Microarchitecture: Micro-Fusion & Macro-Fusion
Micro-Fusion¶
历史原因¶
- 有很多对内存进行操作的指令都会被分成两个或以上的μops,如 add eax, [mem] 在解码时就会分成 mov tmp, [mem]; add eax, tmp。这类型的指令在前端只需要fetch与decode一条指令,相比原来的两条指令占用更少资源(带宽、解码资源、功耗),不过由于在解码后分成多个μops,占用资源(μop entries)增多,但是throughput相对较小,使得RAT以及RRF阶段显得更为拥堵。
- 随着技术的发展,CPU内部指令处理单元(execution unit)以及端口(port)增多。相对,流水线中的瓶颈会出现在register renaming(RAT)以及retirement(RRF)
为了突破RAT以及RRF阶段的瓶颈,Intel从Pentium M处理器开始引入了micro-fusion技术。
解决办法¶
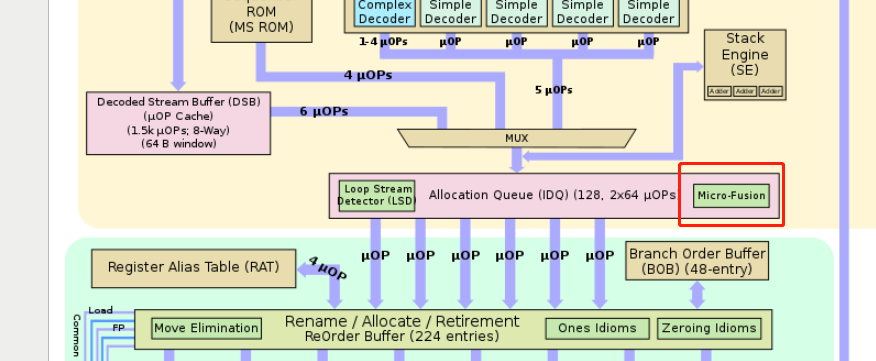 在RAT以及RRF阶段,把同一条指令的几个μops混合成一个复杂的μop,使得其只占用一项(比如在ROB里,但是Unlaminated μops会占用2 slots);
在RAT以及RRF阶段,把同一条指令的几个μops混合成一个复杂的μop,使得其只占用一项(比如在ROB里,但是Unlaminated μops会占用2 slots);
而在EU阶段,该复杂μop会被多次发送到EU中进行处理,表现得像是有多个已被分解的μops一样。(每个uops还是要各自运行)
可以micro-fused的指令¶
其中一条uops是load或者store
- 所有的store指令,写回内存的store指令分为两个步骤:store-address、store-data。
- 所有读内存与运算的混合指令(load+op),如:
- ADDPS XMM9, OWORD PTR [RSP+40]
- FADD DOUBLE PTR [RDI+RSI*8]
- XOR RAX, QWORD PTR [RBP+32]
- 所有读内存与跳转的混合指令(load+jmp),如:
- JMP [RDI+200]
- RET
- CMP与TEST对比内存操作数并与立即数的指令(cmp mem-imm)。
例外的指令¶
不能采用RIP寄存器进行内存寻址:
采用了RIP寄存器进行内存寻址的指令是不能被micro-fused的,并且这些指令只能由decoder0进行解码。Macro-Fusion¶
历史原因¶
为了占用更少的资源,Intel在酷睿处理器引入macro-fusion(Macro-Op Fusion, MOP Fusion or Macrofusion)
解决办法¶
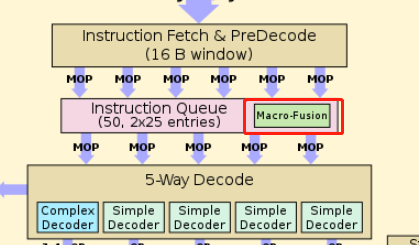 在IQ时读取指令流,把两条指令组合成一个复杂的μop,并且在之后decode等流水线各个阶段都是认为是一项uops。
在IQ时读取指令流,把两条指令组合成一个复杂的μop,并且在之后decode等流水线各个阶段都是认为是一项uops。
macro-fused后的指令可以被任意decoder进行解码
可以macro-fused的指令¶
其他架构ARM,RISC-V见wikiChip
Intel的要求如下:
1. 两条指令要相互紧邻
2. 如果第一条指令在缓存行的第63个字节处结束,而第二条指令在下一行的第0个字节处开始,则无法进行fusion。
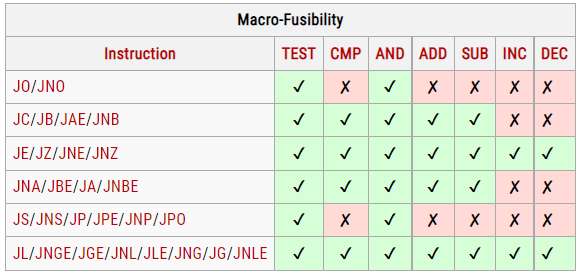
3. 两条指令要满足下表,更新的架构可能会拓展
4. 
需要进一步的研究学习¶
暂无
遇到的问题¶
暂无
开题缘由、总结、反思、吐槽~~¶
参考文献¶
https://www.cnblogs.com/TaigaCon/p/7702920.html
https://blog.csdn.net/hit_shaoqi/article/details/106630483