Vllm Basic
导言
HW24年狠抓了训练,但是推理性能稍微落下,dsv3的出现,强化学习的爆火,反过来对推理性能提出了很高的要求。为此高性能的vllm推理框架变成了hw首先适配的目标。
- 一方面我需要大致了解vllm框架的设计,
- 另一方面,我主要需要关注vllm-ascend实现了哪些接口。
vllm¶
vLLM 是一个 LLM (Large Lanuage Model) 推理和部署服务库
代码逻辑¶
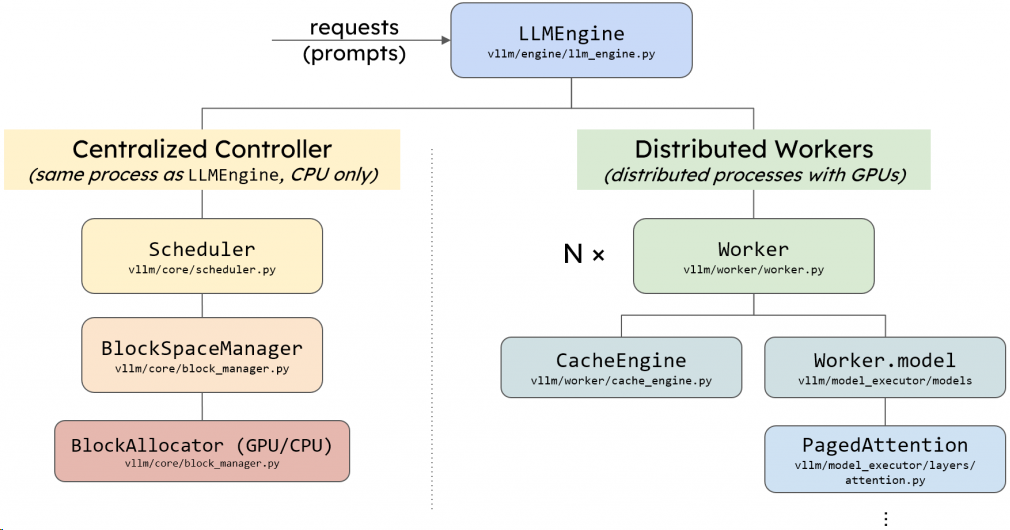
🧠 一、核心架构与组件5
- 引擎初始化
- 配置加载:解析模型路径、缓存策略(如块大小)、并行参数(TP/PP)等。
-
组件构建:
- Processor:验证输入并分词,生成EngineCoreRequest。
- EngineCore:包含模型执行器(Model Executor)、调度器(Scheduler)和KV缓存管理器(核心为分页注意力)。
- OutputProcessor:将模型输出转换为用户可见结果。
-
模型执行器
- 单GPU模式(UniProcExecutor):直接调用Worker执行前向计算。
- 多GPU模式(MultiProcExecutor):通过消息队列协调多个Worker进程,支持张量并行(TP)和流水线并行(PP)。
⚙️ 二、请求处理流程
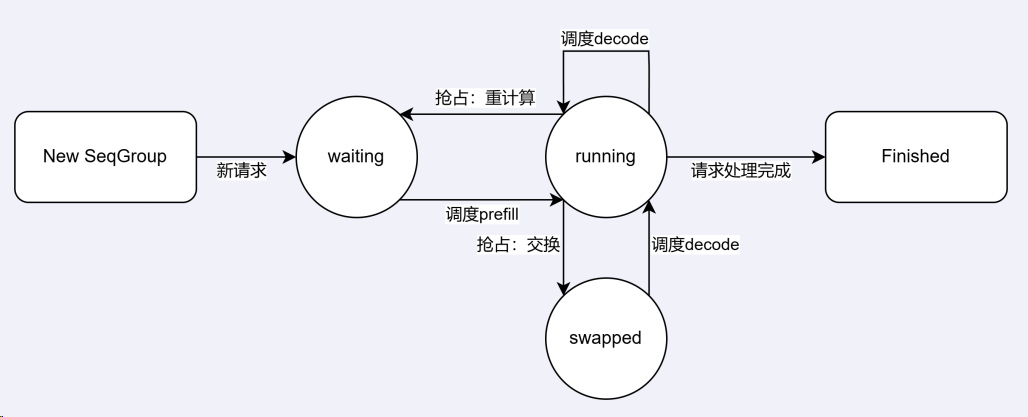
- 请求注入(generate函数)
- 为每个请求生成唯一ID,记录到达时间。
-
分词后打包为EngineCoreRequest,加入调度器的等待队列(FCFS或优先级策略)。
-
执行循环(step函数) 每个步骤包含三个阶段:
- 调度阶段(关键):
- 优先处理解码请求:从运行队列中取出,调用allocate_slots分配KV缓存块。
- 处理预填充请求:从等待队列取出,分配缓存块后移入运行队列。
- 抢占机制:若显存不足,通过重计算或交换(Swap)回收低优先级请求的缓存块。
- 前向传播:
- 输入展平为“超级序列”,通过分页注意力索引KV缓存块。
- 使用自定义内核计算logits,采样新token。
- 后处理:
- 附加采样token,检查停止条件(如EOS、长度限制)。
- 完成请求释放KV缓存块回池(free_block_queue)。
🔄 三、调度与显存管理
- 连续批处理(Continuous Batching)
- 混合预填充(Prefill)与解码(Decode)请求,避免传统批处理需等待完整序列。
-
通过token_budget控制每步新token数量,防止单个长请求阻塞批次。
-
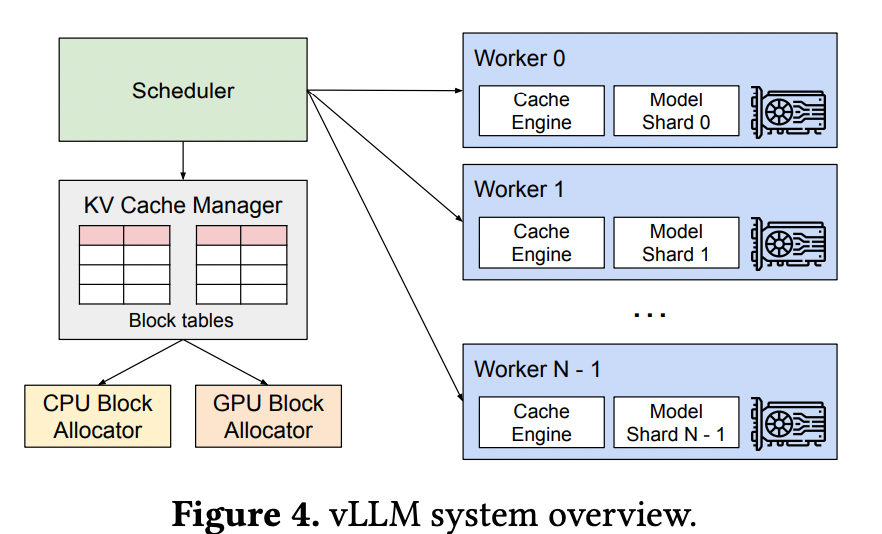
分页注意力(PagedAttention)
- 块分配:KV缓存拆分为固定大小块(默认16 token/块),通过索引结构动态映射。
- 显存优化:
- 初始化时虚拟前向计算,分析显存快照精确规划缓存容量。
- 块池(free_block_queue)复用空闲块,引用计数机制管理生命周期。
⏱️ 四、性能关键点
- 延迟优化
- 首token时间(TTFT):通过分块预填充(Chunked Prefill)拆分长提示词,减少等待。
-
尾延迟控制:优先调度解码请求(内存带宽受限),预填充请求(计算受限)次之。
-
吞吐量提升
- CUDA图捕获:预编译GPU工作流,减少内核启动开销。
- 自动化调优:vllm bench工具根据SLO(如p99延迟<500ms)推荐批大小等参数。
💎 总结 vLLM通过分页注意力实现高效的KV缓存管理,结合连续批处理动态混合不同阶段的请求,显著提升GPU利用率。其调度器优先处理解码请求,确保低延迟,同时通过块池复用显存,支持高吞吐场景。这一设计使vLLM在保持模型准确性的同时,成为业界领先的高性能推理框架。
核心特性¶
🚀 一、核心架构与性能优化
- 分页注意力(PagedAttention)
创新性显存管理技术,将KV缓存拆分为固定大小块(默认16 token/块),通过索引结构动态分配显存,减少碎片化并提升吞吐量30%以上。(PagedAttention)受操作系统虚拟内存和分页思想启发,将原本连续的 KV cache 存储在不连续的空间,以避免 KV cache 带来的显存浪费。 - 连续批处理(Continuous Batching)
支持异步混合处理不同请求的预填充(Prefill)与解码(Decode)阶段,避免传统批处理需等待完整序列的问题,显著提升GPU利用率。(常被称为 continuous batching,该调度算法在 Orca2 中首次被提出)(iterative-level schedule1)以单轮迭代的方式对用户的请求进行处理,即 LLM 生成一个 token 后会重新调度下一轮要处理的请求。 - 显存优化
采用块池(Free Block Queue)管理空闲KV缓存块,结合引用计数机制实现高效复用;初始化时通过虚拟前向计算分析显存快照,精确规划缓存容量。
KV cache的原理 + LLM通俗易懂的实现逻辑介绍
⚙️ 二、高级功能特性
- 分块预填充(Chunked Prefill)
将长提示词拆分为固定大小块(如8 token/块),避免单个长请求阻塞其他请求,降低尾延迟。 - 前缀缓存(Prefix Caching)
对共享前缀的请求(如相同指令模板),复用已计算的KV缓存块。通过块哈希表(BlockHash→KV块)实现O(1)查找,减少重复计算。 - 推测解码(Speculative Decoding)
- 草稿模型加速:小模型(如n-gram、Medusa头)生成候选token,大模型并行验证并接受/拒绝。
- 统计等价性:保证输出分布与逐token生成一致,理论加速比达k+1倍(k为候选数)。
- 引导式解码(Guided Decoding)
基于语法约束的有限状态机(FSM),实时掩码非法token。支持正则表达式与上下文无关文法(如JSON格式生成)。
🌐 三、分布式扩展能力
- 模型并行
- 张量并行(TP):单节点内拆分模型权重(如TP=8),通过NCCL实现高效通信。
- 流水线并行(PP):跨节点划分模型层,优化节点间带宽利用率。
- 服务架构
- 解耦Prefill/Decode:分离计算密集型(Prefill)与内存密集型(Decode)阶段,独立扩缩容。
- 多引擎部署:支持数据并行(DP)、负载均衡(DPLB)及API网关(FastAPI+Uvicorn),实现万亿参数模型服务。
特性:动态批处理¶
vLLM 作为大模型推理框架,主要通过动态调度机制管理 batch_size,虽然不提供直接设置静态 batch_size 的参数,但提供了多种间接控制 batch 行为的选项和优化策略。以下是具体实现方式及相关控制方法:
一、显式控制方式¶
- 显存利用率参数(
gpu_memory_utilization)
在启动 API 服务时,通过 --gpu-memory-utilization 指定 GPU 显存利用率(默认 0.9),间接控制最大并发 batch_size。显存利用率越高,系统可动态调度的 batch_size 上限越大。
- 模型加载配置
通过量化模型(如加载 AWQ 量化模型)减少显存占用,从而提升单次可处理的 batch_size。例如:
二、隐式优化策略¶
- 动态批处理(Continuous Batching) vLLM 的核心特性之一,自动合并请求并动态调整 batch_size。例如:
- 离线批处理模式:用户提交一组 prompts 后,vLLM 根据显存和序列长度动态拆分或合并批次。
- 在线服务模式:请求进入等待队列,系统根据实时资源占用情况将队列中的请求分批处理,无需用户干预。
- KV 缓存管理(PagedAttention) 通过分页显存管理技术,支持更长的序列和更大的 batch_size。用户可通过限制
max_tokens参数控制单条序列的最大长度,间接影响 batch_size 上限。
三、高级参数调优¶
-
请求并发限制(
max_num_seqs)
在 API 服务中通过--max-num-seqs限制同时处理的请求数,避免单次 batch_size 过大导致显存溢出。 -
生成长度控制(
max_tokens)
限制生成文本的最大 token 数(如max_tokens=100),减少单条请求的显存占用,从而允许更大的 batch_size。 -
实验调优公式
根据显存容量估算最大可行 batch_size:
建议预留 20-30% 显存作为缓冲区。
四、实际应用建议¶
- 高吞吐场景:优先选择 7B 级别模型(如 Mistral-7B),并设置
gpu_memory_utilization=0.95以最大化 batch_size。 - 长序列场景:启用 AWQ 量化,结合
max_tokens限制生成长度。 - 稳定性优先:通过
nvidia-smi监控显存占用,动态调整并发请求量。
通过上述方法,用户可以在 vLLM 中间接控制 batch_size 的调度边界,实现效率与资源的平衡。如需深入细节,可参考 vLLM 官方文档 或源码调度逻辑解析。
架构¶
投机推理 & eagle3¶
见单独文章
确定性问题:批次不变性¶
- 问题:vllm推理如果温度设置成0,还是会出现推理出不同结果的情况。
- 原因: 在线推理推理时,会组成不同的batch组,batch大小不同,导致经过RMSNorm、矩阵乘法和注意力三个关键算子时,算子内部会自动切分,并采用不同的规约策略;这会导致出现精度问题(浮点数大数吞小数)
- 解决方案: CUDA重新三个算子,使其满足batch不变性。4
- 效果:损失了50%性能(没优化),但是保证推理稳定输出
- 具体实验:
- 采样了 1000 次完成结果,每次生成 1000 个 token。
- 没修改前:得到了 80 个不同的完成结果,其中最常见的一个出现了 78 次。前 102 个 token 相同,103开始不同。
- 修改后:1000次完全相同
- 额外影响:
vllm-ascend¶
通过VizTrace可以很简单的看出其实现。
- ModelRunner里注册npu代码
DP分离 vs AF 分离¶
AF 分离,是继 DP 分离(Decode-Prefill 分离)之后,在大模型推理优化领域(特别是 DeepSeek-V3 之后)非常火的一个概念。
简单来说,AF 分离指的是 Attention(注意力机制)与 FFN(Feed-Forward Network,前馈网络)在硬件计算资源上的解耦与分离。
1. 为什么会有 AF 分离?¶
要理解 AF 分离,我们先看 Transformer 每一层中这两个组件的不同“性格”:
- Attention (A): 它是“内存饥渴型”。它不仅需要加载权重,还需要频繁地读写 KV Cache。在长文本推理时,KV Cache 的压力非常大,对显存带宽(HBM Bandwidth)和通信速度要求极高。
- FFN (F): 它是“计算密集型”。它占据了模型约 2/3 的参数量,需要大量的浮点运算(FLOPs)。虽然它不产生 KV Cache,但它需要庞大的算力来消化那些矩阵乘法。
痛点: 在传统的统一架构中,所有芯片都要同时负责 A 和 F。这会导致一个矛盾:为了照顾 Attention 的 KV Cache 需求,可能浪费了 FFN 的算力;或者为了 FFN 的高算力,导致 KV Cache 的存储效率不高。
2. AF 分离与 DP 分离的区别¶
你可以把 DP 分离看作是“横向阶段”的拆分,而 AF 分离是“纵向结构”的拆分。
| 维度 | DP 分离 (Decode-Prefill) | AF 分离 (Attention-FFN) |
|---|---|---|
| 拆分逻辑 | 按任务阶段拆(预填充 vs 生成) | 按模型层内组件拆(计算 vs 存储) |
| 核心目的 | 解决不同阶段对吞吐量和延迟要求的不同 | 解决不同组件对显存带宽和算力要求的不同 |
| 优化重点 | 提升 Prefill 的吞吐,降低 Decode 延迟 | 极致优化 KV Cache 存储,充分压榨 GPU 算力 |
3. AF 分离是怎么运作的?¶
在 DeepSeek-V3 等最新的架构设计中,AF 分离通常表现为“解耦架构” (Disaggregated Architecture):
- Attention 节点: 专门配置大内存、高带宽,存放 KV Cache。它负责处理计算量相对小、但数据交换频繁的 Attention 部分。
- FFN 节点: 专门配置高算力芯片,存放模型中占比最大的 FFN 参数。它通过极速互联(如 NVLink 或定制交换机)接收来自 Attention 节点的中间结果,计算完后再传回去。
4. 为什么要这么折腾?(核心优势)¶
- KV Cache 显存利用率暴增: 因为 Attention 节点被独立出来了,你可以把所有的显存几乎都用来存 KV Cache,从而支持超长上下文(如百万 Token)而不会因为 FFN 占用了显存而导致 OOM(显存溢出)。
- 计算效率最大化: FFN 节点可以全速跑矩阵乘法,不用等 KV Cache 的读取,计算流水线更紧凑。
- 异构硬件支持: 理论上,你可以用带宽高的芯片做 Attention,用算力强的芯片做 FFN,实现“因材施教”的硬件部署,大幅降低成本。
总结¶
DP 分离解决了“什么时候算”的问题,而 AF 分离解决了“在哪里算”的问题。这是大模型迈向“算力中心化”和“存储专门化”的重要一步。
如果你是对 DeepSeek 的技术栈感兴趣,AF 分离通常配合他们的 MLA (Multi-head Latent Attention) 技术一起使用,效果更佳。