Intel® Intrinsics Guide
符号说明¶
_mm_sin_ps intrinsic is a packed 128-bit vector of four 32-bit precision floating point numbers.The intrinsic computes the sine of each of these four numbers and returns the four results in a packed 128-bit vector.
ISA¶
AVX2 & AVX¶
AVX2在AVX的基础上完善了256位寄存器的一些实现
FMA¶
float-point multiply add/sub
include 128/256 bits regs
AVX_VNNI¶
AVX-VNNI is a VEX-coded variant of the AVX512-VNNI instruction set extension. It provides the same set of operations, but is limited to 256-bit vectors and does not support any additional features of EVEX encoding, such as broadcasting, opmask registers or accessing more than 16 vector registers. This extension allows to support VNNI operations even when full AVX-512 support is not implemented by the processor.
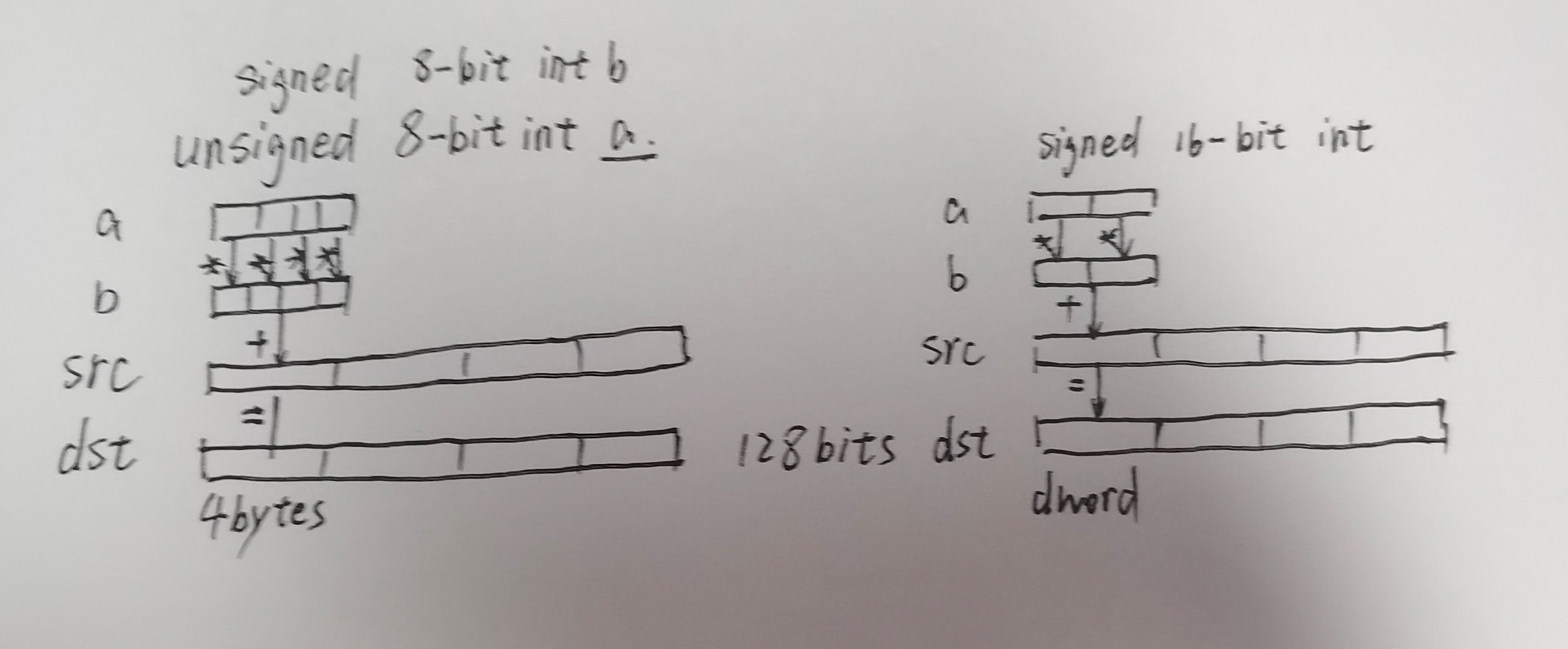
dpbusd //_mm_dpbusd_avx_epi32
dpwssd // b 与 w 是 byte 和dword。 us和ss是ab两数是不是signed
dpwssds // 最后的s是 signed saturation饱和计算的意思,计算不允许越界。
AVX-512¶
有时间再看吧
KNC¶
current generation of Intel Xeon Phi co-processors (codename "Knight's Corner", abbreviated KNC) supports 512-bit SIMD instruction set called "Intel® Initial Many Core Instructions" (abbreviated Intel® IMCI).
https://stackoverflow.com/questions/22670205/are-there-simdsse-avx-instructions-in-the-x86-compatible-accelerators-intel
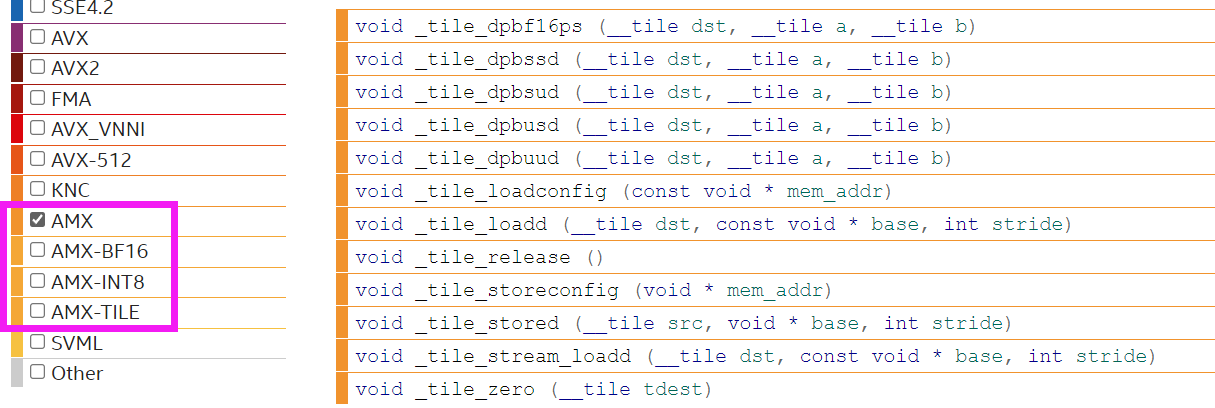
AMX¶
Intel® Advanced Matrix Extensions (Intel® AMX) is a new 64-bit programming paradigm consisting of two components:
* A set of 2-dimensional registers (tiles) representing sub-arrays from a larger 2-dimensional memory image
* An accelerator that is able to operate on tiles; the first implementation of this accelerator is called TMUL (tile matrix multiply unit).
这个不适用于特殊矩阵和稀疏矩阵,这类一般先转换化简再SIMD
SVML¶
Short Vector Math Library Operations (SVML)
The Intel® oneAPI DPC++/C++ Compiler provides short vector math library (SVML) intrinsics to compute vector math functions. These intrinsics are available for IA-32 and Intel® 64 architectures running on supported operating systems. The prototypes for the SVML intrinsics are available in the immintrin.h file.
Using SVML intrinsics is faster than repeatedly calling the scalar math functions. However, the intrinsics differ from the scalar functions in accuracy.
需要进一步的研究学习¶
暂无
遇到的问题¶
暂无