Processing In/near Memory
缘由¶
- 指令为中心,数据移动带来的功耗墙,性能墙
- 内存计算的经典模式
- 3D的内存技术
- Through silicon vias
- ReRAM 新型结构
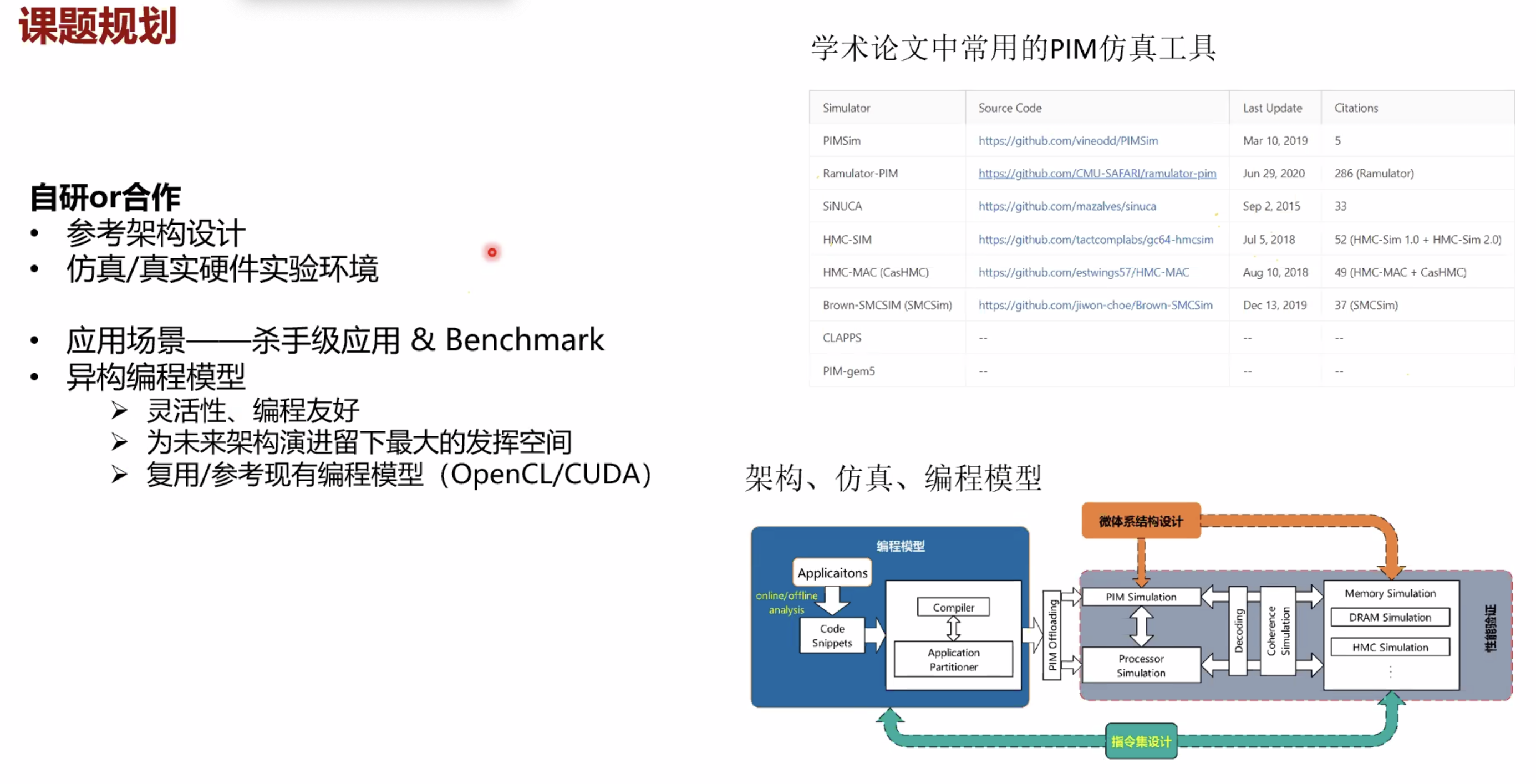
PIM分类¶
-
按照PIM core和memory的距离分类
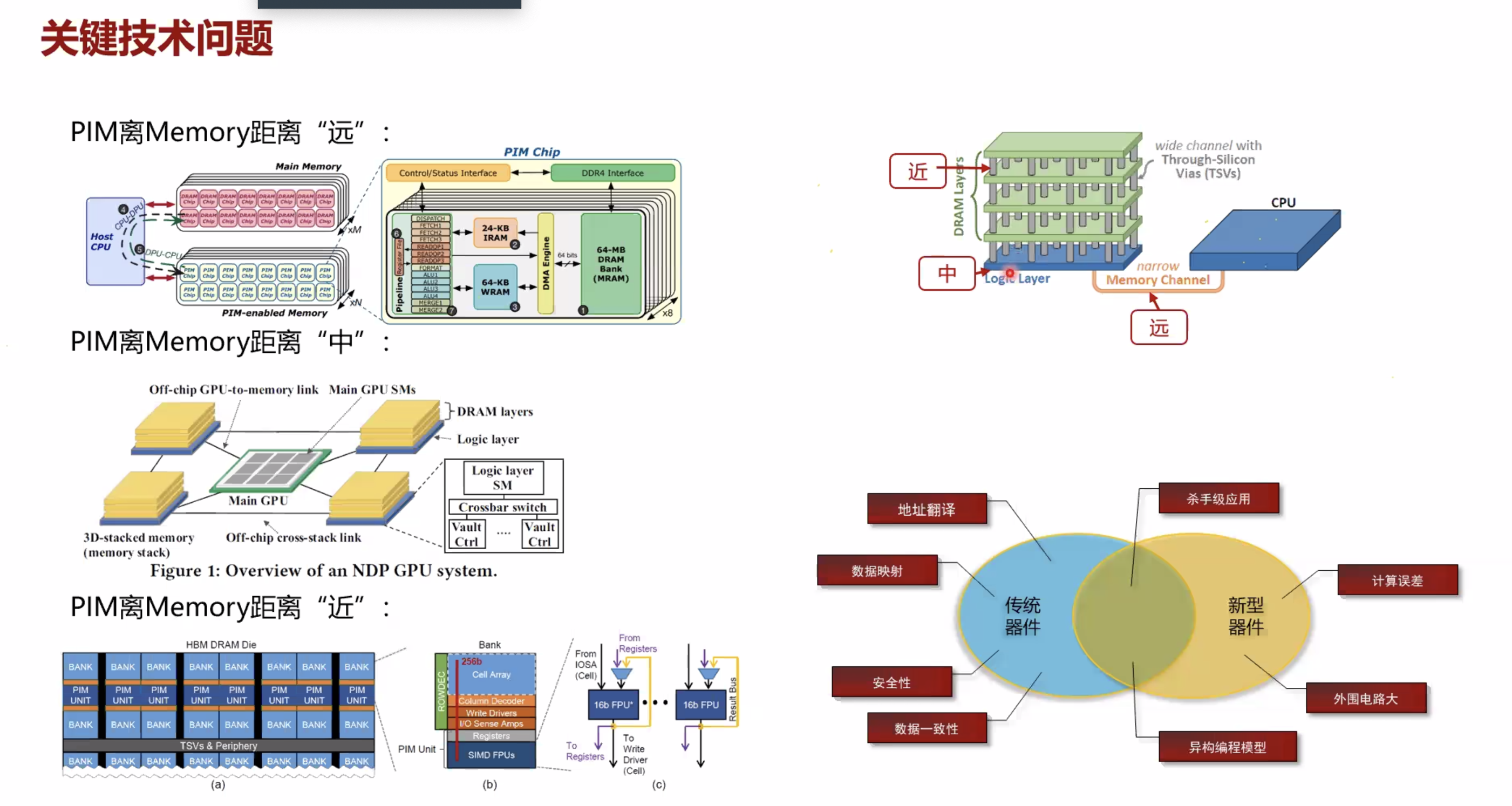
-
新的内存工艺使得内存的最小电路单元具有计算能力(忆阻器)
- 基于现有的商业DRAM和处理器的设计(加速的上限低一些,但是落地推广应用的阻力也越小, 应用范围更广,编程困难低)
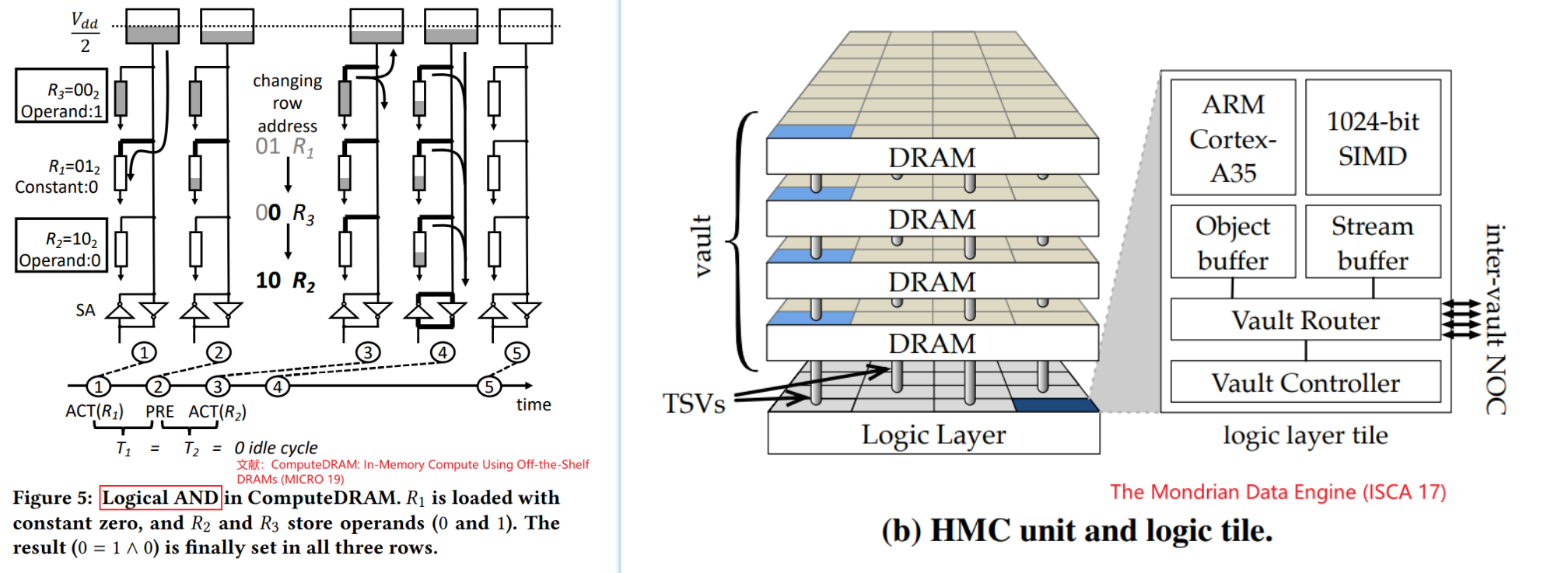
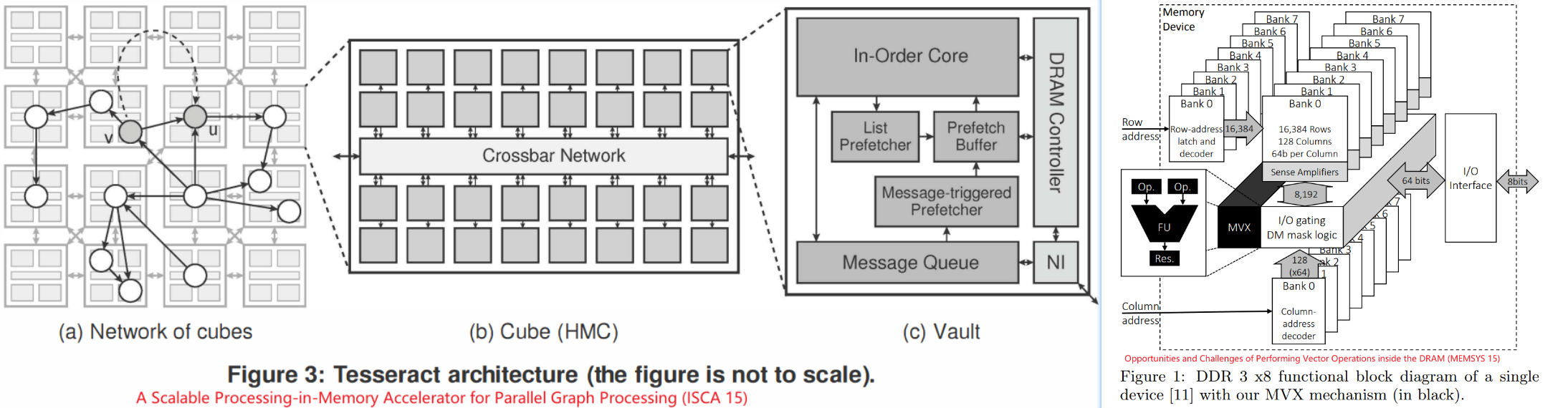
- 基于3D堆叠memory(HMC)的设计(Starting from HMC 2.0, it supports the execution of
18 atomic operations in its logic layer.)
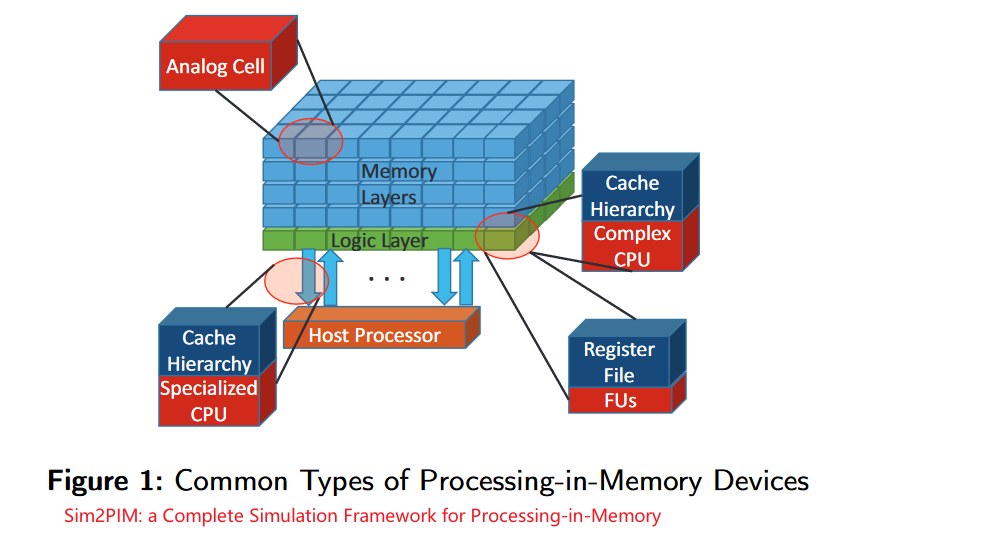
- 在每个最小存储单元融入计算能力(可以结合忆阻器)
- 完整的处理器核,有cache hierarchy
- 简单一点的应用相关的硬件计算单元
- 或者更简单的Functional Units (FUs)
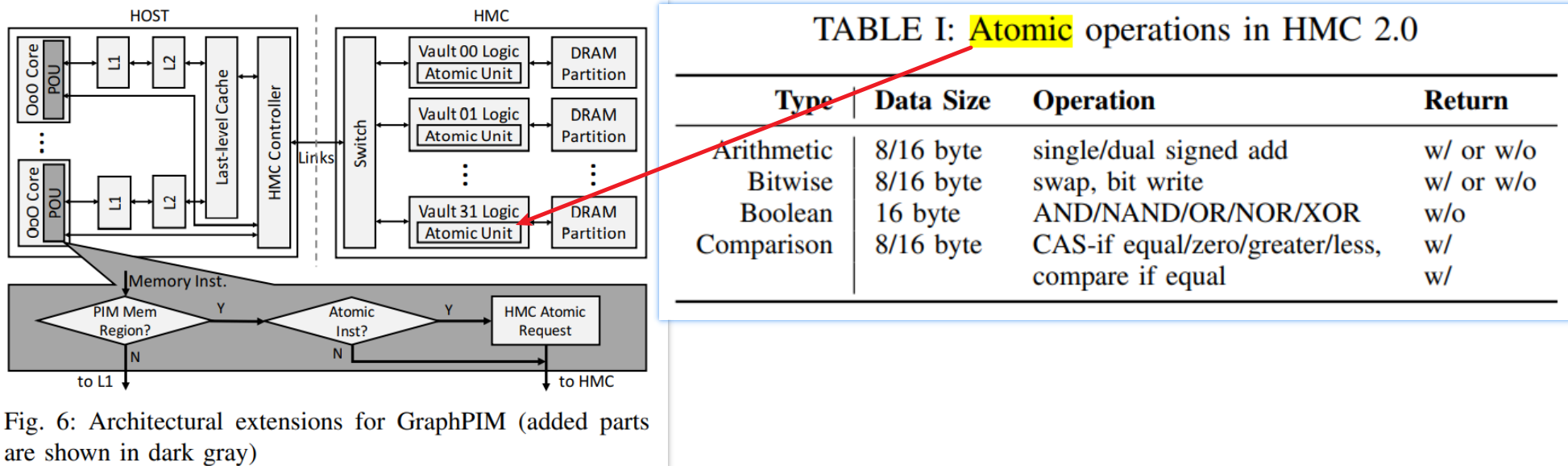
关键技术¶
- 传统器件
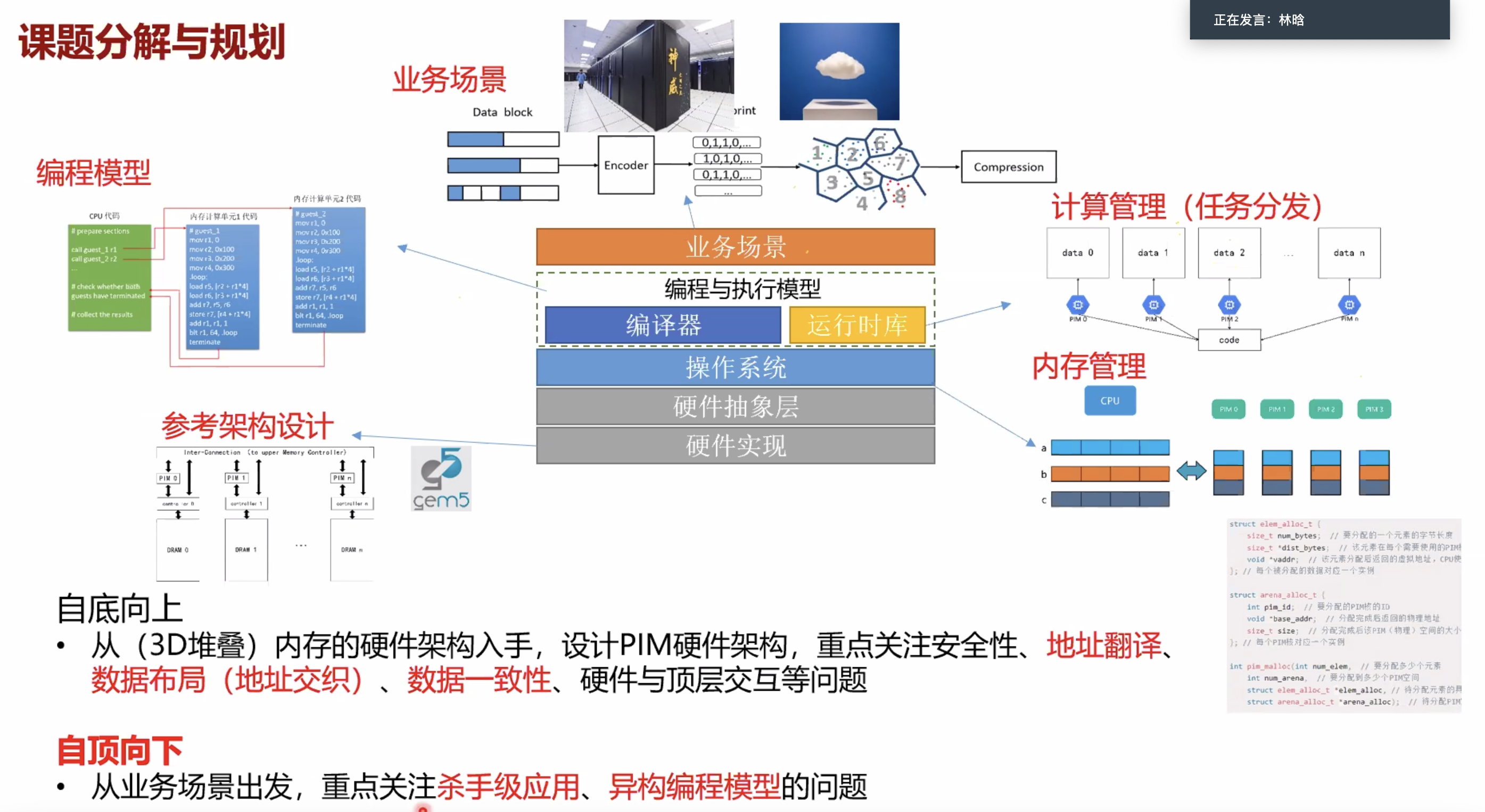
- 地址翻译
- 三种不同解决思路
- 全部由CPU负责指令的发射和翻译
- 使能PIM侧页表管理,翻译机制
- 物理地址空间隔离(交互时需要拷贝),PIM独立管理地址空间
- 三种不同解决思路
- 数据映射
- 物理内存地址排列的冲突(比如 GPUbank)
- CPU高带宽访存(会把数据分散来实现高带宽) vs PIM空间局部性(连续数据会跨多个颗粒)
- 纯软件方案或者软硬件结合大方案
- 物理内存地址排列的冲突(比如 GPUbank)
- 安全性
- 物理内存被暴露在PIM core下,需要新的机制来确保内存安全。
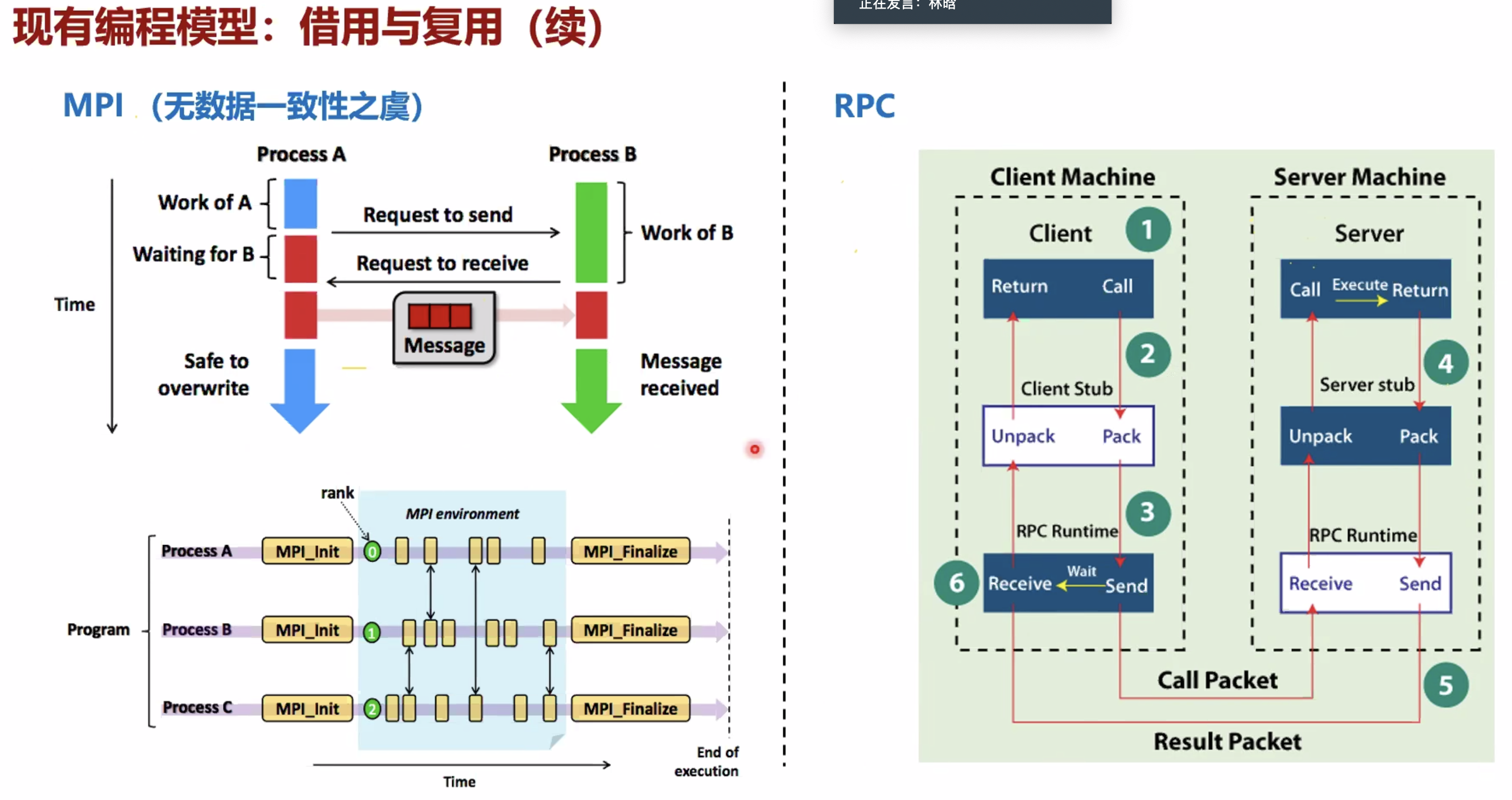
- 数据一致性
- 现有一致性协议拓展差
- 核数量超级多,成千上万
- 解决方法
- 内存空间隔离,避免共享
- 弱化一致性问题,只处理特殊条件下一致性(eg.任务迁移)
- 批量处理一致性请求
- 新型器件
- 计算误差
- 外围电路大
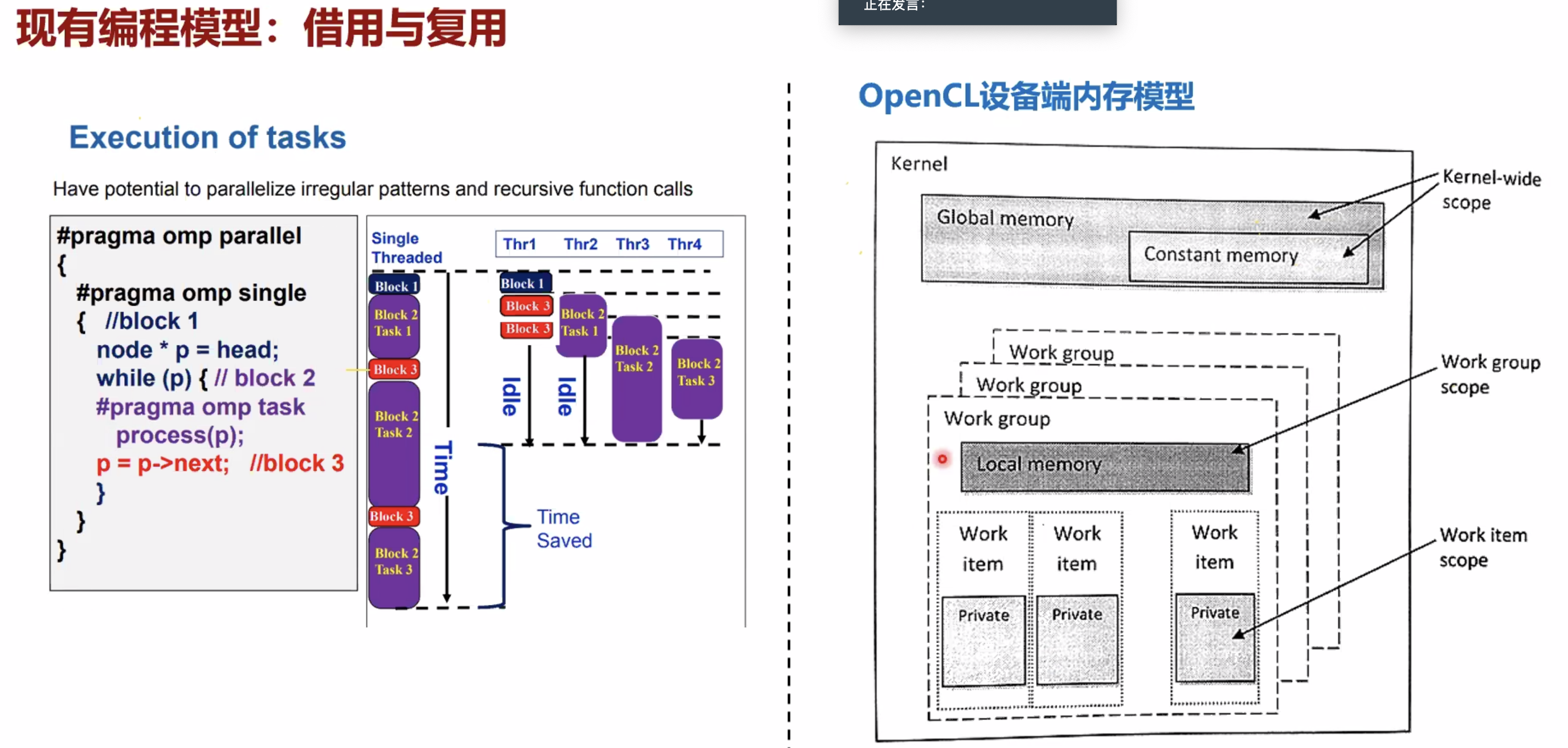
- 异构编程模型
- 应用场景和编程模型
- 高能效比
- 高并行和NUMA访问
- 识别PIM函数的条件(什么函数适合用PIM做)
- 在所有函数中能耗最高
- 数据移动占据应用大比例,或者说是唯一的
- 访存密集型(通过LLC miss rate来判断)
根据PIM距离Memory的距离分成三类 1. NDP GPU 2. ? 3. ?
论文1¶
https://arxiv.org/pdf/2110.01709.pdf
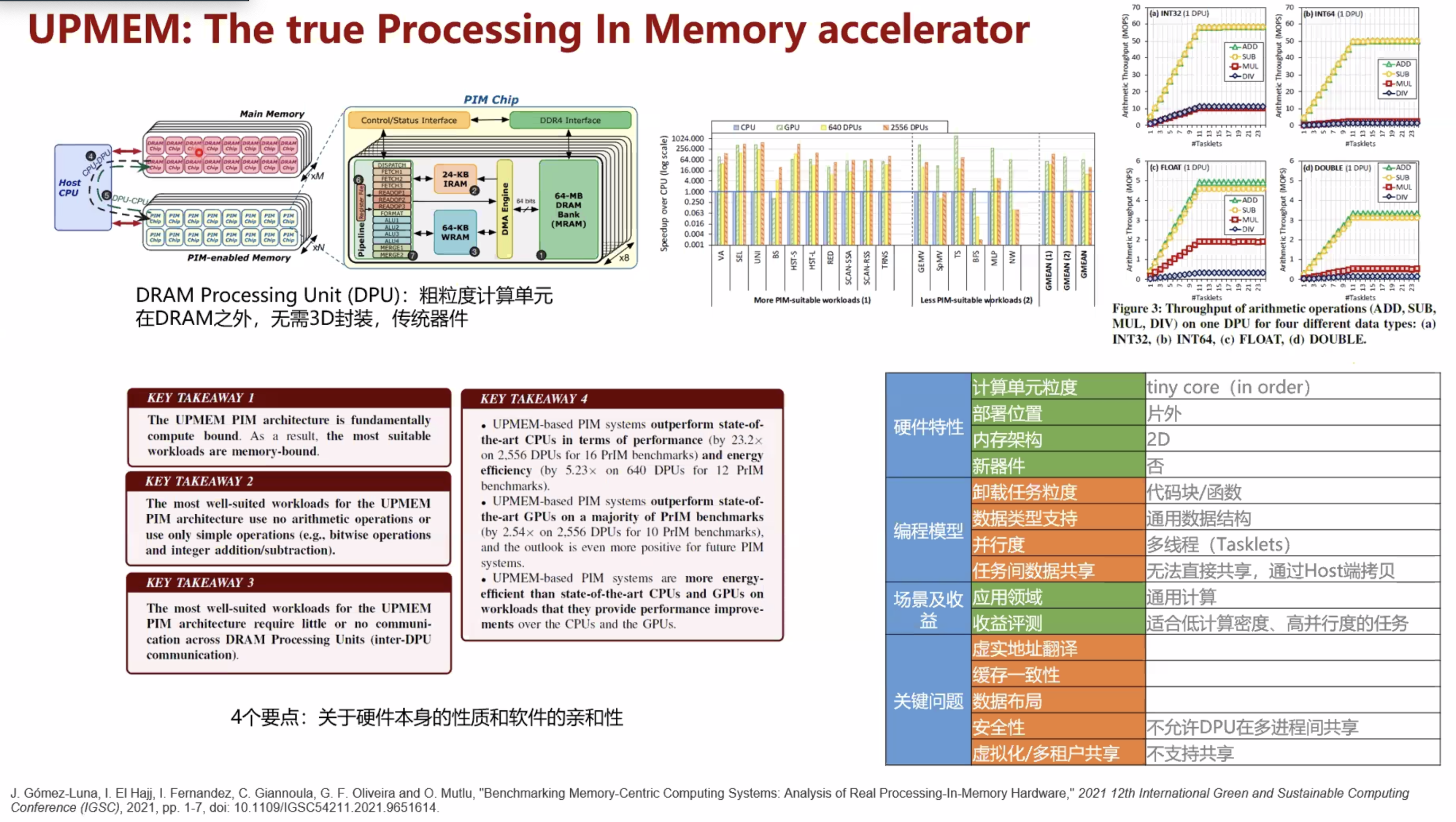
论文2¶
hardware architecture and software stack for pim based on commercial dram technology

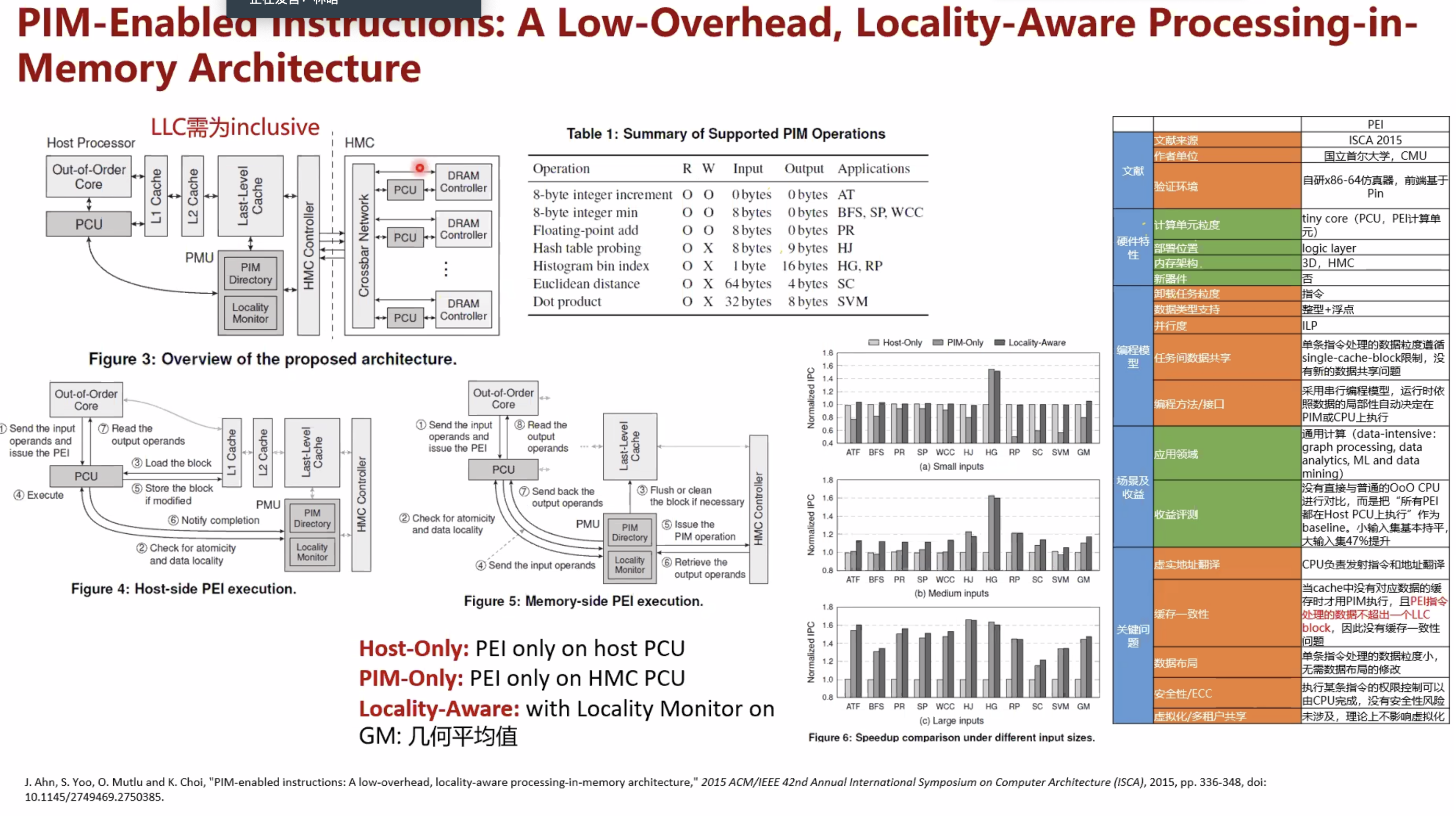
论文3¶
pim-enabled instructions a low-overhead locality-aware processing-in-memory architecture
论文4¶
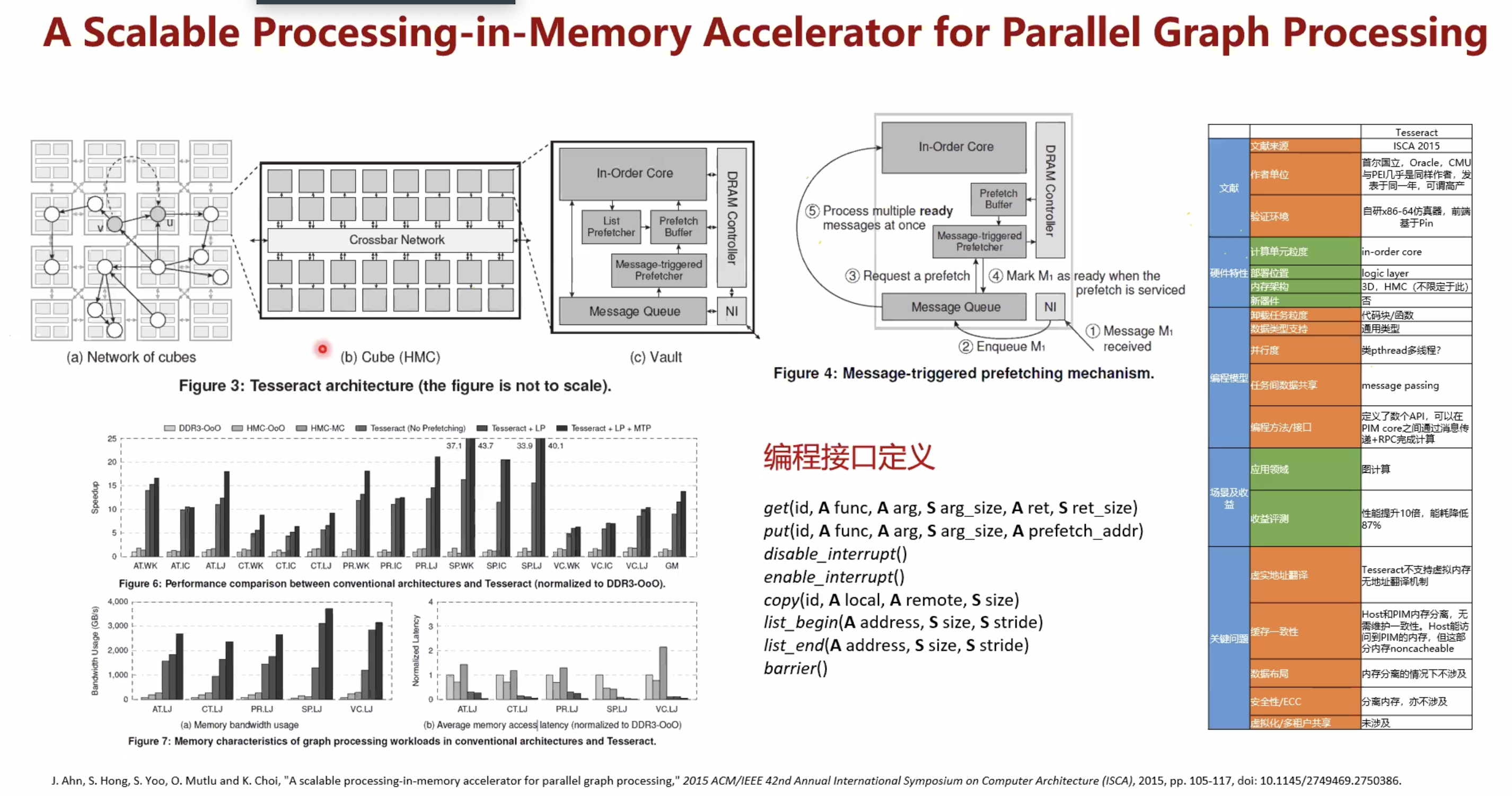
展望¶

问题¶
- 由于核很小,不支持OS
- 但是可以支持message pass(reduce等)
- HPC应用经过数学变化后有些变成稀疏计算的,这时候变成memory-bound。所以PIM减少了数据移动,这时提升比较大。
- PIM的优势在于能效比,功耗的降低。而不是绝对性能。
- 单chip多核怎么通过PIM的思想,软件调度来实现?(不就是减少数据移动,和更近)
需要进一步的研究学习¶
暂无
遇到的问题¶
暂无
开题缘由、总结、反思、吐槽~~¶
参考文献¶
无