Leetcode
导言
- 简单、中等、困难在10、20、30分钟解决(倒计时计数
- 题解在5、10、20分钟内理解,明白核心考点和解题思想,然后重写。
- ACM模式练习
做了30天的leetcode,发现不会的还是不会。我就知道我
学而不思则罔
脑中一团浆糊,虽然学习了一些常见题型的框架、解法以及例题。
但是遇到新题目,是否能使用这些方法,以及如何转换使用还是没考虑清楚。
基础¶
输入输出处理¶
基础cin如何读取字符,读取字符串
- 接受一个字符串,遇“空格”、“TAB”、“回车”都结束
#include <iostream>
using namespace std;
int main(void)
{
int a, b;
while (cin >> a >> b) { }// 读到EOF结束
while (cin) { // 读到EOF结束
char ch = cin.get() //读取一个字符
}
return 0;
}
其余处理
cout输出处理
#include <iomanip>
// 也可以使用 #include <bits/stdc++.h>
int main(void){
int a = 255;
cout << hex << a << endl;//以十六进制的形式输出
cout << dec << a << endl;//以十进制的形式输出
cout << oct << a << endl;//以八进制的形式输出
//结果分别是ff 255 377
return 0;
}
int main(void){
double x = 3.141592658;
//控制输出的宽度,就是printf("%10d");
cout << setw(10) << x << endl;
//限制输出有效数字的个数是5
cout << setprecision(5) << x << endl;
//fixed表示控制小数点后面的数字,两个连用就是小数点后面保留三位小数
cout << fixed << setprecision(3) << x << endl;
//输出结果分别是 3.14159 3.1416 3.142
return 0;
}
魔鬼数字与同义词¶
降低圈复杂度¶
利用map来简化实际情况的复杂判断
for (auto &c : inputStr) {
if (c >= 'a' && c <= 'z') {
result[currentLine].insert(currentPos, 1, isUpCase ? c - 'a' + 'A' : c);
currentPos++;
} else if (c == '@') {
isUpCase = !isUpCase;
} else if (c == '+') {
Enter();
} else if (c == '~') {
Backward();
} else if (c == '-') {
DeleteC();
} else if (c == '^' || c == '*' || c == '<' || c == '>') {
AdjustPos(c);
}
}
将多个字符操作映射为一个 std::unordered_map,每个特殊字符对应一个函数指针或 std::function,从而简化 if 语句结构,降低圈复杂度。以下是一个改进示例:
#include <unordered_map>
#include <functional>
#include <string>
#include <vector>
void Enter();
void Backward();
void DeleteC();
void AdjustPos(char);
void processInput(std::string& inputStr, std::vector<std::string>& result) {
bool isUpCase = false;
int currentLine = 0;
int currentPos = 0;
// 操作字符与对应函数的映射
std::unordered_map<char, std::function<void()>> operations = {
{'+', [&]() { Enter(); }},
{'~', [&]() { Backward(); }},
{'-', [&]() { DeleteC(); }},
{'^', [&]() { AdjustPos('^'); }},
{'*', [&]() { AdjustPos('*'); }},
{'<', [&]() { AdjustPos('<'); }},
{'>', [&]() { AdjustPos('>'); }}
};
for (auto &c : inputStr) {
if (c >= 'a' && c <= 'z') {
result[currentLine].insert(currentPos, 1, isUpCase ? c - 'a' + 'A' : c);
currentPos++;
} else if (c == '@') {
isUpCase = !isUpCase;
} else if (operations.find(c) != operations.end()) {
operations[c]();
}
}
}
在这个改进中,operations 是一个 std::unordered_map,用于将每个字符操作映射到对应的 Lambda 表达式(包含函数调用)。这样,你可以简化 for 循环中对多个字符的判断逻辑。
考前准备¶
- 弱点:
- 字符串处理相关函数
- 滑动窗口(有窗口的需求,如子数组;有滑动的判定)
- 固定一端使得种类数能分类讨论。
- KMP
- 图算法
- 最短路径实现
- 拓扑排序
- 动态规划
- 可信:字符串,头文件,圈复杂度,
- 字符串处理相关函数
遇题对策¶
- 题意的准确理解
- 构造小样例,分析题意
- 题目的抽象
- 提取出独立的不可分子问题
- 题目的转化
- 从问题的反面,所求值的补集,使用不同的变量讨论情况
- 通过规律(数学规律)转换问题: 可以先从小例子分析,然后猜想验证
- 对于输入量多的题型,必定是以下几种情况
- 每次操作(query)是独立的,简单分解成独立任务即可
- 使用特殊数据结构(单调栈,优先队列),边读边算边丢弃
- 读取后,处理成精简表示:
- 前缀和(子数组的元素和转换成两个前缀和的差, 注意为了
sum[0]=0,设置sum[i]=A[0]+...A[i-1]) - 差分数组:B[i]=A[i]-A[i-1]
- 前缀和(子数组的元素和转换成两个前缀和的差, 注意为了
- 可以接受的高时间复杂度操作
O(nlogn)快排10^5元素
- 题型的分类判断
- 常见的题型和考察知识点
- 陌生的技巧题
- 数学技巧题:图论、数值计算技巧
- 常见的错误
- 特殊输入忘记分析:0 或者 相等
- 边界判断错误以及越界:
- 数组越界, 数组下表总是写错一位
- for循环,或者判断的等于号缺失
- int 存储不下 需要long long
- 确实少考虑了某个边界的分析
- 循环调用太多层,导致函数栈溢出
AddressSanitizer: stack-overflow on address 0x7ffe1ea87fc8 (pc 0x00000034e77b bp 0x7ffe1ea88060 sp 0x7ffe1ea87fc0 T0)- 记录遍历过的点,树上记录father,图上记录遍历过点
- 自动补全导致的错误
min与max的两行都写成min了- 两层循环的i,j 有处写混了
- memset() size*n 导致堆栈上的数据全部变成0,程序访问无法访问的地址,gdb也无法执行,变量数值也完全错误
- 其余(类型转换,)
*(1/2)不是*0.5是*0
编程建议¶
- 先注释理清思路,比如动态规划的下表,如何转移
- 先注释写好想到的可能的forget的情况,防止写着写着忘记了。
快速debug¶
- 除开肉眼快速排查上面的常见错误
- vscode实机操作
- 配置好头文件,和main函数
- 找到错误样例的最小集合作为输入
- vscode gdb
注意事项¶
- 以思路清晰简洁的代码解答优先,而不是追求O(n)的算法,导致解法复杂化
- 多用辅助变量来理清思路,编译器会优化,不会影响性能。
- 辅助数据结构的选择一定要切合题意。
- 存储中间数据,或者标记已经处理的情况(DP时记录hit值的次数,而不是是否hit,以便回退)
- 利用二维数组精简讨论的代码
int direction[8][2] = {{2,1}, {2,-1}, {-2,1}, {-2,-1}, {1,2}, {1,-2}, {-1,2}, {-1,-2}};
- 计算时间复杂度
- 按照题目的上限计算
常用写法和技巧¶
二分答案、二分法¶
个人最爱写法
int maxR = *max_element(inputList.begin(), inputList.end());
int left = 0, right = maxR;
// 该方法的问题:默认right是不满足的,需要提前额外判断
if(available(right)) return right;
while(left + 1 < right) {
//由于无论是从left,right相差1、2、3、……开始
//最终都会经过 left+1=right的阶段
int mid = left + ((right-left)>>1); // 注意括号 >> 优先级最低
long long tmpCntSum = 0;
for(auto &x: inputList){
tmpCntSum += (x>mid)? mid : x;
}
if(tmpCntSum <= cnt){
left = mid; // while结束时 left 满足 其tmpCntSum <= cnt
}else{
right = mid; // while结束时 right 满足 其tmpCntSum > cnt
}
}
//求 满足求和不大于cnt 的最大值:left
return left;
其他写法
二维遍历边界小技巧¶
int dirs[4][2] = {1,0,-1,0,0,1,0,-1};
auto check = [&](int x, int y){
return x >= 0 && y >= 0 && x < n && y < m;
};
for(auto &[addx, addy]: dirs){
int nextx = x + addx;
int nexty = y + addy;
if(!check(nextx, nexty)) continue;
……
}
单调栈写法¶
单调栈基础
单调栈的单调性
单调栈的“单调”指的是栈中元素的顺序是单调递增或单调递减的。具体来说:
- 单调递增栈:栈中的元素从栈底到栈顶是递增的。
- 单调递减栈:栈中的元素从栈底到栈顶是递减的。
单调栈的工作原理
- 单调递增栈:
- 当新元素大于栈顶元素时,将其压入栈中。
-
当新元素小于栈顶元素时,不断弹出栈顶元素,直到栈顶元素小于或等于新元素,然后将新元素压入栈中。
-
单调递减栈:
- 当新元素小于栈顶元素时,将其压入栈中。
- 当新元素大于栈顶元素时,不断弹出栈顶元素,直到栈顶元素大于或等于新元素,然后将新元素压入栈中。
单调栈的主要优势在于它能够高效地解决一些特定的问题,例如:
- 寻找下一个更大/更小的元素:通过维护一个单调栈,可以在 \(O(n)\) 时间复杂度内找到每个元素右边第一个比它大/小的元素。
- 直方图中的最大矩形面积:通过维护一个单调栈,可以在 \(O(n)\) 时间复杂度内计算直方图中的最大矩形面积。
- 滑动窗口的最大值:通过维护一个单调队列,可以在 \(O(n)\) 时间复杂度内找到滑动窗口内的最大值。
- 中 1019 链表中的下一个更大节点
- 考察带额外信息的单调栈
stack<int> stk;
while (head) {
while (!stk.empty() && stk.top() <= head->val)
stk.pop(); // 保持从底到top单减
stk.push(head->val); // 每个元素要加入
head = head->next;
}
//vector 也行
vector<pair<int, int>> st; // 当前行的单调栈
for (int j = n - 1; j >= 0; --j) {
while (!st.empty() && mn <= st.back().first)
st.pop_back();
st.emplace_back(mn, j);
}
常用技巧¶
iota构建用于排序的索引数组- itoa 是 希腊语的第九个字母,读
[aɪ’otə]这个名称是从APL编程语言借鉴过来的。 - 题目
iota(id, id + n, 0); sort(id, id + n, [&heights](const auto &i, const auto &j) {return heights[i] > heights[j];});注意[&heights]的lambda表达式引用。
- itoa 是 希腊语的第九个字母,读
- 快慢指针,原地去重/合并
- 贪心枚举,确定枚举一个变量,从而贪心确定另一个。(不用双重循环)
- 易 LCP 33. 蓄水
- 转换思路,枚举另一维度的元素。
常见题型的框架、解法以及例题¶
模拟题¶
- 往往需要辅助数据结构降低时间复杂度
特征:明显的顺序处理数据O(1)空间O(1)操作¶
- 相关例题(最简单的题目)
- 加加减减,哈希表/vector cnt 记录每个元素的剩余次数
- 滑动窗口
- 难 2106. 摘水果
- 同向双指针(滑动窗口),左一动,O(1)时间判断右指针是否需要移动
- 固定一端分类讨论
特征:有限个数集合使得时间复杂度降维¶
- 数字0-9
- 26个字母
- 30个元素的选择问题
- 状态压缩DP
有限二维暴力题¶
- 中/23春美团实习 LCP 74. 最强祝福力场
- 暴力所有矩形四边交叉的点。(注意
1 <= forceField.length <= 100, 暴力所有矩形四角是错误的,反例两矩阵组成十字架形状
- 暴力所有矩形四边交叉的点。(注意
- 华为230426 机试三
- 二分答案,每种情况是一个最强祝福力场子问题
- 中 6392. 使数组所有元素变成 1 的最少操作次数
- 暴力每个最大公约数组的区间的左右端点
- 暴力+剪枝
- 中 2411. 按位或最大的最小子数组长度
- 从每个元素的影响范围来思考,选择顺序选择每个元素,然后反向计算其影响,
- 每个元素的影响或等于并集,按位或最大==数字1最多,即最大的并集
- 没有增大==或结果相同=>子集=>前面不需要再遍历,剪枝
贪心¶
- 往往贪最大,和优先队列(最大堆)结合
- 中 1054. 距离相等的条形码
- 也可以,统计数量之后,先排偶数位,然后排奇数位。
- 证明贪心的正确性:常用反证法
- 假如不是贪心的方式成立,会转换或者有什么问题
- 中 2517. 礼盒的最大甜蜜度:二分答案的子问题中,要证明打包方法,必包括两端的糖果。反证:假如情况不包含两端的糖果,该情况的两端必定可以向外扩展到两端。
考察数据结构¶
- 抽象表示/题目特征(用于高效匹配题型)
- 栈:输入数据量多,顺序push,逆序pop处理,后进先出
- 哈希表:常见记录元素次数
++map_cnt[x]
- 常见的解法流程
- 解法难点:
- 存储元素不是简单的int,而是需要额外index信息的
pair<int,int>
- 存储元素不是简单的int,而是需要额外index信息的
- 相关拓展考点/难度延伸
- 相关例题以及核心考点
- 中 1019 链表中的下一个更大节点
- 考察带额外信息的单调栈
常见困难题: 二维图带障碍的路径分析¶
特征:字符串相关¶
- 字符串相关概念
- 子串与子序列:子串要连续;子序列不需要连续,但是相对位置不改变。
- 真后缀: 指除了 S 本身的 S 的后缀
- 回文串:正着写和倒着写相同的字符串
- 字符串基本处理
- ASCII码 A在65 a在97
- 大小写转换
- char:
str[i] = tolower(str[i]);//把大写全部转为小写 - string, 第三个参数是转换之后,输出到原str字符串的起始地址。转换操作,可以选择toupper,tolower。
- char:
- 快速判断子字符串相同
- 伪难 1147. 段式回文:暴力双指针匹配能通过
O(n^2),官方对字符串进行滚动哈希预处理变成O(n) - 难 1163. 按字典序排在最后的子串
- 核心思想:只有后缀子字符串才是候选的最大字典序子字符串
- python 的切片操作LC容忍度比较高
- 指针 i 指向已知的最大后缀子字符串,j 指向待比较的后缀子字符串
- 一个个比较时,失败时按道理是
j++, 不一定是j+k+1。- 因为当
s[i+k]<s[j+k]时,s[j+1~j+k]内可能有更大子字符串,如cacacb字符串,比较caca与cacb时,后者有更大字串cb。
- 因为当
- 但是通过如下关系能跳过大部分重复的区域
- 当
s[i+k]<s[j+k]时,跳过了以 s[i,..,i+k] 为起始位置的所有后缀子串,因为它们的字典序一定小于对应的 s[j,..,j+k] 为起始位置的后缀子串(由于s[i+k]<s[j+k])。 s[i,..,i+k] < s[j,..,j+k],这时j = max(j + 1, i + k + 1);- 当
s[i+k]>s[j+k]时, 以s[i] > s[i+1,..,i+k] > s[j,..,j+k], 这时j=j+k+1
- 当
- 伪难 1147. 段式回文:暴力双指针匹配能通过
- KMP算法:
- 一种线性时间复杂度的字符串匹配算法,可以在一个字符串S内高效地定位模式字符串P的出现位置。
- 思想:核心就是每次匹配过程中推断出后续完全不可能匹配成功的匹配过程,从而减少比较的趟数。
- next数组实质上就是找出模式串中前后字符重复出现的个数,为了能够跳跃不可能匹配的步骤。next数组的定义为:next[i]表示模式串A[0]至A[i]这个字串,使得前k个字符等于后k个字符的最大值,特别的k不能取i+i,因为字串一共才i+1个字符,自己跟自己相等毫无意义。
- next数组的信息,可以不用从头开始匹配,而是从重复位置开始匹配(类似双指针,或者滑动窗口的效果)
特征:图相关¶
- 图论相关概念
- 简单图:图中无自环与重边,反之为多重图
- 自环:某边的两个端点都是同一点形成的环
- 补图:对于无向简单图G,其补图中的边为G中边的补集
- 图的表示
- 数据以稠密图为主,
- 有边权时:邻接矩阵
vector<vector<int>> g; g = vector<vector<int>>(n, vector<int>(n, INT_MAX / 2));g[e[0]][e[1]] = e[2]; // e[2]权重- 无边权时:权重为1
- 有边权时:邻接矩阵
- 数据以稀疏图为主,使用
- 有边权时:邻接表
vector<vector<pair<int, int>>> m_adj; m_adj[edge[0]].emplace_back(edge[1], edge[2]); // edge[2]权重,- 无边权时:邻接堆
unordered_set<int> nes[n]; g[edge[0]].insert(edge[1]); g[edge[1]].insert(edge[0]);- 或者邻接表
vector<vector<int>> g(n);g[edge[0]].push_back(edge[1]); g[edge[1]].push_back(edge[0]);
- 有边权时:邻接表
- 数据以稠密图为主,
- 图中最短环
- 难 2608. 图中的最短环
- 先把图变成n点的邻接表
vector<vector<int>> g(n); - 寻找最短,明显是从原点开始的BFS,由于要记录遍历的每个点的index和父亲节点,防止邻接表的BFS逆向,采用
queue<pair<int,int>> - 环的判断,BFS过程中
x如果有邻居y已经被遍历到,环大小为该层最小dist[x]+dist[y]+1
- 图中最短路径
- 难 2642. 设计可以求最短路径的图类
- 虽然是单向路径,但是不保证无环。暴力回溯遍历,需要记录已经经过的点。虽然暴力法任然会超时
- Dijkstra算法
- 初始化: start距离0,其余无穷
- 迭代步:
- 当前点集V里距离最小的点x,就是该点到start的最小距离。
find x for min(dis[x]) in V(N)或者int x = min_element(dis, dis + N) - dis; - 更新该点x邻居y的最短距离
for (int y = 0; y < n; ++y) dis[y] = min(dis[y], dis[x] + g[x][y]); // g为邻接矩阵 - 将x从V里剔除(已经找到)
- 结束:
- x为end,提前结束
- x内容为无穷,说明其余的点start无法访问到。
- Floyd 的以中间节点讨论的动态规划算法
- 在一般图上,求单源最长(短)路径的最优时间复杂度为
O(nm)(Bellman-Ford 算法,适用于有负权图)或O(m * log m)(Dijkstra 算法,适用于无负权图)。 - 但在 DAG 上,我们可以使用 DP 求最长(短)路,使时间复杂度优化到
O(n+m)。
- 拓扑排序 - Kahn 算法
- 初始状态下,集合
S装着所有入度为 0 的点(一般是队列,如果题目要求字典序之类,可以换成最大堆/最小堆实现的优先队列),拓扑排序结果L是一个空列表。 - 每次从 S 中取出一个点 u(可以随便取)放入 L, 然后将 u 的所有边\( (u, v_1), (u, v_2), (u, v_3) \cdots \)删除。对于边
(u, v),若将该边删除后点 v 的入度变为 0,则将 v 放入 S 中。 - 不断重复以上过程,直到集合
S为空。检查图中是否存在任何边,如果有,那么这个图一定有环路,否则返回L,L中顶点的顺序就是拓扑排序的结果。 - 华为230426机试一
- 双队列BFS。(S为空时,还有入度不为0的点,有环
- 或者往大更新每点的距离,返回最大值。(N次后还能更新点,说明有环
- 初始状态下,集合
特征:树相关¶
- 基本概念:区分二叉搜索树,平衡二叉树
- 树具有相同的子问题结构,常用dfs递归
- 循环删除树上叶子节点
- 难 2603. 收集树中金币
- 思路1:删除叶子节点
- 先把图变成n点的邻接表,但是由于要删除使用
unordered_set<int> nes[n]; - 叶子节点的判断
nes[i].size() == 1, 删除叶子节点可能会导致新的叶子产生需要queue保存循环处理
- 先把图变成n点的邻接表,但是由于要删除使用
- 思路2:拓扑排序(基于Kohn算法:从多个入度为0的叶子节点开始BFS,取出ready的点,更新其他节点的度。但是每个节点有依赖度的属性
dig[i],只有节点满足依赖才能入队继续BFS)
特征:每步k分支,穷举所有答案组合¶
- 抽象表示/题目特征(用于高效匹配题型)
- 回溯法
- 常见的解法流程
- 采用辅助数据结构记录选择某分支导致的影响次数,以便回退
- 解法难点:
- 时间复杂度较高,往往需要用动态规划等替代。迫不得已不要用。
- 相关拓展考点/难度延伸
- 相关例题以及核心考点
- 中 2597. 美丽子集的数目
- 中 6899. 达到末尾下标所需的最大跳跃次数
- 回溯的时间复杂度过高
k^1000。动态规划大约1000*k
BFS¶
- BFS时,一般不经过重复节点,需要记录。
- 原因:每个节点只有位置信息时,重复遍历节点肯定不满足最小步数的要求(至少加一)。可能导致死循环。
- BFS每步的内容,或者记录的重复节点的内容: 一般不仅有位置,还有方向等其他信息。
- 难 1263. 推箱子
- 多源BFS + 并查集/二分答案
- 要点:区分已经遍历和未经过的区域。如果不需要存储额外信息一个queue就能实现,因为
swap(tmp,cur_queue)耗时。 - ROI: 将两点连线通过BFS的属性值变成并查集,判断在集合内
- 要点:区分已经遍历和未经过的区域。如果不需要存储额外信息一个queue就能实现,因为
特征:每步k分支,求解min步数¶
- 抽象表示/题目特征(用于高效匹配题型)
- BFS: 每步k分支,关心步数,每个分支互不影响
- 常见的解法流程
- 采用双队列,每个元素存储了每个节点所需信息,每次交换相当于树的遍历更深一层。
- 解法难点:
- 具体根据题目简化每个节点处理的时间复杂度
- 记录候选集合,遍历后删除,避免重复访问
- 相关拓展考点/难度延伸
- 相关例题以及核心考点
- 难 2612. 最少翻转操作数
- 由于每个节点都要对大小为n的bannedSet判断,每次
O(logn),次数k,每节点时间复杂度O(klongn) - 一种记录已经遍历的候选集合方法
- 发现其反转的奇偶特性,次数减半,同时将bannedSet的补集分成一半,每节点时间复杂度
O(k/2 *long(n/2)) - 而且由于记录了候选集合,遍历过可以防止重复访问,耗时会逐渐减小。
- 发现其反转的奇偶特性,次数减半,同时将bannedSet的补集分成一半,每节点时间复杂度
- 最快的方法,发现候选集合是连续的。使用
uf[x] = y;记录每个起始地址x,已经处理到地址y,也就是跳过了x~y的区域。
特征:问题能被分成多阶段求解(动态规划)¶
- 抽象表示/题目特征(用于高效匹配题型)
- 最优子结构
- 问题的最优解所包含的子问题的解也是最优的
- 无后效性
- 即子问题的解一旦确定,就不再改变,不受在这之后、包含它的更大的问题的求解决策影响。
- 子问题重叠
- 如果有大量的重叠子问题,我们可以用空间将这些子问题的解存储下来,避免重复求解相同的子问题,从而提升效率。
- 最优子结构
- 常见的解法流程
- 强烈建议先写记忆化搜索的DFS,除非超时而且有固定个数(eg.500)可以写成固定大小的数组的递推.
- 虽然递推会比记忆化搜索快7~8倍左右???
- 但是递推的边界太不直观了,而且容易出错
- 确定dp数组(dp table)以及下标的含义
- 将原问题划分为若干 阶段,每个阶段对应若干个子问题,提取这些子问题的特征(称之为 状态);
- 确定递推公式
- 寻找每一个状态的可能 决策,或者说是各状态间的相互转移方式(用数学的语言描述就是 状态转移方程)。
- dp数组如何初始化
- 确定遍历顺序
- 举例推导dp数组
- 按顺序求解每一个阶段的问题。
- 强烈建议先写记忆化搜索的DFS,除非超时而且有固定个数(eg.500)可以写成固定大小的数组的递推.
- 解法难点:
- 记忆化搜索与从头递推是同时间复杂度的写法
- 记忆化递归变从头递推,一般会变慢。因为递推会计算所有的情况,但是递归不会。
- 递推往往是用其它状态更新当前状态的查表法,也可以变成用当前状态去更新其它状态的刷表法
- 选择参数k,k的变化来分阶段, 寻找k与k+1间的转移关系
- 二维DP,第二个维度间是怎么连续转移的?
- 降低时间复杂度
- 对于二维的DP,简单的阶段转移只需要O(1)时间,总时间O(mn)。
- 复杂的题目阶段转移作为子问题,需要结合额外的方法简化时间复杂度
- 降低空间复杂度
- 分析每次转移使用和产生的数据,去除冗余的数据,二维DP从头递推使用滚动数组优化为O(n), 甚至可能简化为
O(1)
- 相关拓展考点/难度延伸
- 相关例题以及核心考点
- 如何选择分阶段参数和构建转移
- 分阶段参数:输入序列的问题规模
- 区间DP:
- 中 剑指 Offer II 095. 最长公共子序列
- 分阶段参数:前i和前j的元素的最长公共子序列
- 转移关系:遍历时新元素是否满足题意(公共),很简单加入序列,转移到更长的公共子序列(长度+1求max)
- OIWiki 环上石子合并得分
- 区间DP+前缀和+环长*2展开为链
- 中 300. 最长上升递增子序列
- 分阶段参数:以A[i]为子序列结尾的最长子序列f(i)
- 转移关系:遍历时新元素是否满足题意(递增),很简单加入序列,转移到更长的公共子序列
-
\[f(i)=\max[\max_{j \in [0,i-1]}f(j),0]+1, \textbf{if}\ nums[j]<nums[i]\]
- 初始化
f[0]=1
-
- 子问题寻找是满足
nums[j]<nums[i]的最大的已有序列,通过维护辅助数据M[n]存储长度为i的末尾元素的最小值。 - 贪心优化:上升子序列长 -> 上升慢 -> 新加元素尽可能小 -> 维护长度为 i的最长上升子序列的末尾元素的最小值
- 最长上升子序列变种
- 核心思想:以最后最后一个元素为参数来DP,才能比较是否上升。
- 难 面试题 08.13. 堆箱子 往往
return *max_element(dp.begin(), dp.end());
- 难 面试题 08.13. 堆箱子 往往
- 中 1027. 最长等差数列
- 分阶段参数:和上一条相同,由于要判断递增和等差,需要两个元素信息。根据差值j情况又不同
- 以nums[i]结尾的等差为j的最长子序列长度
- 转移关系
- 未优化版本
O(n^3):$\(f(i,j) = max[\max_{k\in [0,i-1]}f(k,j),0]+1, \textbf{if}\ a[i]-a[k]=j\)$ - 朴素的思路:把k维度优化掉,相同j的情况下,f随第一项单增,所以需要辅助数据记录值为
a[i]-j对应的最后一个index - 思路二:优化差值j维度,从后向前遍历k,对于
d=a[i]-a[k], 更新没处理的f(i,d)
- 未优化版本
- 难 1187. 使数组严格递增
- 分阶段参数:考虑包括index为i的前面元素,并且最后一个元素大小小于j的严格递增序列的最小操作数f(i,j)
- 转移关系:被交换的\( a_2[p] \)也应该小于
j。- 初始想法:$$f(i,j)=min[min(f(i,k_1),\textbf{if} k_1\in [0,j-1]), $$
-
\[f(i-1,a_1[i]),\textbf{if}\ a_1[i]<j, \]
-
\[min(f(i-1,k_2)+1), \textbf{if}\ k_2\in \{a_2[0],\cdots,a_2[p]\} , a_2[p]<j )]\]
- 初始化:
f(-1,x)=0 - 二维DP 有许多冗余信息:
- 如果只有最后一个min,后面每行答案一样。加上第二个min,也能保存每行元素单调递减。所以第一行min是冗余的。
- 由于每行是单调递减的,所以最后一个min应该取最后一个
- 转移公式化简:$$f(i,j)=min[f(i-1,a_1[i]),\textbf{if} a_1[i]<j, $$$$ f(i-1,a_2[p])+1, \textbf{if} max p ,a_2[p]<j )]$$
- 还存在两个问题:
- 第二个维度过大\( 10^9 \):由于数的个数是有限的,可以排序后数位与数值一一对应,来处理数位。
- 记忆化DFS时,考虑到第二个维度的范围比较大,可以用哈希表来记忆化。
- 其次该转移公式容易DFS但是难以转化为递推?
- 贪心优化:操作数少 -> 原本数组递增子序列越长 -> 被操作的数越紧密,剩下的未处理的数组的递增子序列就可能越长
- 中 2606. 找到最大开销的子字符串
- 子串的最大最小值
- 分阶段参数:以A[i]为字串结尾的最大开销字串
- 转移关系:新字串=前一个字串+新元素。保留每个以A[i]为字串结尾的字串数据来求最大最小值
- 中 1043. 分隔数组以得到最大和
-
\[f(i)=\max_{j \in [max[i-k+1],i]}[f(j-1)+(i-j+1)\times \max_{p\in [j,i]}arr[p]]\]
- 可以发现转移方程中有一个子区间最大值的子问题, 但是在写成递推时能顺便求解了。
- 难 1335. 工作计划的最低难度
- 求解a[n] d 个子数组的 最大值的和的最小值
- 很自然的确定最后一个子数组的元素个数k来提取子问题,dfs(d-1, n-k)
- 更快的,结合单调栈(太绕了,思路
- 三维DP, 结果要从某个有限个数的维度遍历出来, 类似
return [max(dfs(n,j) for j in range(J))- 中 6898. 字符串连接删减字母
- 观察到有限的字母种类,
- 0-1背包(受限的选择组合问题)
- 分阶段参数:已经考虑的n个元素的个数,限制条件组成第二个参数
- 也属于第一类:分阶段参数为输入序列的问题规模
- OIWiki 有时限的最大化采药价值
- 转移关系: 选与不选导致,\( max(f_{i-1}{k},f_{i-1}{k-w}+v) \)
- 普通的0-1背包问题,使用滚动数组时,要注意遍历方向
- 中 2597. 美丽子集的数目
- 用乘法原理将总组合数问题分解成各个模数的组合数的乘积
- 分阶段参数:包含的前n个元素的个数(单个模数的组合数求解的子问题里)
- 转移关系:组合数关系(总组合数=选i的组合数+不选i的组合数)
- 难 1125. 最小的必要团队
- 状态压缩 + 集合版0-1背包
- 状态压缩:由于输入数据一个小于16,一个小于64,压缩成二进制
- 分阶段参数:
dfs(i,j)表示从前i个集合中选择一些集合,并集包含j(题目限制需要),至少需要选择的集合个数。 - 转移关系:
dfs(i,j)=dfs(i−1,j delete set[i])+1 - 边界:当
j==0,限制已经满足了,dfs==0
- 优化:递推查表法 vs 刷表法
- 不相邻问题:打家劫舍四部曲
- 一:一维序列不相邻问题,前一格和跳一格+自身里选最大
- 二:一维环, 两种情况的最大值
- 如果偷 nums[0],那么 nums[1]和 nums[n−1]不能偷,问题变成从 nums[2]到 nums[n−2]的非环形版本,调用前面的代码即可
- 如果不偷 nums[0],那么问题变成从 nums[1]到 nums[n−1]的非环形版本
- 三:树上的不相邻问题,很像树形DP
- 需要一个根,来确定子树(DFS)方向。除开当前遍历的节点,还需要一个变量表示是否选择
- 转移关系如下:x为i的子节点
- 未选\( f(i,0)= \sum{max(f(x,1),f(x,0))} \)
- 已选\( f(i,1)= \sum f(x,0) + a_i \)
- 三拓展 难 2646. 最小化旅行的价格总和
- 选择的点是1/2, 未选择是原代价。 而且每个节点有次数\( k_i \)
- 转移关系如下:x为i的子节点
- 未选\( f(i,0)= \sum{min(f(x,1),f(x,0))} + a_i * k_i \)
- 已选\( f(i,1)= \sum f(x,0) + 0.5 * a_i* k_i \)
- 四:和二分答案结合
- 分阶段参数:输入序列的问题规模
- 组合数问题:
- 计数DP: 中 1079. 活字印刷
f[i][j]表示用前 i 种字符构造长为 j 的序列的方案数。选k个字符进行放置。
- 降低时间复杂度
- 难 2617. 网格图中最少访问的格子数
- 解法:反转DP方向 + 二分查找单调栈 将阶段转移复杂度由O(m+n)->O(logm+logn)
- 与二进制结合
- 难 1483. 树节点的第 K 个祖先
- 去掉 k 的最低位的 1:
k &= k - 1 - 转化为二进制的DP递推
- 如何选择分阶段参数和构建转移
特征: 数量有限的有无/是非关系(状态压缩)¶
- 抽象表示/题目特征(用于高效匹配题型)
- 题目或其子问题有明显的0-1关系,考虑位运算简化判断
- 常见的解法流程
- 将状态用二进制表示
- 位运算按位与(&)、按位或(| )、按位异或(^)、取反(~)、左移(<<)、右移(>>)
- 位运算替代状态转换
- 将元素 x 变成集合
{x},即1 << x。 - 判断元素 x 是否在集合 A 中,即
((A >> x) & 1) == 1。 - 计算两个集合 A,B 的并集 \( A\cup B \),即
A | B。- 例如
110 | 11 = 111。
- 例如
- 计算 \( A \setminus B \),表示从集合 A 中去掉在集合 B 中的元素,即
A & ~B。- 例如
110 & ~11 = 100。
- 例如
- 全集
U={0,1,⋯ ,n−1},即(1 << n) - 1。
- 解法难点:
- 相关拓展考点/难度延伸
- 相关例题以及核心考点
- 中 1042. 不邻接植花
- 难 1125. 最小的必要团队
- 难 1483. 树节点的第 K 个祖先
- 去掉 k 的最低位的 1:
k &= k - 1 - 转化为二进制的DP递推
问题:求动态区间(子区间)内的最大最小值¶
- 抽象表示/题目特征(用于高效匹配题型)
- 如问题
- 常见的解法流程
- 构建最小单调栈,区间变化的时候push,并且pop大于新元素的元素
- 有时候也是动态规划, 比如 难 1335. 工作计划的最低难度
- 解法难点:
- 额外的要求导致的额外的判读和信息存储
- 相关拓展考点/难度延伸
- 相关例题以及核心考点
- 中难 907. 子数组的最小值之和
- 左右单调栈 + 贡献法
- 难 2617. 网格图中最少访问的格子数
- 解法:反转DP方向 + 二分查找单调栈
- 求min,每一步在push时构建底大顶小递增的单调栈,后push元素要是能使用优先级最高的最小值,按题意新元素最近(idnex相差1), 所以能丢弃前面结果更大的元素。
- 注意:由于是反转DP,由于新元素位于栈末尾,而且新元素的index小,所以单调栈中index也是单调递减的,所以能二分查找。
- 难 1335. 工作计划的最低难度
- 最快的方法: 单调栈递推DP
- 中难 907. 子数组的最小值之和
问题:求动态区间(子区间)内的最大值¶
- 只能用动态规划(递推)
- 问:子区间最大和,一维DP,对象是区间的末尾元素
- 进阶(RedStar 230724):子区间能改变一个值为x,问最大和。二维DP,第二维度是是否在区间内改变,再根据改变的位置是不是末尾来分成两种情况
dp[j][1]=max[max(dp[j-1][0]+x,x),max(dp[j-1][1]+nums[j],nums[j])]
问题:求动态区间(子区间)内的出现元素次数¶
- 相关例题以及核心考点
问题:区间数值求和、绝对值、求个数(有限种类、奇偶个数)¶
- 如何求解\( \sum{|A[i]-k|} \)
- 思路:绝对值通过排序就分成两种情况分别求解, 区间求和通过前缀和化简。
- 难点:输入数据量
10^5, 当时就完全不打算排序 - 中 2602. 使数组元素全部相等的最少操作次数: 排序+前缀和+二分查找
- 中 6360. 等值距离和
- 相关拓展考点/难度延伸
- 中 2607. 使子数组元素和相等
- 将n个数通过+1或者-1操作变成同一个数x,操作次数最小的x是多少?\( min{\sum{|A[i]-x|}} \), x应该是数列的中位数
- 中 1031. 两个非重叠子数组的最大和(实现O(n))
- 代码实现,注意
s[0]=0c++ int s[n + 1]; s[0] = 0; partial_sum(nums.begin(), nums.end(), s + 1); // 计算 nums 的前缀和
- 对于有两个变量的题目,通常可以枚举其中一个变量,把它视作常量,从而转化成只有一个变量的问题。
- 难 1330. 翻转子数组得到最大的数组值
- 求解
max(∣a−x∣+∣b−y∣−∣a−b∣−∣x−y∣) - 假设 四个数由小到大排列的值分别为 a,b,c,d。其表达式结果只可能的为
2×(c−b) - 根据重叠情况讨论如下:
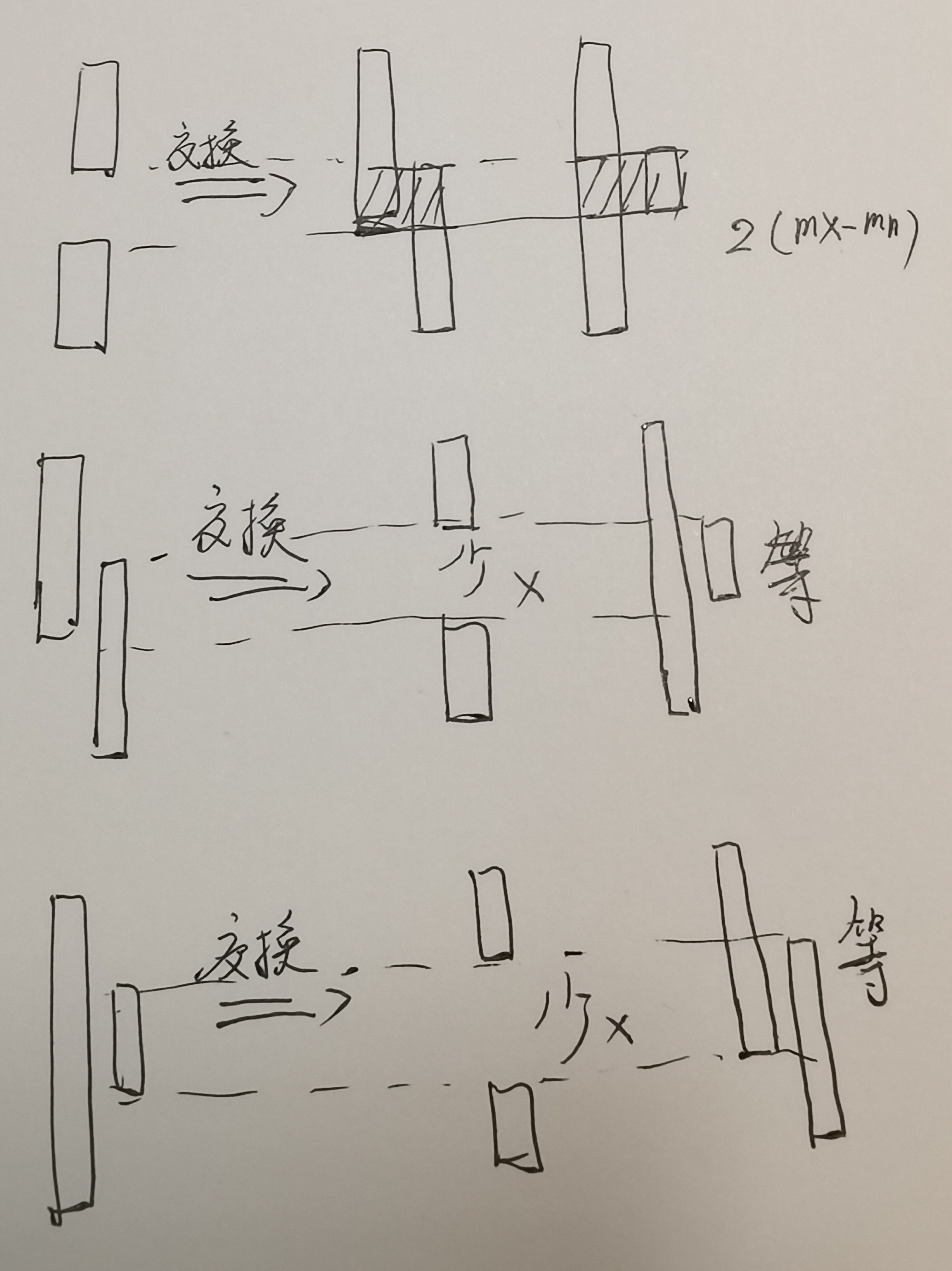
- 中难 1177. 构建回文串检测
- 字串的子区间的个数统计,简化版前缀和统计个数,统计奇偶个数变成异或运算,变成26位的位运算
特征:所有子数组x值的和 mod 10^7¶
- 异或和:贡献法
- 美团笔试,同一个数组
- 但还是会超时,不懂?
- 变种:两个数组,异或和组合,的异或和
- 异或交换顺序,偶数次为结果为0
- 异或运算的逆运算是它本身,也就是说两次异或同一个数最后结果不变,即 a \oplus b \oplus b = a 。
问题:求满足条件的参数的最小/最大值¶
- 抽象表示/题目特征(用于高效匹配题型)
- 题目要求
- 求解满足条件的一个最大或者最小值、最小最大值或者最大最小值
- 单调性,答案是个临界值,两侧分别是满足条件和不满足条件。
- 如果猜测一个答案mid,能作为条件参与到满足题目条件的判断中。
- 否,题目可能是动态规划求解最大最小值
- 答案数值有明显的上界和下界,作为二分答案的
left和right
- 常见的解法流程
- 二分答案mid,判断当前mid的数值是否满足题目条件,来寻找满足条件的最大/最小答案。
- 解法难点:
- 每次判断是否满足题目如何实现
- 相关拓展考点/难度延伸
- 相关例题以及核心考点
- 题单
- 2560. 打家劫舍 IV
- 选择k个中最大数值的最小值,将
最大的最小值转换成不超过mid的限制 - => 最大数值不超过mid的最大个数p的求解, p < k 则不满足条件
- 条件判断转换成DP
- 2616. 最小化数对的最大差值
- 选择p数对的最大差值的最小值
- => 最大差值不超过mid的最多数对数k, k < p则不满足条件
- 条件判断转换成DP
- 难 2528. 最大化城市的最小供电站数目
- 部署电站k个后,城市最小电量的最大值
- => 使得城市最小电量不小于mid,最少需要p个额外电站部署, p > k 则不满足条件
- 华为 2023.04.12-实习笔试-第一题-购物系统的降级策略
- 华为 P1006. 2022.9.21-数组取min
- 华为230426 机试三
- 二分答案,每种情况是一个最强祝福力场子问题
常见数学相关基础¶
模运算相关基础¶
- 同余定理:
- 给定一个正整数m,如果两个整数a和b满足a-b能够被m整除,即
(a-b)/m得到一个整数,那么就称整数a与b对模m同余,记作a≡b(mod m)。对模m同余是整数的一个等价关系。
- 给定一个正整数m,如果两个整数a和b满足a-b能够被m整除,即
- 性质
- 对称性:若a≡b(mod m),则b≡a (mod m);
- 传递性:若a≡b(mod m),b≡c(mod m),则a≡c(mod m);
- 同余式相加:若a≡b(mod m),c≡d(mod m),则a+c≡b+d(mod m);
- 同余式相乘:若a≡b(mod m),c≡d(mod m),则ac≡bd(mod m)。
- 费马小定理
- 若 p 为素数,gcd(a, p) = 1,则 $\(a^{p - 1} \equiv 1 \pmod{p}\)$。
- 另一个形式:对于任意整数 a,有 $\(a^p \equiv a \pmod{p}\)$。
- 欧拉定理
- 欧拉函数:\( \varphi(n) \),表示的是小于等于 n 和 n 互质的数的个数。
- \( \varphi(1) \) = 1。
- 当 n 是质数的时候,有 \( \varphi(n) \) = n - 1。
- 若 gcd(a, m) = 1,则 $\(a^{\varphi(m)} \equiv 1 \pmod{m}\)$。
- 欧拉函数:\( \varphi(n) \),表示的是小于等于 n 和 n 互质的数的个数。
模运算,模数¶
- 循环与mod模数
- 中 2607. 使子数组元素和相等
- 题中的
a[p]如果和a[q]一组,q = p + nx - ky,要满足(p + nx) mod k = q。 - 根据 裴蜀定理,
a[q]=a[p+nx+ky]=a[p+gcd(n,k)],q与p的值差gcd(n,k)就在一组 - 模
gcd(n,k)的结果分组
- mod模数的处理
- 中 2598. 执行操作后的最大 MEX
- 模 k 的结果分组
- mod 负数
-x时,其结果为modx的相反数
- 整除判断转化为模数
- 中 1015. 可被 K 整除的最小整数
-
\[(a+b)modm=((amodm)+(bmodm))modm\]
-
\[(a\cdot b) \bmod m=((a\bmod m)\cdot (b\bmod m)) \bmod m\]
质数(素数)¶
- 质数(素数)相反的概念是合数
- 平凡约数:1和它本身称为平凡约数;大于1小于它本身的约数称为非平凡约数。
- 高效判断是否为质数,重点在上界
i * i <= n- 如果某个整数大于 1 ,且不存在除 1 和自身之外的正整数因子,则认为该整数是一个质数。
bool is_prime(int n) {
for (int i = 2; i * i <= n; ++i)
if (n % i == 0)
return false;
return n >= 2; // 1 不是质数
}
- 最快速的预处理(埃氏筛):MAX内的质数序列, 考虑从头deny候选元素
- 由于没有分支与访问有规律,会比复杂度低的欧拉筛快
存储质数和非质数的版本:
const int MX = 1e5;
bool np[MX + 1]; // 质数=false 非质数=true
int init = []() {
np[1] = true; // 1 不是质数
for (int i = 2; i * i <= MX; i++) {
if (!np[i]) {
for (int j = i * i; j <= MX; j += i) {
np[j] = true;
}
}
}
return 0;
}();
质数push2vector:
const int MX = 1e6;
vector<int> primes; // 建议一个vector,一个数组
bool np[MX + 1]; // 默认是0
int init = []() {
for (int i = 2; i <= MX; i++) { // 不能是 i*i
if (!np[i]) {
primes.push_back(i); // 预处理质数列表, 写在里面,不能是 i*i
// for (int j = i; j <= MX / i; j++) // 避免int溢出的写法
// np[i * j] = true; //deny后续元素, i*i 开始
// or
for(int j = i*i; j <= MX; j+=i){
np[j] = true;
}
}
}
return 0;
}();
- 埃氏筛:通俗的写法
vector<int> generatePrimes(int n) { vector<bool> isPrime(n + 1, true); vector<int> primes; for (int p = 2; p * p <= n; ++p) { // 使用了 i*i,素数要额外push if (isPrime[p]) { // primes.push_back(p); for (int i = p * p; i <= n; i += p) { // 新排除的是新质数的倍数 isPrime[i] = false; } } } for (int p = 2; p <= n; ++p) { if (isPrime[p]) { primes.push_back(p); } } return primes; }
基于费马小定理的O(log n)的伪素数判断方法。但是机试一般不会考。
众数¶
- 绝对众数求解,
- 绝对众数:该众数出现的次数大于N/2。
- 摩尔投票算法:寻找一组元素中占多数元素(不能刚好占一半)的常数空间级时间复杂度算法。
- 每次从序列里选择两个不相同的数字删除掉(或称为“抵消/对拼消耗/争擂台”),最后剩下一个数字或几个相同的数字,就是出现次数大于总数一半的那个。
gcd, lcm¶
- 最大公约数gcd,最小公倍数lcm
- gcd(a, b) = gcd(b, a % b) 注意是求余数
- 虽然平时都是调用函数,但是常见实现是
- 欧几里得算法(辗转相除法): 原理:
gcd(a,b)=gcd(b,a mod b), 大数除以小数得到余数,对三个数中的两小数重复,直到出现整除,较小数为最大公约数。 - 更相减损术: 原理:
gcd(a,b)=gcd(b,a - b), 大数减小数得到C,对三个数中的两小数重复,直到出现相等,即为最大公约数。
- 最小公倍数lcm可以由gcd推导:lcm(a, b) = a * b / gcd(a, b)
- 多个数的最大公约数: 由于有传递性,可以将两个树的gcd,传递下去
- 多个数的最小公倍数:
ans = lcm(a, b, c) = lcm(lcm(a, b), c),或者ans = tmp/gcd(tmp,c)*c先除后乘防止溢出。其中tmp=lcm(a,b)或者递归。
位运算¶
- 中 2411. 按位或最大的最小子数组长度
- 每个元素的影响或等于并集,按位或最大==数字1最多,即最大的并集
- 没有增大==或结果相同=>子集=>前面不需要再遍历,剪枝
- 中 1072. 按列翻转得到最大值等行数
- 逆向思考,相等行间的关系
- 相同的行1111 1111 or 0000 0000. 反转列变成 1101 1101 and 0010 0010
- 可以发现将第一位变成1 后,答案就是同为某序列 1101的最大个数
- 注意异或1相当于取反,异或0相当于不变。
- 异或 也可以视作「不进位加法(减法)」或者「模 222 剩余系中的加法(减法)」
组合数问题¶
- 基本公式:

- 常见分解技巧:
- 组合数关系(总组合数=选i的组合数+不选i的组合数):
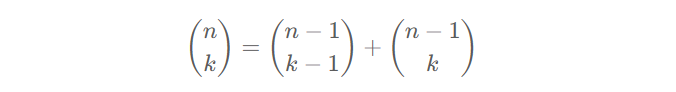
- 乘法原理将总组合数分解成各个部分的组合数的乘积
- 组合问题,常见解法:
- 加加减减回溯法
- 动态规划
- 包含的i种字符,前j个元素来划分
- 中 2597. 美丽子集的数目
不进位的加法¶
- 不进位的加法是异或。华为 P1003. 2022.9.25-分糖果
进制转换¶
- n进制转换为十进制: 简单,
a[i] * n^i - 十进制转换为n进制(n为正数)
- 除n取余数,最后结果取反(reverse)
- 十进制转换为(-n)进制(n为正数)
- 每次取的余数k保证为正数在0到n-1之间。
T=(-n)*p+k - 否则,调整
T=(-n)*(p+1)+(k+n)。余数+n变正数,商++ - 中 1073. 负二进制数相加
- 但是这道题不能用进制转换做,会数据会溢出。 只能模拟按位加法,
- 实现时有一个小问题, 关于负数整除与负数取余
vector<int> int2array(long long num){ const int k = -2; vector<int> result; while(num){ if(num > 0 || num%k==0){ // num%k 余数 大于等于0 result.push_back(num%k); num /= k; }else{ result.push_back(num%k-k); num = num/k + 1; } } reverse(result.begin(), result.end()); if(result.size()==0){return {0};} return result; }
负数整除与负数取余¶
- 负数整除
- C++ 除法采用了向零取整(截断取整):向0方向取最接近精确值的整数,换言之就是舍去小数部分。
- 所以有
(-a)/b==-(a/b) - 负数取余
- 结论
a%b=c中c的符号与a相同 - 证明: 由于 被除数÷除数=商……余数,所以余数=被除数-商×除数。其中除数可由上面的
C++ 除法推导- 讨论
7%(-4)(-7)%4(-7)%(-4)三种情况可知
- 讨论
模板写法¶
- 抽象表示/题目特征(用于高效匹配题型)
- 常见的解法流程
- 解法难点:
- 框架复杂?
- 相关拓展考点/难度延伸
- 相关例题以及核心考点
- 1143 HARD xxx :考察xxx
参考文献¶
许多思路来自:灵茶山艾府