作方式:只有实际被修改的数据部分被写回主存,而不是整个缓存行。
- 优点:
- 减少了数据传输量,只有必要的数据被更新,可以提高带宽的使用效率。
- 缺点:
- 实现上可能更复杂,需要缓存系统能够精确地跟踪哪些部分的数据被修改过。
- 在处理器和主存之间可能需要更频繁的同步,因为数据更新不再是按块进行。
哪种方法更常见?
在大多数实际应用中,尤其是在传统的写直达策略下,通常是写整个缓存行。这样做主要是因为硬件和系统设计简化的考虑,以及保证数据的一致性。写整个缓存行可以减少对复杂逻辑的需求,因为不需要跟踪缓存行内部各部分数据的修改状态。A write-through cache writes a cache block back immediately after the CPU write to the cache block.来自美国东北大学的网址,结论是写整个cache line。
选择写整个缓存行还是只写修改的数据部分,取决于具体的系统设计、预期的应用负载以及对性能与带宽的优化需求。在实际的系统设计中,写整个缓存行通常更为常见,尤其是在需要简化硬件设计并保持高效一致性管理的场景中。如果系统对带宽使用有严格要求,可能会考虑只写修改的数据,尽管这可能增加设计的复杂性。
多核 UCA & NUCA¶
在大规模芯片系统(核心数量巨大)的情况下,为了提高缓存的利用率,通常多个核心会共享最外层缓存。
- 缓存均为一整块,而访问缓存中的某个数据,发生缓存命中时均造成固定的延时。因此这种统一的缓存也被称为均一访问延时(Uniform Cache Access, UCA)的缓存。随着核心的增多,使得这类共享的缓存不断增大,以至于该级缓存命中延时太高、功耗明显增加。
- 将共享缓存分布式的拆分到,每个处理器核心和私有缓存一起组织的设计就是非均一访问延时(Non-Uniform Cache Access,NUCA)。具体表现在:在发生缓存命中时,某核心访问它本地的这部分共享缓存,与访问其它核心拥有的共享缓存的延时不同;某核心访问与它较接近的共享缓存,与访问与它较远的共享缓存的延时不同。
预取¶
TLB 预取¶
TLB 作为页表的缓存,为了提高命中率。也是有对应的预取技术的。
基于G. B. Kandiraju的文章3
- Sequential Prefetching (SP)
- Recency Prefetching
- arbitrary stride prefetching, and markov prefetching
- 马尔科夫链是一种随机过程,它具有"无记忆性"的特点,即当前状态只与前一个状态有关。在缓存预取中,可以使用马尔科夫链来建模程序的数据访问模式。根据先前的访问历史,马尔科夫链可以估计出下一个访问的数据位置,从而预测未来的数据访问模式。
- 然而,准确建立有效的马尔科夫链模型需要足够的历史数据和精确的预测算法。此外,马尔科夫链模型也需要根据程序的特性和访问模式进行定制化的调优,利用数据访问模式的统计特性来设计。
- Distance Prefetching
指令预取技术¶
- next-line prefetchers(下一行预取)
- branch-directed prefetching(分支定向的预取)
- discontinuity prefetchers(不连续的预取)
- temporal Instruction streaming(时间域上的存储流)
数据预取器¶
- stride and stream-based data prefetchers(基于跨步和流的数据预取器)
- address-correlated prefetching(基于地址相关性的预取器)
- spatially correlated prefetching(基于空间相关性的预取器)
- execution-based prefetching(基于执行的预取)
数据预取 prefetch¶
概念¶
將memory中的数据在读写单元空闲時(计算單元努力工作時)平行下載,達到降低 cache miss latency 的效果。注意一般每一级Cache都有相应的硬件预取单元。
优秀的prefetch策略通常使用Coverage和Accuracy来衡量,前者为prefetching命中占总访存比例,后者为有效的prefetching在总prefetch请求中的比例。
一个理想的预取机制应该是
- 高覆盖率,最大程度消除缓存缺失;
- 高准确率,不会增加过多的存储带宽消耗;
- 及时性,完全隐藏缓存缺失时延。
特点
- prefetch 依抓取到資料的時間分類
- prefetch 資料太早到的話,要在 cache 中等很久,占位子,還可能被踢出去 。
- 太晚到的話,就達不到降低 latency 的效果
- 根据prefetch数据存储的位置分
- "binding prefetch"指通过软件/硬件机制直接预取到寄存器中
- 现代处理器多用"non-binding prefetching",将数据预取到cache或cache结构中额外的buffer里面
- prefetch 是有額外開銷(over head)的
- prefetch 本身就是使用不同方式快取內容進行額外的補充,進行額外操作時就會消耗額外的有限資源,但如果這個補充的資料並沒有恰好被使用到則這些額外消耗的有限資源就都是浪費掉的,也就是所謂的快取污染。
硬件预取¶
触发时机
在gem5 的学习时,prefetch_on_access = Param.Bool(False,"notify the hardware prefetcher on every access (not just misses)") 貌似暗示了预取发生在cache miss时。
几种基本策略
动态观测程序的行为并产生相应的预取请求,这种方式称为硬件预取(hardware prefetching)。说简单些,就是用硬件根据某些规律去猜测处理器未来将要访问的数据地址。
- 顺序预取(sequential prefetching)检测并预取对连续区域进行访问的数据。
- 顺序预取是最简单的预取机制,因为总是预取当前cache line的下一条line,硬件开销小,但是对访存带宽的需求高。
- 步长预取(stride prefetching)检测并预取连续访问之间相隔s个缓存数据块的数据,其中s即是步长的大小。硬件实现需要使用访问预测表,记录访问的地址,步长以及访存指令的pc值。
- 流预取(stream prefetching)对流访问特征进行预取,流访问特征是指一段时间内程序访问的cache行地址呈现的规律,这种访问规律在科学计算和工程应用中广泛存在。硬件实现时,需要使用流识别缓冲记录一段时间内访存的cache行地址。预取引擎识别到流访问则进行预取。
- 关联预取(association based prefetching)利用访存地址之间存在的关联性进行预取。
其他做法:
- GHB prefetcher : Global History Buffer,將 cache miss 的資料暫存起來,根據這些資料去選擇較佳的 prefetching method。採 FIFO ,可避免 stable data,提高精準度
- Data Cache Prefetching Using a Global History Buffer
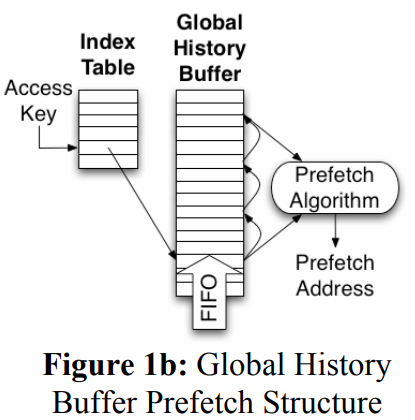
- STR prefetcher : Stream buffers,將 cache miss 在記憶體中附近的連續資料放到 stream buffer 中,在假設常常用到都會放在一起的前提下,可以減少 cache miss 的情況。
优缺点
hardware prefetch 優點
- 透過訓練,可以在執行時間做出適當的 prefetch 選擇
- 不增加指令,直接以硬體運作
hardware prefetch 缺點/限制
- 硬體受到資源限制,無法一次操作大量的 streams
- stream 太短沒有足夠的 cache misses 去做硬體的預取和載入有用的 cache block
- 因為硬體是有規則的拿取,如果要存取不規則的記憶體(資料結構),會變得很複雜
软件预取¶
透過編譯器或者直接在程式中插入 intrinsics,達到 prefetch 的效果,常見的有 intel SSE (Streaming SIMD Extensions) 、 AVX
优缺点
software prefetch 優點
- 不規則的記憶體存取
- Cache Locality Hint 缓存位置提示?
- 可以利用 hint 將資料放在適合的 cache level ,減少不同 level 之間造成 Latency
- 硬體只會將 prefetch 到的資料放在 LLC (last level cache)
- Loop Bounds
- 由 loop unrolling, software pipelining, and using branch instructions 這幾個技巧,使得軟體的 prefetch 較硬體靈活
software prefetch 缺點
- 增加指令數量
- 除了指令本身,每道指令都需要額外的計算記憶體位置
- Static Insertion
- 無法在執行時間根據情況來做更好的調整
- 改變程式結構
- 為了使預取達到效果,有時候會做一些結構的修改,例如:迴圈的拆解(loop unrolling),可能使可讀性下降
软硬件预取¶
同時採用 software 及 hardware prefetch ,兩者會互相影響,有加成的效果,也可能有負面的影響。
优缺点
software + hardware prefetch 優點/正面影響
- 針對規則/不規則的 stream 分別交給 hardware / software prefetch,達到截長補短的正面效果
- 如果 software prefetch 的資料遲了, hardware prefetch 也能及時補上資料
software + hardware prefetch 缺點/負面影響
- software prefetch 會減少能夠訓練 hardware prefetch 的資料,因為都已經 prefetch , hardware prefetcher 就以為這些是不需要 prefetch 的資料
- software prefetch 指令會觸發 hardware prefetch ,造成過早要求 prefetch
- software prefetch 取到錯誤或多餘的資料時,會造成硬體上的負擔,降低效率
实践:详细cache参数分析¶
SYSNODE=/sys/devices/system/node
grep '.*' $SYSNODE/node*/cpu*/cache/index*/* 2>/dev/null |
awk '-F[:/]' '{ printf "%6s %6s %24s %s\n" $6, $7, $9, $10, $11 ; }'
L1 的数据和指令缓存
Data Cache 4路256组相联,每块64K / (4*256) =64字节(正好是一个cache line)。块偏移位b=6(26=64),组索引s=8(28=256),标记位t=64-8-6=50位。
每块能存64/4=16个int,L1总共能存(4*256*16)=1024*16个int。(不考虑写回的话。

L2 和 L3 缓存

参数解释与计算
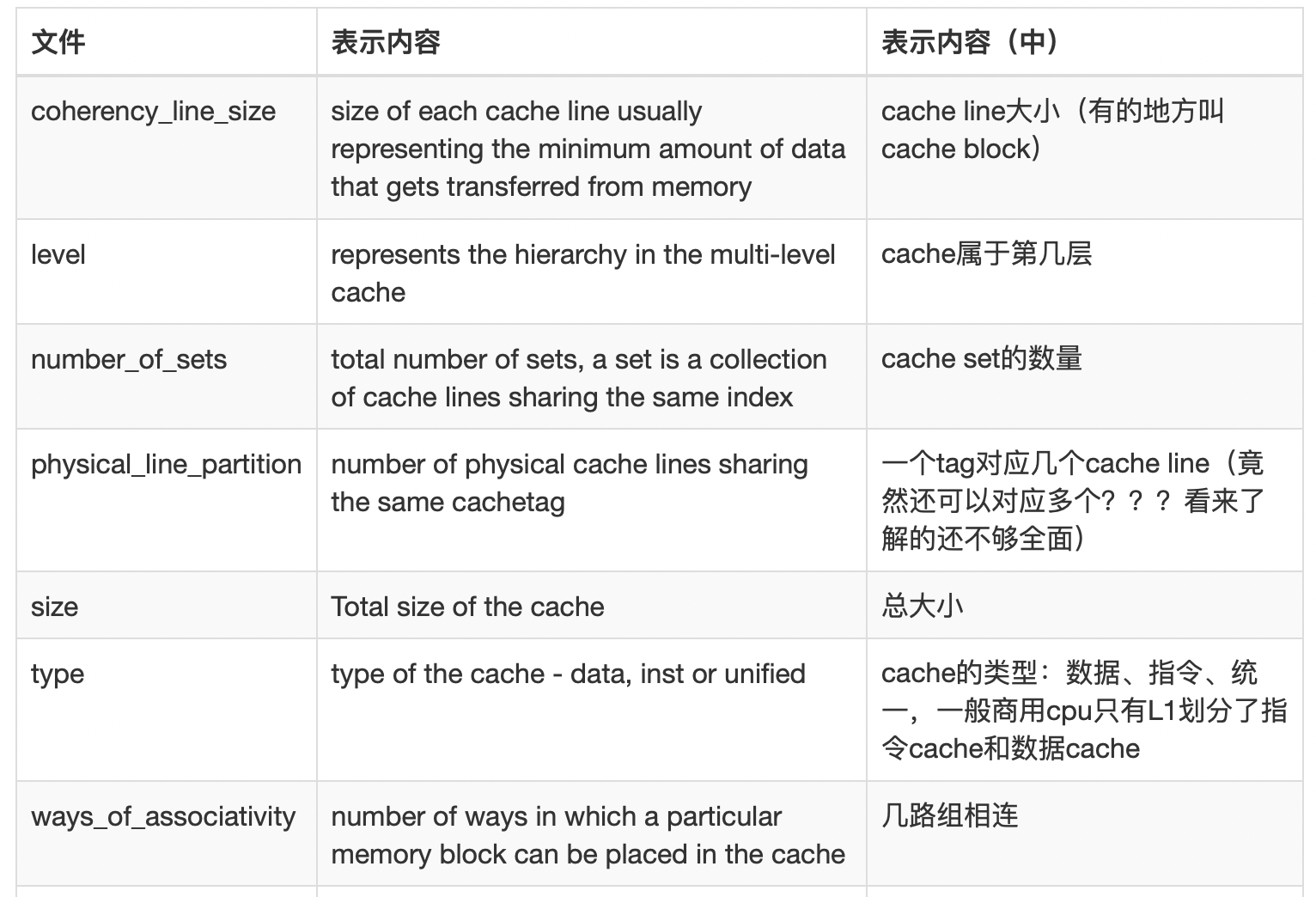
coherency_line_size-how many bytes are in a cache line, which is the unit in which memory is read and written to/from main memory.
ways_of_associativity-how many different cache slots a given line can be mapped to. Higher is better (it means you're less likely to have a working set that is smaller than cache but can't simultaneously be in cache because lots of data wants to be in the same cache lines), but is hard to implement, especially in the lower-level caches that have to be faster. 8 is pretty common for L1.
但是这里对L3不对,很奇怪。
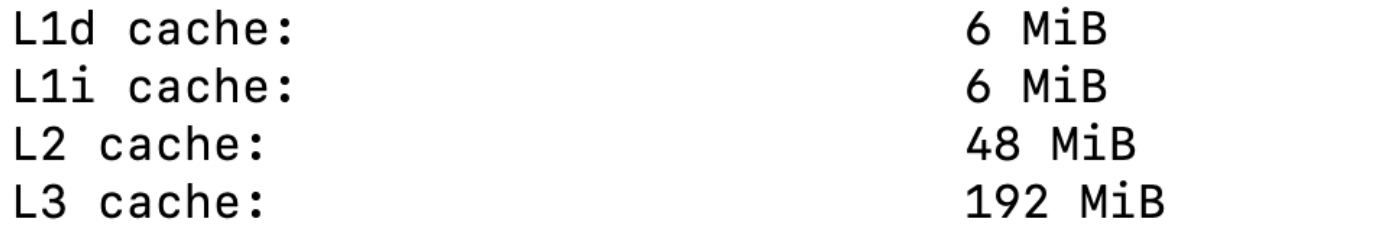
需要进一步的研究学习¶
硬件预取技术导论《A Primer on Hardware Prefetching》
■■3 数据预取 Data Prefetching-
- ■1 数据的跨步和流预取器 Stride and Stream Prefetchers for Data-
- ■2 基于地址相关性的预取器 Address-Correlating Prefetchers-
- 1 跳转指针 Jump Pointers-
- 2 成对两者间的相关性 Pair-Wise Correlation-
- 3 马尔可夫预取器 Markov Prefetcher-
- 4 通过预取深度改善前瞻性 Improving Lookahead via Prefetch Depth-
- 5 通过死快预测改善前瞻性 Improving Lookahead via Dead Block Prediction-
- 6 片上存储器寻址的局限性 Addressing On-Chip Storage Limitations-
- 7 全局历史缓冲区 Global History Buffer-
- 8 流链 Stream Chaining-
- 9 时间域上的存储流 Temporal Memory Streaming-
- 10 不规则流的缓冲区 Irregular Stream Buffer-
- ■3 基于空间相关性的预取器 Spatially Correlated Prefetching-
- 1 Δ相关性查找 Delta-Correlated Lookup-
- 2 PC局域性/Δ相关性的全局历史缓冲(GHB PC/DC) Global History Buffer PC-Localized/Delta-Correlating (GHB PC/DC)-
- 3 代码相关性查找 Code-Correlated Lookup-
- 4 空间足迹预测 Spatial Footprint Predicction-
- 5 空间模式预测 Spatial Pattern Prediction-
- 6 隐形预取 Stealth Prefetching-
- 7 空间存储流 Spatial Memory Streaming-
- 8 时空存储流 Spatio-Temporal Memory Streaming-
- ■4 基于执行的预取 Execution-Based Prefetching-
- 1 算法汇总 Algorithm Summarization-
- 2 辅助内存和辅助内核的方法 Helper-Thread and Helper-Core Approaches-
- 3 超前执行 Run-Ahead Execution-
- 4 上下文恢复 Context Restoration-
- 5 计算分摊 Computation Spreading-
- ■5 预取的调制与控制 Prefetch Modulation and Control-
- ■6 软件方法 Software Approaches
参考文献¶
https://www.findhao.net/easycoding/1694
https://en.wikipedia.org/wiki/Cache_placement_policies
https://hackmd.io/@Rance/Hy3KRm1CG?type=view
https://aijishu.com/a/1060000000210697
-
Which cache mapping technique is used in intel core i7 processor? ↩
-
https://shaojiemike.notion.site/CSAPP-6-62b5d68fadc54142b306d8c7a1d8e1d7 ↩
-
G. B. Kandiraju and A. Sivasubramaniam, "Going the distance for TLB prefetching: an application-driven study," Proceedings 29th Annual International Symposium on Computer Architecture, Anchorage, AK, USA, 2002, pp. 195-206, doi: 10.1109/ISCA.2002.1003578. ↩
-
B. Calder, D. Grunwald, and J. S. Emer, “Predictive sequential associative cache,” in Proceedings of the 1996 International Symposium on High-Performance Computer Architecture, 1996 ↩
-
Aamer Jaleel, Kevin B. Theobald, Simon C. Steely, and Joel Emer. High Performance Cache Replacement Using Re-Reference Interval Prediction (RRIP). In ISCA 2010. ↩