Nvidia Arch : Ampere & Hopper & Pascal
基本概念¶
GPU Processing Clusters (GPCs),
Texture Processing Clusters (TPCs),
Streaming Multiprocessors (SMs)¶
- CUDA cores: basic integer/floating point arithmetic – high throughput, low latency
- Load/Store (LD/ST): issues memory accesses to appropriate controller – possibly high latency
- Special Function Unit (SFU): trigonometric math functions, etc – reduced throughput
- special tensor cores (Since Turing and Volta): have specialized matrix arithmetic capabilities
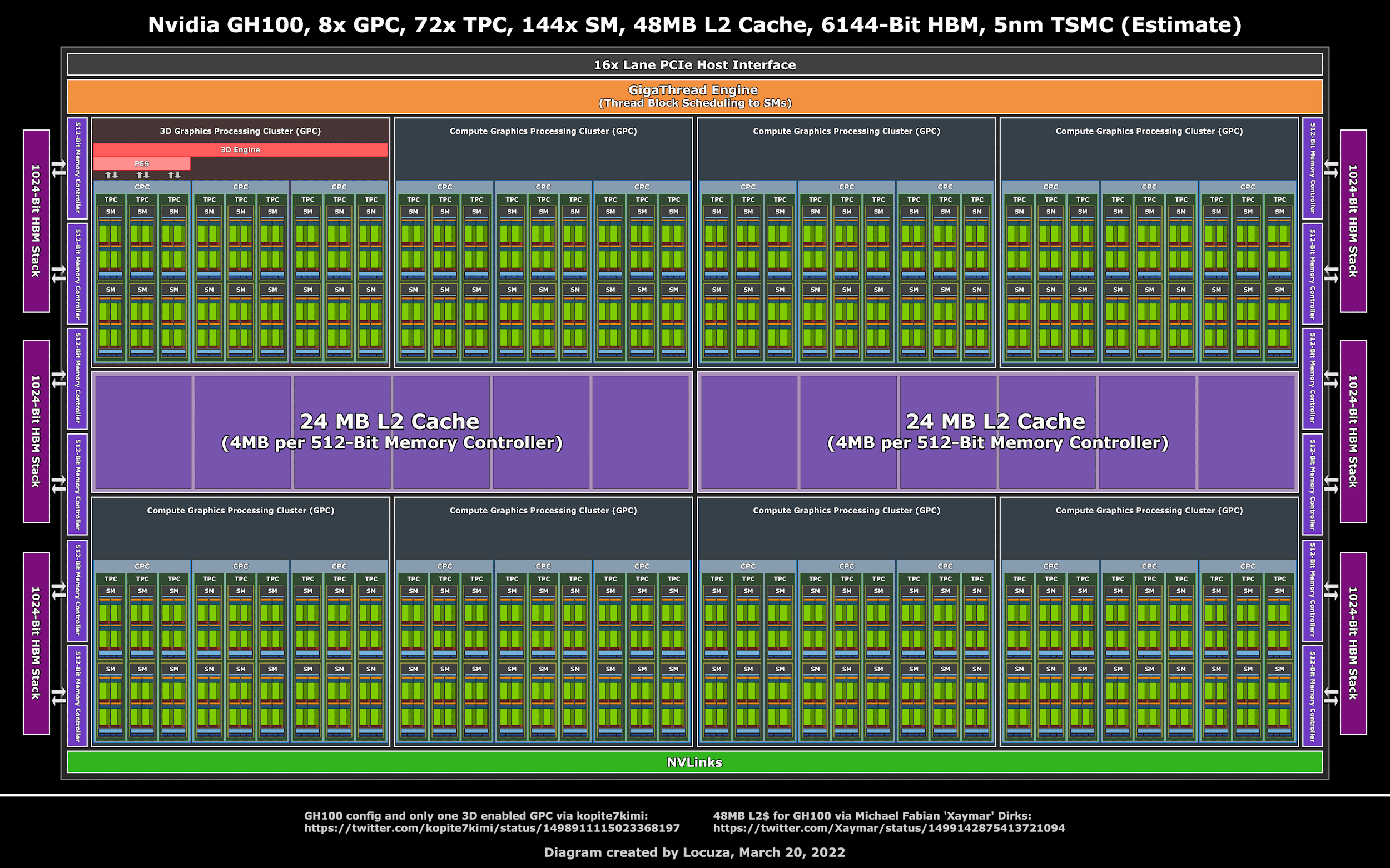
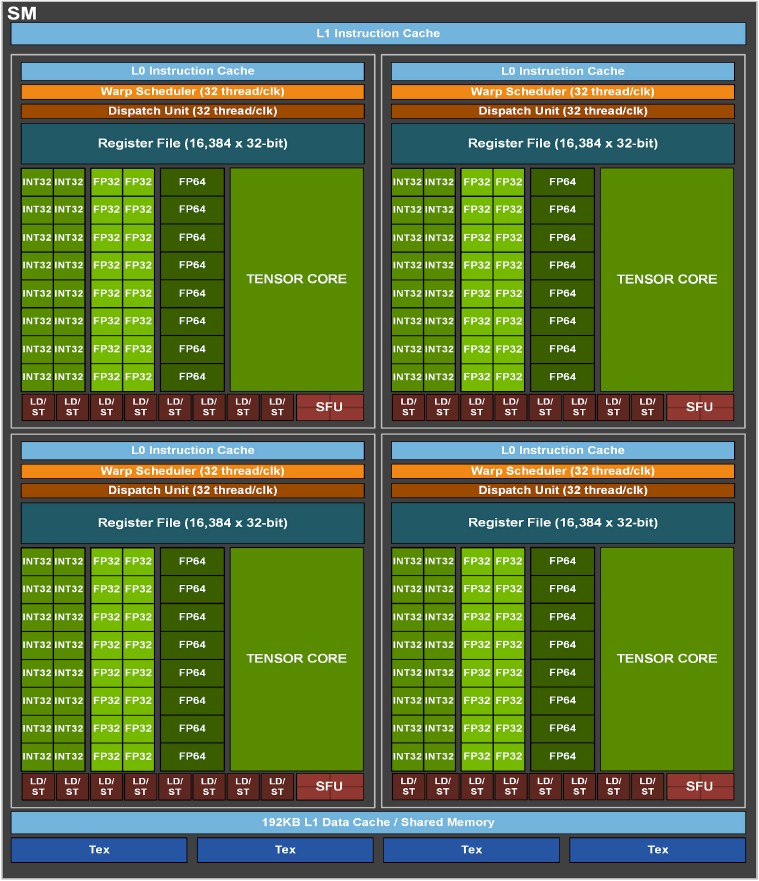
H100¶
GH100¶
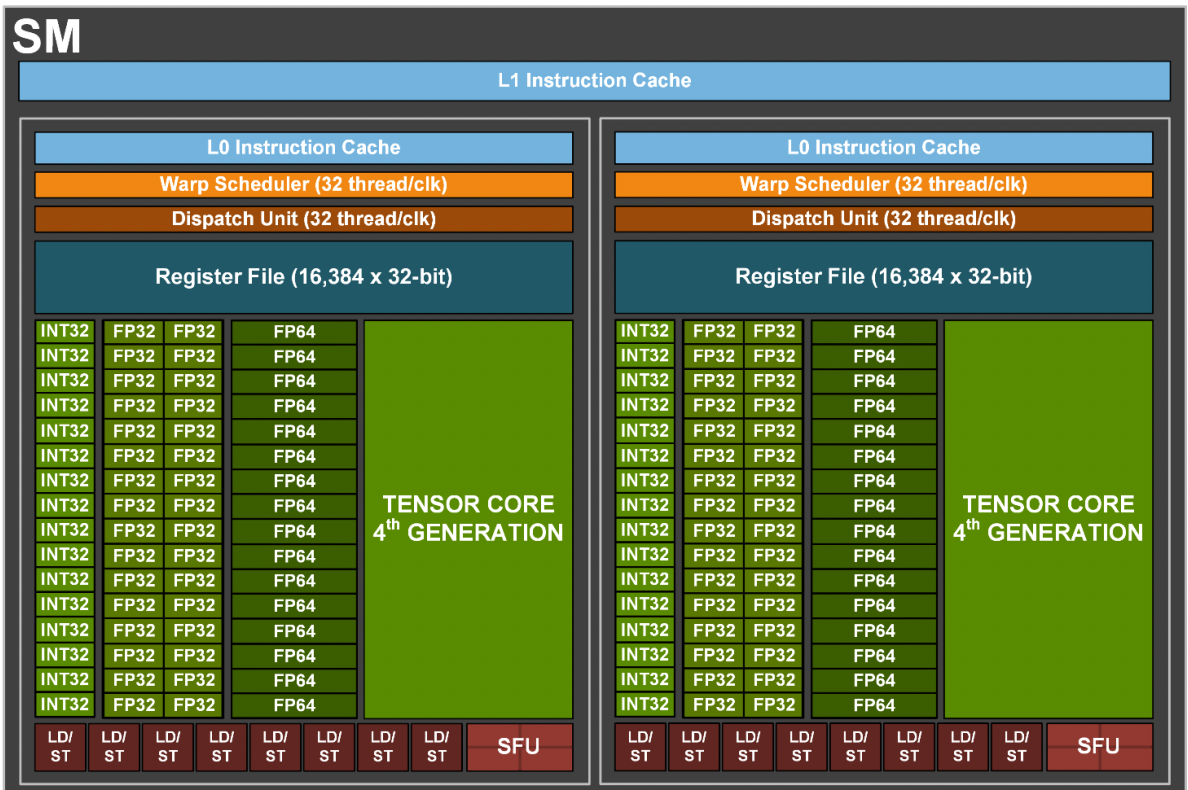
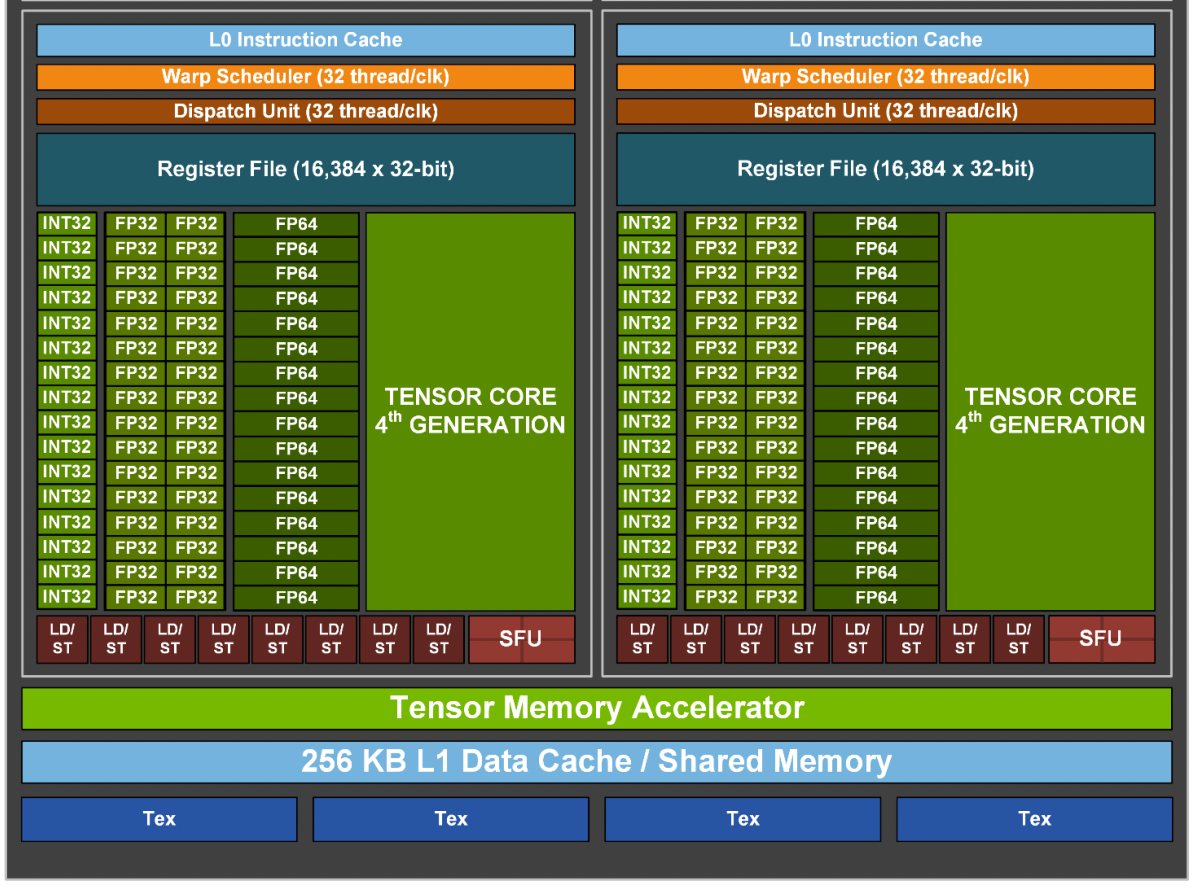
上面两张图组成一个SM,Special Function Units (SFUs)
P40¶
GP102¶

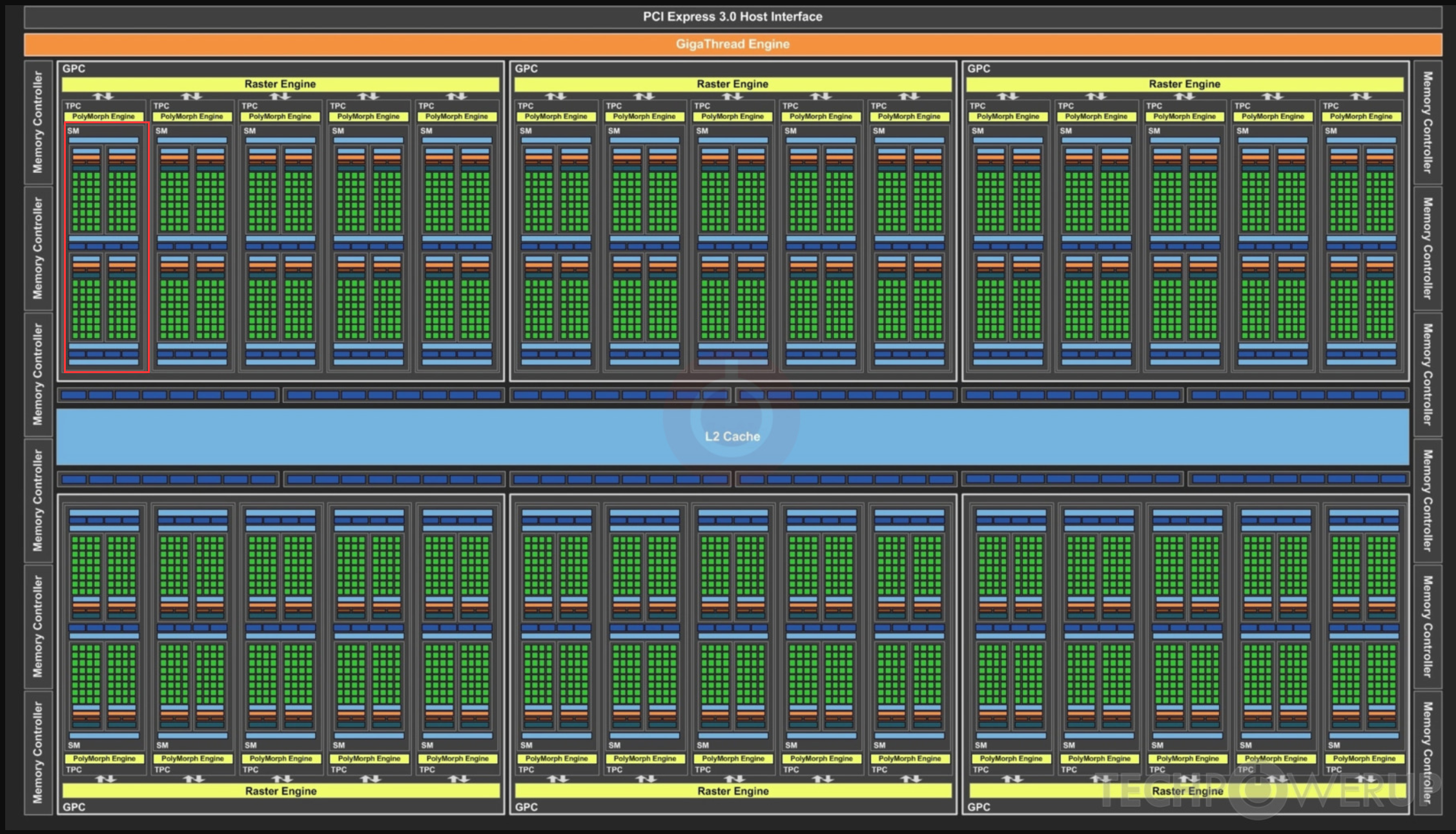 图中红框是一个SM
图中红框是一个SM
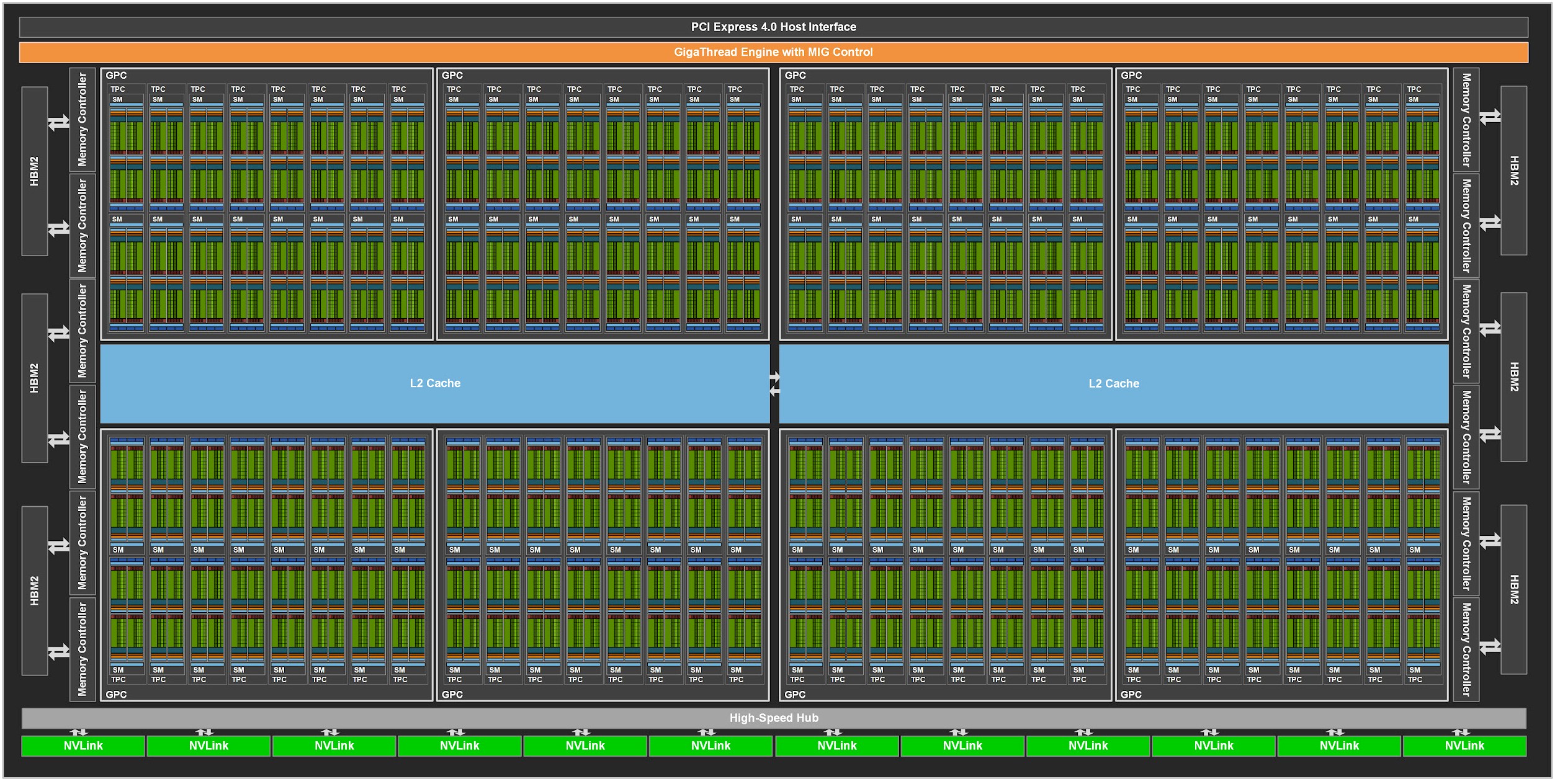
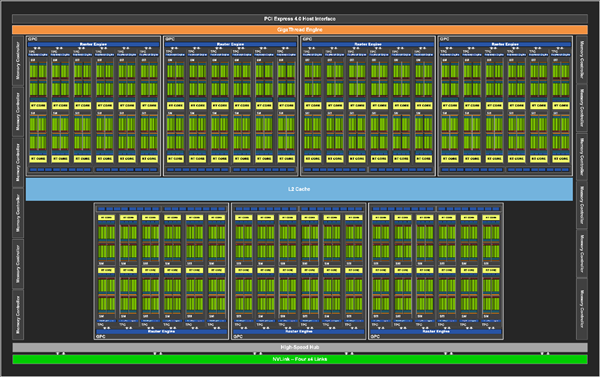
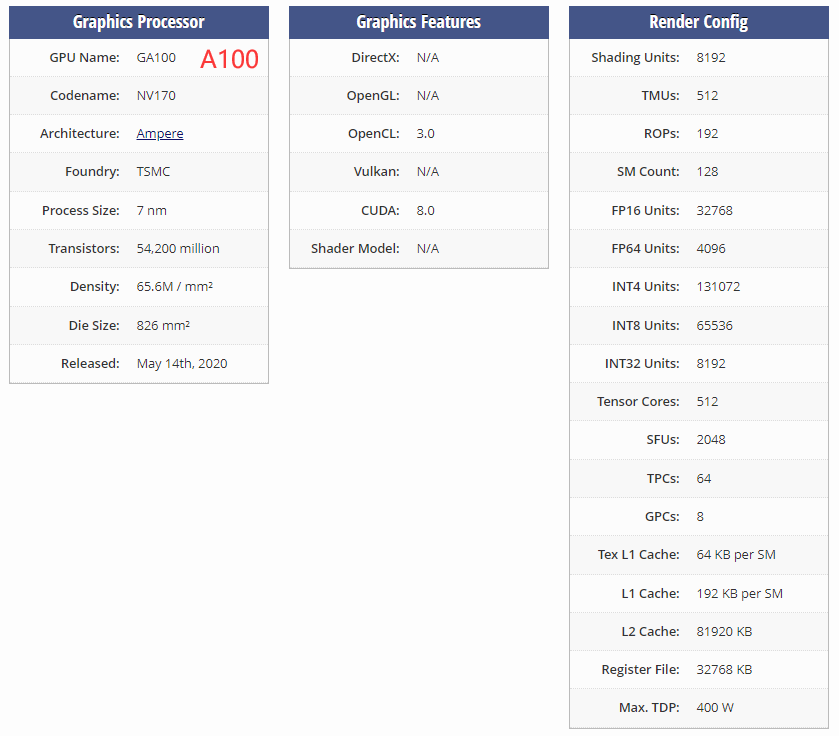
A100¶
GA100¶
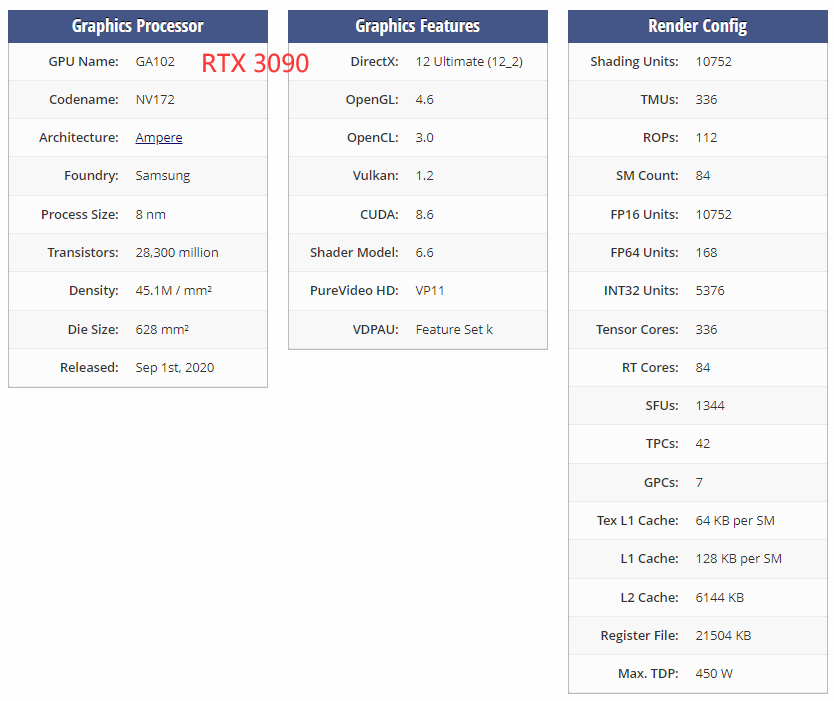
RTX 3090¶
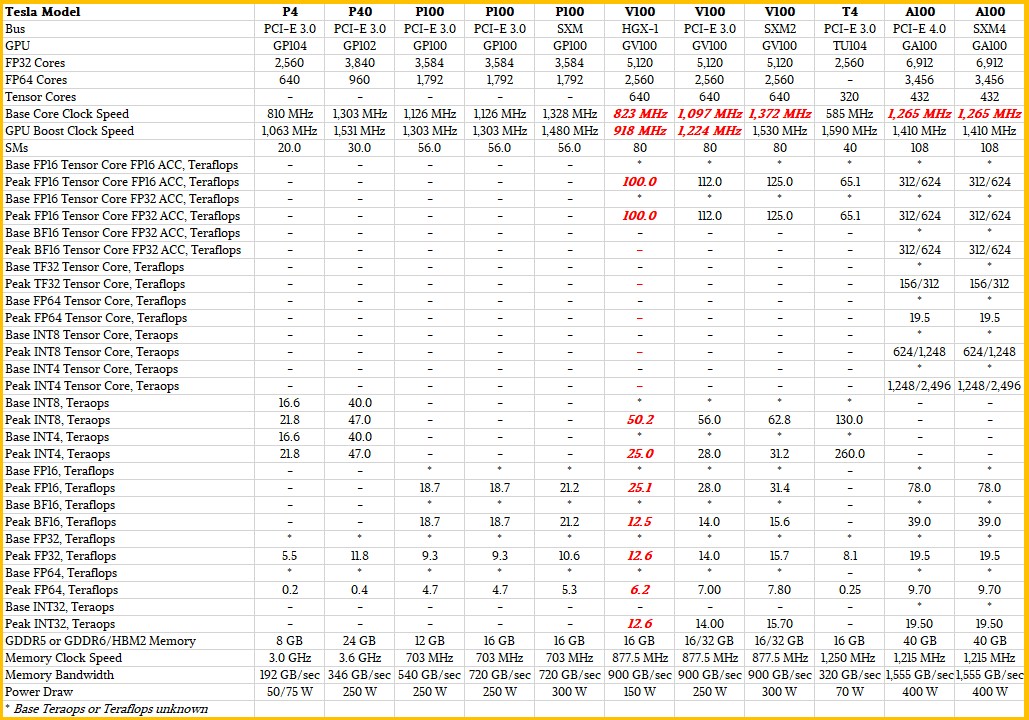
10496个流处理器,核心加速频率1.70GHz,384-bit 24GB GDDR6X显存。
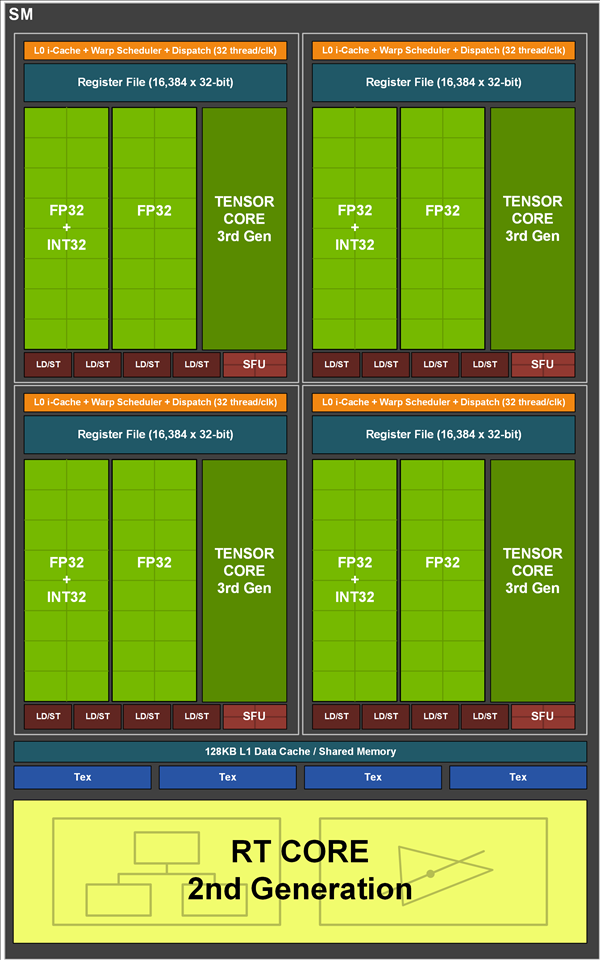
GA102¶
在之前的GA100大核心中,每组SM是64个INT32单元、64个FP32单元及32个FP64单元组成的,但在GA102核心中,FP64单元大幅减少,增加了RT Core,Tensor Core也略微减少。
游戏卡与专业卡的区别¶
- 应用方面不同
- 游戏卡会对三维图像处理有特殊处理,有光线追踪单元
- 专业计算卡,可能对某些格式的解压压缩有特殊单元,或者对半精度计算有特殊支持。
- 做工不同
- 专业卡由于在服务器上24小时不同工作,在多相供电,散热都堆料处理,游戏卡不同(公版,非公版肯定不一样)
- 驱动不同
- 游戏卡对应游戏软件的优化驱动,专业卡有对专业软件的驱动支持
- 价格不同
- 专业卡贵4倍不止。
- 参数的不同,对于同一颗核心(以RTX3090与A100 40G举例)
- A100的GA100是8块完整的,GA102是7块。
- A100领先的地方
1. 堆料完爆对手
2. 显存往往更多,AI应用
3. 访存更快
4. 支持 High bandwidth memory (HBM)
5. 在多精度和半精度有优势(NVIDIA A100 SXM4 40 GB VS.NVIDIA GeForce RTX 3090)

- RTX3090领先的地方 1. 频率更高 2. 有视频输出接口,支持OpenGL,DirectX 3. 有RT core 光追
参考文献¶
https://zhuanlan.zhihu.com/p/394352476