GNU Assembly File
GNU汇编语法¶
伪指令¶
- 指示(Directives): 以点号开始,用来指示对编译器,连接器,调试器有用的结构信息。指示本身不是汇编指令。
| 伪指令 | 描述 |
|---|---|
| .file | 指定由哪个源文件生成的汇编代码。 |
| .data | 表示数据段(section)的开始地址 |
| .text | 指定下面的指令属于代码段。 |
| .string | 表示数据段中的字符串常量。 |
| .globl main | 指明标签main是一个可以在其它模块的代码中被访问的全局符号 。 |
| .align | 数据对齐指令 |
| .section | 段标记 |
| .type | 设置一个符号的属性值 |
- 语法:
.type name , description - description取值如下:
%function表示该符号用来表示一个函数名%object表示该符号用来表示一个数据对象
至于其它的指示你可以忽略。
实践:阅读汇编文件¶
从最简单的C文件入手
运行gcc -S -O3 main.c -o main.s,得到main.s文件
.file "simple.cpp"
.text
.section .text.startup,"ax",@progbits
.p2align 4
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
endbr64
xorl %eax, %eax
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:
- 下面回答来自ChatGPT-3.5,暂时没有校验其可靠性(看上去貌似说得通)。
section¶
.section .rodata.str1.1,"aMS",@progbits,1rodata.str1.1是一个标号(label), 意思是只读数据段的字符串常量aMS是一个属性值:- 可分配的(allocatable),即程序运行时需要动态分配空间才能分配该代码段,
- 不可执行 (M),
- 数据的类型为串(S)
- 其余属性值:对齐方式的通常为 b(byte对齐),w(word对齐),或者其他更大的对齐单位,例如 d(double word对齐)。
@progbits: 表示该段的类型是程序数据段(PROGBITS),这种类型的段包含程序的代码和数据。1: 表示该段的对齐方式是2^1 = 2个字节(按字节对齐)。如果不写这个数字,默认对齐到当前机器的字长。.section .text.startup,"ax",@progbits其中ax表示该段是可分配的(allocatable)和可执行的(executable)。- "
.section .note.GNU-stack"指令用于告诉链接器是否允许在堆栈上执行代码。 - "
.section .note.gnu.property"指令用于指定一些属性,这里是一个GNU特性标记。
汇编的入口¶
- 汇编的执行流程:入口函数在哪里
- 入口函数在该文件中的名称为“main”,定义于“
.text.startup” section,其首地址为“.globl main”。
构造函数¶
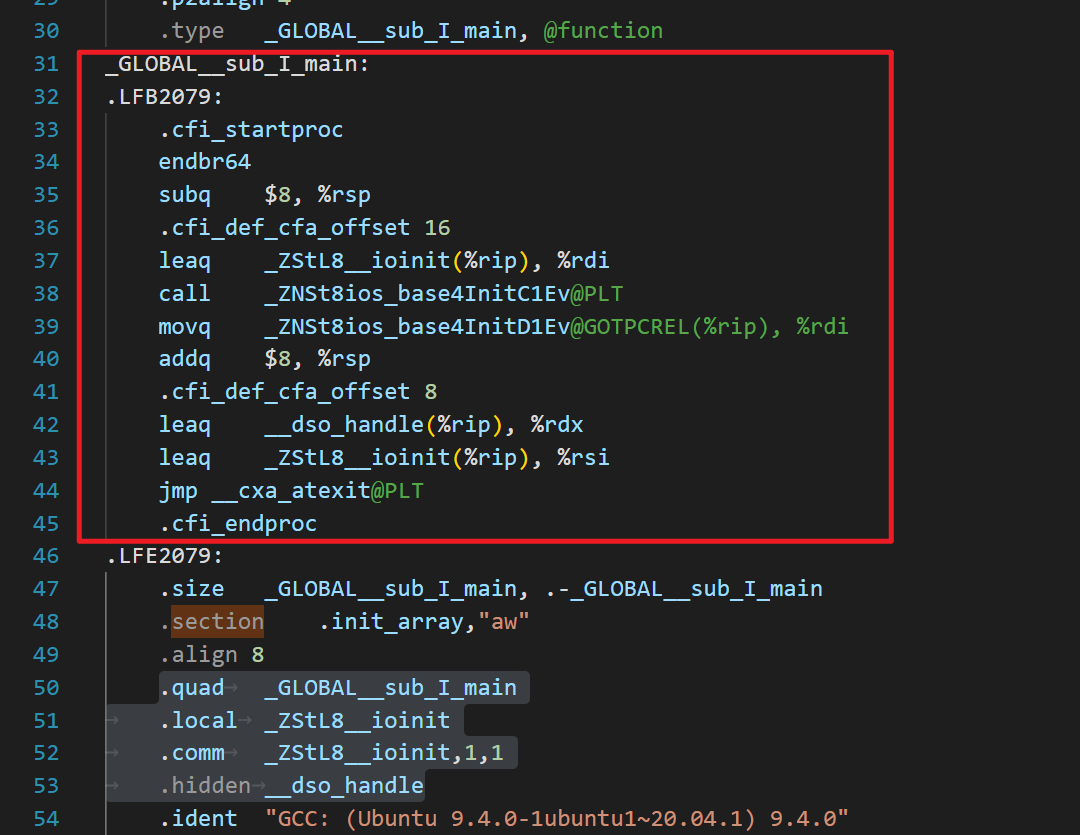
- 为了确保这些初始化操作可以在程序启动时正确执行,编译器将把这些构造函数和析构函数的调用代码打包成若干个函数,统一放在名字为“
_GLOBAL__sub_I_xxx”的section中。 - 因为在C++程序编译后的二进制文件中,全局变量、静态变量和全局对象等信息都需要进行初始化操作,包括构造函数(初始化对象)和析构函数(清理对象)。
- 在这段汇编代码中,也就是那个"_GLOBAL__sub_I_main"函数,它是C++全局变量和静态变量的构造函数,它调用了预初始化函数 "
ios_base::Init()",并注册了一个在程序退出时调用的析构函数 "__cxa_atexit"。 - 在"
.init_array" section中,定义了一个"_GLOBAL__sub_I_main"的地址,这是在程序启动时需要调用的所有C++全局和静态对象的初始化函数列表,编译器链接这个列表并在程序启动时依次调用这些初始化函数。 - 总之,这两个section的存在是为了保证C++全局变量和静态变量的正确初始化。
其中四条指令都定义了一些符号或变量,并分配了一些内存空间,这些在程序里的意义如下:
- "
.quad _GLOBAL__sub_I_main":
在程序启动时,将调用所有全局静态对象的构造函数。这些构造函数被放在一个名为"_GLOBAL__sub_I_xxx"的section中,而每个section都是由一个指向该section所有对象的地址列表所引用。这里的".quad _GLOBAL__sub_I_main"是为了将"_GLOBAL__sub_I_main"函数的地址添加到该列表中。
- "
.local _ZStL8__ioinit":
这条指令定义了一个本地符号"_ZStL8__ioinit",它表示C++标准输入输出的初始化过程。由于该符号是一个本地符号,所以只能在编辑该文件的当前单元中使用该符号。
- "
.comm _ZStL8__ioinit,1,1":
这条指令定义了一个名为"_ZStL8__ioinit"的未初始化的弱符号,并为该符号分配了1个大小的字节空间。这个弱符号定义了一个C++标准输入输出部分的全局状态对象。在全用动态库时,不同的动态库可能有自己的IO状态,所以为了确保C++输入输出的状态正确,需要为其指定一个单独的段来存储这些状态数据。在这里,".comm _ZStL8__ioinit,1,1"将会为"_ZStL8__ioinit"符号分配一个字节大小的空间。
- "
.hidden __dso_handle":
这条指令定义了一个隐藏的符号 "__dso_handle"。这个符号是一个链接器生成的隐式变量,其定义了一个指向被当前动态库使用的全局数据对象的一个指针。该符号在被链接进来的库中是隐藏的,不会被其他库或者main函数本身调用,但是在main返回后,可以用来检查库是否已经被卸载。
末尾的元数据¶
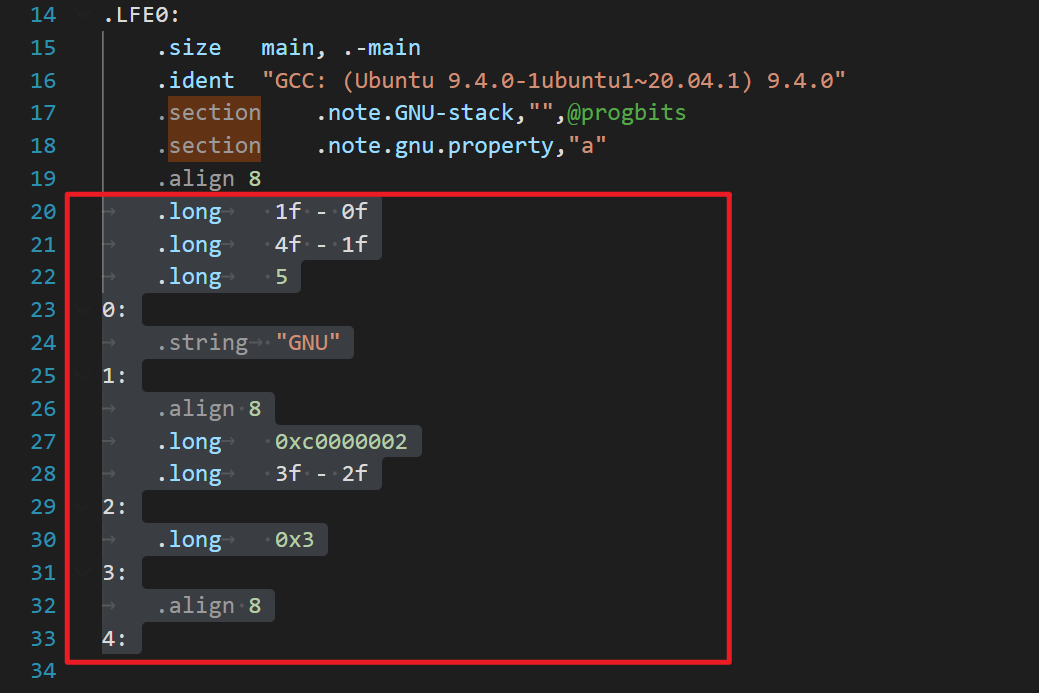
这段代码是一些特殊的指令和数据,主要是用于向可执行文件添加一些元数据(metadata)。这些元数据可能包含各种信息,如调试信息、特定平台的指令集支持等等。
具体来说:
- ".long"指令用于定义一个长整型数值,这里用来计算地址之间的差值。
- 例如,第一行"
.long 1f - 0f"建立了一个长整型数值,表示"1:"标签相对于当前指令地址(即0f)的偏移量。偏移量可以用来计算标签对应的指令地址,从而可用于跳转或计算指针偏移量。 - "
4f - 1f",即"4:"标签相对于"1:"标签的偏移量; - "
.long 0xc0000002"表示这是一个特殊的属性标记,标识这个文件可以在Linux平台上执行。它是用来告诉操作系统这个程序是用特定指令集编译的。 - "
.long 0x3"表示另一个属性标记,表示这个文件可以加载到任意地址。
总之,这些元数据可能对程序运行起到关键作用,但在大多数情况下可能都没有明显的作用,因此看起来没有用。
比较汇编的debugging symbols¶
执行gcc -S -g testBigExe.cpp -o testDebug.s,对比之前的汇编文件,由72行变成9760行。
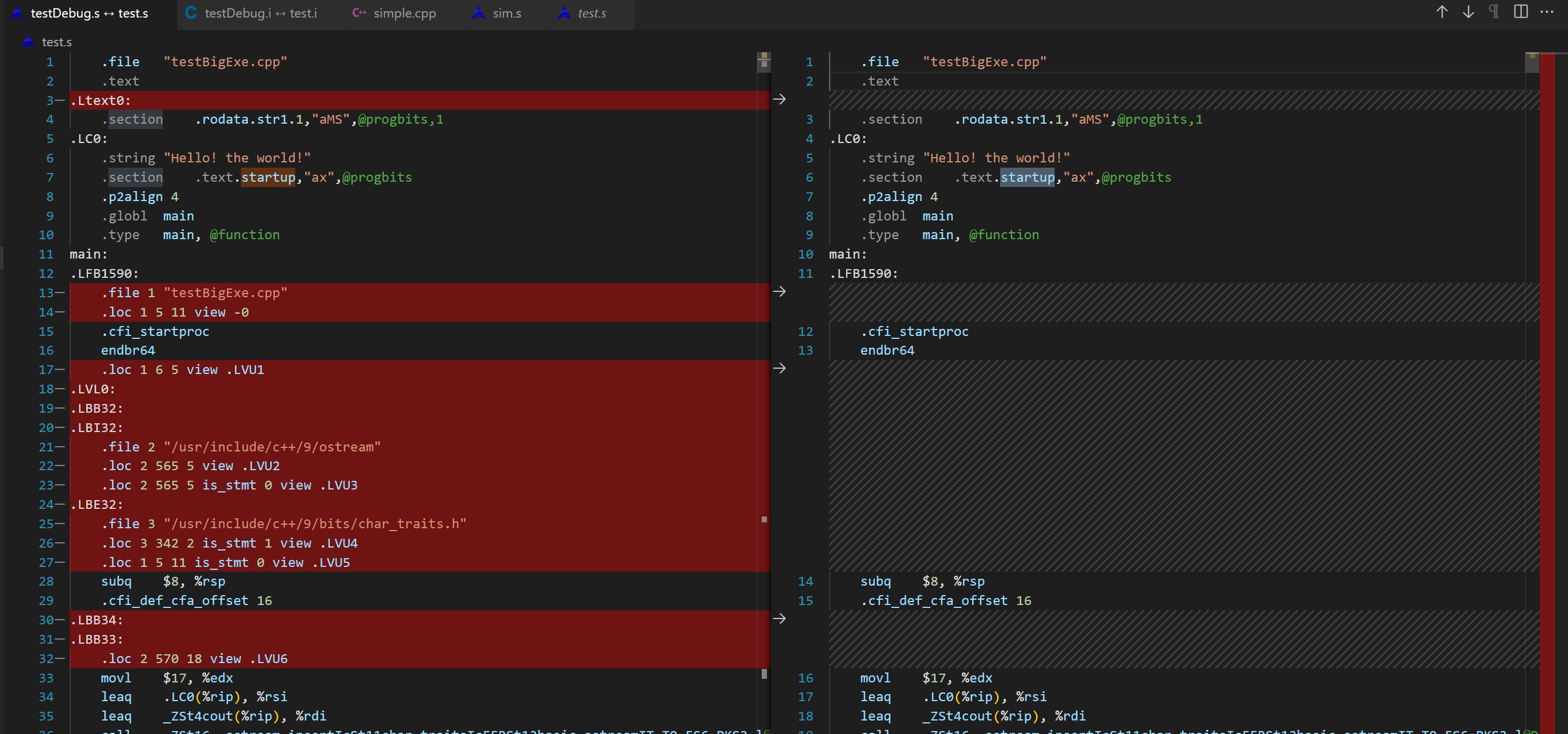
.loc¶
.LBE32:
.file 3 "/usr/include/c++/9/bits/char_traits.h"
.loc 3 342 2 is_stmt 1 view .LVU4
.loc 1 5 11 is_stmt 0 view .LVU5
- 第一行:
.loc 3 342 2表示当前指令对应的源代码文件ID为3,在第342行,第2列(其中第1列是行号,第2列是第几个字符),同时is_stmt为1表示这条指令是语句的起始位置。 - 第二行:
.loc 1 5 11表示当前指令对应的源代码文件ID为1,在第5行,第11列,同时is_stmt为0表示这条指令不是语句的起始位置。 view .LVU4表示当前指令所处的作用域(scope)是.LVU4。作用域是指该指令所在的函数、代码块等一段范围内的所有变量和对象的可见性。在这个例子中,.LVU4 是一个局部变量作用域,因为它是位于一个C++标准库头文件中的一个函数的起始位置。
debug section¶
新增的这些 section 存储了 DWARF 调试信息。DWARF(Debugging With Attributed Record Formats)是一种调试信息的标准格式,包括代码中的变量、类型、函数、源文件的映射关系,以及代码的编译相关信息等等。
具体来说,这些 section 存储的内容如下:
.debug_info:包含程序的调试信息,包括编译单元、类型信息、函数和变量信息等。.debug_abbrev:包含了 .debug_info 中使用到的所有缩写名称及其对应的含义,用于压缩格式和提高效率。.debug_loc:存储每个程序变量或表达式的地址范围及其地址寄存器、表达式规则等信息。在调试时用来确定变量或表达式的值和范围。.debug_aranges:存储简化版本的地址范围描述,允许调试器加速地定位代码和数据的位置。.debug_ranges:存储每个编译单元(CU)的地址范围,每个范围都是一个有限开区间。.debug_line:存储源代码行号信息,包括每行的文件、行号、是否为语句起始位置等信息。.debug_str:包含了所有字符串,如文件名、函数名等,由于每个调试信息的数据都是字符串,因此这是所有调试信息的基础。
需要注意的是,这些 section 中的信息是根据编译器的配置和选项生成的,因此不同编译器可能会生成略有不同的调试信息。
需要进一步的研究学习¶
- 在编译的过程中,哪个阶段 label会变成真实执行地址
遇到的问题¶
暂无