Manual AVX256 SIMD
类型区别¶
The __m256 data type can hold eight 32-bit floating-point values.
The __m256d data type can hold four 64-bit double precision floating-point values.
The __m256i data type can hold thirty-two 8-bit, sixteen 16-bit, eight 32-bit, or four 64-bit integer values
向量预取¶
Load & Store¶
__m256i _mm256_loadu_epi32 (void const* mem_addr) //读入连续的256位数据,为32位int
_mm256_lddqu_si256 //上面识别不了也可以考虑这个
__m256d _mm256_loadu_pd (double const * mem_addr) // 读入连续4个double
__m256d _mm256_broadcast_sd (double const * mem_addr) // 读取一个double,并复制4份
__m256d _mm256_i64gather_pd (double const* base_addr, __m256i vindex, const int scale) // 间隔读取
scatter // 类似间隔读取
_mm512_mask_prefetch_i32extgather_ps // 有选择预取
mask // 根据掩码选择不读,0等操作
不连续读取¶
long long int vindexList = [0,2,4,6];
__m256i vindex = __mm256_loadu_epi64(vindexList);
__m256d vj1 = __mm256_i64gather_pd(&rebuiltCoord[jj*k], vindex, 1);
设置每个元素¶
__m256d _mm256_set_pd (double e3, double e2, double e1, double e0) // 设置为四个元素
__m256d _mm256_set1_pd (double a) // 设置为同一个元素
Arithmetic¶
_mm256_hadd_epi16 // Horizontally add eg.dst[15:0] := a[31:16] + a[15:0]
_mm256_mulhi_epi16 // Multiply the packed signed 16-bit integers in a and b, producing intermediate 32-bit integers, and store the high 16 bits of the intermediate integers in dst.
_mm256_sign_epi16 // 根据b的值,将-a/0/a存入dst
// 乘加,乘减,的计算组合也有
横向结果归约¶
手动实现向量浮点abs绝对值¶
static const double DP_SIGN_One = 0x7fffffffffffffff;
__m256d vDP_SIGN_Mask = _mm256_set1_pd(DP_SIGN_One);
vj1 = _mm256_and_pd(vj1, vDP_SIGN_Mask);
Shift¶
logic¶
Elementary Math Functions¶
向量化 取反、sqrt
Convert¶
Compare¶
Swizzle(混合)¶
_mm256_blendv_pd // 根据mask结果,从a和b里选择写入dst
_mm_blend_epi32 // 寄存器内数据的移动
_mm256_permute4x64_epi64 // 寄存器高位复制到低位
VEXTRACTF128 __m128d _mm256_extractf128_pd (__m256d a, int offset); // 寄存器内数据的移动
VUNPCKHPD __m512d _mm512_unpackhi_pd( __m512d a, __m512d b); //寄存器内数据的移动
类型转换¶
__m256d _mm256_undefined_pd (void)
__m128i low = _mm256_castsi256_si128(v); //__m256i 变 type __m128i,源向量较低的128位不变地传递给结果。这种内在的特性不会向生成的代码引入额外的操作。
Select4(SRC, control) {
CASE (control[1:0]) OF
0: TMP ←SRC[31:0];
1: TMP ←SRC[63:32];
2: TMP ←SRC[95:64];
3: TMP ←SRC[127:96];
ESAC;
RETURN TMP
}
VSHUFPS (VEX.128 encoded version) ¶
DEST[31:0] ←Select4(SRC1[127:0], imm8[1:0]);
DEST[63:32] ←Select4(SRC1[127:0], imm8[3:2]);
DEST[95:64] ←Select4(SRC2[127:0], imm8[5:4]);
DEST[127:96]←Select4(SRC2[127:0], imm8[7:6]);
DEST[MAXVL-1:128] ←0
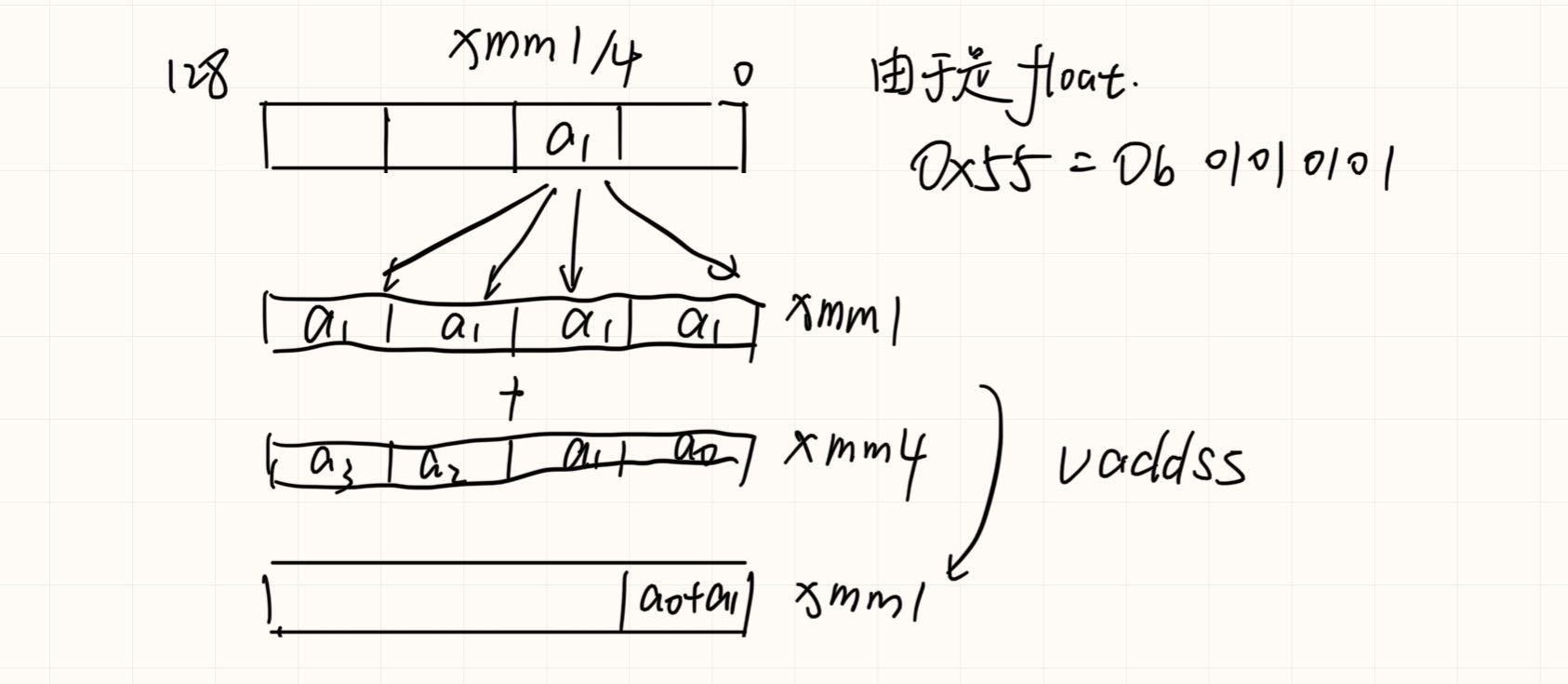 之后float类型转换为double,再求和。
之后float类型转换为double,再求和。
需要进一步的研究学习¶
暂无
遇到的问题¶
暂无
开题缘由、总结、反思、吐槽~~¶
参考文献¶
https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html#text=_mm256_loadu_pd&ig_expand=4317